
[블로그 리뷰] Self-supervised learning: The dark matter of intelligence
이번 포스팅에서는 Meta AI의 VP인 Yann LeCun님이 21년 3월에 작성한 블로그를 번역하면서 필자의 생각과 함께 정리해 보려고 한다.
Self-supervised learning: The dark matter of intelligence
최근 몇년동안 AI분야는 신중하게 라벨링된 거대한 양의 데이터로부터 학습하는 방식의 AI process가 엄청난 발전을 이루었다. Supervised-learning으로 학습된 모델은 학습된 task에 대해 매우 잘 작동하게 된다. 하지만 AI 분야가 Supervised-learning만으로 나아갈 수 있는 범위에는 한계가 있다.
Supervised-learning은 라벨링된 방대한 데이터로부터 학습을 하기 때문에 정말로 ‘지능적인 모델’이 아니고 AI라는 이름에 걸맞지 않는다. 현실적으로 존재하는 모든 데이터를 라벨링한다는 것은 불가능하다. 더불어 라벨링 작업이 충분하지 않거나 어려운 task들도 많이 있다. 라벨링된 데이터로 학습된 것 이상으로 현실에 대한 깊은 이해를 얻게 된다면 인간 수준의 지능에 더 가까운 AI를 만들 수 있을 것이다.
태어나서부터 우리는 관찰을 통해 세상이 어떻게 작동하는지 배우게된다. 예를들어 어린 아이들에게 소 그림을 몇개만 보여준다면 아이들은 현존하는 모든 소를 거의 알아볼 수 있게 된다. 하지만 Supervised-learning으로 학습된 모델은 소이미지에 대한 많은 데이터가 필요하며 해변에 소가 누워있는 것과 같은 비정상적인 상황에서는 여전히 소를 분류하지 못할 수 있다. 요약하자면 인간은 세상이 어떻게 작동하는지에 대해 이전에 습득한 배경지식, 가설, 상식에 의존할 수 있다는 것이다.
어떻게 해야 기계를 인간처럼 작동하게 할 수 있을까?

우리는 Self-supervised learning이 그러한 배경지식을 구축하고 상식의 한 형태에 근접하는 가장 유망한 방법중 하나라고 믿는다.
Self-supervised learning을 통해 AI 시스템은 훨씬 더 많은 데이터를 학습할 수 있으며, 이는 세상의 일반적이지 않은 상황의 패턴을 인식하고 이해하는데 중요한 역할을 한다. Self-supervised learning은 오랫동안 자연어처리 분야를 발전시키는데 큰 기여를 하였다. (Collobert-Weston 2008 model, Word2Vec, GloVE, fastText, and, more recently, BERT, RoBERTa, XLM-R, and others.) Self-supervised learning으로 학습된 모델은 Supervised-learning으로 학습된 모델보다 훨씬 더 높은 성능을 보여준다.
오늘, 우리는 Self-supervised learning이 AI의 다음 시대를 여는데 도움이 될 수 있는 이유에 대한 정보를 공유하려고 한다.
1. Self-supervised learning is predictive learning
Self-supervised learning은 데이터의 기본구조를 활용하여 데이터 자체에서 supervisory signal을 얻는다. 일반적으로 input의 특정 부분을 숨기고 이것을 예측하는 방법을 사용한다. 예를들어 자연어 처리에서는 문장의 일부를 숨기고 남아있는 단어들을 통해 숨겨진 단어를 예측하는 방식이 있다. 또한 최근의 영상을 통해 과거나 미래를 숨기고 그것을 예측하는 방법도 있다. Self-supervised learning은 데이터 자체의 구조를 사용하기 때문에 라벨에 의존하지 않고 big dataset 전반에 걸쳐 다양한 supervisory signal을 사용할 수 있다.
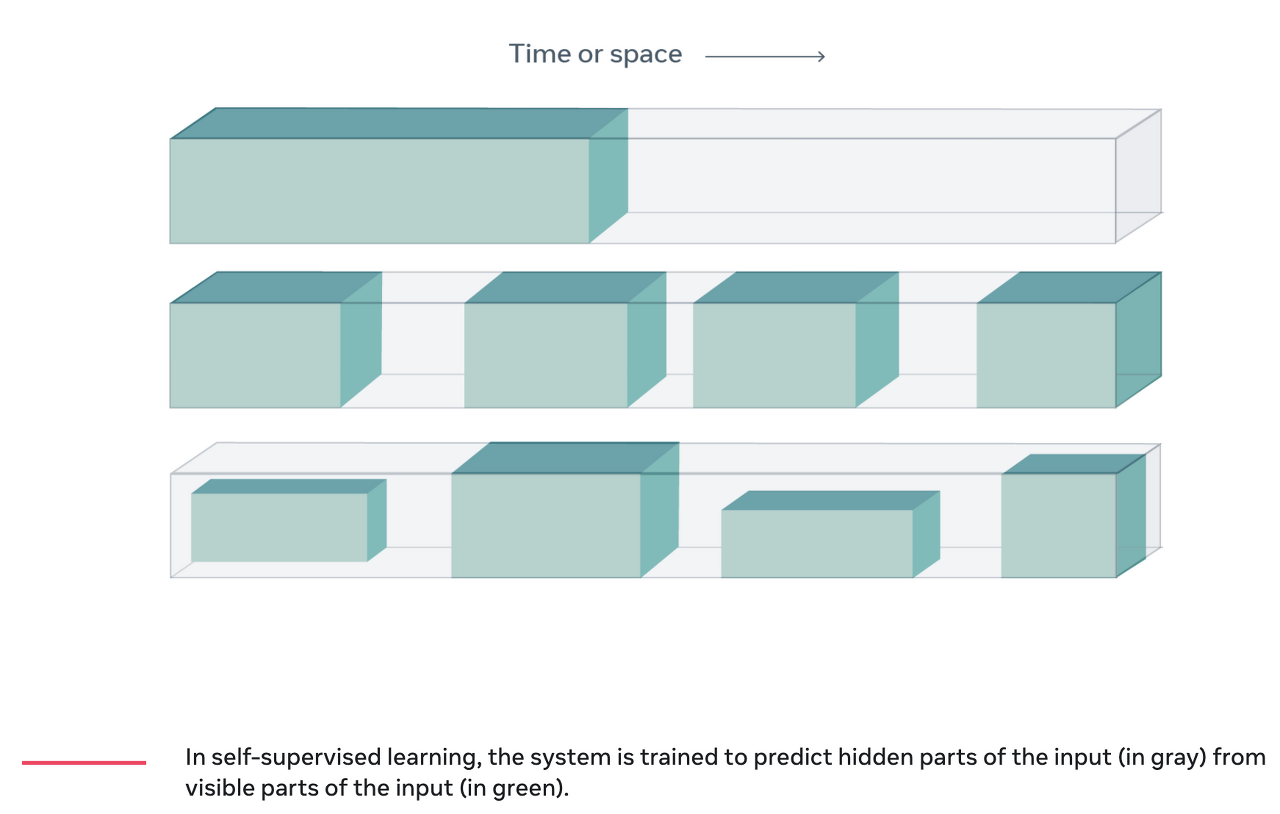
라벨링되지 않은 데이터지만 supervisory signal을 사용하기 때문에 Unsupervised-learning이 아니라 Self-supervised learning이라는 용어가 더 맞는 말이다. Unsupervised-learning은 학습에서 supervisory signal을 전혀 사용하지 않음을 시사하는 잘못 정의되고 오해의 소지가 있는 용어이다. 사실 Self-supervised learning은 Supervised 및 강화학습 방법보다 훨씬 더 많은 feedback signal을 사용하기 때문에 Unsupervised-learning이 아니다.
2. Self-supervised learning for language versus vision
Self-supervised learning의 많은 영향을 받은 BERT, RoBERTa, XLM-R등과 같은 자연어처리 모델은 라벨링이 없는 큰 텍스트 데이터 세트를 학습한 다음 downstream task에서 사용할 수 있다. 즉 이러한 모델은 Self-supervised learning 단계에서 pretrain되고 텍스트 주제 분류(downstream)와 같은 특정 task에 fine tuning 된다. Self-supervised pretraining 단계에서는 일부 단어가 마스킹되거나 대체된 짧은 텍스트가 주어진다. 모델은 마스킹되거나 대체된 단어를 예측하도록 학습된다. 그렇게 함으로써 모델은 텍스트의 의미를 표현하는 법을 배우므로 올바른 단어나 문맥에서 의미가 있는 단어로 잘 채울 수 있게된다.
input의 누락된 부분을 예측하는것은 Self-supervised pretraining을 위한 일반적인 작업중 하나이다. “The (blank) chases the (blank) in the savanna.” 라는 문장을 완성하려면 모델은 사자나 치타가 노루를 쫒을 수는 있지만 고양이는 부엌에서 쥐를 쫒는다는 것을 배워야한다. 학습의 결과로 모델은 단어의 의미, 단어의 구문론적 역할, 전체 텍스트의 의미를 표현하는 법을 배우게 된다.
하지만 이런 Self-supervised learning은 컴퓨터비전과 같은 도메인에서는 쉽게 작동하지 않는다. 자연어처리에서의 높은 성능에도 불구하고 컴퓨터비전에서는 개선이 이루어지지 않았다.
주요한 이유는 언어보다 이미지 예측에서 불확실성을 표현하기가 훨씬 더 어렵기 때문이다.
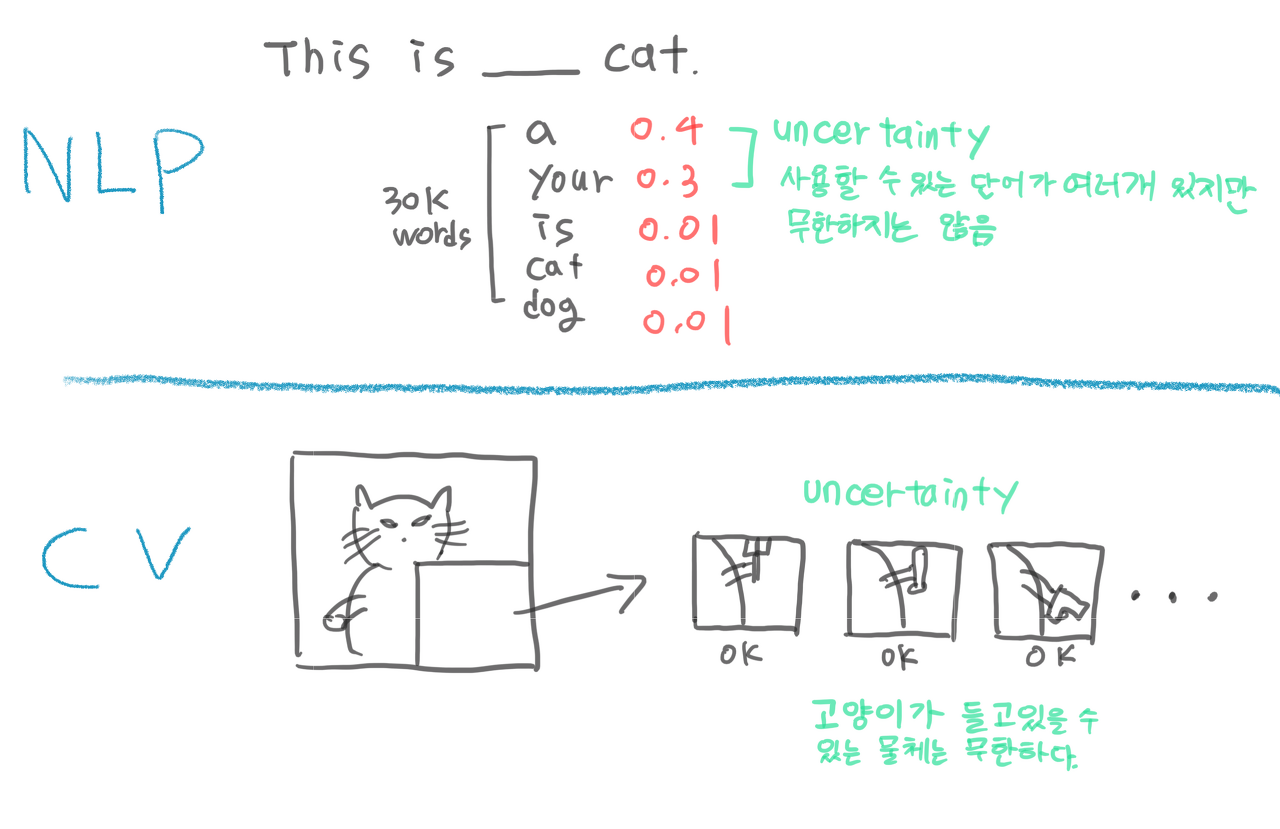
위 그림에서 NLP는 빈칸에 올 수 있는 단어는 여러개가 될 수 있지만 단어는 무한한것이 아니기 때문에 불확실성에 대한 문제가 크지 않지만 CV에서 마스킹된 영역을 예측할때 정답이라는 것이 없기 때문에 불확실성에 대한 문제가 크다.
3. Modeling the uncertainty in prediction
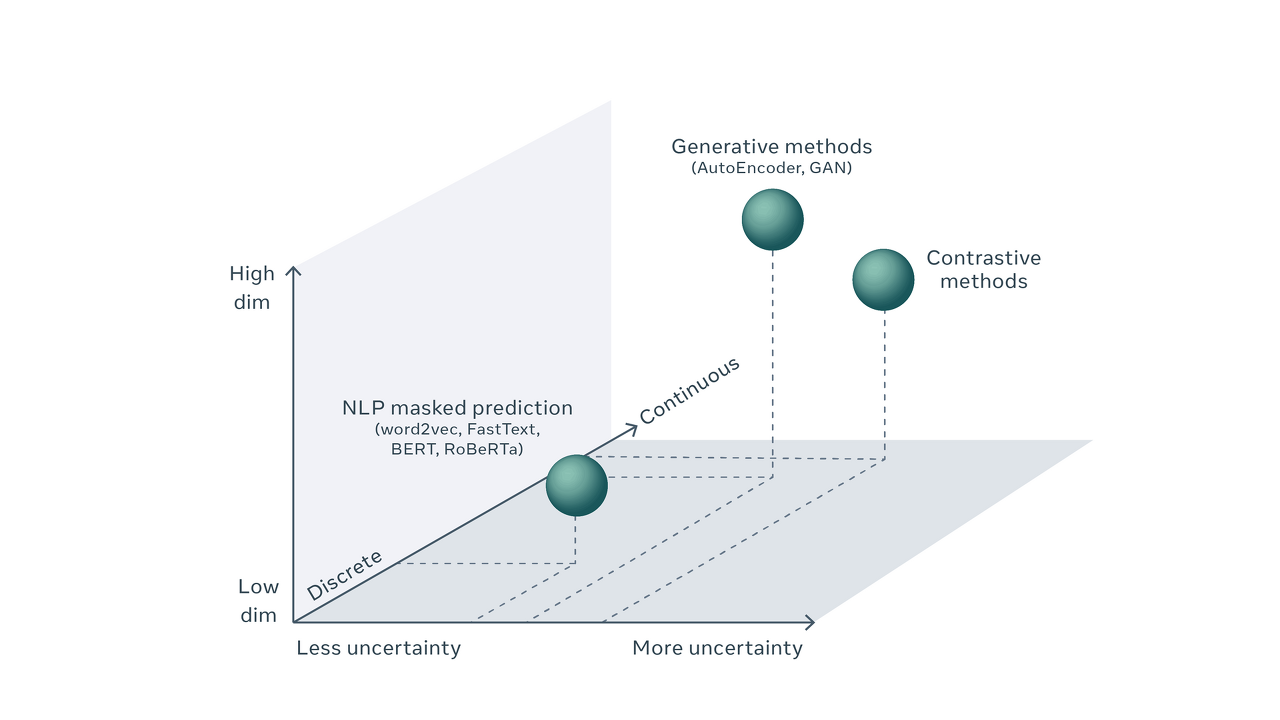
이 문제를 더 잘 이해하려면 먼저 불확실성 예측을 NLP와 CV를 비교하여 모델링 되는 방식을 이해해야 한다. NLP에서는 누락된 단어를 예측하는 것은 모든 단어에 대한 예측점수를 계산하는 것을 포함한다. 어휘 자체가 많고 누락된 단어를 예측하는 데 약간의 불확실성이 수반되지만 해당 위치에서 단어가 나타날 확률 추정치와 함께 어휘에서 가능한 모든 단어의 목록을 생성하는 것이 가능하다. 일반적인 기계학습은 예측문제를 분류문제로 처리하고 모델의 output을 확률분포로 변환하는 소프트맥스 레이어를 사용해 각 output에 대한 score를 계산한다. 이때 경우의 수가 유한하다면 불확실성을 확률 분포로서 모두 표현할 수 있다.
반면에 CV에서는 missing patches를 예측하는 데에 있어서는 discrete outcomes보다는 high-dimensional continuous한 예측이 포함된다. 비디오 프레임 수는 무한하고 이 예측값의 score를 구한다는 것은 불가능하다. 사실 모든 비디오 프레임 같은 high-dimensional continuous space에 대한 적절한 확률 분포를 나타내는 기술이 없을 수 도 있다.
이것은 꽤 다루기 힘든 문제로 보인다.
4. A unified view of Self-supervised method
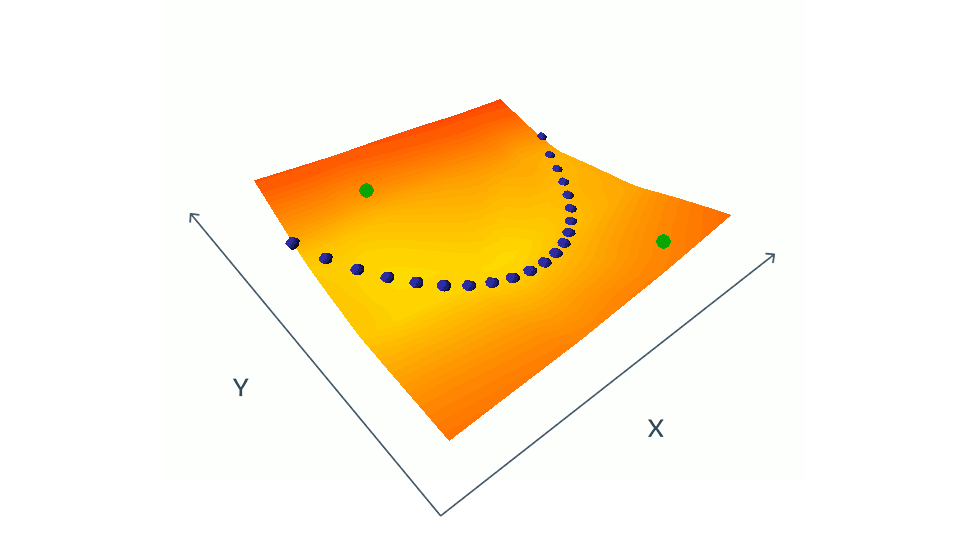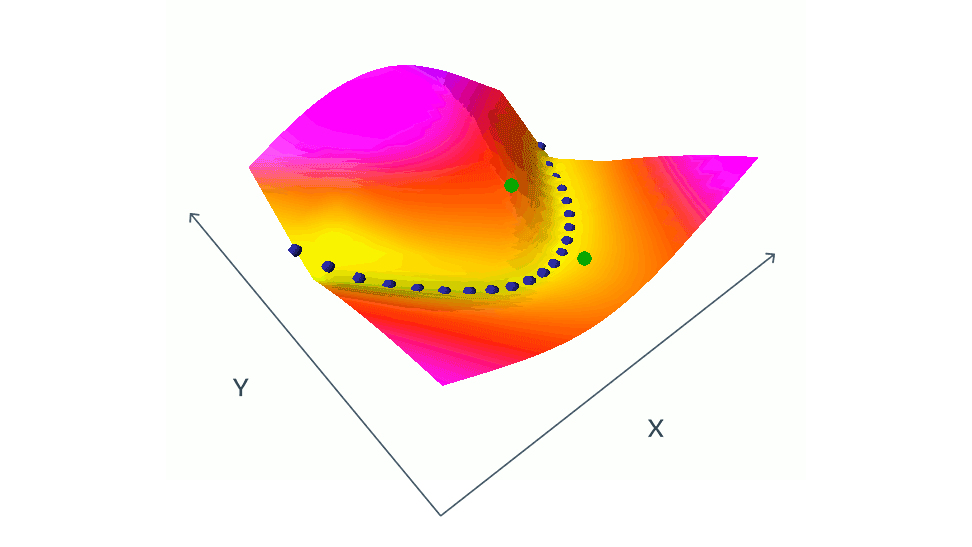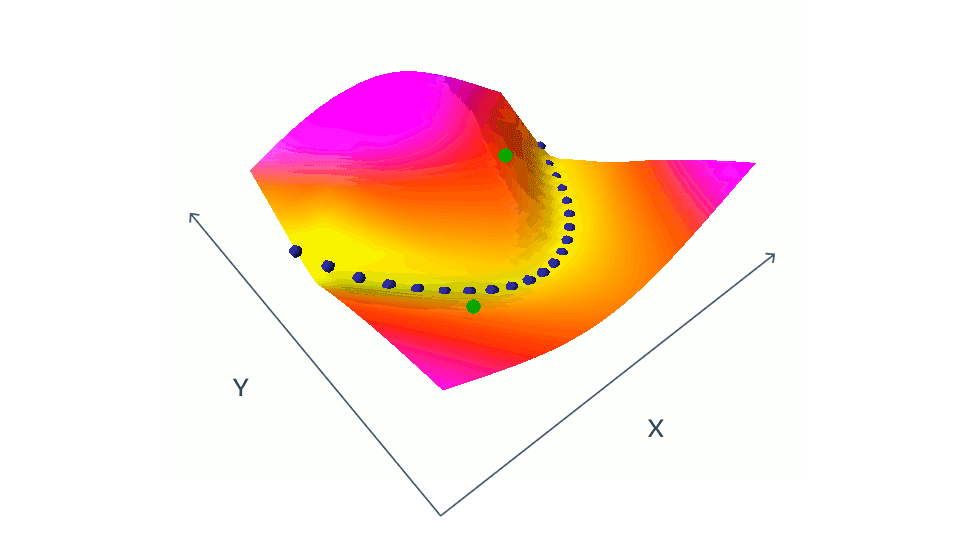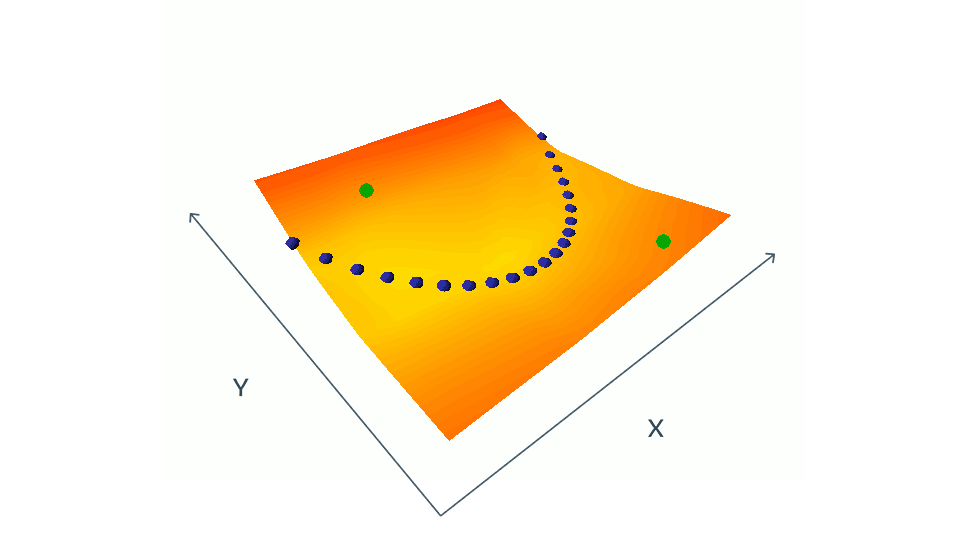
Energy Based Model(EBM)이라는 통합 프레임워크 내에서 Self-supervised learning에 대해 생각해 볼 수 있다. EBM은 x와 y라는 두개의 input이 주어지면 두 input이 서로 얼마나 호환되지 않는지 알려주는 학습 가능한 시스템이다.(마치 loss fuction과 같은 역할을 함.) 예를들어 x는 입력 비디오 클립이고 y는 예측된 비디오 클립일때 기계는 y가 x에 대해 어느정도 좋은 continuation을 가지는지 알려준다. x와 y사이의 비 호환성을 나타내기 위해 기계는 에너지라고 하는 단일 숫자를 생성하며 에너지가 낮으면 x와 y가 호환되는 것으로 간주되고 높다면 호환되지 않는 것으로 간주된다.
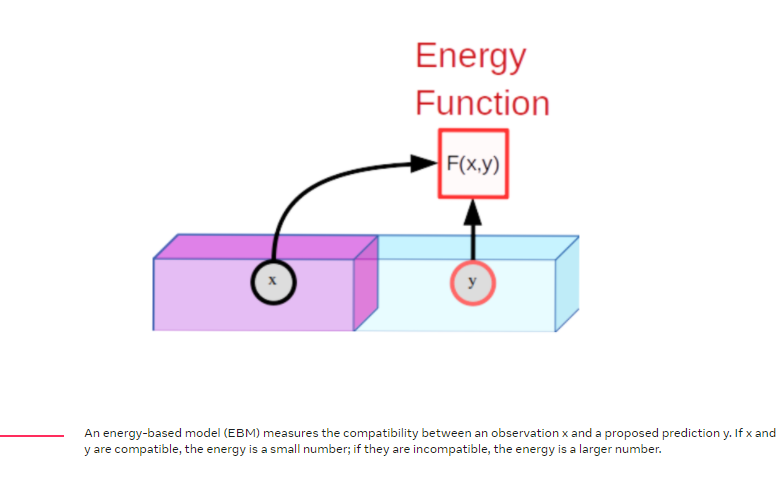
EBM학습은 두 부분으로 구성된다. 1) 호환되는 x와 y를 보여주고 이를통해 낮은 에너지를 생성하도록 학습하고 2) 특정 x에 대해 x와 호환되지 않는 y값이 x와 호환되는 y값보다 더 높은 에너지를 생성하도록 하는 방법을 찾는 것이다. 1번 문제는 비교적 간단하지만 2번은 어려움이 있는 문제이다.
이미지 인식을 위해 우리 모델은 x와 y라는 두개의 이미지를 입력으로 사용한다고 했을 때 x와 y가 약간 왜곡된 버전의 동일한 이미지인 경우 모델은 낮은 에너지를 생성하도록 학습된다. 예를들어 x는 자동차 사진이고 y는 약간 다른 위치및 다른 시간 혹은 이동, 회전, 확대, 축소, 다른 색상을 가질 수 있다.
Joint embedding, Siamese networks
그렇게 하는데 특히 적합한 딥러닝 구조는 소위 siamese network 또는 joint embedding 구조이다. 이 아이디어는 1990년대 Geoff Hinton의 연구실과 Yann LeCun 그룹의 논문으로 나와있었지만 상대적으로 무시되었던 논문이다. 하지만 2019년 말부터 아이디어가 부활하였다. joint embedding architecture는 동일한(거의 동일한) 두개의 네트워크로 구성된다. 하나의 네트워크에는 x가 다른 하나의 네트워크에는 y가 주어지고 각 네트워크는 x와 y를 나타내는 임베딩이라는 출력 벡터를 생성한다. head에서 네트워크를 연결하는 세번째 모듈은 두개의 임베딩 벡터 사이의 거리로 에너지를 계산한다. 모델이 왜곡된 버전의 동일한 이미지로 표시되면 네트워크의 파라미터를 쉽게 조정하여 출력이 서로 더 가깝게 이동할 수 있다. 이렇게 되면 해당 개체의 특정 부분에 관계없이 네트워크가 개체에 대해 거의 동일한 표현을 해낼수 가 있다.
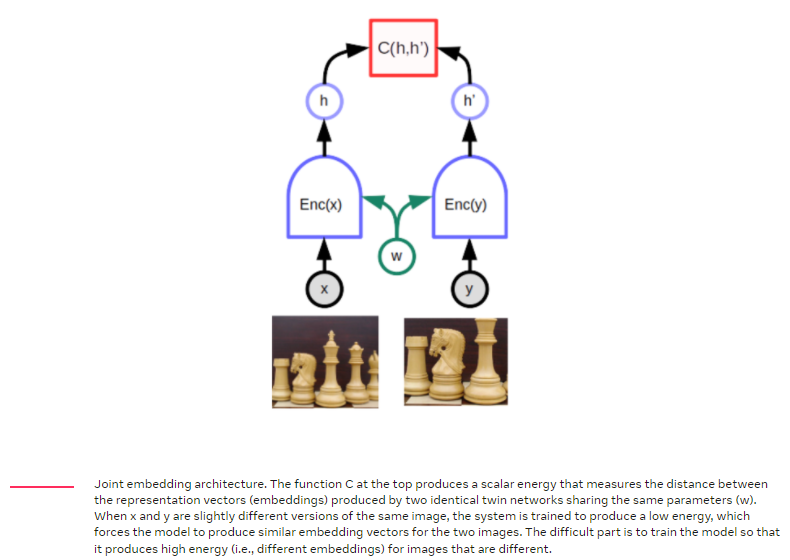
여기서 어려운점은 네트워크가 높은 에너지도 출력할수 있도록 학습하는 것이다. 서로 연관이 없는 이미지 x와 y에 대해 다른 임베딩 벡터가 나와야 한다. 이것을 해내지 못하면 두 네트워크는 input의 variation을 무시하고 항상 동일한 임베딩을 출력하게 된다. 이러한 현상을 collapse(붕괴?) 라고하며 collapse가 발생하면 일치하지 않는 x와 y의 에너지는 일치하는 x와 y의 에너지 보다 높지 않게된다.
collapse를 피하는 방법으로는 크게 contrastive 방법과 regularization 방법이 있다.
Contrastive energy-based SSL
contrastive방법은 호환되지 않는 x, y쌍을 구성하고 해당 출력 에너지가 커지도록 모델의 파라미터를 조정하는 간단한 아이디어이다.
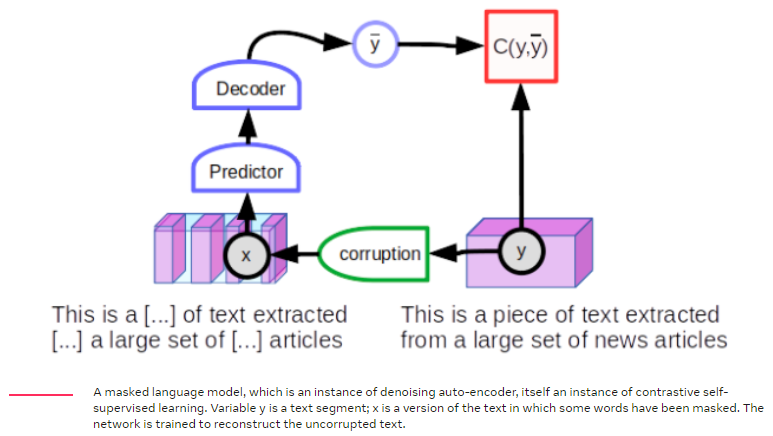
일부 input 단어를 마스킹하거나 대체하여 NLP모델을 학습하는데 사용되는 방법은 contrastive방법의 범주에 속한다. 하지만 Joint embedding 아키텍쳐를 사용하지 않는다. 대신 모델이 y에 대한 예측을 직접 생성하는 아키텍쳐를 사용한다.
텍스트 y의 전체 세그먼트에 대해 시작한 다음, 새로운 x를 생성하기 위해 일부 단어를 마스킹하여 텍스트를 손상시킨다. 손상된 입력은 원본 텍스트 y를 재현하도록 학습된 대규모 신경망에 제공된다. 손상되지 않은 텍스트는 그 자체로 재구성되는 반면(낮은 재구성 오류) 손상된 텍스트는 자체의 손상되지 않은 버전으로 재구성된다. 재구성 오류를 에너지로 해석하면 “깨끗한” 텍스트에 대해 낮은 에너지, “손상된” 텍스트에 대해 높은 에너지와 같은 결과를 얻을 수 있다.
입력의 손상된 버전을 복원하기 위해 모델을 학습하는 일반적인 기술을 1) denosing autoencoder라고 한다.
앞서 말했듯이 NLP 유형의 예측 아키텍처는 주어진 입력에 대해 단일 예측만 생성할 수 있다. 모델은 여러개의 가능한 결과를 예측할 수 있어야 하므로 예측은 단일 단어 세트가 아니라 누락된 단어 위치에 들어갈 만한 모든 단어를 점수로 나타내어야 한다. (cross entropy)
하지만 이미지 task에서는 나올수 있는 모든 픽셀값을 나열할 수 없기 때문에 이런 방법은 CV에서는 적용할 수 없다. 이 문제에 대한 해결책은 아직 없다. 여러 아이디어가 제시되고 있지만 아직 Joint embedding 아키텍처만큼 좋은 결과로 이어지지는 않았다. 흥미로운 방법이 하나 있는데 2) latent-variable predictive 아키텍처이다.
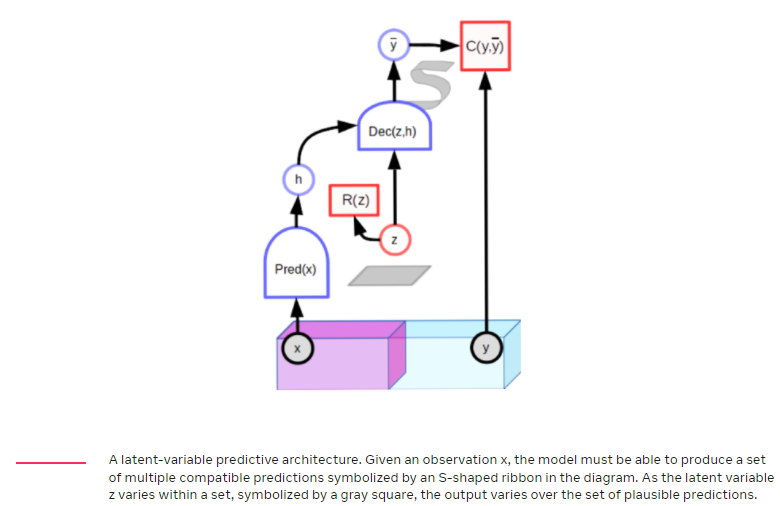
latent-variable 모델에는 추가 입력 변수 z가 포함된다. 이 z값은 지금까지 관찰되지 않았기 때문에 latent라고 부른다. 예측값에 latent-variable을 결합함으로써 주어진 집합에 따라 결과가 달라지므로 하나의 이미지로 모두 다른 여러개의 output을 낼 수 있다.
latent-variable모델은 contrastive 방법으로 학습할 수 있다. 이에 대해 좋은 예로 GAN(Generative Adversarial Network)가 있다. Discriminator의 input으로 들어오는 y값이 적절한 것인지 여부를 판별하는것을 에너지를 계산하는 것으로 볼 수 있다. Generator 네트워크는 Discriminator가 높은 에너지를 associate시키도록 contrastive 샘플을 생성하도록 학습된다.
하지만 contrastive 방법은 학습하는데 매우 비효율적이라는 중요한 문제가 있다. 이미지같은 고차원 공간에서는 이미지가 서로 다를 수 있는 경우의 수가 너무 방대하다. 주어진 이미지와 다를 수 있는 모든 방법을 포괄하는 contrastive 이미지 셋을 찾는것은 거의 불가능한 일이다.
라벨링 없이 호환되지 않는 쌍의 에너지가 호환 가능한 쌍의 에너지보다 높은지 확인 할 수 있다면 어떨까?
Non-contrastive energy-based SSL
Joint embedding 아키텍처에 적용되는 Non-contrastive 방법은 현재 Self-supervised learning CV분야에서 가장 핫한 주제일 가능성이 있다. 이 영역은 아직 많이 연구되지 않았지만 매우 유망해 보인다.
joint-embedding을 위한 Non-contrastive 방법으로는 DeeperCluster, ClusterFit, MoCo-v2, SwAV, SimSiam, Barlow Twins, BYOL from DeepMind등이 있다. 이들은 유사한 이미지 그룹(DeeperCluster, SwAV, SimSiam)애 대한 가상 target embedding을 계산하거나 아키텍처 또는 파라미터 vector(BYOL, MoCo)를 통해 두 개의 공동 임베딩 아키텍처를 약간 다르게 만드는 것과 같은 다양한 트릭을 사용한다. Barlow Twins는 임베딩 벡터의 개별 구성 요소 간의 중복성을 최소화 하려고 했다.
아마도 장기적으로 더 나은 대안은 latent-variable 예측모델을 사용하여 non-contrastive 방법을 고안하는 것이다. 주요 장애물은 latent-variable의 capacity를 최소화 하는 방법이 필요하다는 것이다. latent-variable이 변할 수 있는 집합의volume은 낮은 에너지를 사용하는 출력의 volume을 제한한다. 이 volume을 최소화 함으로써 자동으로 올바른 방식으로 에너지를 형성할 수 있다.
이러한 방법의 성공적인 예로 VAE(Variatinal Auto-Encoder)에서는 latent-variable을 fuzzy(gaussian method(mu and sigma))하게 만들어 capacity를 제한했다. 하지만 VAE는 아직 downstream visual 분야의 작업에서 좋은 representation을 생성하지 못한다. 또 다른 성공적인 예는 sparse-modeling 이지만 이것은 단순한 아키텍처로만 제한된다. latent-variable의 capacity를 제한하는 완벽한 레시피는 존재하지 않는 것으로 보인다.
향후 몇 년 동안의 과제는 라벨링된 많은 양의 데이터를 사용하지 않고 이미지, 비디오, 음성 및 기타 신호 분야에서 발전된 representation을 성공적으로 생성하고 downstream의 supervised task(recognition 등)에서 최고의 성능을 내는 latent-variable energy-based model에 대한 Non-contrastive 방법을 고안하는 것이 될 것이다.
End
CV분야에서 공부를 하면서 지금까지 항상 라벨링 된 데이터를 사용해왔다. 그렇다보니 모델 구조에 대한 아이디어를 체득할 기회는 많지만 real world dataset을 다룰때 발생하는 문제를 해결하는 능력을 기르기가 쉽지 않다는 것을 느꼈다.
현업에서 새로운 데이터들을 조금씩 마주하고 있지만 이 또한 라벨링이 완성될 때 까지 기다리는 시간과 비용이 많이 투자되기 때문에 Self-supervised learning 분야가 많이 연구되어 raw 데이터만을 활용해 다양한 downstream에 적용가능한 날이 오기를 바란다.
Keep Going
Reference
Blog - https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence
Explaned - https://youtu.be/Ag1bw8MfHGQ
Leave a comment