
Test Time Augmentation(TTA)
Test Time Augmentation(이하 TTA) 이란 말 그대로 일반적인 train에서의 augmentation이 아닌 test 단계에서 augmentation을 수행하는 것으로 각 Augmentation된 이미지의 예측값을 평균내어 최종 예측을 내는것을 말한다.
오늘은 이 Test Time Augmentation에 대해 간단히 포스팅하려고 한다.
Why use TTA?
- TTA는 일종의 Ensemble 기법이다.
- Ensemble이란 일반적으로 어떤 데이터에 대해 여러 모델의 예측결과를 평균내어 편향된 데이터를 억제하는 역할을 함으로써 정확도를 높이는 데에 사용된다.
- 이와 마찬가지로 이미지 task에서 예측을 할 데이터의 조도가 어둡거나 밝은 데이터, 객체가 작은 데이터 등과 같이 편향된 데이터가 있을때 여러 Augmentation 기법을 적용해 평균을 내게 되면 그냥 모델의 output을 예측으로 사용할때 보다 일반적으로 더 높은 성능을 보인다.
- 결국 TTA는 모델의 정확도가 중요할 때(Competetion과 같은 상황) 사용하면 좋다.
Pytorch Implementation
Test Time Augmentation을 하드코딩으로 직접 할수도 있지만 TTA를 위한 ttach 라이브러리가 있어서 사용해보았다.
import torch
import ttach as tta
import timm
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import cv2
image_path = "../dogs/Golden retriever/dog1.jpg"
image = np.array(Image.open(image_path)) / 255 # 이미지를 읽고 min max scaling
image = cv2.resize(image, (384, 384)) # Vision Transformer base model input size
image = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0).to(torch.float32)
print(image.shape)
transforms = tta.Compose(
[
tta.HorizontalFlip(),
tta.Rotate90(angles=[0, 90]),
# tta.Scale(scales=[1, 2]),
# tta.FiveCrops(384, 384),
tta.Multiply(factors=[0.7, 1]),
]
)
model = timm.create_model("vit_base_patch16_384", pretrained=True)
# model = timm.create_model("seresnet50", pretrained=True)
imagenet_labels = dict(enumerate(open('classes.txt'))) # ImageNet class name
fig = plt.figure(figsize=(20, 20))
columns = 3
rows = 3
for i, transformer in enumerate(transforms): # custom transforms
augmented_image = transformer.augment_image(image)
output = model(augmented_image)
predicted = imagenet_labels[output.argmax(1).item()].strip()
augmented_image = np.array((augmented_image*255).squeeze()).transpose(1, 2, 0).astype(np.uint8)
fig.add_subplot(rows, columns, i+1)
plt.imshow(augmented_image)
plt.title(predicted)
plt.show()
tta.Compose() 안에 Image Transform 기법을 넣으면 모든 경우의 수로 output을 내게 된다.
| number | 밝기 | Horizontal Flip | Rotate 90° |
|---|---|---|---|
| 1 | 0.7 | X | X |
| 2 | 1 | X | X |
| 3 | 0.7 | X | O |
| 4 | 1 | X | O |
| 5 | 0.7 | O | X |
| 6 | 1 | O | X |
| 7 | 0.7 | O | O |
| 8 | 1 | O | O |
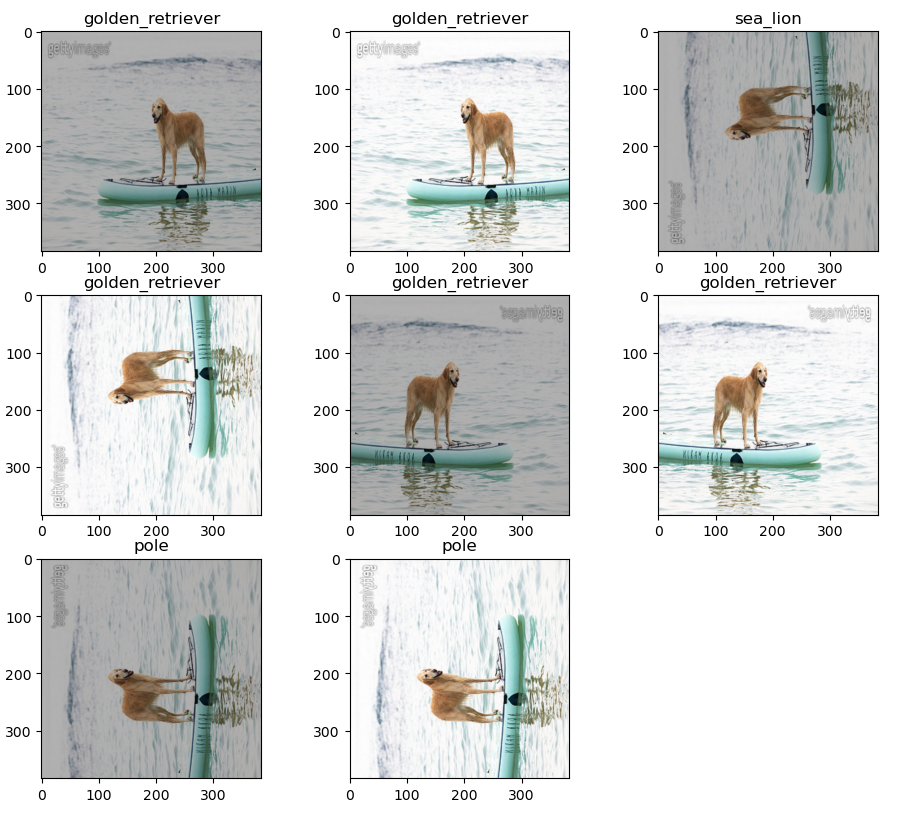
output
- golden_retriever : 5
- pole : 2
- sea_lion : 1
- result : golden_retriever
output을 보면 알 수 있듯이 다 같은 골든 리트리버이지만 이미지의 형태에 따라 모델은 다른 예측을 내기도 한다. 특히 편향된 데이터들에 대해 이런일이 자주 발생을 하게되는데 이때 TTA를 사용하게 되면 그 편향데이터에 대한 output을 조금 보정해줄 수 있다.
하지만 TTA를 사용했을때 시간에 대한 cost가 요구되기때문에 상황에 맞게 사용하면 좋을 것 같다.
End
오늘은 Test Time Augmentation에 대해 알아보았다. 이번 포스팅에서 학습결과에 대해 비교까지는 해보지 않았는데 다음에 정확도를 높여야 하는 상황에서 사용해보고 결과에 대해 리뷰할 예정이다.
keep going
Reference
- ttach library - https://github.com/qubvel/ttach
Leave a comment