
stable diffusion with mlflow tracking server
Intro
이번 포스팅에서는 AWS에서 MLflow를 활용할 수 있도록 환경을 구축하고 Stable Diffusion 모델을 Low-Rank Adaptation of Large Language Models(LoRA) 방법을 활용한 하이퍼파라미터 튜닝 및 학습에 대한 결과를 mlflow tracking server에 기록하고 모델 버전을 관리하는 방법에 대해 다루려고 합니다.
구상한 아키텍쳐는 다음과 같습니다.
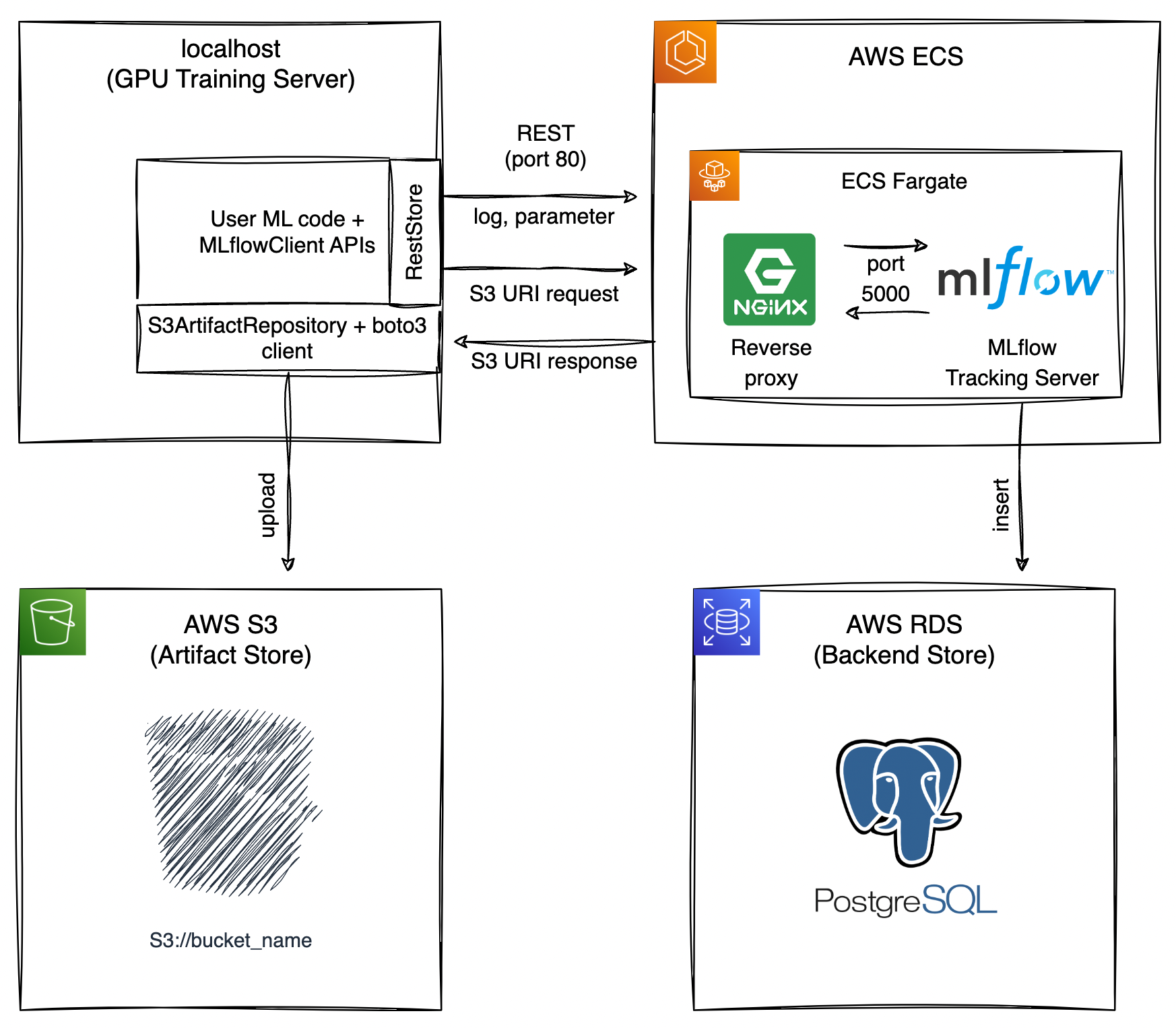
MLflow tracking server를 로컬(클라이언트) 환경에서 완전히 분리시키려면 backend store와 artifact store를 따로 준비해야합니다.
- backend store: Experiments의 metadata, parameter, metircs, tag를 저장하는 관계형 데이터베이스
- artifact store: file, model과 같은 artifact를 저장하는 S3 bucket 혹은 NFS
아키텍쳐를 위 그림과 같이 구상한 이유가 몇가지 있습니다.
ECS Fargate vs ECS EC2
ECS 클러스터에서 사용할 자원을 EC2가 아닌 Fargate로 선택한 이유는 현재 상황에서 서버리스(Fargate)의 장점이 EC2의 장점보다 더 좋기 때문입니다.
mlflow tracking server는 모델 학습, 모델 버저닝, 대시보드 접속 등과 같은 일을 할때가 아니라면 24시간 내내 컨테이너를 실행시킬 필요가 없습니다.
mlflow tracking server가 중지되더라도 데이터는 RDS와 S3에 안전하게 저장되기 때문에 비용절감과 인스턴스 프로비전 및 관리가 필요없는 Fargate로 원할때만 ECS 태스크를 실행하는 방법을 선택했습니다.
Nginx Reverse Proxy
아키텍쳐를 보시면 외부에서 mlflow에 바로 접근하는게 아니라 Nginx Reverse Proxy로 접근하도록 되어 있습니다. Nginx Reverse Proxy를 사용한 이유는 보안 때문입니다.
mlflow 대시보드에 접속해 보신 분들은 아시겠지만 mlflow는 자체 로그인 시스템이 없습니다. 그렇기 때문에 대시보드 주소가 localhost가 아닌 외부 IP로 설정된 경우 IP가 노출되면 누구나 접속이 가능하다는 문제가 있습니다.
접속 IP를 제한하거나 인증서를 활용하는 방법 등 여러 방법이 있지만 저는 간단하게 Nginx Reverse Proxy의 HTTP Basic Authentication 기능을 활용하여 대시보드에 접속할 때 로그인을 할 수 있도록 처리하였습니다.
Client가 AWS 외부?
mlflow tracking server, backend store, artifact store 와는 다르게 실제 하이퍼 파라미터 튜닝과 모델 학습을 AWS 외부 localhost 에서 진행하는 이유는 비용 때문입니다.
Stable Diffusion은 Attention 기반의 이미지 생성 모델입니다. 즉 GPU 메모리가 어느정도 요구되는데 개인적으로 사용 가능한 GPU 서버가 있기 때문에 AWS 환경에서 분리하였습니다.
MLflow 환경 구축
S3 생성
S3 서비스로 이동하여 버킷을 하나 만들겠습니다.
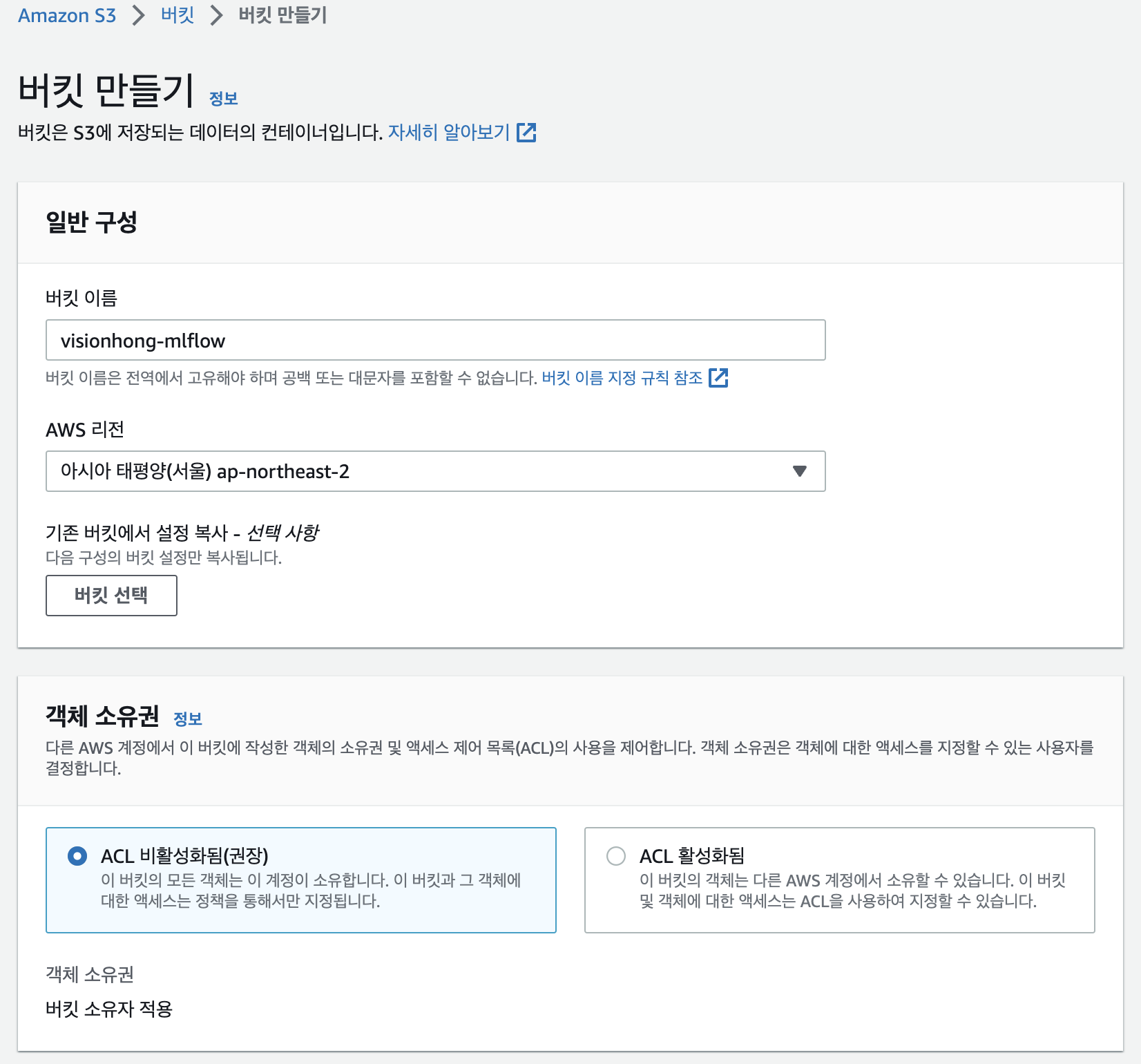
S3의 데이터는 리전에 저장되지만 기본적으로 글로벌 서비스입니다. 그렇기 때문에 버킷 이름은 리전에 상관없이 전세계에서 고유값이어야 합니다. 저는 visionhong-mlflow 라고 설정하였고 나머지 항목들은 default로 두고 바로 생성하겠습니다.
bucket이 잘 생성되었습니다.
보안그룹(Security Group) 생성
EC2 서비스로 이동하여 보안그룹을 먼저 생성하겠습니다.
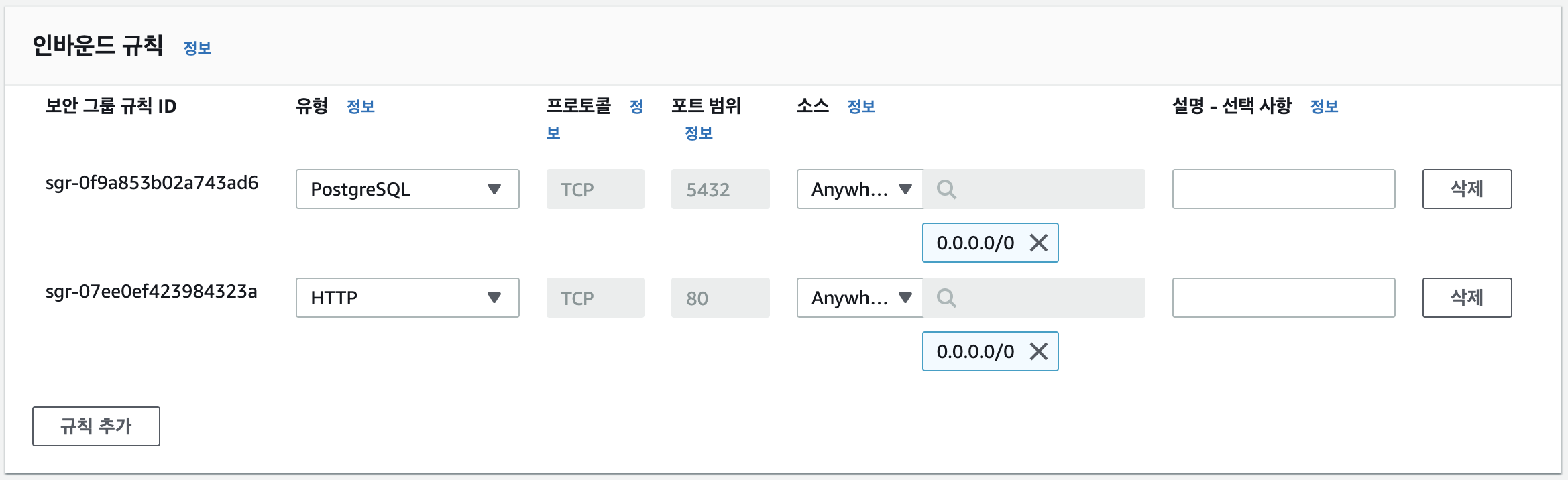
첫번째 인바운드 규칙은 ECS 클러스터에서 생성될 컨테이너가 PostgreSQL에 접속하기 위한 규칙이고 두번째 인바운드 규칙은 외부에서 컨테이너에 접속하기 위한 규칙입니다.
RDS 생성
이제 Amazon RDS 서비스로 이동하여 데이터베이스를 하나 생성하겠습니다.
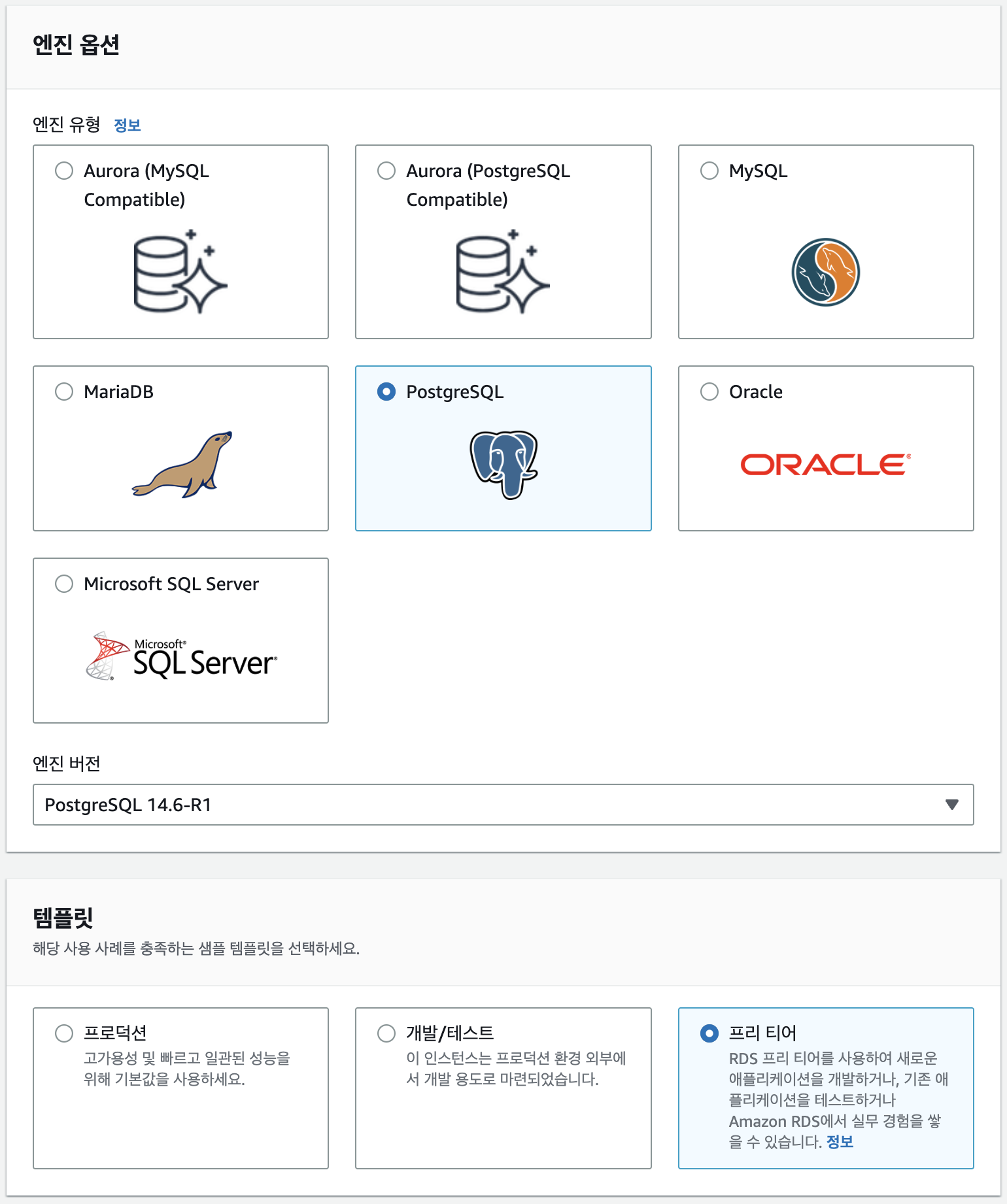
DB는 PostgreSQL 최신버전으로 선택하고 프리티어 템플릿을 사용하겠습니다.
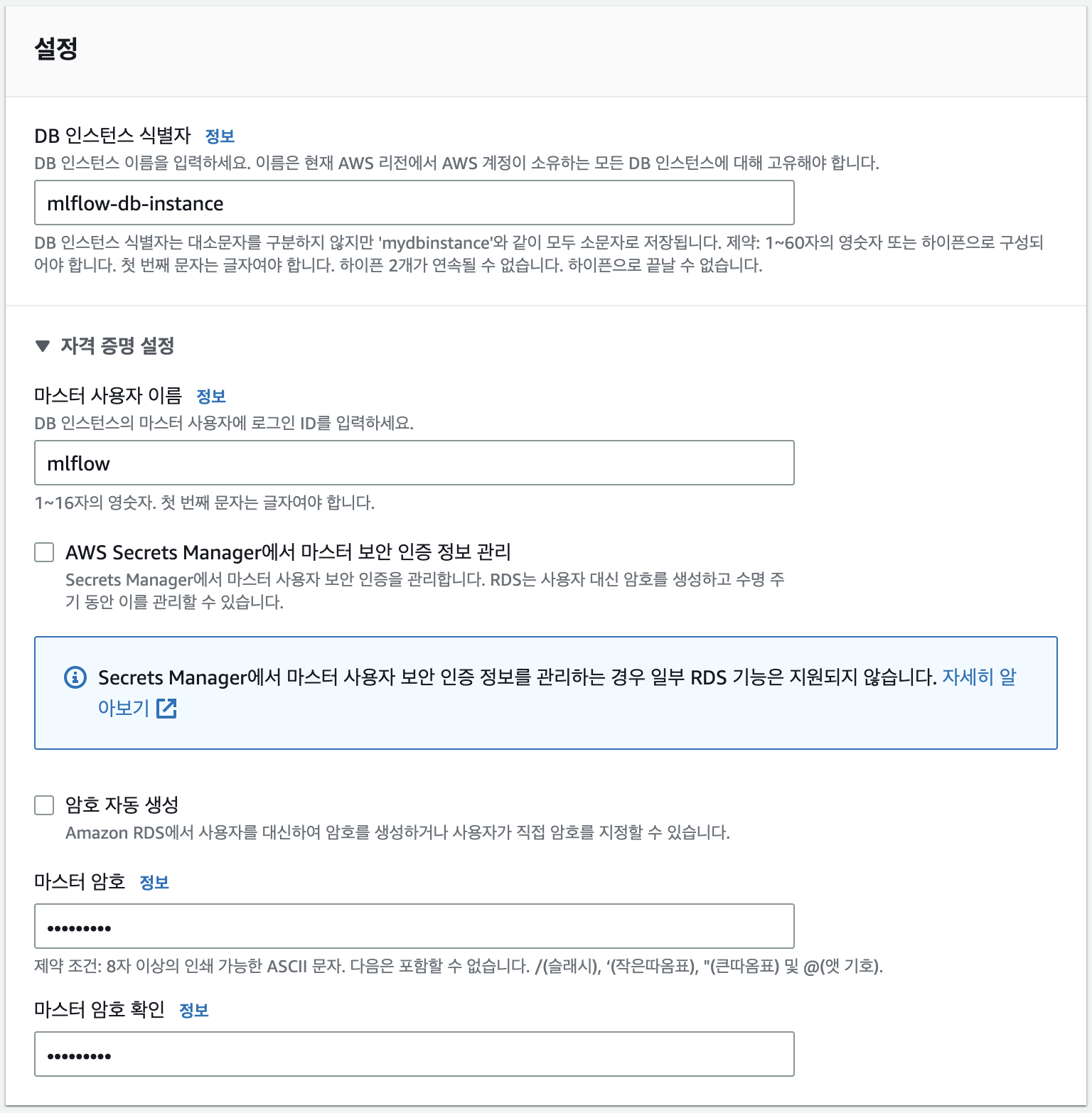
자격증명 설정의 마스터 사용자 이름과 마스터 암호는 DB에 접근하기 위한 아이디와 비밀번호 같은 정보입니다. 나중에 환경변수 파일(.env)에 작성해야 하니 잘 기록해주세요.
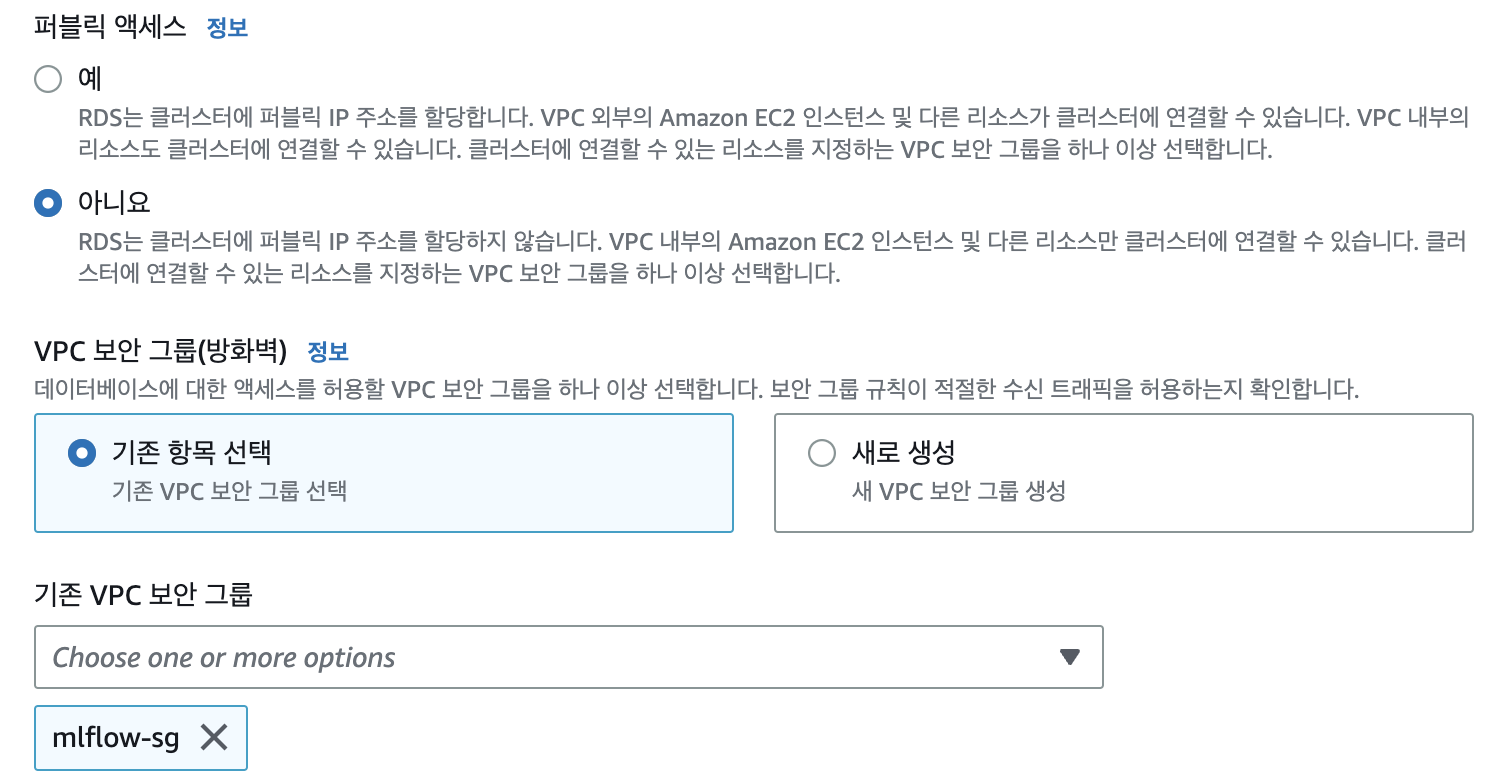
추후 ECS 클러스터와 RDS를 같은 VPC에서 생성할 것이기 때문에 퍼블릭 액세스는 False로 두었습니다. 그리고 위에서 생성한 보안그룹을 적용하여 컨테이너에서 RDS로 접근 가능하도록 해줍니다.
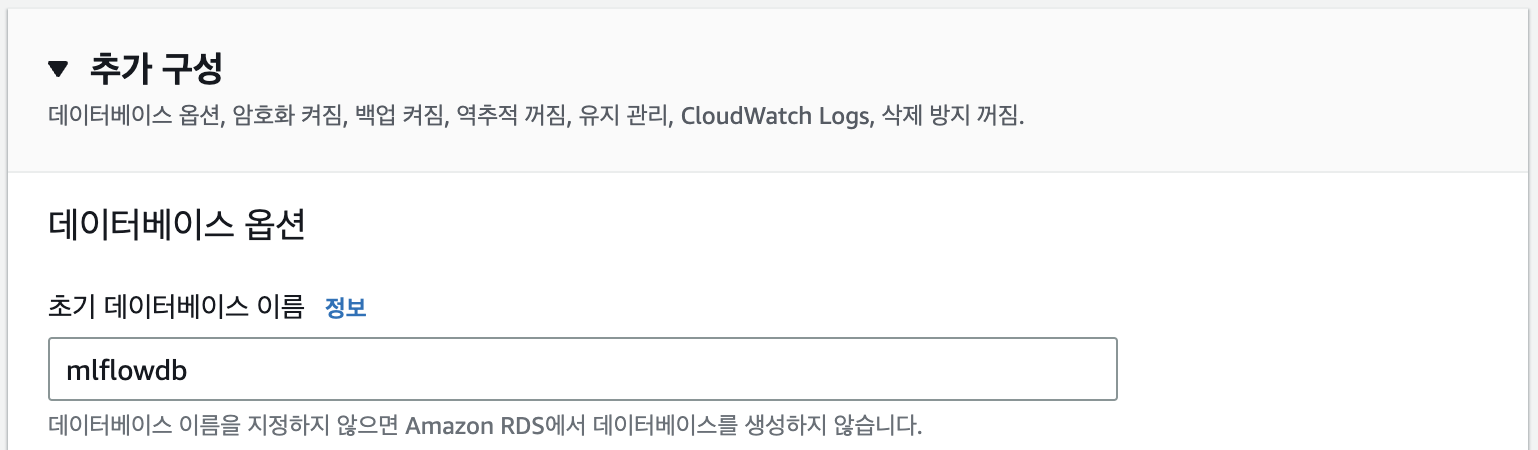
추가 구성을 클릭하고 데이터베이스 이름을 지정해줍니다. 데이터베이스 이름도 마찬가지로 mlflow tracking server가 DB와 통신할 때 필요합니다.
나머지 설정은 default로 두고 DB를 생성하겠습니다.
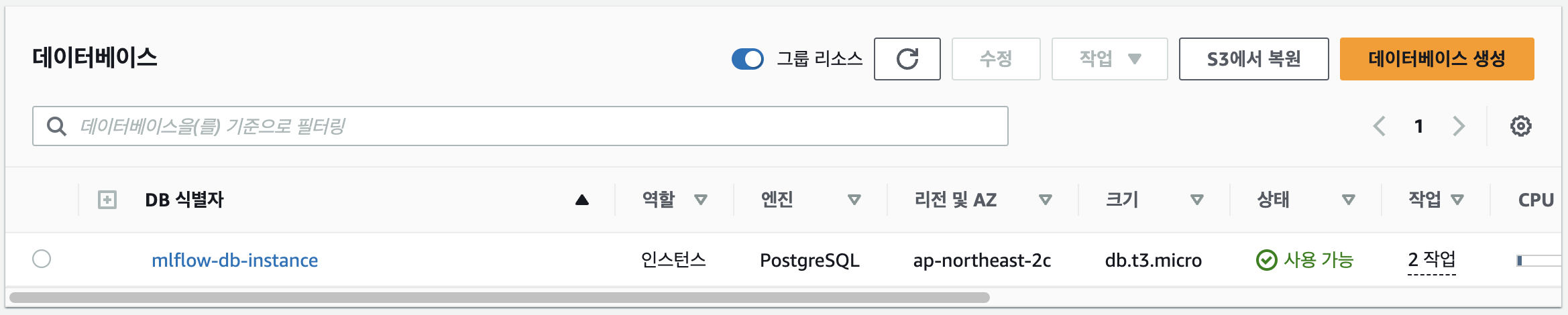
DB가 정상적으로 생성되었습니다.
ECR
ECS에서 사용할 컨테이너 이미지는 Docker Hub, GitHub Container Registry, AWS ECR 등에서 가져올 수 있습니다. 여기에서는 컨테이너 이미지를 로컬에서 생성하여 ECR repository에 등록해 보겠습니다.
Dockerfile
FROM ubuntu/nginx:1.18-20.04_beta
RUN apt-get update \
&& apt-get install --no-install-recommends pip -y \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir mlflow==2.3.2 boto3 psycopg2-binary
COPY auth.conf auth.htpasswd launch.sh ./
RUN chmod +x launch.sh
CMD ["./launch.sh"]
이미지로 빌드할 도커파일 내용을 요약하면 다음과 같습니다.
- ubuntu 20.04 환경에 nginx 1.18 버전이 설치된 베이스 이미지 활용
- pip 패키지 설치 및 패키지 캐시 삭제(이미지 경량화)
- mlflow 2.3.2 버전, s3 통신을 위한 boto3, Postgresql 접속을 위한 psycopg2 라이브러리 설치
- 파일 복사 및 launch.sh 실행
launch.sh
envsubst < auth.conf >/etc/nginx/sites-enabled/default
envsubst < auth.htpasswd > /etc/nginx/.htpasswd
service nginx restart
mlflow server \
--backend-store-uri postgresql://$DB_USER:$DB_PW@$DB_ENDPOINT:$DB_PORT/$DB_NAME \
--default-artifact-root s3://$AWS_BUCKET_NAME
launch.sh 파일에서는 nginx reverse proxy를 설정하고 mlflow tracking server를 실행합니다.
이때 여러 환경변수를 활용합니다. Docker run과 Docker-compose 명령어에서 –env_file 옵션이 있는것처럼 ECS에서 task를 정의할때 컨테이너에서 사용할 환경변수 파일을 활용할 수 있습니다.
컨테이너에서 사용할 환경변수 파일을 생성하겠습니다.
mlflow.env
DB_NAME=<db-name>
DB_USER=<user-name>
DB_PW=<db-password>
DB_PORT=<db-port>
DB_ENDPOINT=<db-endpoint>
AWS_BUCKET_NAME=<bucket-name>
AWS_ACCESS_KEY_ID=<aws-access-key-id>
AWS_SECRET_ACCESS_KEY=<aws-secret-access-key>
AWS_REGION=<resion>
HTPASSWD=<htpasswd>
DB_ENDPOINT 환경변수는 RDS 콘솔에서 주소를 확인할 수 있으며 AWS 관련 환경변수는 IAM과 S3에서 확인하시면 됩니다.
추가적으로 HTPASSWD는 mlflow 대시보드에 접속할때 필요한 username과 password 입니다. htpasswd generator 에서 생성하시면 됩니다. ex) user1:$apr1$clme56rh$7kbO8h94VA5UWBNpdayu80)
작성이 완료되었다면 이 파일을 S3에 등록해야 합니다. ECS task를 생성할때 컨테이너 환경변수 파일을 S3에서 가져오기 때문입니다. 위에서 생성한 S3 bucket에 환경변수 파일을 업로드 하겠습니다.
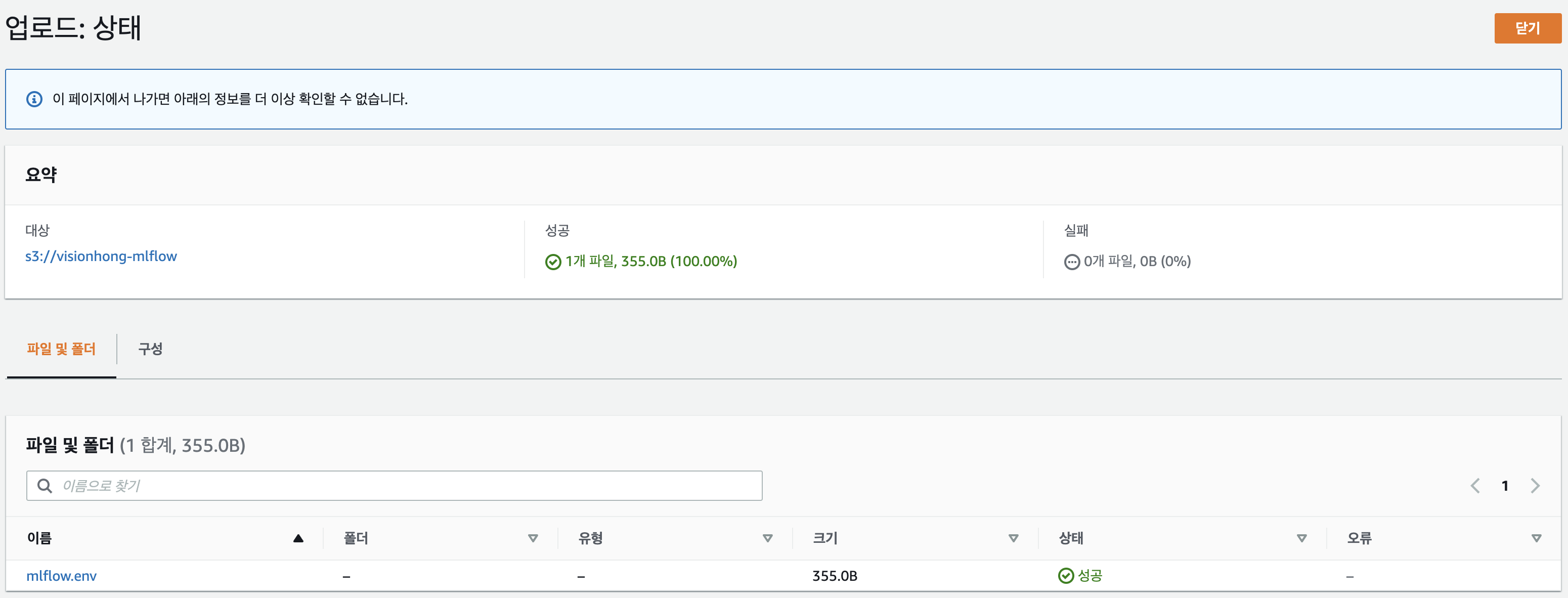
ECR에 이미지를 push하기 위해서는 ECR에 Repository가 등록되어있어야 합니다. ECR 콘솔로 이동하여 Repository를 생성하겠습니다.
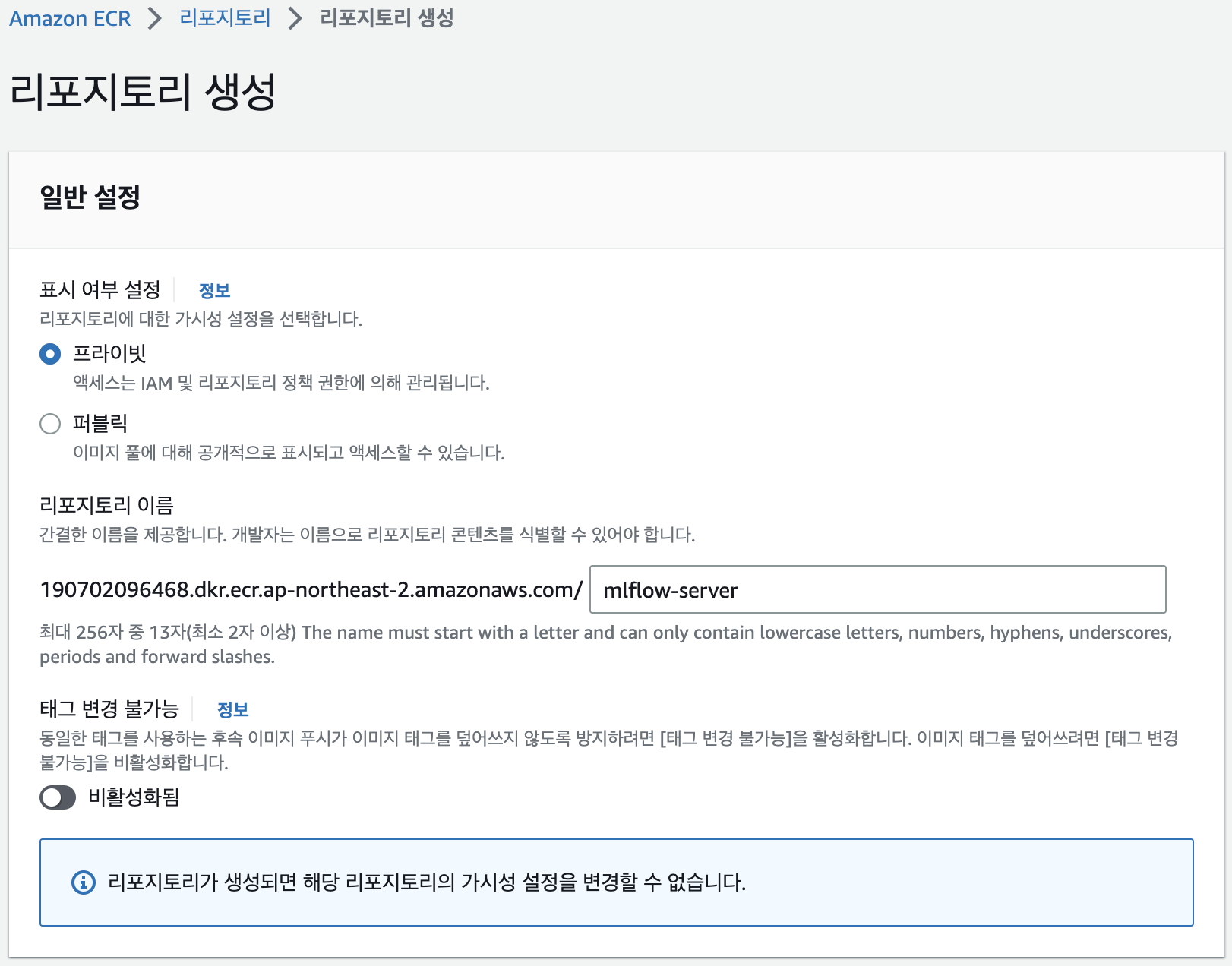
Repository 이름이 URI가 됩니다. 이름을 설정해주시고 나머지는 default 값으로 바로 생성하겠습니다.
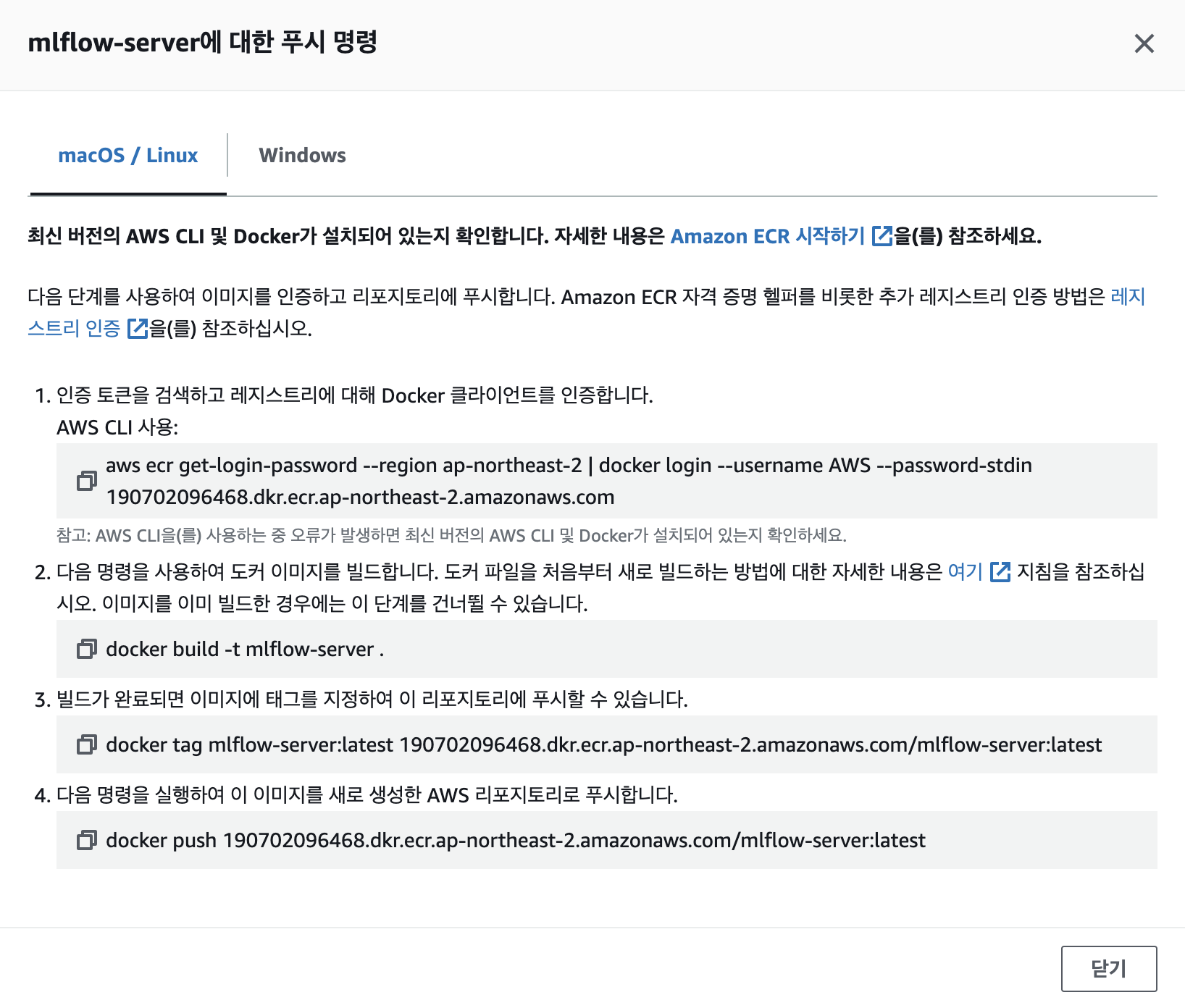
생성된 Repository를 클릭하면 우측 상단에 푸시 명령 보기 버튼이 있습니다. 버튼을 클릭하면 위 이미지처럼 로컬에서 ECR에 이미지를 푸시하는 커맨드가 적혀있습니다.
1번 명령어를 실행하려면 로컬환경에 aws 패키지가 설치되어있어야 하고 aws configure 로 IAM 사용자인증을 하셔야합니다. 1번 명령어를 통해 도커 로그인을 했다고 가정하고 여기서는 2번 커맨드부터 시작하겠습니다.(이미지 빌드를 위한 파일이 필요하신 분은 포스팅 아래 Reference를 참고해주세요)
docker build -t mlflow-server:2.3.2 .
docker tag mlflow-server:2.3.2 190702096468.dkr.ecr.ap-northeast-2.amazonaws.com/mlflow-server:2.3.2
docker push 190702096468.dkr.ecr.ap-northeast-2.amazonaws.com/mlflow-server:2.3.2

이미지가 정상적으로 ECR에 푸시되었습니다.
ECS
태스크 정의
ECS를 사용하기 위해서는 미리 태스크를 정의해야 합니다. ECS 콘솔에서 새 태스크를 정의하겠습니다.
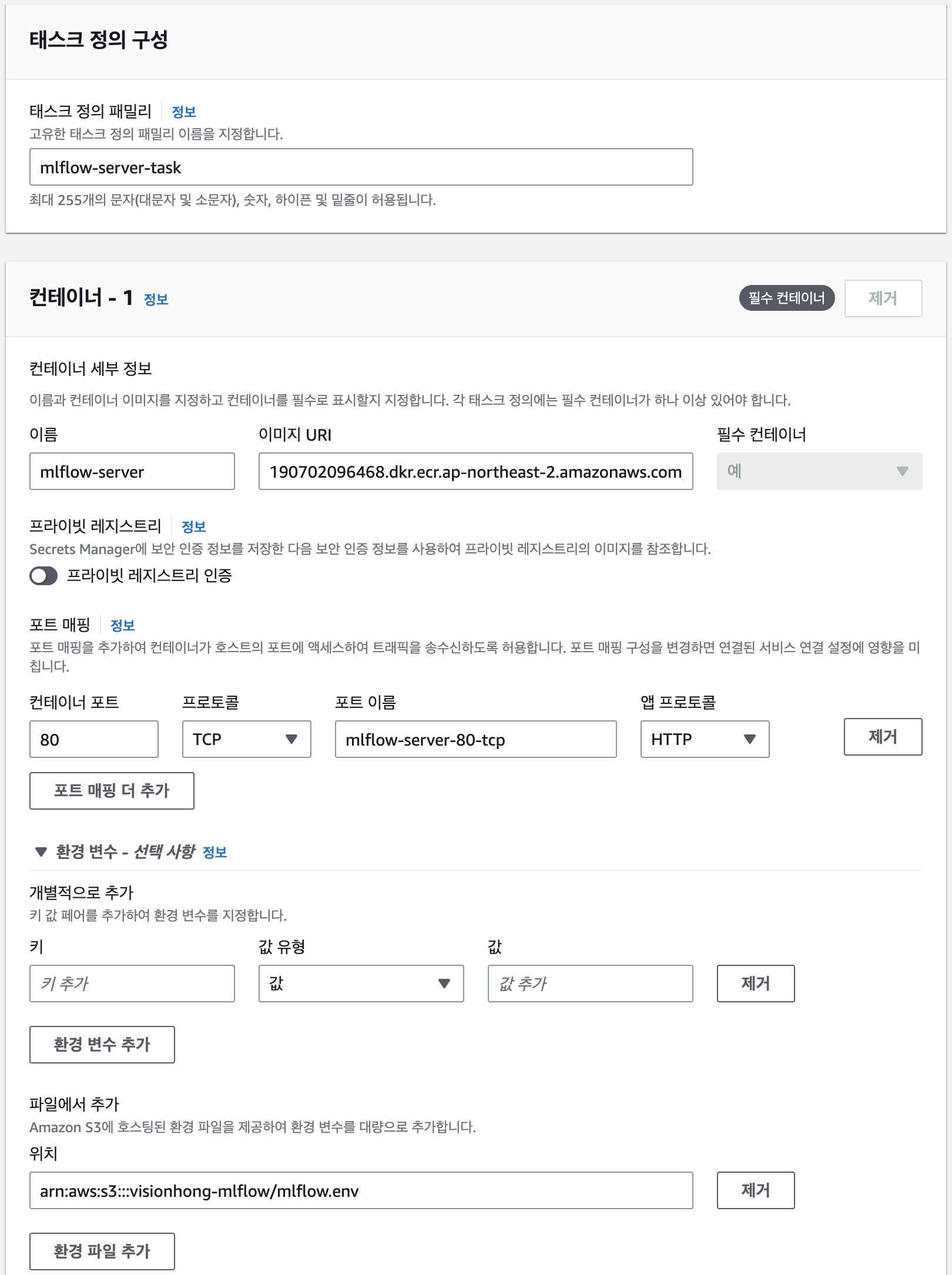
사용할 이미지는 ECR에 저장했던 이미지의 URI를 붙여넣어줍니다. 컨테이너 포트는 HTTP 프로토콜 80번 포트로 열어두겠습니다. Nginx reverse proxy가 HTTP well known port(80)으로 들어온 요청을 5000번 포트로 연결해주기 때문입니다.
그리고 환경변수 추가를 클릭하고 환경파일 추가에 S3에 저장한 환경변수 파일의 arn을 입력합니다. (S3 콘솔에서 확인)
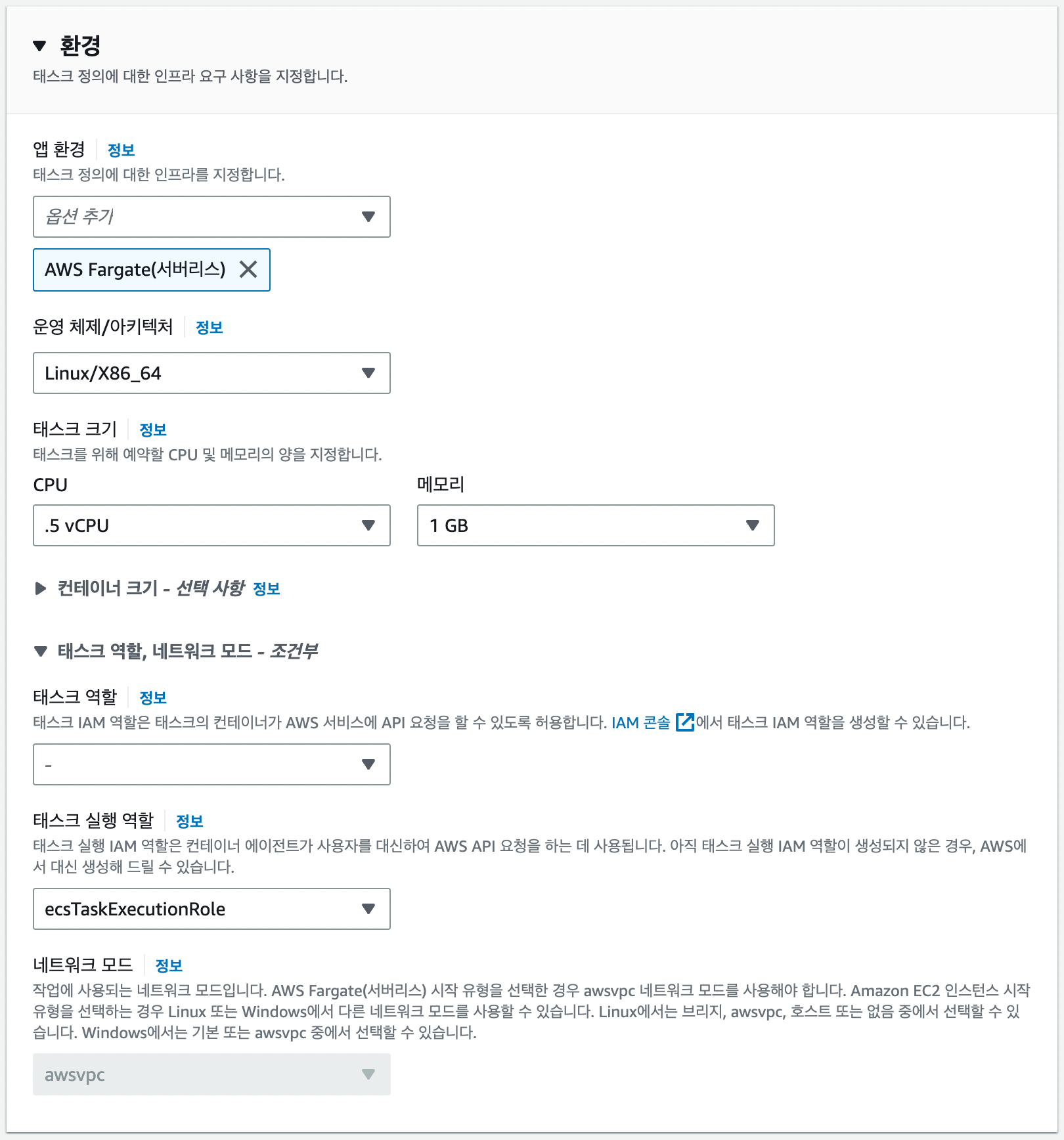
다음으로 넘어가면 어떤 자원으로 컨테이너를 실행할지 환경을 구성합니다. 앱 환경은 AWS Fargate로 선택하고 나머지 리소스들은 가장 작은 값으로 설정했습니다.
태스크 실행 역할에 보면 ecsTaskExecutionRole이라는 IAM 역할이 기본으로 설정되어있습니다. 이 IAM 역할에 저희는 S3접근을 위한 인라인 정책을 추가해주어야합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:GetBucketLocation",
"Resource": "arn:aws:s3:::*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::visionhong-mlflow/mlflow.env"
}
]
}
IAM 콘솔로 이동하여 역할에 ecsTaskExecutionRole를 검색하고 인라인 정책 생성을 클릭하고 위 JSON 내용을 넣어주시면 됩니다. GetObject action의 resource는 자신의 환경변수 파일의 arn을 입력해야 하는것을 주의해주세요.
정책을 생성하게되면 이제 ECS에서 S3의 환경변수 파일을 활용하여 컨테이너를 생성할 수 있게됩니다. 다시 ECS로 돌아와 나머지 값들을 Default로 두고 태스크를 생성하겠습니다.
클러스터 생성
정의한 태스크를 실행하기 위해서는 ECS 클러스터가 존재해야합니다. 클러스터를 생성하겠습니다.
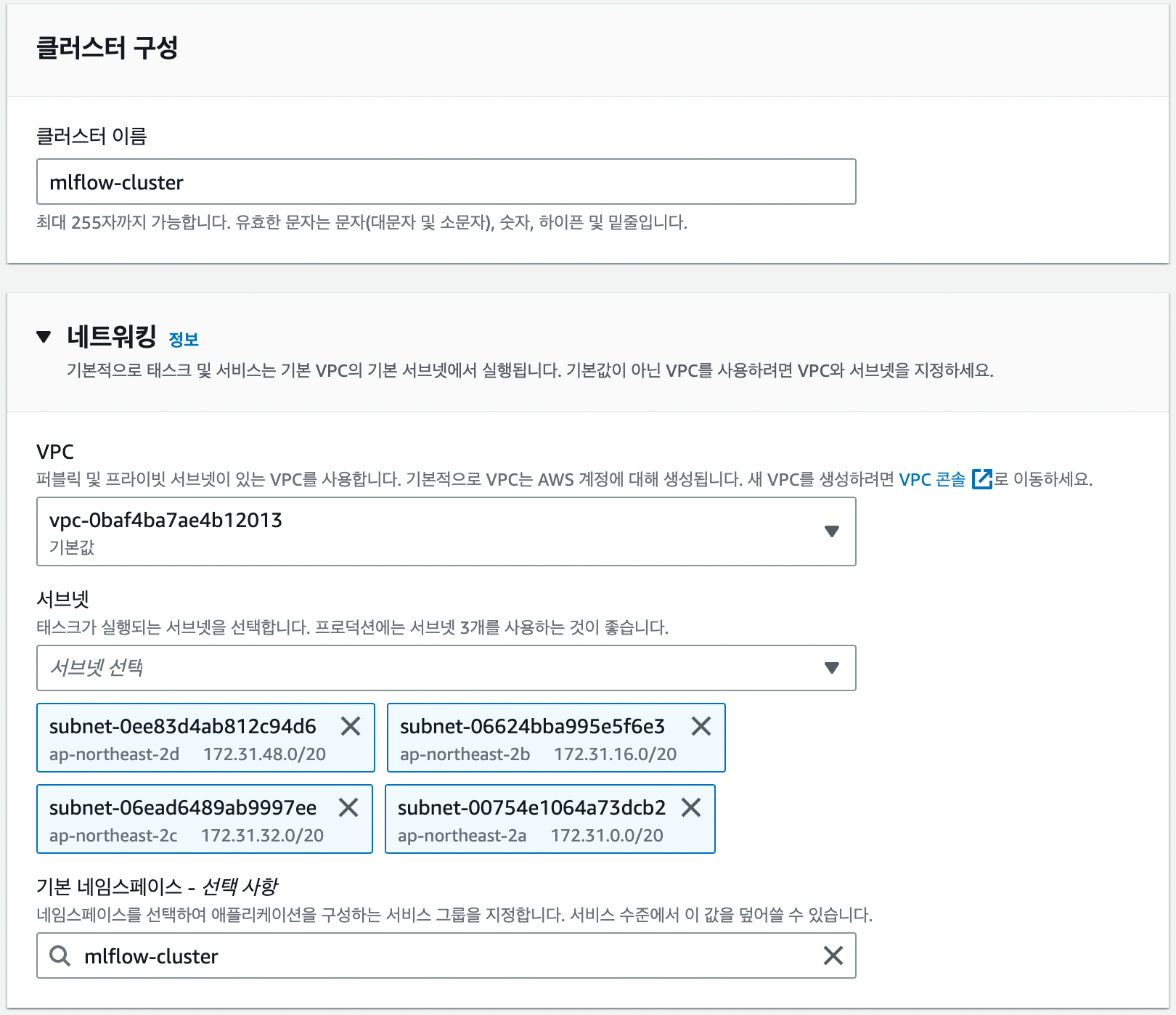
클러스터 생성시 주의할 점은 VPC입니다. RDS에서 DB를 생성할 때 VPC외부에서 접근가능하도록 설정하지 않았기 때문에 DB가 위치한 VPC를 그대로 사용하셔야 합니다.
서비스 생성
서비스는 컨테이너의 배포, 확장, 종료를 관리합니다. 또란 컨테이너의 상태를 모니터링하고, 컨테이너가 실패할 경우 재시작합니다. 서비스를 생성하겠습니다.
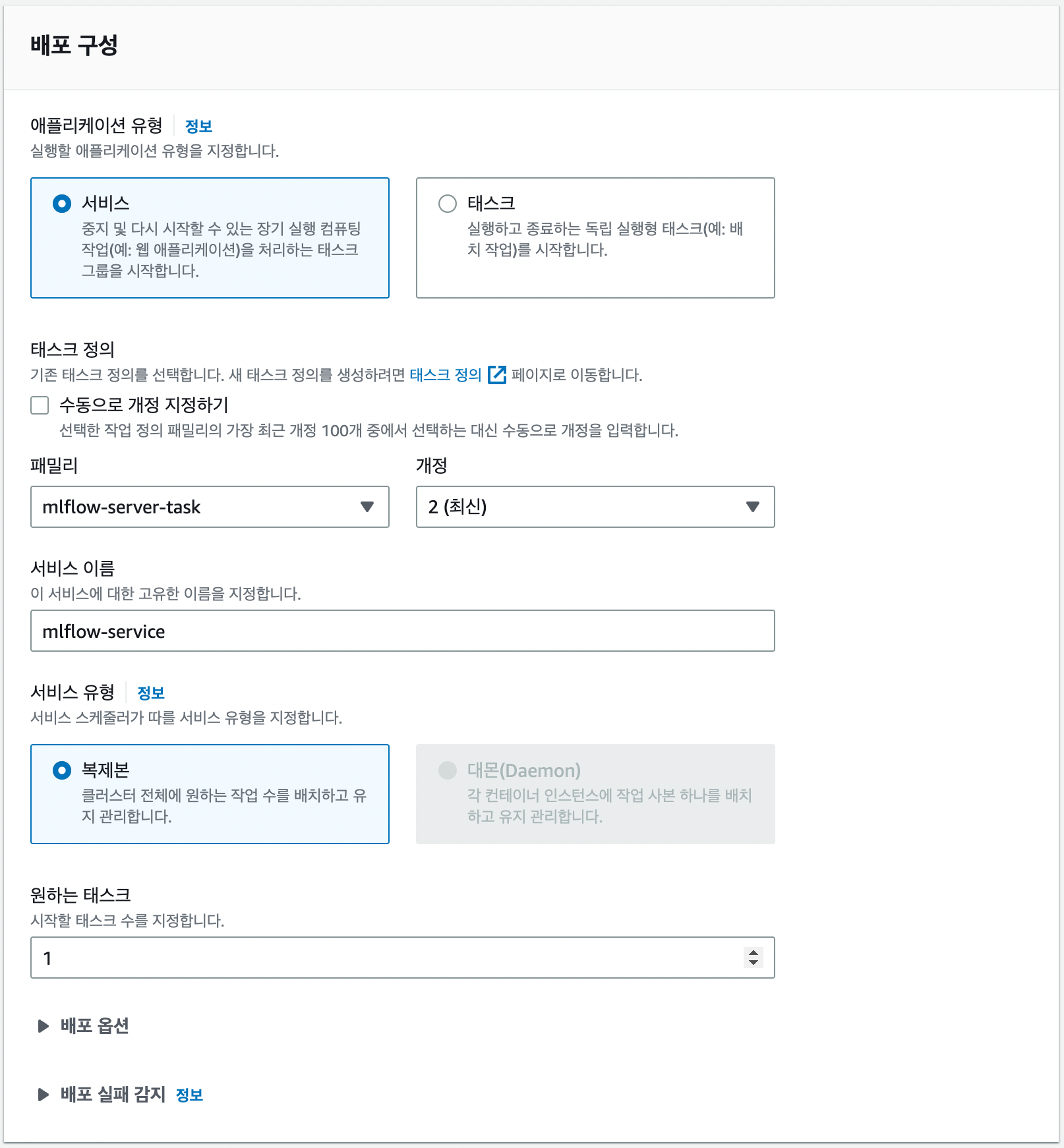
배포 구성 패밀리에서 미리 생성한 태스크와 그 버전을 선택할 수 있습니다. (저는 버전이 하나 더 있어서 2로 되어있습니다.)
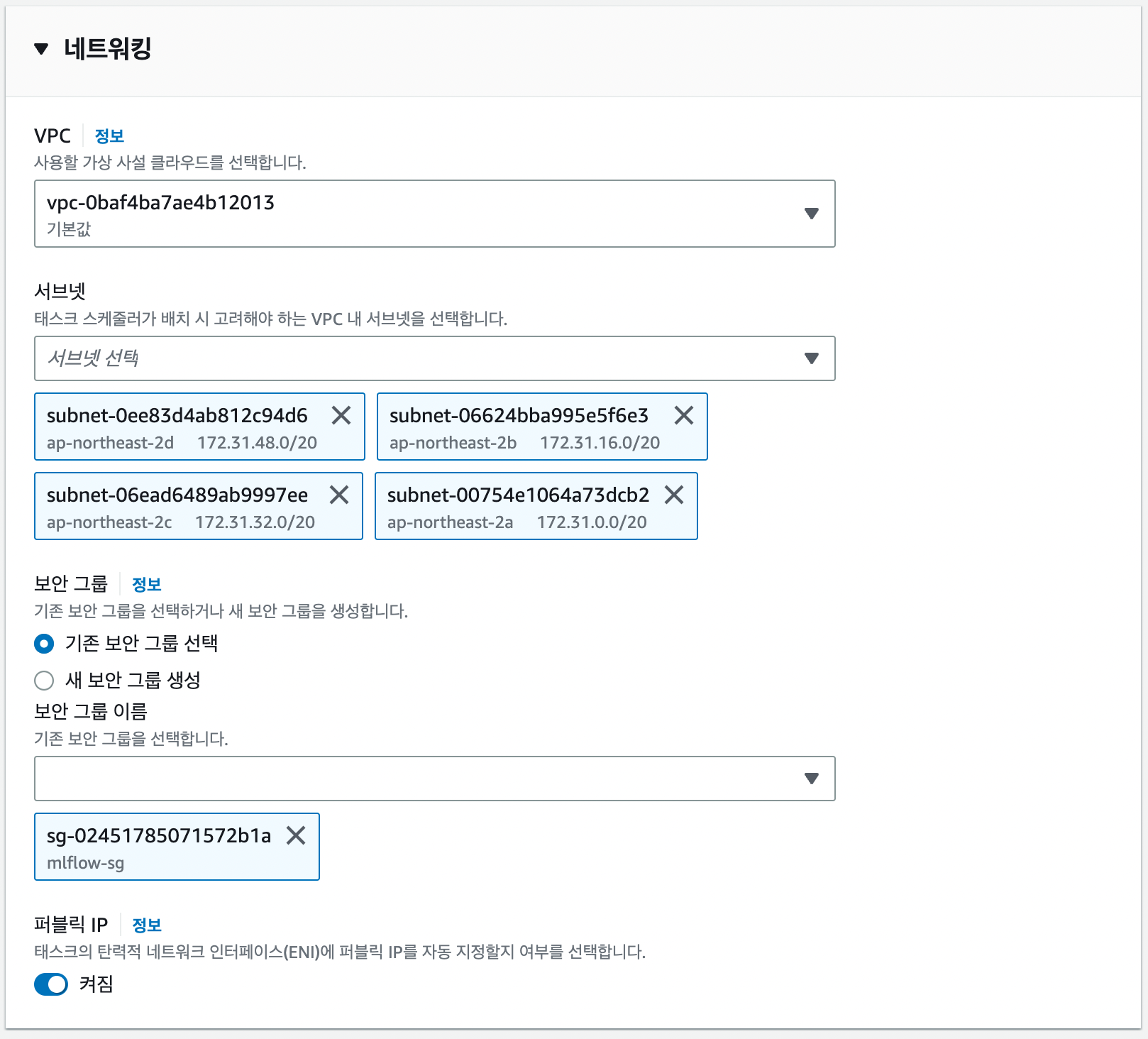
네트워킹 설정에서 보안 그룹을 위에서 생성했던 보안 그룹 선택하여 외부에서 컨테이너로 접속할 수 있고록 하고 나머지 설정은 Default로 두고 서비스를 생성하겠습니다.
다만 이렇게하면 ECS 서비스를 생성할때마다 매번 public IP가 바뀌게 됩니다. 만약 고정 IP를 사용하고 싶으신 분들은 Load Balancer와 Elastic IP를 활용하시면 됩니다. 여기서는 이대로 진행하겠습니다.
서비스가 실행되었으면 태스크의 Public IP로 접속해 보겠습니다.
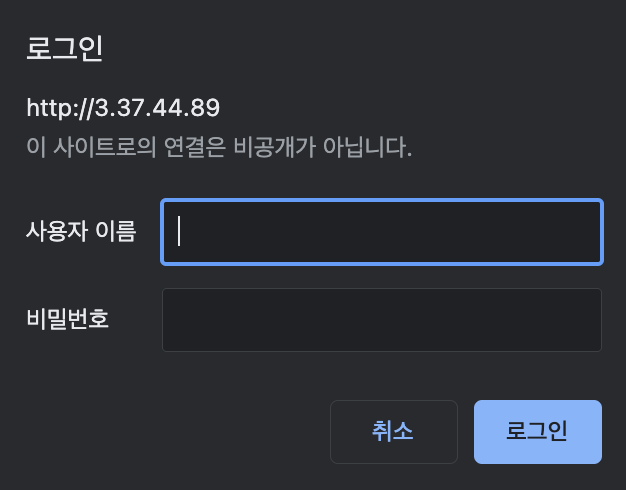
Public IP로 접속을 하게되면 Username과 Password를 입력하라고 나옵니다. htpasswd에 등록했던 유저 정보를 입력해줍니다.
 드디어 2.3.2버전의 mlflow tracking server로 접속하였습니다. mlflow 환경을 구축했으니 이제 하이퍼파라미터 튜닝 및 모델 학습에 대한 실험관리와 모델 버전관리를 해보도록 하겠습니다.
드디어 2.3.2버전의 mlflow tracking server로 접속하였습니다. mlflow 환경을 구축했으니 이제 하이퍼파라미터 튜닝 및 모델 학습에 대한 실험관리와 모델 버전관리를 해보도록 하겠습니다.
MLflow Experiments
먼저 MLflow의 experiments 기능을 활용해 보겠습니다. hugging face의 diffusers GitHub repo에 공개된 학습코드에 하이퍼파라미터 튜닝 코드와 mlflow tracking server에 로그 및 artifact를 저장하는 코드를 추가하였습니다. 코드는 포스팅 아래 Reference를 참고해 주세요.
하이퍼 파라미터 튜닝과 모델 학습에서는 다음과 같은 일을 수행합니다.
- 하이퍼 파라미터 튜닝
- Ray Tune을 활용해 리소스를 분할하여 병렬작업
- ex) 하나의 GPU에서 하나의 trial 실행
- 각 trial이 mlflow의 run으로 생성되어 loss metric 저장
- Ray Tune을 활용해 리소스를 분할하여 병렬작업
- 모델 학습
- accelerate 라이브러리를 활용한 multi-gpu 분산학습
- 하이퍼파라미터, loss, validation result(image) 저장
- onnx 변환 및 모델 artifact 저장
사용한 데이터셋은 256x256 크기의 스케치 데이터셋 입니다. 9999장의 이미지와 텍스트가 존재합니다.
example:


Hyper Parameter Tuning
하이퍼 파라미터 튜닝이 어떻게 작동하는지 ray tune 코드를 일부 살펴보겠습니다.
train_tune.py
def ray_tune(gpus_per_trial=1):
exp_name = opt.experiments_name
mlflow.set_experiment(exp_name)
def stop_fn(trial_id: str, result: dict) -> bool:
return result["loss"] != result["loss"]
tuner = tune.Tuner(
tune.with_resources(
tune.with_parameters(main),
resources={"gpu": gpus_per_trial}
),
tune_config=tune.TuneConfig(
chdir_to_trial_dir=False
),
run_config=air.RunConfig(
name="mlflow",
stop=stop_fn,
callbacks=[
MLflowLoggerCallback(
tracking_uri=mlflow.get_tracking_uri(),
experiment_name=exp_name,
save_artifact=False,
)
],
),
param_space={
"learning_rate": tune.grid_search([3e-4, 2e-4, 1e-4]),
"train_batch_size": tune.grid_search([1, 4]),
},
)
results = tuner.fit()
best_result = results.get_best_result("ema_loss", "min")
print(best_result)
Ray Tune에서는 MLflowLoggerCallback 함수를 통해 각 trial의 log metric을 mlflow tracking server run으로 생성할 수 있도록 지원합니다.
또한 각 trial에 할당할 리소스를 지정해줄 수 있습니다. 예를 들어 서버에 gpu 4개가 있을 때 trial 당 gpu 개수를 1로 설정하게 되면 4개의 trial이 병렬적으로 수행됩니다. 이때 trial당 cpu 개수를 지정하지 않으면 각 trial 에서는 ‘보유중인 CPU core 수 / trial 수’ 로 자동적으로 나뉘어 cpu를 사용하게 됩니다.
stop_fn 함수는 loss가 nan 값으로 발산했을때 해당 trial을 중지하기 위한 함수입니다. 파이썬에서 nan == nan 인 경우에 값이 False가 나오는 것을 이용하였습니다.
이제 2가지의 하이퍼 파라미터(learning_rate, train_batch_size)를 grid search 방법으로 탐색해 보겠습니다.
export MLFLOW_TRACKING_URI="<ECS 태스크 Public IP>"
export MLFLOW_TRACKING_USERNAME="<대시보드 username>"
export MLFLOW_TRACKING_PASSWORD="<대시보드 비밀번호>"
export AWS_ACCESS_KEY_ID="<IAM 사용자 Access Key>"
export AWS_SECRET_ACCESS_KEY="<IAM 사용자 Secret Key>"
먼저 클라이언트에서 mlflow tracking server와의 통신을 위한 환경변수를 설정합니다.
python train_tune.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--dataset_name="zoheb/sketch-scene" \
--dataloader_num_workers=8 \
--width=256 --height=256 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=1000 \
--learning_rate=1e-04 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--experiments_name='sketch_ray_tune' \
--seed=1337 \
--mixed_precision='fp16' \
--enable_xformers_memory_efficient_attention \
--tune \
--gpus_per_trial=1
하이퍼 파라미터 튜닝에 중요한 옵션은 아래와 같습니다.
- seed: 하이퍼 파라미터 튜닝에 있어서 가장 중요한 요소입니다. 모든 실험의 재현성이 유지되어야 정상적으로 하이퍼 파라미터를 비교할 수 있습니다.
- tune: 모델 학습이 아닌 하이퍼 파라미터 튜닝을 진행하겠다는 의미입니다.
- gpus_per_trial: 하나의 trial이 gpu를 몇 개 사용할지에 대한 옵션입니다. 보유하고있는 GPU 상황에 맞게 설정해주시면 됩니다.
result:
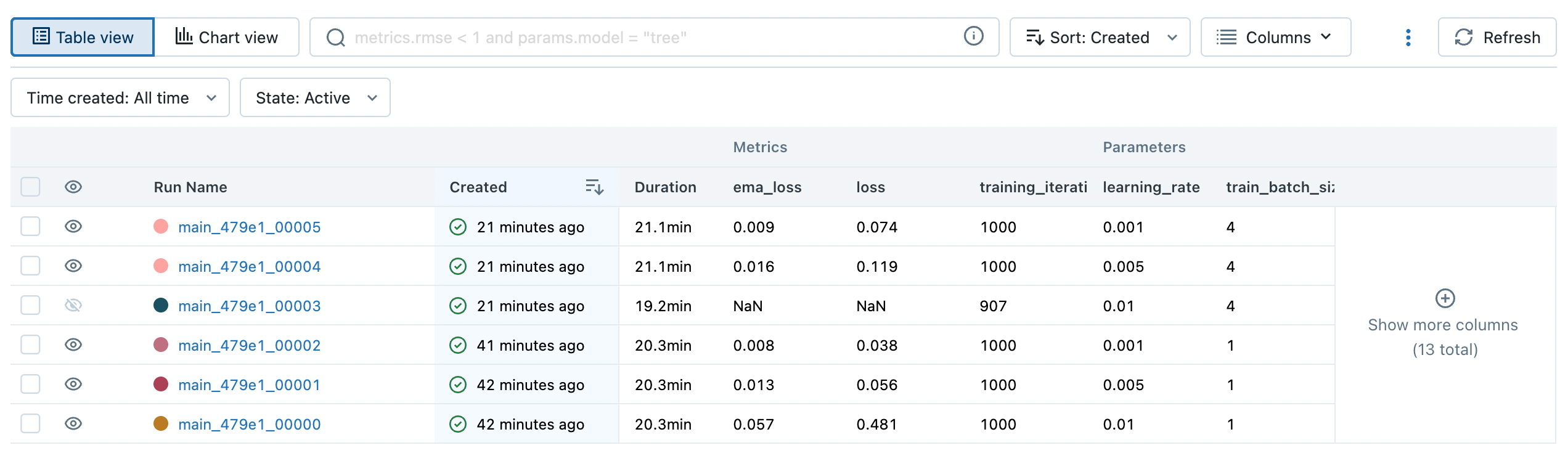
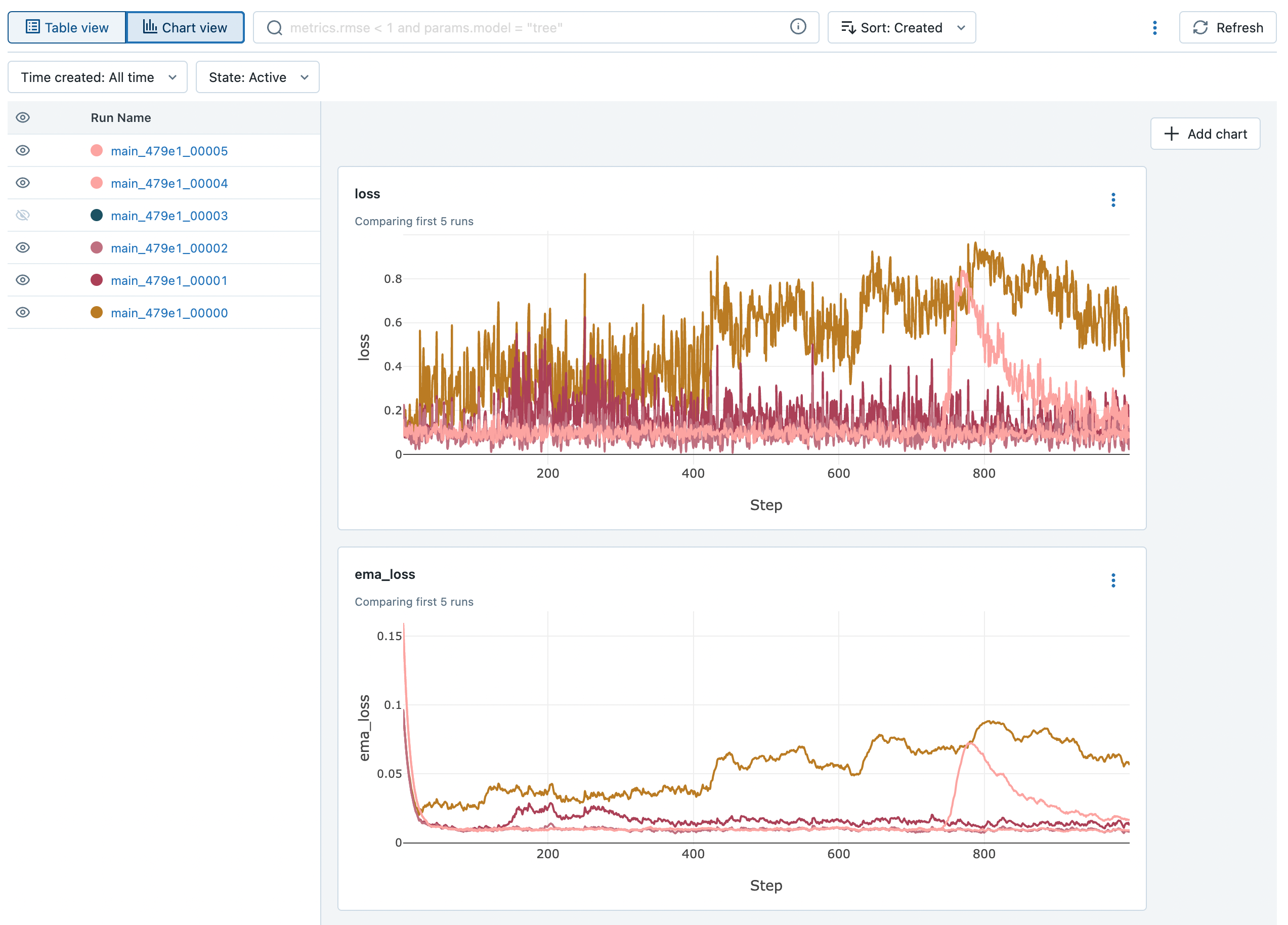
mlflow 대시보드에서는 parameter, metric을 table 혹은 chart 로 간편하게 볼 수 있습니다. 위 그림을 보았을 때 learning rate가 작을수록 loss가 안정적으로 감소하는 것을 확인할 수 있습니다.
반대로 learning_rate=0.01에 batch_size=4인 경우에는 loss가 발산하여 NaN 값이 기록되어 907 iteration에서 멈춘것이 확인됩니다. (mlflow에서는 chart view 에서 metric에 NaN값이 존재하면 그래프가 정상적으로 보이지 않기 때문에 해당 Run은 chart view 에서 제외하였습니다.)
위 그림을 자세히 보면 metric에 ema_loss라는것이 있습니다. ema는 exponential moving average의 약자로 직전의 데이터보다 최근의 데이터의 추세에 더 큰 가중치를 부여하는 방법입니다. ema는 여러 시각화 툴에서 그래프에 smoothing 효과를 주는데에 많이 사용됩니다.
mlflow도 마찬가지로 ema를 활용한 smoothing을 지원하지만 이 기능은 하나의 run에 대해서만 가능합니다. chart view에서 여러 run을 smoothing 처리하여 볼 수 없기 때문에 ema_loss를 직접 계산하여 metric으로 남겨두었습니다.
위 chart view 그림의 loss 그래프는 어떤 run이 좋고 나쁜지를 판단하기가 어렵지만 ema_loss 그래프는 쉽게 판단할 수 있습니다.
Model Training
accelerate launch --mixed_precision="fp16" train_tune.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--dataset_name="zoheb/sketch-scene" \
--dataloader_num_workers=8 \
--width=256 --height=256 --center_crop --random_flip \
--train_batch_size=2 \
--gradient_accumulation_steps=4 \
--num_train_epochs=10 \
--learning_rate=1e-03 \
--lr_scheduler="cosine" --lr_warmup_steps=500 \
--output_dir="LoRA_sketch_output" \
--experiments_name='sketch' \
--checkpointing_steps=5000 \
--validation_prompt="a man swimming in the sea" \
--validation_epochs=1 \
--num_validation_images=2 \
--seed=1337 \
--enable_xformers_memory_efficient_attention
학습에는 accelerate 라이브러리를 활용하여 multi-gpu training, mixed-precision 을 활용하겠습니다.
하이퍼파라미터 튜닝 결과를 참조하여 위와같이 값을 설정하였고 매 epoch마다 validation을 수행하도록 하였습니다.
result:
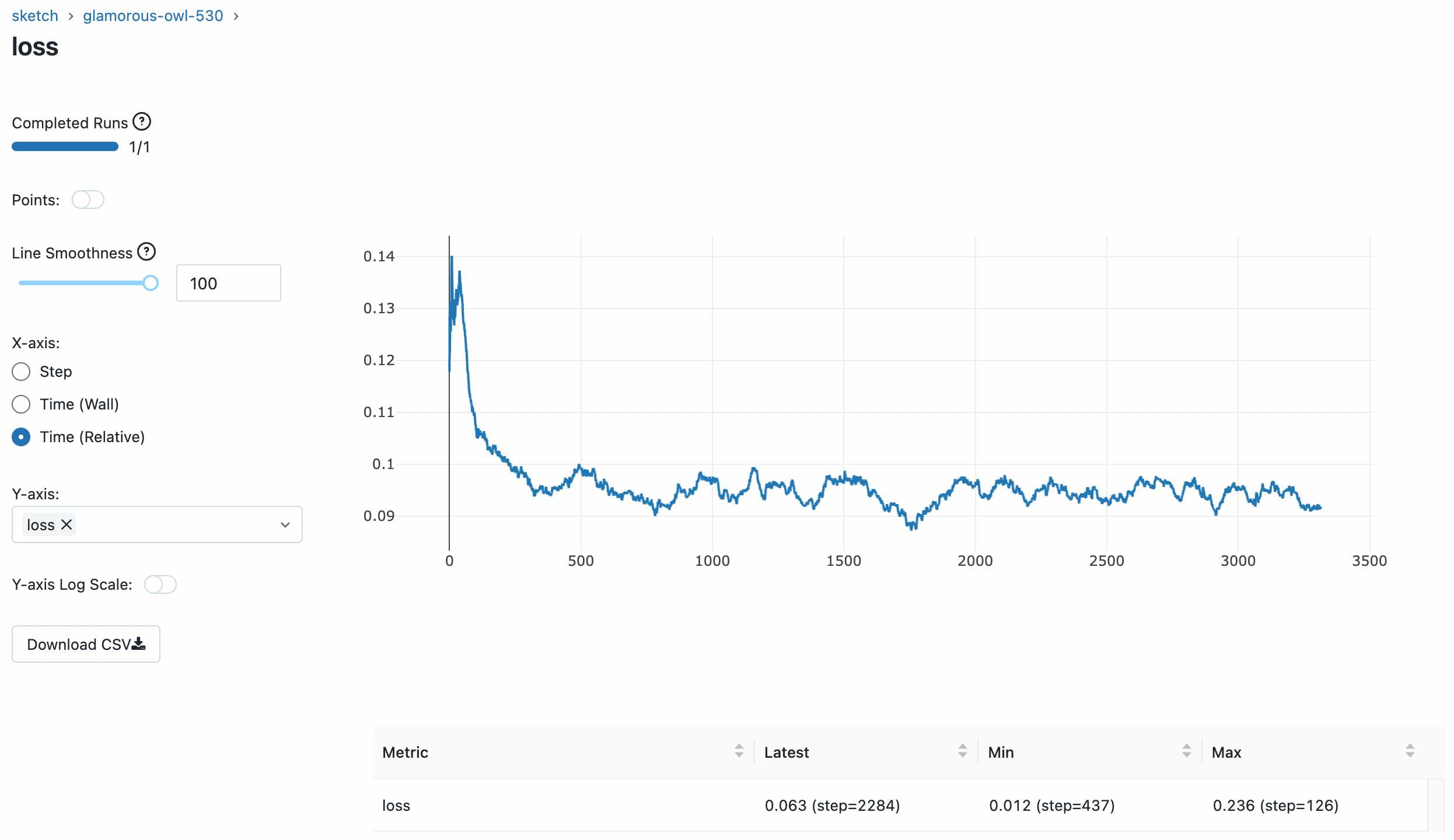
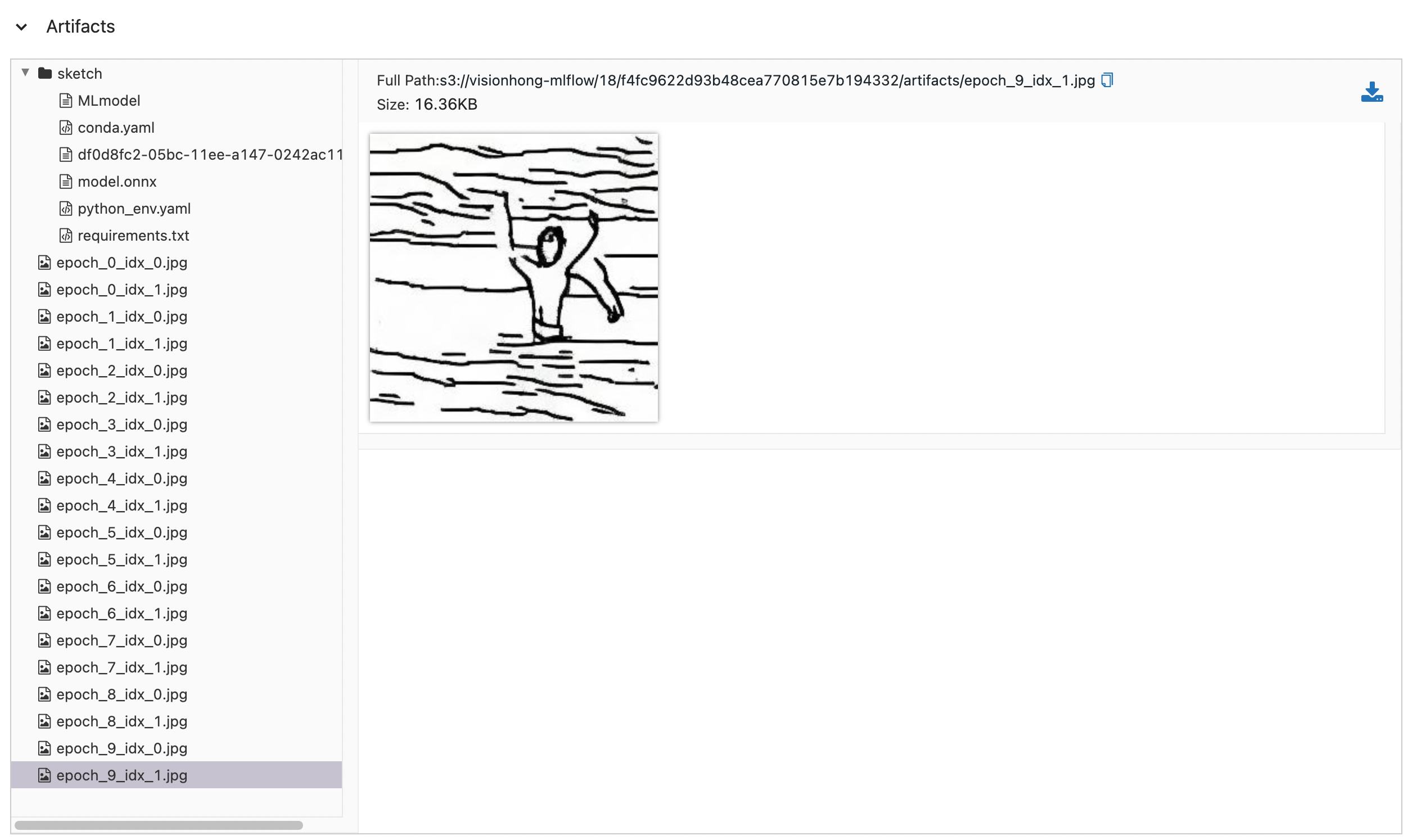
위 그림은 학습 loss 그래프와 validation 결과 이미지입니다. loss가 안정적이며 “a man swimming in the sea” 라는 프롬프트에 대한 inference 결과도 괜찮아 보입니다.
Artifacts를 보시면 validation 이미지와 모델이 저장된 것을 볼 수 있습니다. 이때 diffusers 파이프라인을 저장하지 않고 unet 모델만 저장하게 됩니다.
이유는 MLflow에서 diffusers 파이프라인을 지원하지 않기도 하고 AWS S3에 artifact를 저장하는데 굳이 학습 주체가 아닌 VAE, Text Encoder를 저장해서 돈을 더 지불할 이유가 없기 때문입니다.
또한 다양한 프레임워크, 툴과의 호환성 및 확장성을 고려하여 Unet 모델을 ONNX로 변환하도록 하였습니다.
MLflow Models
mlflow tracking server 에서는 모델 버전 관리를 할 수 있습니다. 모델을 버저닝하려면 artifact가 먼저 Experiments에 등록되어있어야 합니다.
이미 학습에서 unet 모델을 artifact로 저장해 두었기 때문에 바로 대시보드에서 모델을 버저닝 해보도록 하겠습니다.
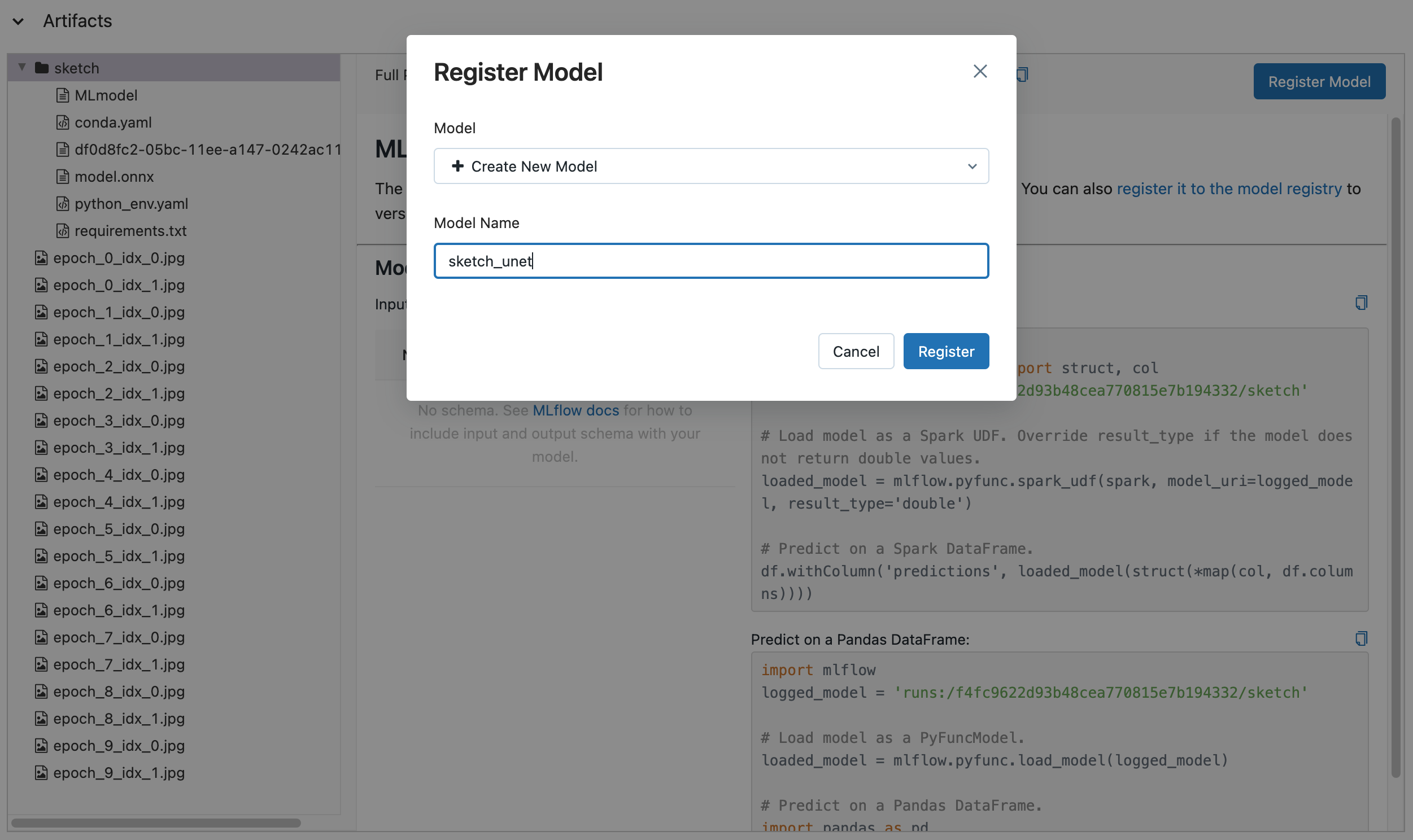
학습을 진행했던 run의 artifact를 보면 폴더가 하나 있습니다. 이 폴더를 클릭했을때 MLflow에서 이 폴더를 모델 폴더라고 인식했을때에만 우측 상단처럼 Register Model이라는 버튼이 보이게 됩니다.
버튼을 눌러서 새 이름으로 모델을 버저닝 해보겠습니다.
상단 Models를 클릭하면 방금 등록한 sketch_unet 모델이 버전1로 등록된 것을 확인할 수 있습니다.
모델 버전은 이렇게 대시보드에서 관리하거나 Python API를 활용하여 관리할 수도 있습니다. 모델 버전 등록, 모델 로드, 모델 다운로드 등 더 자세한 내용이 궁금하신 분들은 MLflow 공식문서를 참고해주세요.
END
지금까지 AWS 서비스를 활용해 mlflow tracking server를 구축하고 이미지 생성 모델 실험 및 버저닝을 하는 방법에 대해 알아보았습니다.
참고로 Mlflow v2.3.2 버전부터 transformers 를 지원하기 때문에 파이프라인 자체를 artifact로 저장할 수 있게 되었습니다. 파이프라인을 로드하여 바로 추론을 할 수 있어졌고 바로 배포를 할 수 있는상태이기 때문에 사용자 입장에서 조금 더 편해졌습니다.
추후에 diffusers 파이프라인도 지원하게 된다면 MLflow로 더 많은 기능을 활용하는 포스팅을 작성해 보겠습니다.
Reference
Leave a comment