
Detectron2 + weights and biases + multi gpu
이번 포스팅에서는 Detectron2의 mask rcnn을 이용해서 instance segmentation을 해보려고 한다.
Detectron2: A PyTorch-based modular object detection library
- Detectron2는 computer vision 분야에서 특히 detection관련 모델을 간편하게 학습 및 평가를 할 수 있도록 FAIR에서 Pytorch를 기반으로 제작한 라이브러리이다.
- Detectron2를 사용해보면서 느낀것은 모델의 다양성이 mmdetection에는 못미치지만 custom dataset에 대한 configuration및 visualization이 간편해서 사용자가 빠르게 자신의 데이터셋에 대한 성능평가를 해보고 싶을때 사용하면 좋을 것 같다고 느꼈다.
- 하지만 weights and biases를 multi gpu로 사용하면서 detectron2의 원본코드를 수정해야 했기 때문에 수많은 에러가 찾아왔다. (아직 해결하지 못한 문제가 있는데 아래에서 다루도록 하겠다.)
Dataset
사용한 데이터셋은 Astrophysics라는 장비로 찍은 공항 수하물 xray(rgb) 데이터셋을 사용하였고 annotation은 COCO format으로 되어있다.

STEP 1 : Dataset 분할 (리눅스 서버)
현재 데이터셋은 2508장의 이미지가 하나의 폴더 그리고 하나의 json file로 되어있다. Detectron2를 사용하기 위해선 데이터셋이 train, valid, test로 분할되어 있어야 하기때문에 해당 작업을 먼저 하였다.
import json
import os
import random
import cv2
from PIL import Image
from tqdm.notebook import tqdm
def split_dataset(input_json, kind_of, train_ratio, val_ratio, test_ratio, random_seed):
random.seed(random_seed)
for i in range(3):
with open(input_json[i]) as json_reader:
dataset = json.load(json_reader)
images = dataset['images']
annotations = dataset['annotations']
categories = dataset['categories']
# astrophysics:(1920, 1080),'rapiscan(1680 × 1050)','smith(1680 × 1050)
# width, height가 0으로 되어있음
for m in range(len(images)):
if kind_of[i] == 'astrophysics':
images[m]['width'] = 1920
images[m]['height']= 1080
elif kind_of[i] == 'smith':
images[m]['width'] = 1680
images[m]['height']= 1050
elif kind_of[i] == 'rapiscan':
images[m]['width'] = 1680
images[m]['height']= 1050
## 이미지 아이디를 불러와서 shuffle하고 세개의 세트로 분할 -> annotation을 한줄씩 불러서 분할된 아이디로 instance별 annotation정보를 분류시킴
image_ids = [x.get('id') for x in images]
image_ids.sort()
random.shuffle(image_ids)
num_test = int(len(image_ids) * test_ratio)
num_val = int(len(image_ids) * val_ratio)
num_train = len(image_ids) - num_val - num_test
image_ids_train, image_ids_val, image_ids_test = set(image_ids[:num_train]), set(image_ids[num_train:-num_test]), set(image_ids[-num_test:])
train_images = [x for x in images if x.get('id') in image_ids_train]
val_images = [x for x in images if x.get('id') in image_ids_val]
test_images = [x for x in images if x.get('id') in image_ids_test]
train_annotations = [x for x in annotations if x.get('image_id') in image_ids_train]
val_annotations = [x for x in annotations if x.get('image_id') in image_ids_val]
test_annotations = [x for x in annotations if x.get('image_id') in image_ids_test]
train_data = {
'images': train_images,
'annotations': train_annotations,
'categories': categories,
}
val_data = {
'images': val_images,
'annotations': val_annotations,
'categories': categories,
}
test_data = {
'images': test_images,
'annotations': test_annotations,
'categories': categories,
}
# 이미지 분할
train_filename = [x['file_name'] for x in train_data['images']]
os.makedirs(f'dataset/images/{kind_of[i]}/train', exist_ok=True)
for j in tqdm(train_filename):
!cp {kind_of[i]}/{j} dataset/images/{kind_of[i]}/train/{j}
valid_filename = [x['file_name'] for x in val_data['images']]
os.makedirs(f'dataset/images/{kind_of[i]}/valid', exist_ok=True)
for j in tqdm(valid_filename):
!cp {kind_of[i]}/{j} dataset/images/{kind_of[i]}/valid/{j}
test_filename = [x['file_name'] for x in test_data['images']]
os.makedirs(f'dataset/images/{kind_of[i]}/test', exist_ok=True)
for j in tqdm(test_filename):
!cp {kind_of[i]}/{j} dataset/images/{kind_of[i]}/test/{j}
# annotation 분할
os.makedirs(f'dataset/annotations/{kind_of[i]}', exist_ok=True)
output_train_json = os.path.join(f'dataset/annotations/{kind_of[i]}', 'train.json')
output_val_json = os.path.join(f'dataset/annotations/{kind_of[i]}', 'val.json')
output_test_json = os.path.join(f'dataset/annotations/{kind_of[i]}', 'test.json')
print(f'write {output_train_json}')
with open(output_train_json, 'w') as train_writer:
json.dump(train_data, train_writer)
print(f'write {output_val_json}')
with open(output_val_json, 'w') as val_writer:
json.dump(val_data, val_writer)
print(f'write {output_test_json}')
with open(output_test_json, 'w') as test_writer:
json.dump(test_data, test_writer)
- 사실 장비는 3개가 있는데 해당 글에서는 astrophysics만 다루고있다. 위 코드는 세개의 장비를 한번에 분할하는 코드이다.
- 22번째 줄부터 하는 작업은 annotation의 images에서 width와 height가 0으로 되어있어서 이미지 사이즈에 맞게 수정하는 작업이다. (이미지 사이즈가 정확하지 않으면 detectron2에서 에러가 난다.)
- coco annotation을 분할해야하기 때문에 조금 지저분하지만 잘 작동한다.
STEP 2 : 도커 컨테이너 환경구축
conda 가상환경 대신 도커 컨테이너를 사용하였다. detectron2 도커 컨테이너를 만들기 위해서는 docker file이 필요하다. docker file은 detectron2의 공식 github를 clone하여 사용하였다.
docker file을 도커 이미지로 변환하기 전에 먼저 docker file을 아래 사진과 같이 수정하였다. 수정한 이유는 학습을 주피터랩에서 사용하기 위함이다.
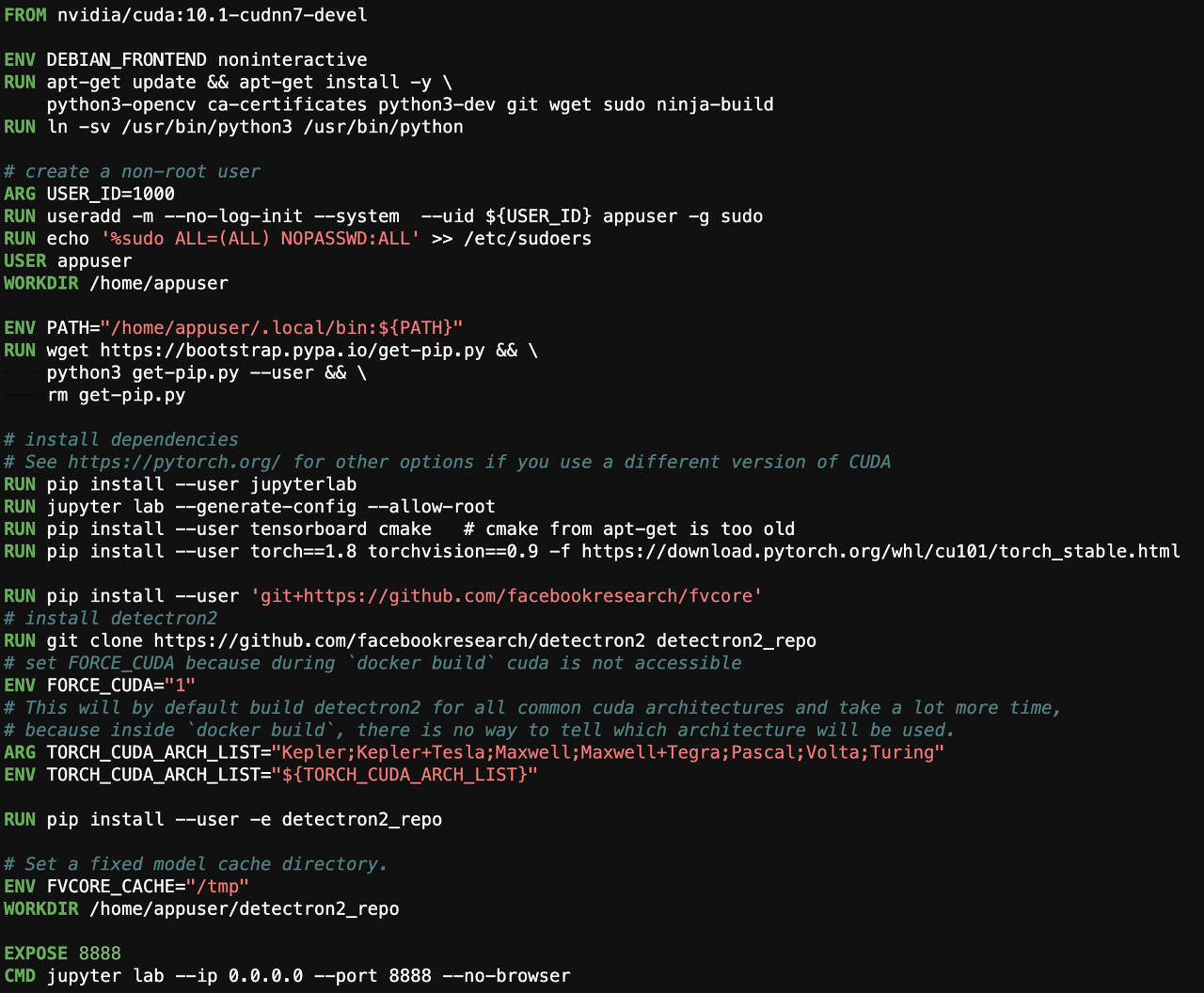
dockerfile을 수정한 뒤에 터미널에서 도커 이미지로 변환을 한다.
sudo docker build -t detectron2:v0 .
도커 이미지를 만들었으면 도커 컨테이너를 띄운다.
sudo nvidia-docker run --ipc=host --name -it --restart always -p 8000:8888 detectron2:v0
- 주피터를 사용하기 위해 사용할 포트(8000)를 입력한다.
- --ipc=host를 사용하면 주피터의 메모리 관련 에러를 방지할 수 있다.
STEP 3 : 데이터셋 복사
현재 데이터셋은 서버안에 저장되어있다. 이 데이터셋을 컨테이너로 복사 해야한다.
sudo docker cp [서버 데이터셋경로] [컨테이너아이디]:/home/appuser/detectron2_repo/datasets
- 서버에 있는 데이터셋(폴더)을 방금 만든 컨테이너의 detectron2의 datasets폴더로 복사한다는 의미
STEP 4 : Import Libraries
cd /home/appuser/detectron2_repo
# Some basic setup:
# Setup detectron2 logger
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
from tqdm import tqdm
import matplotlib.pyplot as plt
# from google.colab.patches import cv2_imshow
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.engine import DefaultTrainer, DefaultPredictor, launch
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer, ColorMode
from detectron2.data import MetadataCatalog, DatasetCatalog
from detectron2.engine.hooks import HookBase
import wandb, yaml
wandb.login()
- 첫번째 줄을 통해 컨테이너 detectron2 경로로 이동한다.
- Import 하기전에 pip install wandb –upgrade 필요
STEP 5 : Detectron2 데이터셋 정의
from detectron2.data.datasets import register_coco_instances
register_coco_instances("train_dataset", {}, "datasets/xray/annotations/astrophysics/train.json", "datasets/xray/images/astrophysics/train")
register_coco_instances("val_dataset", {}, "datasets/xray/annotations/astrophysics/val.json", "datasets/xray/images/astrophysics/valid")
register_coco_instances("test_dataset", {}, "datasets/xray/annotations/astrophysics/test.json", "datasets/xray/images/astrophysics/test")
- 하이퍼 파라미터는 앞에서 부터 변수명, 메타정보, annotation path, data path 이다.
- 메타정보는 굳이 쓰지 않아도 되며 해당 모듈은 detectron2에서 coco format으로 작성된 annotation을 위해 제공한다.
STEP 6 : Data Visualization
import random
import matplotlib.pyplot as plt
my_dataset_train_metadata = MetadataCatalog.get("train_dataset")
dataset_dicts = DatasetCatalog.get("train_dataset")
for d in random.sample(dataset_dicts, 4):
img = cv2.imread(d["file_name"])
v = Visualizer(img[:, :, ::-1], metadata=my_dataset_train_metadata, scale=0.5)
v = v.draw_dataset_dict(d)
plt.figure(figsize = (22, 14))
plt.imshow(cv2.cvtColor(v.get_image()[:, :, ::-1], cv2.COLOR_BGR2RGB))
plt.show()
output:
STEP 7 : wandb sweep을 위한 파라미터 정의
sweep_config = {
'method': 'bayes' # random, grid등 사용 가능
}
metric = { # method를 bayes로 사용한다면 반드시 metric이 정의되어야 한다.
'name': 'total_loss', # name은 학습코드에서 log로 지정한 이름과 같아야 함 (total_loss는 detectron2/engine/train_loop.py 파일에서 run_step 함수에 log를 찍어놓음)
'goal': 'minimize'
}
sweep_config['metric'] = metric
parameters_dict = {
'learning_rate': {
'distribution': 'uniform', # uniform distribution 즉 균둥분포로 lr을 뽑겠다는 의미
'min' : 0,
'max' : 0.001
},
'IMS_PER_BATCH': {
'values': [2, 4, 8]
},
'iteration': {
'values': [300, 1000, 1500, 5000]
},
'BATCH_SIZE_PER_IMAGE' : {
'values': [32, 64, 128, 256]
},
'model': {
'value' : 'COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml'
}
}
sweep_config['parameters'] = parameters_dict
import pprint
pprint.pprint(sweep_config)
output:

# wandb sweep 등록하고 해당 id를 변수에 담음
sweep_id = wandb.sweep(sweep_config, project='xray')
STEP 8 : Define configuration & train func
def init_cfg(config):
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(config.model))
cfg.DATASETS.TRAIN = ("train_dataset",) # 위에서 정의한 train dataset 변수
cfg.DATASETS.TEST = () # validation용인데 sweep에서는 사용하지 않았음
cfg.DATALOADER.NUM_WORKERS = 4
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(config.model)
cfg.SOLVER.IMS_PER_BATCH = config.IMS_PER_BATCH
cfg.SOLVER.BASE_LR = config.learning_rate
cfg.SOLVER.MAX_ITER = config.iteration # 특이하게 epoch대신 iteration으로 학습기간을 정함
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.SOLVER.LR_SCHEDULER_NAME = "WarmupCosineLR" # WarmupCosineLR or WarmupMultiStepLR
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = config.BATCH_SIZE_PER_IMAGE
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 13
cfg.OUTPUT_DIR = 'output/astrophysics'
return cfg
def train(config=None):
with wandb.init(project='xray', config=config) as run:
config = wandb.config
cfg = init_cfg(config)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False) # 첫번째 학습 후에 학습을 좀더 하고싶을 때 True
trainer.train()
STEP 9 : Hyper parameter tuning
wandb.agent(sweep_id, train, count=10) # count: 실험 횟수
output:
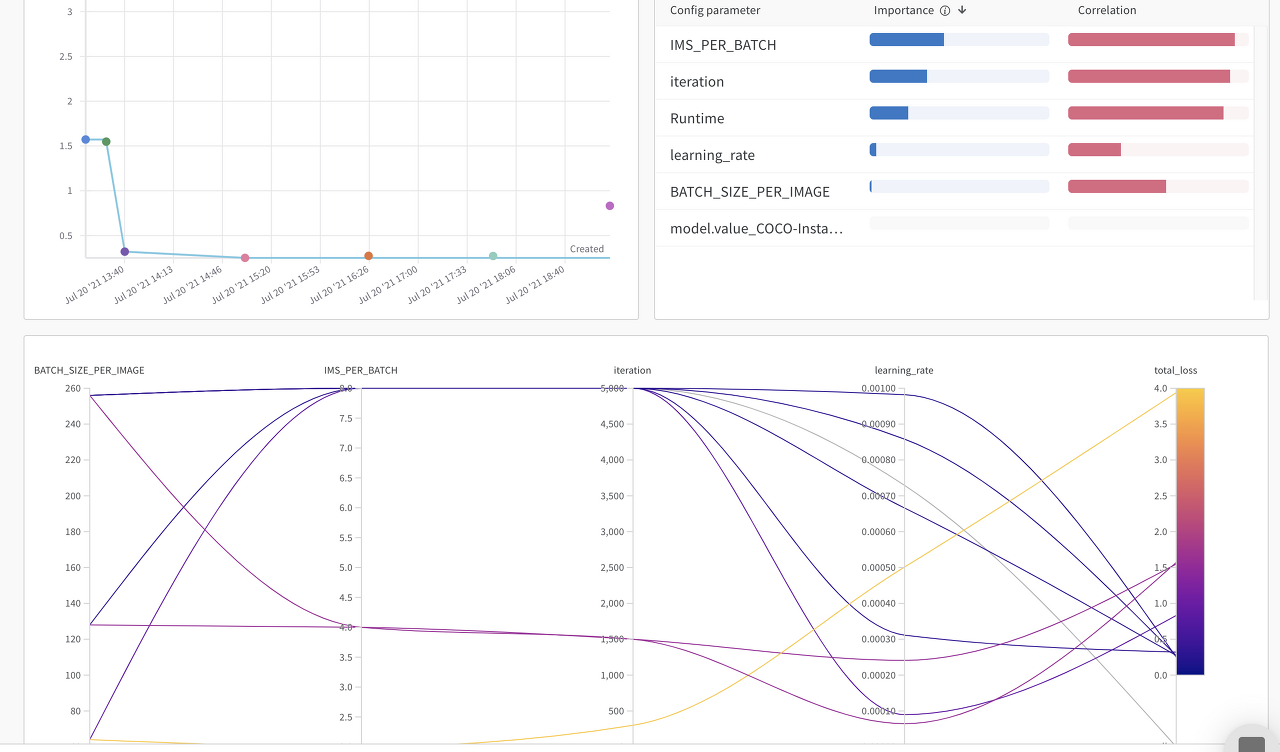
- parameter 서칭 도중에 실수로 kernel을 끊어버려서 10번중 8번의 기록만 남아있다.
- 아래 그래프의 오른쪽을 보면 total loss가 있는데 이중에서 제일 낮은 값 즉 loss가 가장 낮을때의 parameter를 선택할 수있다.
- 선택된 하이퍼 파라미터들은 아래와 같다.
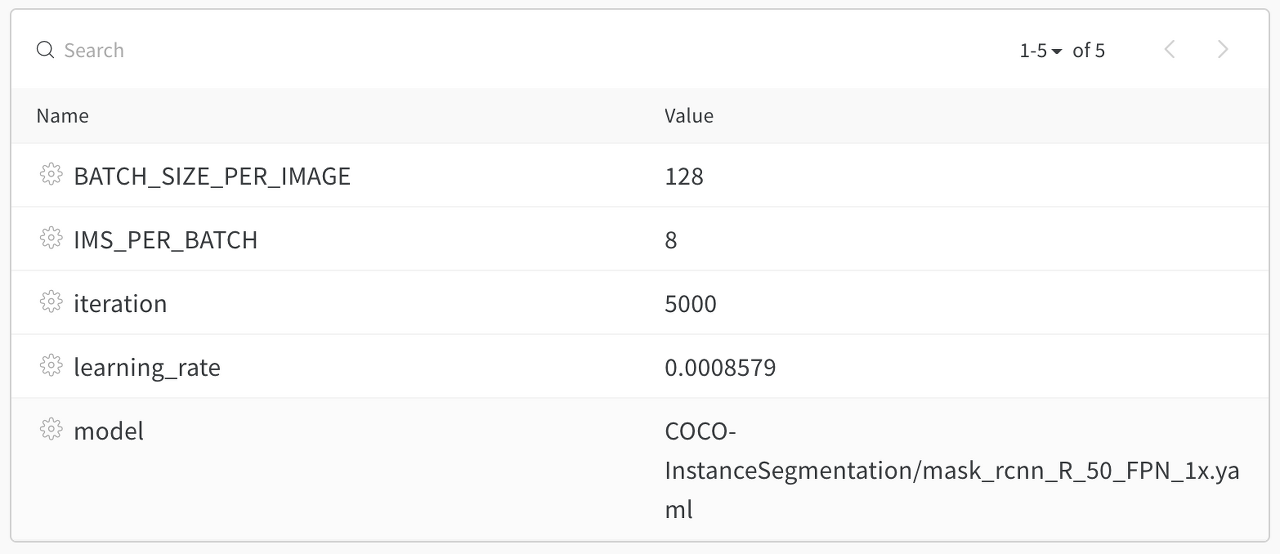
STEP 10 : Multi GPU Training
하이퍼 파라미터를 결정했으니 이제 제대로 모델을 학습만 하는 일만 남았다. custom dataset에 대한 multi gpu training을 하기 위해서는 먼저 detectron2 tools 폴더의 train_net.py 파일을 수정해야 한다.
def main(args):
register_coco_instances("train_dataset", {}, "datasets/xray/annotations/astrophysics/train.json", "datasets/xray/images/astrophysics/train")
register_coco_instances("val_dataset", {}, "datasets/xray/annotations/astrophysics/val.json", "datasets/xray/images/astrophysics/valid")
register_coco_instances("test_dataset", {}, "datasets/xray/annotations/astrophysics/test.json", "datasets/xray/images/astrophysics/test")
cfg = setup(args)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
cfg_wandb = yaml.safe_load(cfg.dump())
wandb.init(project='xray', name='smith', config=cfg_wandb, sync_tensorboard=True)
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if cfg.TEST.AUG.ENABLED:
res.update(Trainer.test_with_TTA(cfg, model))
if comm.is_main_process():
verify_results(cfg, res)
return res
"""
If you'd like to do anything fancier than the standard training logic,
consider writing your own training loop (see plain_train_net.py) or
subclassing the trainer.
"""
trainer = Trainer(cfg)
# trainer = MyTrainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
- train_net.py 파일의 main 함수에서 jupyter에서의 custom dataset을 여기서 새로 지정해준다. (1~3줄 코드)
- log를 wandb에 남기기 위해서 init을 해준다. (9~10줄 코드)
- 위와같은 작업을 하는 이유는 train_net.py의 직접실행 코드(if __name__ == ”__main__”:)부분을 보면 알 수 있다.
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)
- 위 코드를 보면 launch라는 함수에 main함수를 넣고 gpu와 machine의 개수를 묻는 것으로 보아 launch는 multi gpu가 있다면 사용가능하게 만들어주는 일을 하는 것 을 알 수 있다.
- 하지만 해당 코드만 주피터로 빼와서 실행하려 했는데 혼자서는 해결되지 않는 에러가 발생하였다.
- 이런 문제 때문에 sweep(하이퍼파라미터 튜닝)을 진행할 때 single gpu만 사용할 수 밖에 없었다. sweep을 하기 위해서는 train 함수가 파라미터로 들어가야 하는데 저 launch함수안에 train코드가 있어서 어떻게 접근해야 할지 감이오지 않았다.
- train_net.py 파일을 수정했다면 주피터로 돌아와 아래 코드를 통해 Multi gpu training을 할 수 있다.
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml'))
cfg.DATASETS.TRAIN = ("train_dataset",)
cfg.DATASETS.TEST = ("val_dataset",) # validataion 사용
cfg.TEST.EVAL_PERIOD = 500 # 5000 iteration중에서 500번마다 validation 수행
cfg.DATALOADER.NUM_WORKERS = 4
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml')
cfg.SOLVER.IMS_PER_BATCH = 8
cfg.SOLVER.BASE_LR = 0.0008579
cfg.SOLVER.MAX_ITER = 5000
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.SOLVER.LR_SCHEDULER_NAME = "WarmupCosineLR" # WarmupCosineLR or WarmupMultiStepLR
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 13
cfg.OUTPUT_DIR = 'output/astrophysics/train'
cfg_file = yaml.safe_load(cfg.dump())
with open('configs/astrophysics.yaml', 'w') as f:
yaml.dump(cfg_file, f)
!python tools/train_net.py --num-gpus 4 --config-file configs/astrophysics.yaml
output:

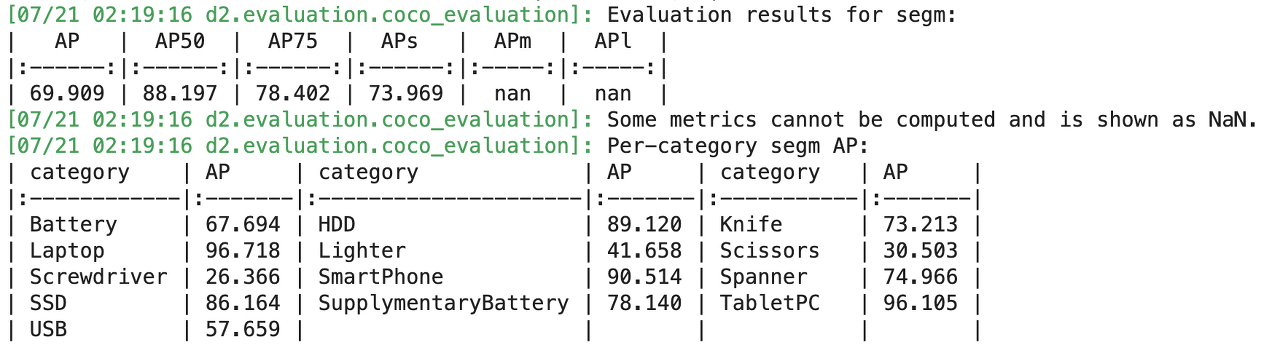
- 마지막 validation 부분의 출력을 가져왔는데 데이터수가 적은것 치고는 그리 나쁘지 않은 결과가 나왔다.
- 학습시간은 4개의 GPU(Tesla v100)으로 22분정도 소요되었다.
STEP 11 : Evaludation
1) Metric
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator("test_dataset", cfg, False, output_dir="./output/astrophysics")
val_loader = build_detection_test_loader(cfg, "test_dataset")
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
inference_on_dataset(trainer.model, val_loader, evaluator)
output:

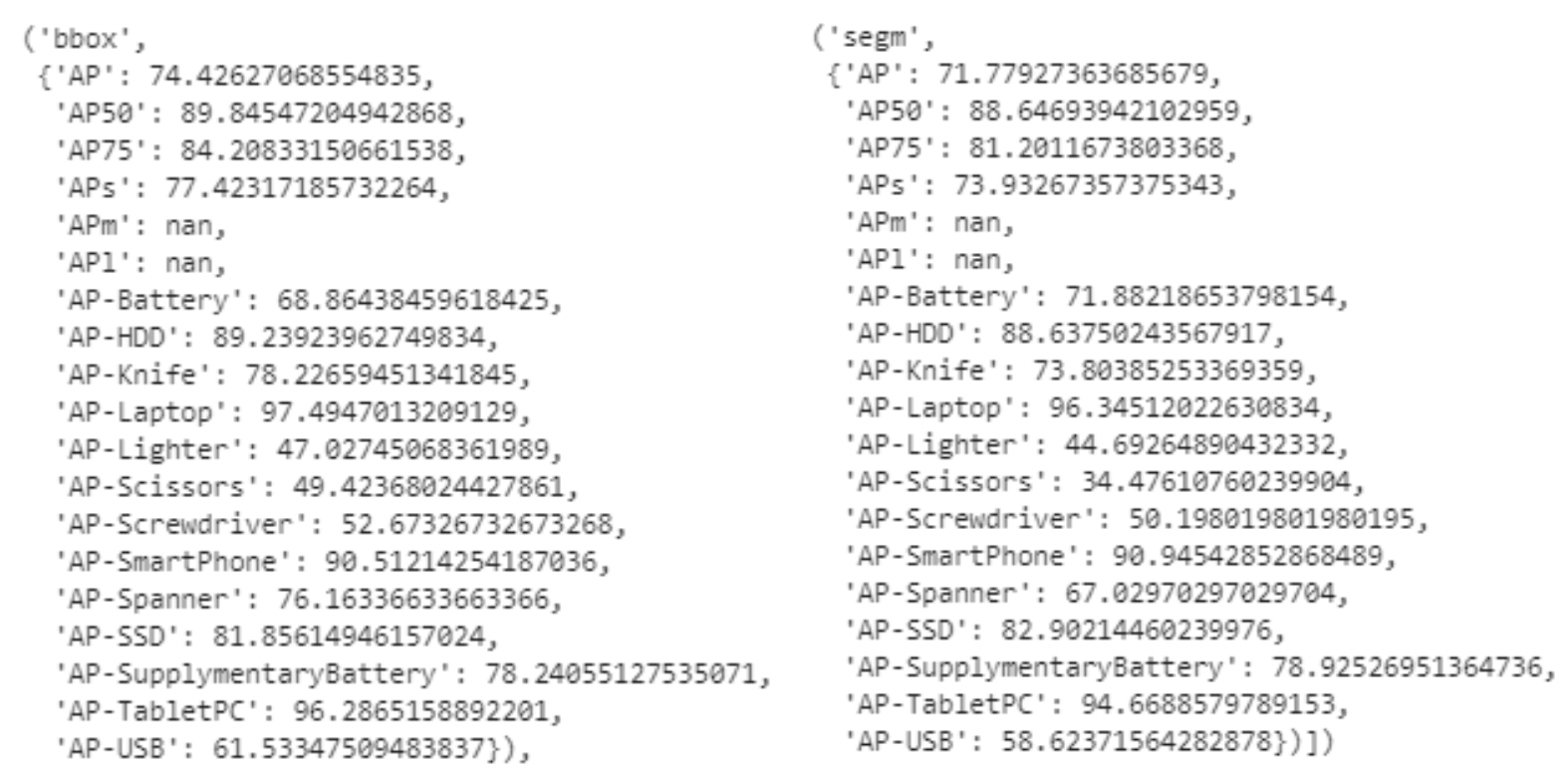
2) Visualization
def get_predictor(cfg, model_name: str):
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, model_name)
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set the testing threshold for this model
cfg.DATASETS.TEST = ("test_dataset",)
predictor = DefaultPredictor(cfg)
return predictor
def visualise_prediction(predictor, d: str = "test_dataset"):
my_dataset_test_metadata = MetadataCatalog.get(d)
dataset_dicts = DatasetCatalog.get(d)
for idx, d in enumerate(random.sample(dataset_dicts, 7)):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=my_dataset_test_metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW
)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
# fig.add_subplot(3, 1, idx+1)
plt.figure(figsize = (18, 12))
plt.imshow(cv2.cvtColor(v.get_image()[:, :, ::-1], cv2.COLOR_BGR2RGB))
plt.show()
predictor = get_predictor(cfg, "model_final.pth")
visualise_prediction(predictor, "test_dataset")
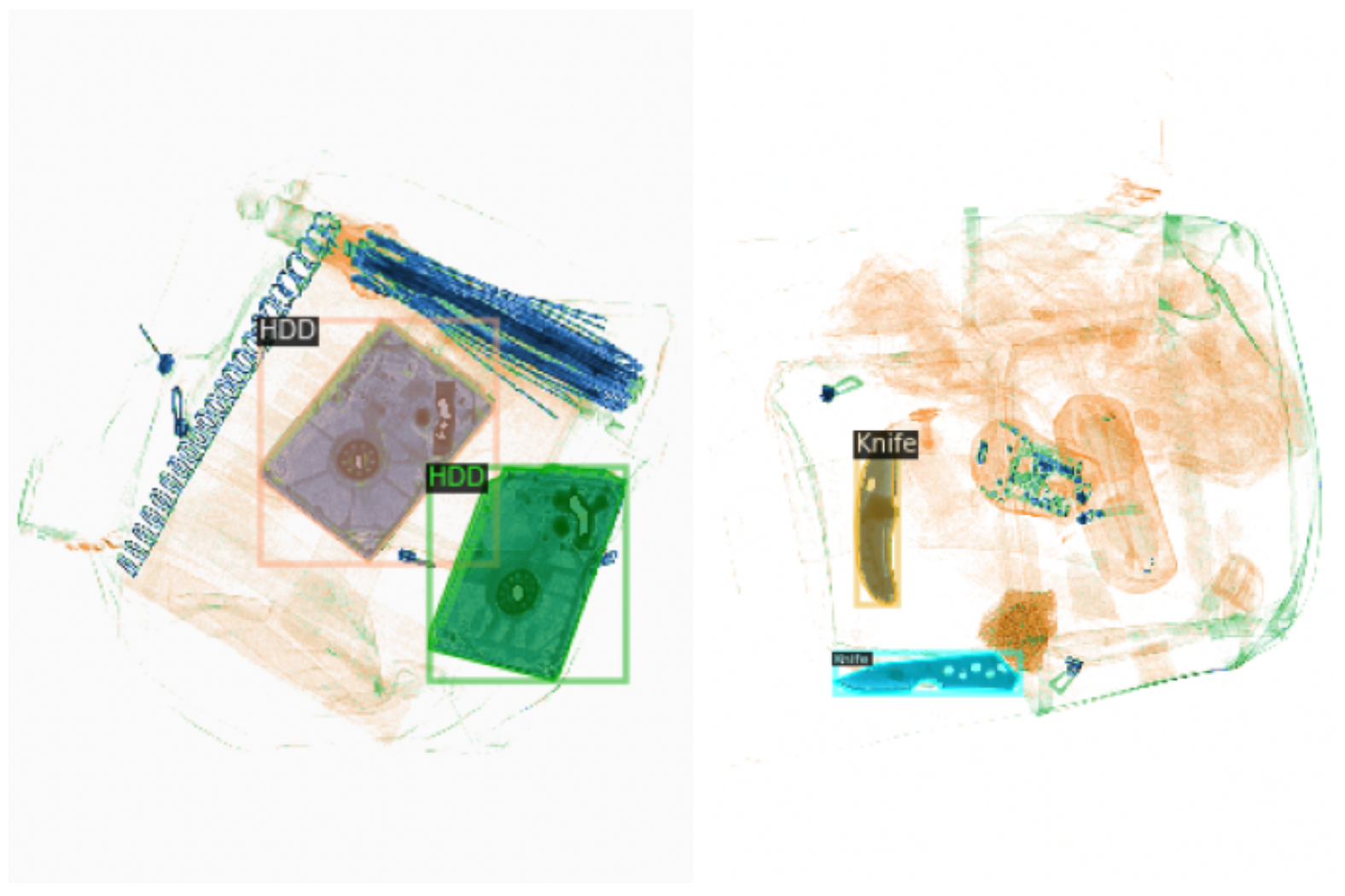
- 3번째 줄 코드에서 Threshold는 최종 하이퍼 파라미터로 Object Detection에서의 confidence와 비슷한 역할을 한다.
- 즉 최종 예측값을 threshold값으로 결정 (0.5의 값을 선택했기 때문에 아래 오른쪽 그림에서 Knife가 0.61로 visualization에 포함 되었다.)

End
오늘은 detectron2를 활용해서 custom dataset을 instance segmentation을 해 보았다. 아직 성능을 높일 수 있는 방법이 많고(모델변경, augmentation추가 등) 특히 Multi GPU로 weights and biases의 sweep을 사용할 수 있도록 하는것을 목표로 detectron2를 조금 더 파헤쳐야 할 것 같다.
Keep going
Reference
Leave a comment