
Custom Dataset
Pytorch에서는 사용자가 추상클래스인 torch.utils.data.Dataset을 오버라이드하여 직접 커스텀 데이터셋을 만들 수 있도록 지원한다. 커스텀 데이터셋을 만들 때, 가장 기본적인 뼈대는 아래와 같다. (아래 3개의 메서드는 반드시 구현되어야함.)
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
def __len__(self):
def __getitem__(self, idx):
__init__ : 데이터셋 전처리
__len__ : 데이터셋의 총 길이. 즉 총 데이터 수
__getitem__ : 어떤 샘플을 가져올지 인덱스를 받아서 그만큼 보내주는 함수
이제 실제 데이터를 가지고 커스텀 데이터셋을 만들어보자. 데이터는 유명한 데이터셋인 MNIST를 사용했다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import torch
from torch.utils.data import DataLoader, Dataset
import torchvision
from torchvision import transforms
class Dataset(Dataset):
def __init__(self, file_path, transform=None):
self.data = pd.read_csv(file_path)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image = self.data.iloc[index, 1:].values.astype(np.uint8).reshape((1,28,28))
label = self.data.iloc[index,0]
if self.transform is not None:
image = self.transform(image)
return image, label
- getitem의 첫번째 줄에보면 type을 uint8로 해주는 이유는 이미지는 0~255의 값을 가지므로 256개를 가지는 unsigned integer로 지정해주면 좋다.
- 그리고 Pytorch 모델들은 (batchsize,width,height,channel) 이 아닌 (batchsize,channel,width,height)의 shape을 받는다는것을 기억해야 한다.
file_path = "../input/digit-recognizer/train.csv"
train_dataset = Dataset(file_path=file_path, transform=None)
image, label = train_dataset.__getitem__(0)
print(image.shape)
print(type(image))
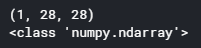
image의 shape은 (channel, width, height) 로 Pytorch에서 shape을 만들어주고 gray scale이기 때문에 channel은 1이다.
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
train_iter = iter(train_loader)
print(type(train_iter))
images, labels = train_iter.next()
print('images shape on batch size = {}'.format(images.size()))
print('labels shape on batch size = {}'.format(labels.size()))

- DataLoader의 첫번째 인자는 위에서 선언한 dataset을 받고 batch_size=8 이므로 8개의 데이터씩 뽑아낼 수 있다.
- 반복 가능한 객체를 iter라는 함수를 이용해 next로 계속해서 값을 받아올 수 있다.
- 그리고 DataLoader에서 나온 데이터의 타입은 torch.Tensor이다.
grid = torchvision.utils.make_grid(images)
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.axis('off')
plt.title(labels.numpy())

- 위쪽에 있는 작은 숫자들이 label이고 아래가 image이다. torchvision.utils의 make_grid함수를 이용해 위의 사진처럼 옆으로 나타냈고(channel도 1에서 3으로 바뀜) plt.imshow()를 하기 위해서는 데이터타입이 numpy이어야 하고 (channel,width,height) shape을 가져야 하므로 transpose 함수를 이용하여 shape의 자리를 바꿔줄 수 있다.
- transpose말고 permute라는 함수가 있는데 기능은 transpose와 같다. 다만 둘의 차이점은 transpose는 numpy타입에 대해서만 사용하고(torch.Tensor형에서도 동작을 하지만 2개의 위치만 바꿀수 있기 때문에 width와 height을 바꿀때만 사용한다.) permute는 torch.Tensor 타입에서만 작동한다.
print(grid.numpy().shape)
print(grid.numpy().transpose(1,2,0).shape)
print(grid.permute(1,2,0).numpy().shape)
이번에는 transform에 ToTensor()를 사용해보자 ToTensor는 (width,height,channel) shape을 (channel,width,height)로 바꿔주고 0~255의 픽셀값을 0~1값으로 normalize해준다. 타입도 numpy에서 torch.Tensor로 바뀐다.
class DatasetMNIST2(Dataset):
def __init__(self, file_path, transform=None):
self.data = pd.read_csv(file_path)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image = self.data.iloc[index,1:].values.astype(np.uint8).reshape((28,28,1))
label = self.data.iloc[index,0]
if self.transform is not None:
image = self.transform(image)
return image, label
첫번째 Dataset와는 다르게 getitem의 첫번째 줄에서 reshape이 (1,28,28)이 아닌 (28,28,1)로 쓴 것을 볼 수 있는데 ToTensor를 쓰기 위해서는 (width,height,channel) shape을 가지고 있어야 한다.
train_dataset2 = DatasetMNIST2(file_path=file_path, transform=torchvision.transforms.ToTensor())
img,lab = train_dataset2.__getitem__(0)
print('image shape at the first row : {}'.format(img.size()))

train_dataloader2 = DataLoader(train_dataset2, batch_size=8, shuffle=True)
train_iter2 = iter(train_dataloader2)
images, labels = train_iter2.next()
grid = torchvision.utils.make_grid(images)
plt.imshow(grid.permute(1,2,0).numpy())
plt.axis('off')
plt.title(labels.numpy())

이제 바로 이전 글에서 소개한 albumentations를 custom Dataset에 넣어 데이터를 뽑아올때 기존데이터를 가져오는게아니라 가져올때마다 조금씩 변형된 데이터가 나올수 있도록 해보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import torch
from torch.utils.data import DataLoader, Dataset
import torchvision
from torchvision import transforms
import albumentations as A
from albumentations.pytorch import ToTensor
train_transform = A.Compose([
A.RandomRotate90(),
A.Flip(),
A.Transpose(),
A.OneOf([
A.IAAAdditiveGaussianNoise(),
A.GaussNoise(),
], p=0.2),
A.OneOf([
A.MotionBlur(p=.2),
A.MedianBlur(blur_limit=3, p=0.1),
A.Blur(blur_limit=3, p=0.1),
], p=0.2),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, p=0.2),
A.OneOf([
A.OpticalDistortion(p=0.3),
A.GridDistortion(p=.1),
A.IAAPiecewiseAffine(p=0.3),
], p=0.2),
A.OneOf([
A.CLAHE(clip_limit=2),
A.IAASharpen(),
A.IAAEmboss(),
A.RandomBrightnessContrast(),
], p=0.3),
A.HueSaturationValue(p=0.3),
ToTensor()
])
augmentation 기법들은 저번 포스트에서 사용한 코드를 그대로 가져왔다. from albumentations.pytorch import ToTensor를 통해 ToTensor라는 함수를 가져오고 이를 Compose안에 써주기만 하면 된다.
class albumDataset(Dataset):
def __init__(self, file_path, transform=None):
self.data = pd.read_csv(file_path)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
img = self.data.iloc[index,1:].values.astype(np.uint8).reshape((28,28,1))
img = np.repeat(img,3,2)
label = self.data.iloc[index,0]
if self.transform is not None:
image = self.transform(image=img)['image']
return image, label
여기서 봐야할 것은 getitem의 2번째줄이다. np.repeat(img,3,2)는 데이터 shape (28,28,1) 을 (28,28,3)으로 만들어준다. 여기서 이것을 쓴 이유는 grid를 쓰지않고 바로 결과를 보여주고 싶어서 그렇게 했다.(torchvisions.utils.make_grid를 사용하면 자동으로 3차원으로 만들어줌)
file_path = "../input/digit-recognizer/train.csv"
train_dataset3 = albumDataset(file_path, transform = train_transform)
plt.imshow(train_dataset3[0][0].permute(1,2,0).numpy())
train_dataset3[0][0]에서 [0][0]의 의미는 첫번째row의 데이터의 image 픽셀값을 가져오는것이다. ([0][1]이면 첫번째 row의 데이터의 target값)
이제 dataset에서 데이터가 어떻게 나오는지 보자

위의 사진들은 바로 위의 코드를 계속해서 실행을 했을때 나온 결과들이다. 하나만의 데이터로도 albumentations의 기법들을 거쳐서 오도록 Dataset을 정의해주면 이렇게 다양한 데이터를 얻을 수 있다.
Leave a comment