
[ML Design Pattern] 추론 시스템 / 7. 시간차 추론 패턴
시간차 추론 패턴
마이크로서비스 패턴에서 언급한 대로 여러 모델을 조합하게 되면 추론기 사이에 지연시간의 차이가 발생한다. 같은 데이터에 대한 추론이라도 전체 추론 결과를 반드시 같은 타이밍에 응답할 필요는 없다. 지연에 차이가 있는 추론이라도 시스템 차원에서 유효하게 활용할 수 있는 패턴인 시간차 추론 패턴에 대해 알아보자.
Use Case
- Interactive한 애플리케이션에 추론기를 삽입할 경우
- 응답이 빠른 추론기와 느린 추론기를 조합한 workflow를 만들고 싶은 경우
해결하려는 과제
이전 포스팅 주제인 병렬 MSA 패턴에서는 동일한 데이터에 대해 여러 개의 추론기를 조합하였다. 여러 추론기를 조합할 때 해결해야 할 과제 중 하나는 추론기 간의 지연시간에 차이이다. 동기적으로 처리하는 경우라면 병렬 MSA 패턴 전체 추론속도는 가장 느린 추론기의 추론속도다. 가장 늦은 추론기의 평균적인 추론 소요 시간이 1초라면 1초, 5초라면 5초가 추론기 전체의 latency이다. 항상 느린 추론기를 기준으로 시스템의 성능 요건을 충족시킨다면 문제는 없다.
하지만 interactive한 웹 애플리케이션에서는 불과 1초의 대기시간도 너무 길다고 보는 요건도 있다. 가장 느린 추론기 이외의 추론기들이 0.2ms로 응답이 가능하고, 그 추론기들만으로도 충분히 좋은 추론 결과를 낼 수 있다면 0.2ms 이내로 클라이언트 응답이 가능한 요건을 충족한 시스템 설계가 되는 것이다.
시간차 추론 패턴에서는 빠른 추론기를 동기적인 추론과 응답에 활용하는 한편, 느린 추론기는 비동기적으로 추론해 두었다가 추론이 완료되면 결과를 클라이언트에 반영하는 전략을 세울 수 있다.
Architecture
시간차 추론 패턴은 추론 결과를 여러 단계로 나눠 클라이언트에 응답할 경우에 유효하다. 일반적인 머신러닝에서 정형 데이터를 다루는 모델은 추론이 빠르고, 이미지나 텍스트 같은 비정형 데이터를 다루면 느려지는 결향이 있다. 서비스는 보통 요청에 대해 빠르게 응답해야 하지만, 다소 늦더라도 좋은 결과를 반환하는 것이 사용자 경험 개선에 도움이 될 수 있다.
웹 애플리케이션에서 머신러닝을 다루는 경우, 이와 같은 속도와 정확도의 균형이 중요하게 작용한다. 즉, 추론의 정확도나 속도 중 하나만이 중요하다는 것은 아니다. 애플리케이션이 Interactive하게 사용된다면 빠른 추론기로 즉시 추론 결과를 응답한 이후에 사용자가 서비스를 사용하는 동안 더 좋은 추론 결과를 다음 화면에 준비해 두는 lifecycle을 생각할 수 있다.
시간차 추론 패턴에서는 두 종류의 추론기를 배치한다. 빠르고 동기적으로 추론 결과를 응답하는 추론기와 비동기적이고 처리가 무거운 추론기다. 전자는 요청에 대해 신속하게 응답하기 위해 REST API 또는 gRPC 등을 인터페이스로 하면 좋고 후자는 처리시간이 발생하기 때문에 비동기적인 처리가 가능한 메세징이나 큐를 중개한다. 전자와 후자에 탑재하는 모델의 종류는 클라이언트에 응답하는 속도 및 추론의 정확도 요건에 따라 달라지지만, 예를 들어 입력 데이터가 숫자, 카테고리, 이미지, 자연어 등의 조합으로 이루어져 있다면 전자에는 신속한 추론이 가능한 숫자와 카테고리를, 후자에는 이미지와 자연어를 나눠 입력하는 방법을 생각할 수 있다.
구현
이번 패턴에서는 추론을 처리함에 있어 시간차가 있는 추론기 여러 개를 가동시킨다. 이미지를 분류하기 위해 MobileNetV2 와 InceptionV3 두가지 모델을 사용하며, 비교적 가벼운 모델인 MobileNetV2 로는 동기적으로, InceptionV3 로는 비동기적으로 추론한다.
클라이언트로부터의 요청은 프락시를 경유한다. 프락시에서는 MobileNetV2 로의 추론 요청에 대해 동기적으로 응답한 후 Redis에 요청된 이미지를 큐에 추가하는 구성을 취한다. 배치 서버가 Redis 큐를 폴링하고, 처리하지 못한 데이터가 있으면 큐에서 꺼내 InceptionV3에 요청을 보내는 구성이다.
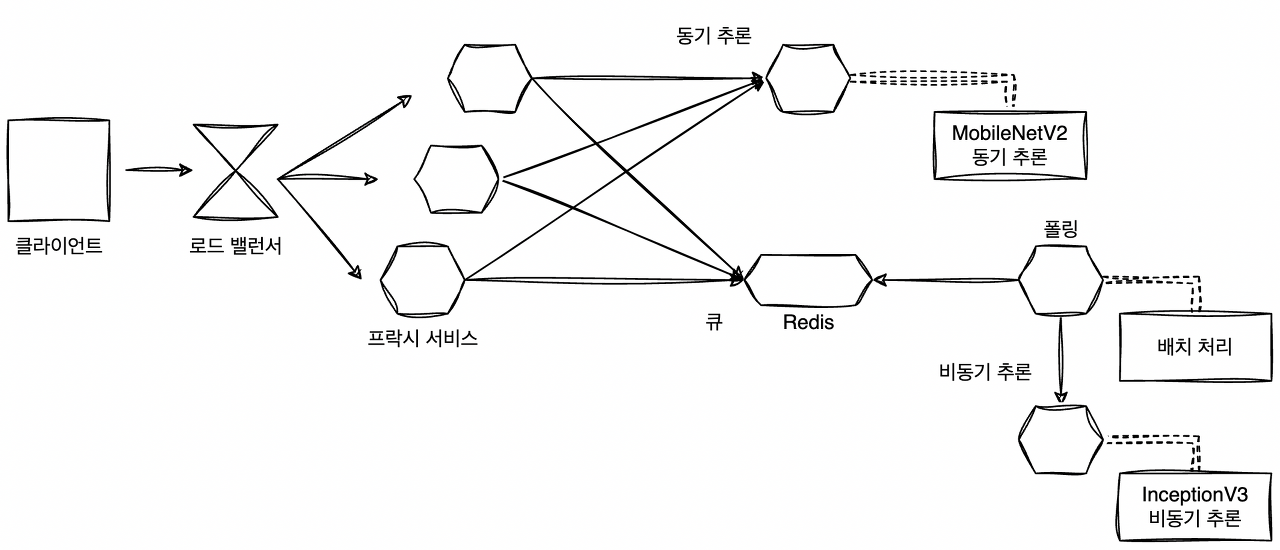
프락시는 병렬 MSA 패턴과 유사하지만 Redis에 데이터를 등록하는 과정이 추가된다. FastAPI로 웹 API를 기동하고, MobileNetV2 추론기에 대한 요청은 gRPC 클라이언트로 전송하며, InceptionV3 에서 추론하기 위한 큐는 Redis에 등록한다. Redis의 등록은 FastAPI BackgroundTasks를 사용하며, 동기적으로 응답한 이후에 실시되기 때문에 응답이 방해받을 일은 없다.
src/api_composition_proxy/routers/routers.py
# MobileNetV2로의 GRPC 접속
channel = grpc.insecure_channel(ServiceConfigurations.grpc_mobilenet_v2)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
router = APIRouter()
# 추론 요청
@router.post("/predict")
def predict(data: Data, background_tasks: BackgroundTasks) -> Dict[str, Any]:
logger.info(f"POST redirect to: /predict")
job_id = str(uuid.uuid4())[:6]
results = {"job_id": job_id}
image = base64.b64decode(str(data.image_data))
bytes_io = io.BytesIO(image)
image_data = Image.open(bytes_io)
image_data.save(bytes_io, format=image_data.format)
bytes_io.seek(0)
# MobileNetV2에 동기적으로 요청
r = request_tfserving.request_grpc(
stub=stub,
image=bytes_io.read(),
model_spec_name=ModelConfigurations.sync_model_spec_name,
signature_name=ModelConfigurations.sync_signature_name,
timeout_second=5,
)
logger.info(f"prediction: {r}")
results[ServiceConfigurations.mobilenet_v2] = r
# 백그라운드에서 돌고있는 redis에 이미지 저장
background_job.save_data_job(
data=image_data,
job_id=job_id,
background_tasks=background_tasks,
enqueue=True,
)
return results
# redis에 저장된 InceptionV3 추론 결과를 요청
@router.get("/job/{job_id}")
def prediction_result(job_id: str):
result = {job_id: {"prediction": ""}}
data = store_data_job.get_data_redis(job_id)
result[job_id]["prediction"] = data
return result
- /predict가 클라이언트로부터 요청 데이터를 받아들이면 먼저 동기 처리를 하는 MobileNetV2 추론기에서 바로 예측값을 구하고 비동기 처리를 하기 위해 이미지를 redis에 저장한다. 이때 동기 추론기는 클라이언트에게 응답을 해야하기 때문에 MobileNetV2 추론기의 예측값을 return한다.
- 비동기로 처리된 InceptionV3의 예측 결과는 /job/{job_id} 으로 요청할 수 있다.
docker-compose.yml
version: "3"
services:
proxy:
container_name: proxy
image: visionhong/ml-system-in-actions:sync_async_pattern_sync_async_proxy_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- QUEUE_NAME=tfs_queue
- REST_MOBILENET_V2=sync:8501
- REST_INCEPTION_V3=async:8601
- GRPC_MOBILENET_V2=sync:8500
- GRPC_INCEPTION_V3=async:8600
ports:
- "8000:8000"
command: ./run.sh
depends_on:
- redis
- sync
- async
- backend
sync:
container_name: sync
image: visionhong/ml-system-in-actions:sync_async_pattern_imagenet_mobilenet_v2_0.0.1
restart: always
environment:
- PORT=8500
- REST_API_PORT=8501
ports:
- "8500:8500"
- "8501:8501"
entrypoint: ["/usr/bin/tf_serving_entrypoint.sh"]
async:
container_name: async
image: visionhong/ml-system-in-actions:sync_async_pattern_imagenet_inception_v3_0.0.1
restart: always
environment:
- PORT=8600
- REST_API_PORT=8601
ports:
- "8600:8600"
- "8601:8601"
entrypoint: ["/usr/bin/tf_serving_entrypoint.sh"]
backend:
container_name: backend
image: visionhong/ml-system-in-actions:sync_async_pattern_sync_async_backend_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- QUEUE_NAME=tfs_queue
- REST_MOBILENET_V2=sync:8501
- REST_INCEPTION_V3=async:8601
- GRPC_MOBILENET_V2=sync:8500
- GRPC_INCEPTION_V3=async:8600
entrypoint:
["python", "-m", "src.api_composition_proxy.backend.prediction_batch"]
depends_on:
- redis
redis:
container_name: redis
image: "redis:latest"
ports:
- "6379:6379"
- 리소스는 총 5개 (프락시, 동기추론기, 비동기추론기, 비동기 처리를 위한 배치서버, Redis)가 존재한다.
- 동기, 비동기 추론기 모두 TensorFlow Serving을 통해 배포한다.
이미지 빌드가 끝났다고 가정하고 도커 컴포즈를 가동시켜 컨테이너를 실행하고 추론요청을 해보자.
# 컨테이너 실행
docker-compose \
-f ./docker-compose.yml \
up -d
# /predict 요청(동기추론 + 비동기추론 요청)
(echo -n '{"image_data": "'; base64 data/cat.jpg; echo '"}') | \
curl \
-X POST \
-H "Content-Type: application/json" \
-d @- \
localhost:8000/predict
# {"job_id":"48841a","mobilenet_v2":"Egyptian cat"}
# 비동기 추론 결과 확인
curl localhost:8000/job/48841a
# {"48841a":{"prediction":"Egyptian cat"}}
- /predict 으로 클라이언트가 요청을 보내면 동기추론 결과를 return하면서 입력 이미지를 redis에 등록하여 백그라운드로 돌고있는 배치서버에서 비동기 추론을 할 수 있도록 한다.
- /job/48841a 으로 클라이언트가 요청을 보내면 이전 /predict로 요청한 488841a job을 배치서버가 추론을 하여 redis에 저장한 추론 결과를 return한다.
 Egyptian cat
Egyptian cat
이점
- 신속하게 응답하면서 더욱 나은 추론 결과를 제공할 수 있음.
검토사항
시간차 추론 패턴에서 검토할 사항은 추론의 정확도와 속도의 균형이다. 어떤 추론기에서 동기적으로 응답하고 어떤 추론기에서 비동기적으로 처리 할 것인가에 대한 분담이 중요하다. 어떤 시스템이라도 빠르고 정확하게 처리하는 것이 이상적이다.
머신러닝에서는 일반적으로 심플하고 가벼운 머신러닝 모델보다 연산량이 많은 딥러닝이 정확도가 높고 속도가 느린 경향이 있다. 딥러닝이 아닌 머신러닝 분류 모델에서도 로지스틱 회귀나 Decision Tree에 비해 XGBoost는 무겁고 정확한 모델로 평가된다. 딥러닝에서도 가볍고 빠른 추론을 목적으로 한 모델(MobileNet)이 있는 반면, 속도는 고려하지 않고 정확성만을 중시한 모델(BERT)도 있다.
느린 추론기의 결과를 보여주는 방법은 일종의 사용자 경험을 만드는 방법이라고 생각하고 검토할 필요가 있다. 사용자가 조작하는 중간에 추론 결과를 제공할 수 있는 애플리케이션도 있으며, 동일 화면 안에서 이동하지 않고 추론 결과를 제공해야만 하는 경우도 있다. 전자라면 화면의 이동 타이밍에 표시할 수 있을 것이다. 콘텐츠가 목록이 된 게시판 형식이라면 스크롤을 조작한 후에 보여지는 콘텐츠에 느린 추론기의 결과를 반영할 수 있다. 후자의 경우에 추론 결과에 따라 갑자기 보는 화면이 바뀌게 되면 사용자를 당황시킬 위험이 있다. 화면을 갑자기 바꾸는 것이 아닌, 팝업이나 공지 등으로 결과를 반영하려는 노력이 필요하다.
End
이상으로 시간차 추론 패턴에 대해 알아보았다. 전처리 · 추론 패턴, 마이크로서비스 패턴, 시간차 추론 패턴까지 여러 개의 모델로 구성된 추론 시스템의 구현 예시를 설명했다. 해결하려는 과제는 서로 다르지만, 여러 개의 모델로 하나의 추론 시스템을 구축할 수 있다면, 시스템은 더욱 유연해지고 높은 확장성을 가질 수 있을 것이다.
다음 포스팅에서는 같은 데이터를 여러 차례 추론하는 경우에 활용할 수 있는 추론 캐시 패턴에 대해 알아보자.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/sync_async_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/sync_async_pattern
Leave a comment