
PyTorch Lightning
이번 포스팅에서는 PyTorch Ligtning에 대해 알아보려고 한다.
https://www.pytorchlightning.ai/
PyTorch Lightning이란 또다른 딥러닝 프레임워크가 아닌 PyTorch 문법을 가지면서 학습 코드를 PyTorch보다 더 효율적으로 작성할 수 있는 파이썬 오픈소스 라이브러리이다.
PyTorch를 통해 쉽게 딥러닝 모델을 만들 수 있지만 CPU, GPU, TPU간의 변경, mixed_precision training(16 bit)등의 복잡한 조건과 반복되는 코드(traning, validation, testing, inference)들을 좀더 효율적으로 추상화 시키자는 것을 목적으로 PyTorch Lightning이 나오게 되었다.
본격적으로 PyTorch Lightning을 기존 PyTorch 코드와 비교하면서 왜 PyTorch Lightning을 써야 하는지 확인해보자.
Dataset : Melanoma(피부암 / binary classification)
- https://www.kaggle.com/c/siim-isic-melanoma-classification
- https://www.kaggle.com/shonenkov/melanoma-merged-external-data-512x512-jpeg
- Train: 48381 / Valid: 12106 / Test: 10982 로 분할
GPU: Colab Pro - Tesla P100
- 캐글 데이터셋인데 캐글 노트북을 사용하지 않은 이유는 캐글의 gpu 사용시간 제한(주 30시간)도 있고 가끔씩 학습이 너무 느릴때가 있어서 코랩을 사용하였다.
Model: EfficientNet-b5
- use pretrained model (ImageNet)
- Transfer Learning
1. PyTorch Lightning
Install & Import
!pip install pytorch-lightning
import pytorch_lightning as pl
- Pytorch Lightning을 colab 환경에 설치하고 import 한다.
- Pytorch Lightning은 축약해서 보통 pl로 사용
Lightning Model
기존 PyTorch는 DataLoader, Mode, optimizer, Training roof 등을 전부 따로따로 코드로 구현을 해야하는데 Pytorch Lightning에서는 Lightning Model class 안에 이 모든것을 한번에 구현하도록 되어있다. (클래스 내부에 있는 함수명은 똑같이 써야하고 그 목적에 맞게 코딩해야 함 ex. Dataset의 init, getitem, len)
from efficientnet_pytorch import EfficientNet
from pytorch_lightning.metrics.classification import AUROC
from sklearn.metrics import roc_auc_score
class Model(pl.LightningModule):
def __init__(self, *args, **kwargs):
super().__init__()
self.net = EfficientNet.from_pretrained(arch, advprop=True)
self.net._fc = nn.Linear(in_features=self.net._fc.in_features, out_features=1, bias=True)
- Lightning Model 정의를 할 클래스에는 반드시 LightningModule을 상속받는다. (Like Torch’s nn.Module)
- pretrained model을 생성하고 transfer learning을 위해 마지막 Linear layer의 출력을 1(for binary)로 바꿔준다.
def forward(self, x):
return self.net(x)
- model의 입력에 대한 output을 내는 forward
def configure_optimizers(self):
optimizer = torch.optim.AdamW(self.parameters(), lr=lr, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
max_lr=lr,
epochs=max_epochs,
optimizer=optimizer,
steps_per_epoch=int(len(train_dataset) / batch_size),
pct_start=0.1,
div_factor=10,
final_div_factor=100,
base_momentum=0.90,
max_momentum=0.95,
)
return [optimizer], [scheduler]
- 최적화를 위한 optimizer와 learning rate scheduler 초기화 및 반환
def step(self, batch): # forward and calculate loss
# return batch loss
x, y = batch
y_hat = self(x).flatten()
y_smo = y.float() * (1 - label_smoothing) + 0.5 * label_smoothing
loss = F.binary_cross_entropy_with_logits(y_hat, y_smo.type_as(y_hat),
pos_weight=torch.tensor(pos_weight))
return loss, y, y_hat.sigmoid()
- forward를 통해 output을 얻고 loss를 계산하는 step 함수
- 여기서는 input parameter인 batch는 1 iteration에 대한 batch를 의미한다,
- self(x)를 하게되면 shape이 (batch, 1)이 되기때문에 y값의 shape인 (batch)와 맞추기 위해 flatten()이 사용됨
- label smoothing을 위한 y_smo
- 만약 label_smoothing값이 0.05이면 1(true) -> 0.975 / 0(false) -> 0.025로 바뀜
- binary classification이므로 binary_cross_entropy_with_logits loss 사용
- y_hat을 sigmoid 취해 0~1 사이 값으로 만들어줌 -> 나중에 accuracy 계산에 사용됨
def training_step(self, batch, batch_nb):
# hardware agnostic training
loss, y, y_hat = self.step(batch)
acc = (y_hat.round() == y).float().mean().item()
tensorboard_logs = {'train_loss': loss, 'acc': acc}
return {'loss': loss, 'acc': acc, 'log': tensorboard_logs}
- 1 iteration에 대한 training
- batch만큼의 output을 얻고 loss와 accuracy를 return
def validation_step(self, batch, batch_nb):
loss, y, y_hat = self.step(batch)
return {'val_loss': loss,
'y': y.detach(), 'y_hat': y_hat.detach()}
def validation_epoch_end(self, outputs): # 한 에폭이 끝났을 때 실행
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
y = torch.cat([x['y'] for x in outputs])
y_hat = torch.cat([x['y_hat'] for x in outputs])
auc = AUROC()(y_hat, y) if y.float().mean() > 0 else 0.5 # skip sanity check
acc = (y_hat.round() == y).float().mean().item()
print(f"Epoch {self.current_epoch} acc:{acc} auc:{auc}")
tensorboard_logs = {'val_loss': avg_loss, 'val_auc': auc, 'val_acc': acc}
return {'avg_val_loss': avg_loss,
'val_auc': auc, 'val_acc': acc,
'log': tensorboard_logs}
- validation_step은 1 iteration에 대한 함수라고 하면 validation_epoch_end는 1 epoch에 대한 함수이다.
- validation_step 함수의 역할은 training_step과 같은 역할을 하며 validation_epoch_end 함수는 logging과 학습과정에 대한 print를 위해 사용한다.
- classification이므로 accuracy와 ROC AUC 그래프를 성능지표로 사용한다.
- AUROC()(y_hat, y) if y.float().mean() > 0 else 0.5 에서 if절이 있는 이유는 auc roc 그래프를 그릴때 true 값이 전부다 같은 값이면 그래프를 그릴 수 없기 때문에 모두 0일때는 0.5를 주었음
def test_step(self, batch, batch_nb):
x, _ = batch
y_hat = self(x).flatten().sigmoid()
return {'y_hat': y_hat}
def test_epoch_end(self, outputs):
y_hat = torch.cat([x['y_hat'] for x in outputs])
df_test['target'] = y_hat.tolist()
N = len(glob('submission*.csv'))
df_test.target.to_csv(f'submission{N}.csv')
return {'tta': N}
- test 단계는 inference 과정이기 때문에 정답이 없으며 output을 submission할 데이터프레임에 한 컬럼으로 추가한다.
def train_dataloader(self):
return DataLoader(train_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=True, shuffle=True, pin_memory=True)
def val_dataloader(self):
return DataLoader(valid_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=False, shuffle=False, pin_memory=True)
def test_dataloader(self):
return DataLoader(test_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=False, shuffle=False, pin_memory=False)
- 각 학습모드의 DataLoader를 초기화 한다.
지금까지의 함수가 LightningModule내에서 정의되는 메서드이다. 이렇게 재정의를 하고나면 바로 학습에 들어갈 수 있다.
Pytorch Lightning에서의 학습 실행코드는 아래와 같다.
checkpoint_callback = pl.callbacks.ModelCheckpoint('{epoch:02d}_{val_auc:.4f}',
save_top_k=1, monitor='val_auc', mode='max')
trainer = pl.Trainer(
tpu_cores=tpu_cores,
gpus=gpus,
precision=16 if gpus else 32,
max_epochs=max_epochs,
num_sanity_val_steps=1 if debug else 0, # catches any bugs in your validation without having to wait for the first validation check.
checkpoint_callback=checkpoint_callback
)
trainer.fit(model)
- 먼저 모델을 저장하기위해 callbacks의 ModelCheckpoint를 사용할 수 있다.
- 첫번째 인자값은 디렉토리 경로이고 save_top_k로 몇개의 모델을 저장할 것인지 정할 수 있다.
- 저장 기준은 val_auc 값이 최대값으로 경신되면 저장되도록 하였다.
- pl.Trainer로 본격적인 학습을 하게 된다.
- gpus : gpu 사용 개수 / precision: mixed precision 사용(16) / max_epochs: 에폭 수 / num_sanity_val_steps: training 루틴을 시작하기 앞서 n개의 validation batch를 실행 / checkpoint_callback : checkpoint
- 이외에 수십가지의 파라미터값을 줄 수 있는데 나머지는 documentation을 보면서 활용해보면 좋을 것 같다.
- trainer.fit으로 학습시작
output
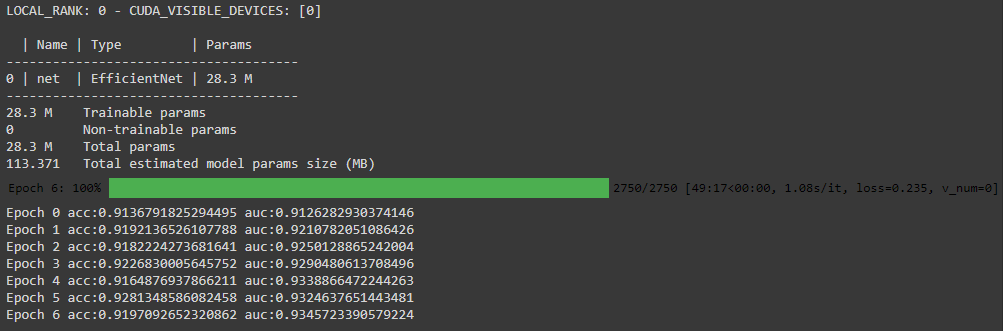
- 한개의 gpu로 EfficientNet-b5를 돌리려니까 epoch당 50분씩 걸려서 7에폭 정도만 실행해 보았고 auc가 점점 올라가는 것을 볼 수 있다.
2. Just PyTorch
기존의 PyTorch 코드와 비교했을때 얼마나 차이가 나는지 비교해보자
train_loader = DataLoader(train_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=True, shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=False, shuffle=False, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, num_workers=num_workers,
drop_last=False, shuffle=False, pin_memory=False)
def train(epoch, model, optimizer, criterion, scaler, scheduler):
model.train()
train_loss = []
correct = 0
total = 0
loop = tqdm(train_loader, desc=f'TRAIN-{epoch}', leave=True)
for idx, (inputs, targets) in enumerate(loop):
inputs, targets = inputs.to(device), targets.to(device)
smooth_targets = targets.float() * (1 - label_smoothing) + 0.5 * label_smoothing
with torch.cuda.amp.autocast():
outputs = model(inputs).flatten()
loss = criterion(outputs, smooth_targets)
train_loss.append(loss.item())
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
output_enc = outputs.sigmoid().round()
correct += (output_enc == targets).sum().item()
total += targets.shape[0]
mean_loss = sum(train_loss) / len(train_loss)
mean_acc = correct / total * 100
loop.set_postfix(loss=mean_loss, accuracy=mean_acc)
scheduler.step(mean_loss)
def valid(epoch, model, optimizer, criterion):
model.eval()
val_loss = []
correct = 0
total = 0
ra = 0
loop = tqdm(valid_loader, desc=f'VALID-{epoch}', leave=True)
for idx, (inputs, targets) in enumerate(loop):
inputs, targets = inputs.to(device), targets.to(device)
with torch.no_grad():
outputs = model(inputs).flatten()
loss = criterion(outputs, targets.float())
val_loss.append(loss.item())
output_enc = outputs.sigmoid().round()
correct += (output_enc == targets).sum().item()
total += targets.shape[0]
ra += roc_auc_score(output_enc.cpu(),targets.cpu())
mean_loss = sum(val_loss) / len(val_loss)
mean_acc = correct / total * 100
loop.set_postfix(loss=mean_loss, accuracy=mean_acc)
print(f"Epoch {epoch} acc:{mean_acc} auc:{ra / len(train_loader)}")
def test(model, optimizer):
model.eval()
all = torch.tensor([])
loop = tqdm(test_loader, desc=f'TEST', leave=True)
for (inputs, _) in loop:
inputs = inputs.to(device)
with torch.no_grad():
outputs = model(inputs).flatten().sigmoid()
all = torch.cat((all, outputs))
df_test['target'] = all.tolist()
N = len(glob('submission*.csv'))
df_test.target.to_csv(f'submission{N}.csv')
return {'tta': N}
from efficientnet_pytorch import EfficientNet
def main():
model = EfficientNet.from_pretrained(arch, advprop=True)
model._fc = nn.Linear(model._fc.in_features, out_features=1, bias=True)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.BCEWithLogitsLoss()
scaler = torch.cuda.amp.GradScaler() # FP16
scheduler = torch.optim.lr_scheduler.OneCycleLR(
max_lr=lr,
epochs=max_epochs,
optimizer=optimizer,
steps_per_epoch=int(len(train_dataset) / batch_size),
pct_start=0.1,
div_factor=10,
final_div_factor=100,
base_momentum=0.90,
max_momentum=0.95,
)
for epoch in range(max_epochs):
train(epoch, model, optimizer, criterion, scaler, scheduler)
valid(epoch, model, optimizer, criterion)
main()
- 기존 Pytorch 코드에서는 이정도 길이의 코드가 나오고 알다시피 굉장히 반복적인 코드와 자료형 변경이 필요해서 구현하는데 꽤 시간을 잡아먹게 된다.
- 기존 Pytorch 코드에서는 save나 print를 위한 log를 따로 적지 않았음에도 더 긴 것을 알 수 있다. 아마 Pytorch Lightning 처럼 똑같이 구현하면 2배이상 차이날 것으로 보인다.
output

- 시간상 1 epoch만 학습을 해 보았다
- 1 epoch의 결과와 학습속도가 Lightning과 거의 같은 것을 볼 수 있다.
End
Pytorch Lightning의 장점은 세부적인 High-Level 코드를 작성할때 좀 더 정돈되고 간결화된 코드를 작성할 수 있다는 데에 있다. 또한 처음 접하더라도 pytorch의 모델 학습구조를 이해하고 있다면 documentation을 보지 않아도 바로 example을 활용할 수 있을 정도로 접근성이 뛰어난 것 같다. (Keras와 비슷한 면이 있는 것 같다.)
앞으로 더 Pytorch Lightning의 다양한 기능들을 활용해서 좀 더 효율적이고 직관적인 코드를 작성해 보면 좋을 것 같다.
Reference
- PyTorch Lightning - https://www.pytorchlightning.ai/
- 참고한 코드 - https://www.kaggle.com/hmendonca/melanoma-neat-pytorch-lightning-native-amp
Leave a comment