
[ML Design Pattern] 추론 시스템 / 8. 추론 캐시 패턴
추론 캐시 패턴
만약 반복적으로 추론기에 들어가는 데이터가 있다고 가정해보자 매번 같은 결과를 내는데 굳이 Cost를 낭비할 필요가 있을까?
이처럼 같은 데이터를 같은 추론기로 여러 번 추론하는 경우가 있을 수 있다. 이럴 때는 추론 캐시 패턴을 활용해 식별이 가능한 데이터라면 추론했던 결과를 그대로 사용할수 있도록 문제를 해결할 수 있다.
Use-Case
- 동일 데이터에 대해 추론 요청이 발생함과 동시에 그 데이터를 식별할 수 있는 경우
- 동일 데이터에 대해 동일한 추론 결과를 응답할 수 있는 경우
- 입력 데이터를 검색할 수 있는 경우
- 추론의 지연을 단축하고 싶은 경우
해결하려는 과제
모든 시스템은 갖춰야 할 기능을 요구되는 속도와 비용으로 가동시킬 필요가 있다. 그리고 대부분의 경우 기능, 속도, 비용이 밸런스를 갖추게 하는 것이 중요하다. 머신러닝 시스템은 다른 시스템보다 고성능의 자원을 필요로 하는 경향이 있다. 학습이나 추론에서 필요로 하는 연산량이 방대하기 때문이다. 게다가 추론의 용도가 사용자나 시스템의 동작에 직접적인 영향을 미치는 경우, 사용자나 시스템을 기다리게 하지 않을 정도의 속도가 요구된다.
예를 들어 웹 검색 서비스는 일반적으로 검색 결과를 최적의 순서로 나열하는 모델을 사용한다. 순위 학습의 결과를 얻는 데 10초 정도의 시간이 필요하다면 차라리 결과를 정렬하지 않고 응답하는 것이 사용자 경험 측면에서 유리할지도 모른다. On-Premise나 cloud 환경에서도 속도를 유지하기 위해서는 고성능 자원을 사용해야 하고 그만큼 비용이 필요하다.
Architecture
캐시 관련 패턴에서는 캐시를 이용해 비용과 속도에 관한 문제를 개선한다. 추론 캐시 패턴에서는 추론 결과를 캐시해두고, 동일한 입력 데이터가 요청된 경우에는 캐시해둔 추론 결과를 응답하는 시스템을 구축한다. DB로의 효율적인 접근을 위해 접근 빈도가 높은 데이터를 캐시해 두는 시스템이 있는데, 추론 캐시 패턴은 마치 이 시스템의 추론기 버전이라고 생각할 수 있다. 캐시 서버는 Memcached나 Redis 등에서 추론기와는 별도로 준비해 두고, 입력 데이터를 Key로, 추론결과를 Value로 검색할 수 있어야 한다. 캐시의 양과 검색 성능이 추론 캐시 패턴의 성능지표가 된다.
추론 캐시 패턴에서는 다음과 같은 캐시 타이밍이 있다.
- 사전에 배치 추론을 실행하고 캐시함.
- 추론 시에 캐시함.
- 1번과 2번의 조합
사전에 배치 추론해 놓는 경우는 캐시 대상이 되는 입력 데이터를 사전에 예측할 수 있어야 한다. 검색 시스템이라면 검색 빈도가 높은 키워드 상위 1,000건 등을 캐시해 두는 것을 고려할 수 있다.
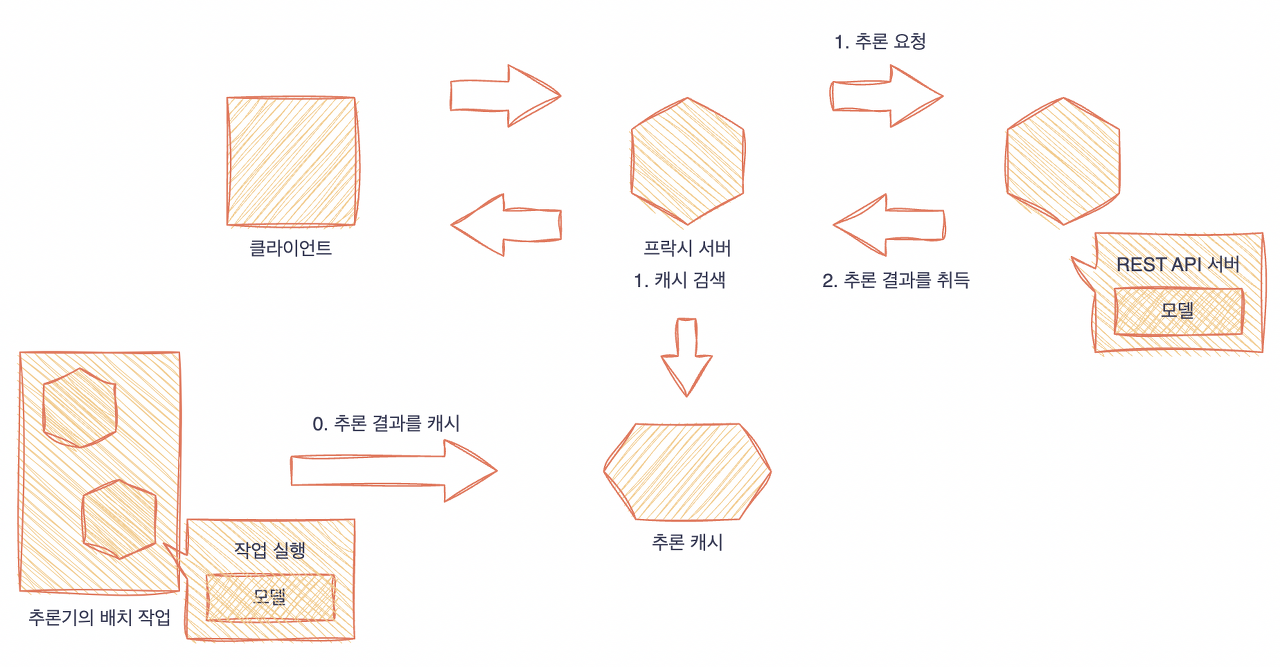 추론 캐시 패턴(사전에 배치 추론을 실행해서 캐시해 놓는 경우), 캐시 검색과 추론 요청을 동시에 실행.
추론 캐시 패턴(사전에 배치 추론을 실행해서 캐시해 놓는 경우), 캐시 검색과 추론 요청을 동시에 실행.
배치 추론을 실행하는 타이밍은 추론 결과가 시간에 따라 변하지 않는다면 추론기를 릴리스하는 타이밍에 캐시를 해두면 좋을 것이다. 1번의 문제점은 캐시의 대상이 되는 데이터가 요청되지 않으면 캐시가 소용이 없다는 점이다. 캐시 작성시에 높은 빈도로 요청되는 입력 데이터가 바뀌지 않아야 한다는 조건이 있어야 한다.
추론시에 캐시하는 2번의 경우는 추론 후에 캐시 서버에 등록하는 처리가 필요하다. 추론마다 캐시를 등록하기 때문에 추론 건수가 많으면서 중복되는 입력 데이터가 적을 경우 캐시양이 증가할 우려가 있다.
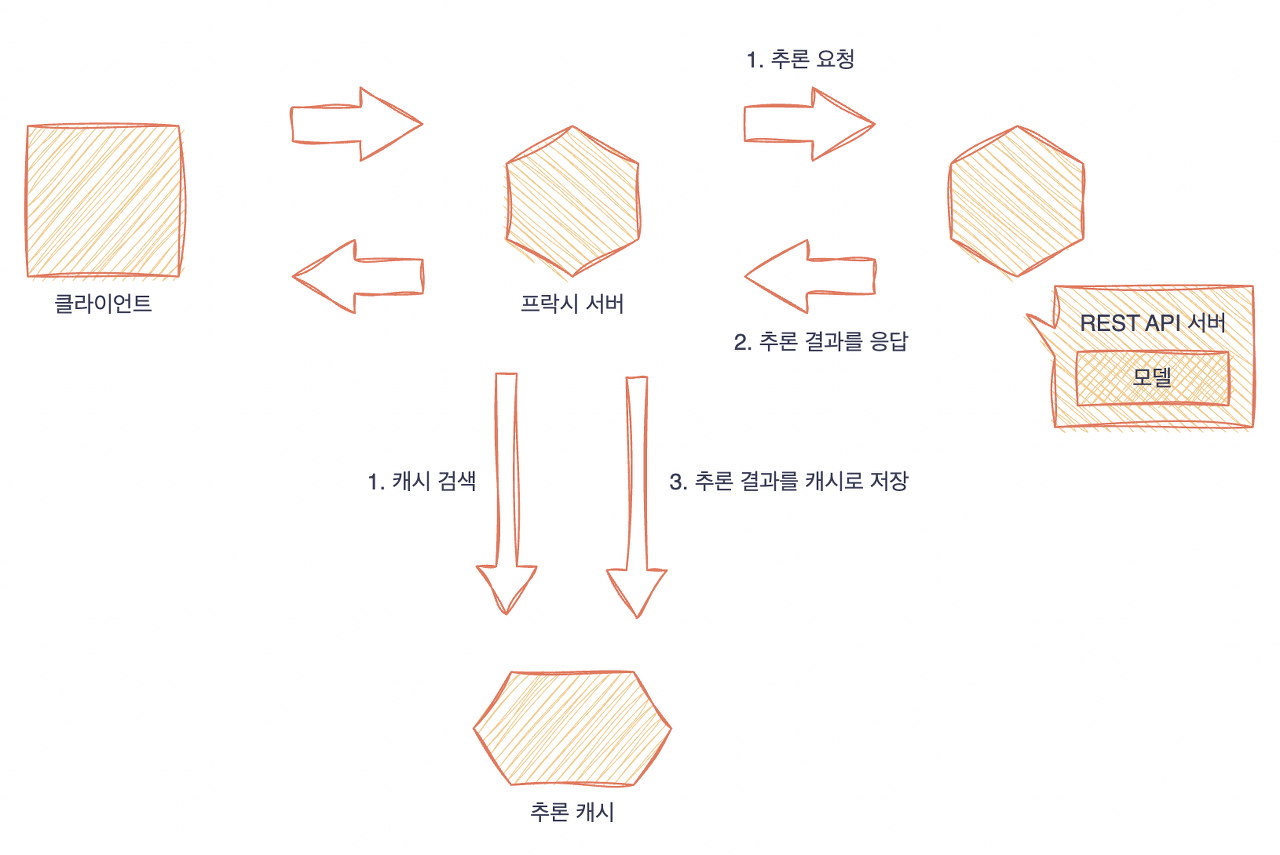 추론 캐시 패턴(추론 시에 캐시해 두는 경우), 캐시 검색과 추론 요청을 동시에 실행.
추론 캐시 패턴(추론 시에 캐시해 두는 경우), 캐시 검색과 추론 요청을 동시에 실행.
이것을 실용화하기 위해서는 1번과 2번을 조합해서 운용하는 것이 좋다. 1번처럼 사전에 캐시 데이터를 작성해 두고, 2번과 같이 1번에서 캐시되지 않은 데이터를 추가해 나가는 방식이다. 캐시는 메모리를 사용하기 때문에 비록 적은 용량이라 할지라도 디스크에 비해 비용이 든다. 캐시 양이 몇 GB정도라면 버틸만하지만, 수십~수백 GB를 초과하면 무시할 수 없는 비용으로 치닫게 되기 때문에 캐시를 정기적으로 클리어해주는 대책이 필요하다. 캐시 클리어 전략에는 여러 가지가 있지만, 오랫동안 사용하지 않은 캐시(LRU: Least Recently Used) 또는 적은 횟수로 사용한 캐시(LFU: Least Frequently Used)를 삭제하는 것이 가장 적절하다.
캐시 검색 타이밍에도 다음과 같은 선택지가 있다.
1. 추론기에 추론을 요청하기 전에
2. 추론기에 추론을 요청함과 동시에
1번의 경우에는 캐시 hit 수만큼 부하를 줄일 수 있다. 캐시 hit 때는 추론기로 요청하지 않기 때문에, 캐시 적중률이 높으면 자원을 효율적이고 저렴하게 사용할 수 있다. 한편 캐시 miss가 많으면 캐시를 검색하는 데 걸리는 시간이 전체적인 추론 지연에 더해지므로 성능 저하로 이어질 수 있다.
2번의 경우 캐시 검색과 추론 요청을 동시에 실행한다. 캐시 hit 하면 추론 요청을 바로 취소하고 응답하며, 캐시 hit 하지 않으면 추론 결과를 기다렸다가 응답한다. 모든 요청을 추론기로 송신하기 때문에 추론기의 자원을 모두 사용해야 하지만, 성능이 저하될 우려는 없다.
추론 캐시 패턴에서는 입력한 데이터와 추론이 끝난 데이터가 같은 것인지 식별할 수 있어야 한다.따라서 캐시 키에 입력데이터로부터 변환한 해시 값을 사용하는 것이 좋다.
구현
추론 캐시 패턴은 반복되는 데이터의 추론 요청이 전송된다는 전제로부터 시작한다. 따라서 요청된 데이터가 이미 캐시가 끝난 것으로 보아야 한다. 이번 구현에서는 ID가 부여된 데이터가 준비되어 있고 클라이언트에서 데이터의 ID를 요청하는 상황을 가정한다. 물론 기존 데이터가 대상이라면 일일이 요청하지 않더라도 미리 모든 데이터를 추론해두고 데이터베이스에 등록하는 것이 좋아 보인다.
그러나 데이터의 양이 방대하면 비용적으로나 시간적으로 어려울 것이고, 과거부터 지금까지의 모든 데이터의 추론 결과가 필요하다고는 할 수 없다. 게다가 추론 모델이 바뀔 가능성도 있다. 따라서 추론 캐시 패턴은 필요한 경우에만 추론하고 재이용이 가능한 케이스를 상정한다.
추론 요청을 받는 웹 API 서버로 FastAPI, 추론 결과를 캐시해 두는 환경으로는 Redis를 사용한다. 모델은 PyTorch로 학습 완료된 ResNet50 모델을 사용하고 ONNX Runtime Server로 가동한다. 웹 API 서버는 Redis에서 데이터 ID를 검색한 후, 캐시 히트 시에는 그대로 응답한다. 캐시 히트에 실패하면 ResNet50 ONNX Runtime server 로부터 추론 결과를 취득하고 클라이언트에 응답한 후 추론 결과를 Redis에 등록한다.
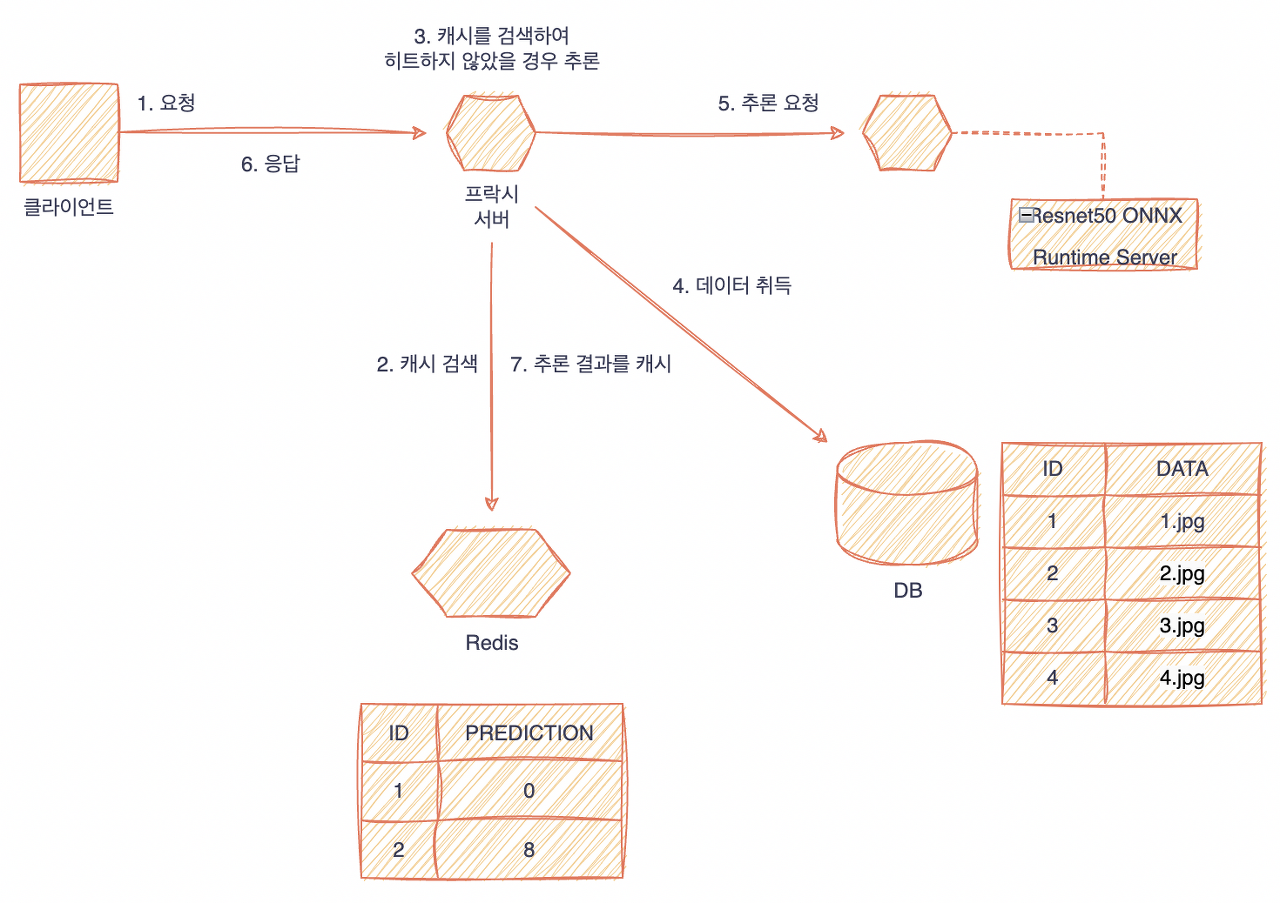 추론시 캐시하는 경우의 예시
추론시 캐시하는 경우의 예시
src/app/routers/routers.py
from logging import getLogger
from typing import Any, Dict, List
from fastapi import APIRouter, BackgroundTasks
from src.ml.prediction import Data, classifier
logger = getLogger(__name__)
router = APIRouter()
@router.get("/health")
def health() -> Dict[str, str]:
return {"health": "ok"}
@router.get("/metadata")
def metadata() -> Dict[str, Any]:
return {
"data_type": "str",
"data_structure": "(1,1)",
"data_sample": Data().data,
"prediction_type": "float32",
"prediction_structure": "(1,1000)",
"prediction_sample": "[0.07093159, 0.01558308, 0.01348537, ...]",
}
@router.post("/predict")
def predict(data: Data, background_tasks: BackgroundTasks) -> Dict[str, List[float]]:
prediction = classifier.predict(data=data, background_tasks=background_tasks)
return {"prediction": list(prediction)}
@router.post("/predict/label")
def predict_label(data: Data, background_tasks: BackgroundTasks) -> Dict[str, str]:
prediction = classifier.predict_label(data=data, background_tasks=background_tasks)
return {"prediction": prediction}
- /predict에서 classifier 클래스의 predict 함수를 데이터와 FastAPI background task를 argument로 넣어 실행한다.
- 이때 데이터는 key가 되어서 캐시검색으로 활용되기 때문에 파일이 아닌 파일명(cat.jpg라면 cat)으로 요청이 들어옴
src/app/ml/prediction.py
import json
import os
from logging import getLogger
from typing import List
import grpc
import joblib
import numpy as np
from fastapi import BackgroundTasks
from PIL import Image
from pydantic import BaseModel
from src.app.backend import background_job
from src.configurations import ModelConfigurations
from src.ml.transformers import PytorchImagePreprocessTransformer, SoftmaxTransformer
from src.proto import onnx_ml_pb2, predict_pb2, prediction_service_pb2_grpc
logger = getLogger(__name__)
class Data(BaseModel):
data: str = "0000"
class Classifier(object):
def __init__(
self,
preprocess_transformer_path: str = "/prediction_cache_pattern/models/preprocess_transformer.pkl",
softmax_transformer_path: str = "/prediction_cache_pattern/models/softmax_transformer.pkl",
label_path: str = "/prediction_cache_pattern/data/image_net_labels.json",
serving_address: str = "localhost:50051",
onnx_input_name: str = "input",
onnx_output_name: str = "output",
):
self.preprocess_transformer_path: str = preprocess_transformer_path
self.softmax_transformer_path: str = softmax_transformer_path
self.preprocess_transformer: PytorchImagePreprocessTransformer = None
self.softmax_transformer: SoftmaxTransformer = None
self.serving_address = serving_address
self.channel = grpc.insecure_channel(self.serving_address)
# onnx runtime 추론기
self.stub = prediction_service_pb2_grpc.PredictionServiceStub(self.channel)
self.label_path = label_path
self.label: List[str] = []
self.onnx_input_name: str = onnx_input_name
self.onnx_output_name: str = onnx_output_name
# multi stage build에서 저장한 pkl 불러옴
self.load_model()
self.load_label()
def load_model(self):
logger.info(f"load preprocess in {self.preprocess_transformer_path}")
self.preprocess_transformer = joblib.load(self.preprocess_transformer_path)
logger.info(f"initialized preprocess")
logger.info(f"load postprocess in {self.softmax_transformer_path}")
self.softmax_transformer = joblib.load(self.softmax_transformer_path)
logger.info(f"initialized postprocess")
def load_label(self):
logger.info(f"load label in {self.label_path}")
with open(self.label_path, "r") as f:
self.label = json.load(f)
logger.info(f"label: {self.label}")
def predict(
self,
data: Data,
background_tasks: BackgroundTasks,
) -> List[float]:
# 해당 key로 등록된 캐시가 있는지 확인
cache_data = background_job.get_data_redis(key=data.data)
# 해당 key가 검색이 되지 않는다면 추론실행
if cache_data is None:
logger.info(f"registering cache: {data.data}")
image = Image.open(os.path.join("data/", f"{data.data}.jpg"))
preprocessed = self.preprocess_transformer.transform(image)
input_tensor = onnx_ml_pb2.TensorProto()
input_tensor.dims.extend(preprocessed.shape)
input_tensor.data_type = 1
input_tensor.raw_data = preprocessed.tobytes()
request_message = predict_pb2.PredictRequest()
request_message.inputs[self.onnx_input_name].data_type = input_tensor.data_type
request_message.inputs[self.onnx_input_name].dims.extend(preprocessed.shape)
request_message.inputs[self.onnx_input_name].raw_data = input_tensor.raw_data
# onnx runtime grpc inference
response = self.stub.Predict(request_message)
output = np.frombuffer(response.outputs[self.onnx_output_name].raw_data, dtype=np.float32)
softmax = self.softmax_transformer.transform(output).tolist()
# 추론 결과를 캐싱
background_job.save_data_job(data=list(softmax), item_id=data.data, background_tasks=background_tasks)
# 해당 key가 검색 되었다면 value 활용
else:
logger.info(f"cache hit: {data.data}")
softmax = list(cache_data)
logger.info(f"predict proba {softmax}")
return softmax
def predict_label(
self,
data: Data,
background_tasks: BackgroundTasks,
) -> str:
softmax = self.predict(data=data, background_tasks=background_tasks)
argmax = int(np.argmax(np.array(softmax)[0]))
return self.label[argmax]
classifier = Classifier(
preprocess_transformer_path=ModelConfigurations().preprocess_transformer_path,
softmax_transformer_path=ModelConfigurations().softmax_transformer_path,
label_path=ModelConfigurations().label_path,
serving_address=f"{ModelConfigurations.api_address}:{ModelConfigurations.grpc_port}",
onnx_input_name=ModelConfigurations().onnx_input_name,
onnx_output_name=ModelConfigurations().onnx_output_name,
)
- init 함수에서 pkl로 저장된 전, 후처리 코드를 load하고 onnx runtime server의 엔드포인트를 통해 grpc로 통신할 준비를 한다.
- predict 함수에서는 먼저 입력으로 들어온 key(data)값이 캐시에 등록되어있는지 검색한 뒤 등록이 되어있지 않다면 추론을, 등록이 되어있다면 value를 활용한다.
- 입력 key가 등록된 캐시가 아니어서 추론을 진행한 경우 추론이 완료되면 추론 결과를 캐싱해두어 다음에 같은 key가 들어왔을때 캐시를 활용할 수 있도록 한다.
- 예측 결과는 후처리(softmax)하여 리스트로 감싸서 value로 저장된다.
docker-compose.yml
version: "3"
services:
proxy:
container_name: proxy
image: visionhong/ml-system-in-actions:prediction_cache_pattern_proxy_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- API_ADDRESS=pred
- CACHE_HOST=redis
ports:
- "8010:8000"
command: ./run.sh
depends_on:
- pred
- redis
pred:
container_name: pred
image: visionhong/ml-system-in-actions:prediction_cache_pattern_pred_0.0.1
restart: always
environment:
- HTTP_PORT=8001
- GRPC_PORT=50051
ports:
- "8011:8001"
- "50051:50051"
entrypoint: ["./onnx_runtime_server_entrypoint.sh"]
redis:
container_name: redis
image: "redis:latest"
ports:
- "6379:6379"
- 서비스로는 프락시, 추론기, Redis가 필요하기 때문에 3개의 컨테이너를 docker-compose로 실행한다.
- 프락시에서 추론기의 엔드포인트를 알아야 추론요청을 할 수 있기 때문에 이를 환경변수 API_ADDRESS에서 받도록 한다. 또한 캐시 검색과 저장을해야 하기 때문에 환경변수 CACHE_HOST로 Redis의 엔드포인트 정보를 입력한다.
이제 컨테이너를 실행해 추론과 캐싱이 잘 작동하는지 확인해보자
# 컨테이너 실행
docker-compose \
-f ./docker-compose.yml \
up -d
# 추론 요청
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": "0007"}' \
localhost:8010/predict/label
# {"prediction":"tabby"}
# 컨테이너 로그확인
docker logs <containerID>
# [2022-12-28 01:31:31] [INFO] [11] [src.ml.prediction] [predict] [76] registering cache: 0007
 tabby
tabby
추론결과 tabby로 예측하였고 컨테이너의 로그를 살펴보면 캐시로 등록되어 있는 데이터가 아니기 때문에 registering cache라는 로그가 남아있다. 다시 한번 같은데이터로 추론해보자.
# 추론 요청
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": "0007"}' \
localhost:8010/predict/label
# {"prediction":"tabby"}
# 컨테이너 로그확인
docker logs <containerID>
# [2022-12-28 01:35:18] [INFO] [11] [src.ml.prediction] [predict] [97] cache hit: 0007
이미 입력 key(0007)의 캐시가 존재하기 때문에 ‘cache hit: 0007’ 로그가 기록되었고 추론을 건너뛰게 된다.
이점
- 응답속도의 개선이 가능하다.
- 추론기의 비용을 절감할 수 있다.
검토사항
추론 캐시 패턴에서 주의할 점은 캐시 서버의 비용이 오히려 커질 수 있다는 것이다. 캐시를 키울수록 메모리양에 따른 비용이 증가한다. 따라서 캐시를 이용해 추론 횟수를 줄여 추론기의 부하를 덜었다 하더라도, 추론기에서 절약한 비용보다 캐시 서버에 들어가는 비용이 더 많다면 캐시가 필요한지 검토 할 필요가 있다. 물론 캐시 덕분에 지연이 개선되는 경향을 보인다면 좋겠지만, 비용 절감만이 목적인 경우라면 캐시 용량을 줄이기 위한 대책이 필요하다.
게다가 추론 캐시 패턴은 같은 데이터에 대한 hit로 인해 효과를 발휘하지만, 유사한 데이터로는 사용할 수 없다. 같은 데이터에 대한 추론이 종종 발생하는 시스템에서는 강점을 낼 수는 있어도, 비슷하기만 하고 엄밀하게는 같지 않은 데이터의 추론이 자주 발생하는 시스템(동영상을 프레임 단위로 추론하는 경우)에서는 캐시가 없는 추론기와 다를 바없는 성능을 보이게 된다.
End
이상으로 추론 캐시 패턴에 대해 알아보았다. 추론 캐시 패턴에서는 캐시가 쌓일수록 추론기에 대한 요청이 줄어들어 리소스 효율에 기여하게 된다. 딥러닝 추론기는 일반적으로 Redis 등에서 캐시 서버를 준비하는 것보다 비용이 높아질 수 있는데, 캐시 hit율이 오르면 비용 절감을 기대할 수 있다.
다음 포스팅에서는 추론 캐시가 아닌 데이터와 전처리된 데이터를 캐시하고 데이터를 매우 빠르게 취득할 수 있도록 하는 데이터 캐시 패턴에 대해 알아보자.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/prediction_cache_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/prediction_cache_pattern
Leave a comment