
[ML Design Pattern] 모델 릴리스 / 1. 모델 인 이미지 패턴
머신러닝 모델을 만드는 확습환경과 모델을 사용해 추론을 수행하는 추론환경은 다르다. 학습환경에서는 풍부한 컴퓨팅 자원과 학습용 라이브러리를 함께 활용해 모델을 개발하고, 추론환경에서는 한정된 자원과 추론용 라이브러리를 통해 추론을 수행한다. 머신러닝 모델을 릴리스하기 위해서는 반드시 추론환경을 기준으로 모델을 제공해야 할 뿐만 아니라, 추론환경에 적합한 프로그램이나 라이브러리도 같이 작성해야 한다.
학습 방법이나 학습 결과를 연구논문으로 집필하고 학회에서 발표하는 경우는 보통 학습 자체에서 학술적인 가치를 찾을 수 있다. 그러나 비즈니스의 목적으로 모델을 개발한다면 모델이 과제 해결에 직접적인 역할을 해야한다. 즉 학습한 모델을 실제 시스템으로 릴리스해서 가치를 창출해내는 것이 중요하다. 모델을 릴리스하고 실제 환경에서 추론할 수 없다면 실험에 사용한 비용을 낭비하게 되는 셈이다.
이번 포스팅부터 두차례에 걸쳐 모델을 릴리스하는 방법과 안티 패턴에 대해 정리하려고 한다.
학습환경과 추론환경
학습환경
- 풍부한 컴퓨팅 자원
- 코드를 라인 단위로 실행하고, 실험 결과를 검증하면서 개발해 나가는 방식
- 코드리뷰, 단위 테스트, 리팩터링 부재
추론환경
- 장애가 발생한 경우 이를 감지하고 트러블 슈팅을 통해 즉시 복구해야함
- 끊임없이 가동되어야 하므로 자원(CPU, 메모리 등)의 사용량을 최소한으로 조정
- CPU를 컴퓨팅 자원으로 사용할 경우, 라이브러리는 학습환경에서 사용한 GPU 버전이 아닌 CPU 버전 사용
공통
- 모델파일은 학습과 추론에 관계없이 같은 것을 사용
- 전처리에 사용한 라이브러리나 구현방식
- 입출력 데이터의 타입과 shape
추가로 머신러닝은 입력 데이터에 대해 학습한 결과를 출력할 때 내부에서는 기존 컴퓨터 프로그램과 마찬가지로 메모리상에 정의된 데이터를 CPU로 읽어 연산이 이뤄진다. 그러므로 입력 데이터의 타입, Float16과 Float32는 별개로 취급해야 하고, 이에 따라 연산 결과도 달라진다. 파이썬에서는 변수 타입이 동적으로 정해지므로 개발자가 입출력 데이터의 타입을 명시하지 않아도 되지만, 학습 환경을 추론기로 이행할 때는 두 환경에서 다루는 변수의 데이터 타입을 반드시 확인해서 맞춰줘야 한다.
이제 모델 릴리스에서의 안티 패턴에 대해 알아보자.
안티 패턴 (버전 불일치 패턴)
상황
- 학습환경과 추론환경에서 같은 라이브러리를 사용하고 있으나, 라이브러리의 버전이 일치하지 않는 경우
- 추론기로 모델을 불러올 수 없는 경우
- 추론기의 추론 결과가 예상 결과(학습환경에서 예상했던)와 일치하지 않는 경우
구체적인 문제
예를들어 scikit-learn에서 만든 모델을 추론기에 포함하는 경우, 파이썬에서 제공하는 pickle 모듈로 모델을 출력해 .pkl 형식의 파일로 저장한 뒤, 추론기에서는 해당 .pkl 파일로 모델을 불러오는 프로세스가 일반적이다. pickle은 scikit-learn으로 만든 모델(학습한 파라미터를 가지는 클래스 객체)의 인스턴스 변수를 저장한다. .pkl파일을 로딩하면 pickle dump를 통해 저장된 객체의 클래스가 파일를 불러오려는 환경에서 인스턴스화되는 구조다. 따라서 pickle로 저장했던 환경과 그것을 불러오려는 환경에서 라이브러리의 버전이 달라 실제로는 같은 클래스라 할지라도 변수나 함수가 바뀌었을 경우 .pkl 파일을 불러오지 못하게 된다.
프레임워크의 버전도 마찬가지이다. TensorFlow 1.x 버전과 2.x 버전은 구현 방법 등에서 큰 변화가 있었으며, 같은 클래스라도 달라진 사양이 많이 있다(tensorflow.keras 등). PyTorch 역시 항시 호환성이 유지된다고 볼 수 없으며, 버전이 업데이트됨에 따라 기본으로 제공하는 텐서 형식이나 상수 등이 달라지기도 한다. 이와 같은 호환성 문제는 모든 라이브러리에서 발생할 수 있기 때문에 사용하는 쪽(개발자)에서 대처하는 수밖에 없다.
해결 방법
학습환경과 추론환경에서 공통으로 사용되는 라이브러리는 그 버전까지 포함해서 공유하는 구조를 만들어 두는 것이 좋다. 버전을 포함한 라이브러리 목록을 requirements.txt에 저장하여 코드와 함께 관리하고 이를 추론환경에서 pip install -r requirements.txt를 실행해 라이브러리 전체를 설치할 수 있다.(requirements.txt를 처음 생성할 때는 pip list freeze > requirements.txt를 실행)
requirements.txt 파일은 학습할 때만 필요한 라이브러리도 포함되어 있기 때문에 추론에 불필요한 라이브러리는 제외하는 것이 좋다.
모델의 배포와 추론기의 가동
모델 파일을 추론기에 담는 방법도 하나의 시스템으로 설계할 필요가 있다. 일반적으로 모델 파일의 배포 과정에서 겪는 어려움은 아래와 같다.
- 모델 파일이 수 MB 이상의 사이즈인 경우
- 배포 대상 추론기와의 호환성
- 인벤토리 관리
1. 모델 파일이 수 MB 이상의 사이즈인 경우
딥러닝 모델이라면 용량이 수 MB에서 수십 MB까지 차지하는 경우가 흔하다. 따라서 모델을 배포하고 교체하는 과정에서 네트워크 통신과 추론기를 통한 로딩만으로 수십 초 정도가 소요되기도 한다. 그러므로 실제 시스템이 가동 중인 경우라면 모델을 배포하고 갱신하는 중에는 시스템이 멈추지 않도록 검토해야 한다. 시스템을 정지할 수 없다면 canary 방식으로 기존의 추론기와 새로운 추론기의 가동을 병행해 새로운 추론기를 충분한 시간을 두고 교체하는 것이 좋다.
2. 배포 대상 추론기와의 호환성
안티패턴에서 언급한것처럼 추론기에 설치되어 있는 라이브러리의 버전과 모델이 일치해야 추론기를 정상적으로 가동시킬 수 있다. 이미 가동중인 추론기가 있다면 설치된 라이브러리 버전을 관리해 두는 것이 좋다.
3. 인벤토리 관리
여기서 인벤토리란 가동하고 있는 추론기의 OS나 라이브러리, 버전, 가동하고 있는 모델, 입력데이터 형식, 모델 task 등을 의미한다. 물론 길지 않은 기간의 프로젝트라면 모델 하나 정도는 문제없이 가동, 운용할 수도 있겠지만, 세월이 흘러 담당 엔지니어의 이동이 발생하면 언제부터 가동했는지조차 알 수 없는 추론기만 남겨지는 사태가 발생할 수 있다. 추론기의 인벤토리 관리는 매우 중요하다.
추론기에 모델 포함하기
서버에 모델을 포함시켜 추론기로 가동할 때 필요한 컴포넌트는 다음과 같다.
- 인프라: 서버, CPU, 메모리, storage, 네트워크
- OS: Linux, Windows, MacOS 등
- 런타임: ONNX Runtime, TensorFlow Serving, Torch Serve 등
- 모델 파일: 이미 학습된 모델 파일
- 프로그램: 추론 요청에 대해 전처리, 추론, 후처리를 수행하고 응답하는 프로그램
머신러닝에서 모델 파일은 학습할 때마다 생성된다. 모델은 정확도에 따라 그 가치가 달라질 수 있기 때문에 보다 좋은 모델이 학습되었을 경우에 대비해 모델을 손쉽게 릴리스할 수 있는 상태를 준비하는 것이 이상적이다. 바꿔 말하면 모델의 릴리스 사이클과 OS, 런타임, 프로그램의 릴리스 사이클은 서로 일치하지 않으며, 경우에 따라서는 모델이 더 자주 릴리스될 수도 있다. 따라서 효율적으로 모델을 출시함과 동시에 모델을 정상 가동시킬 수 있는 방법이 필요하다.
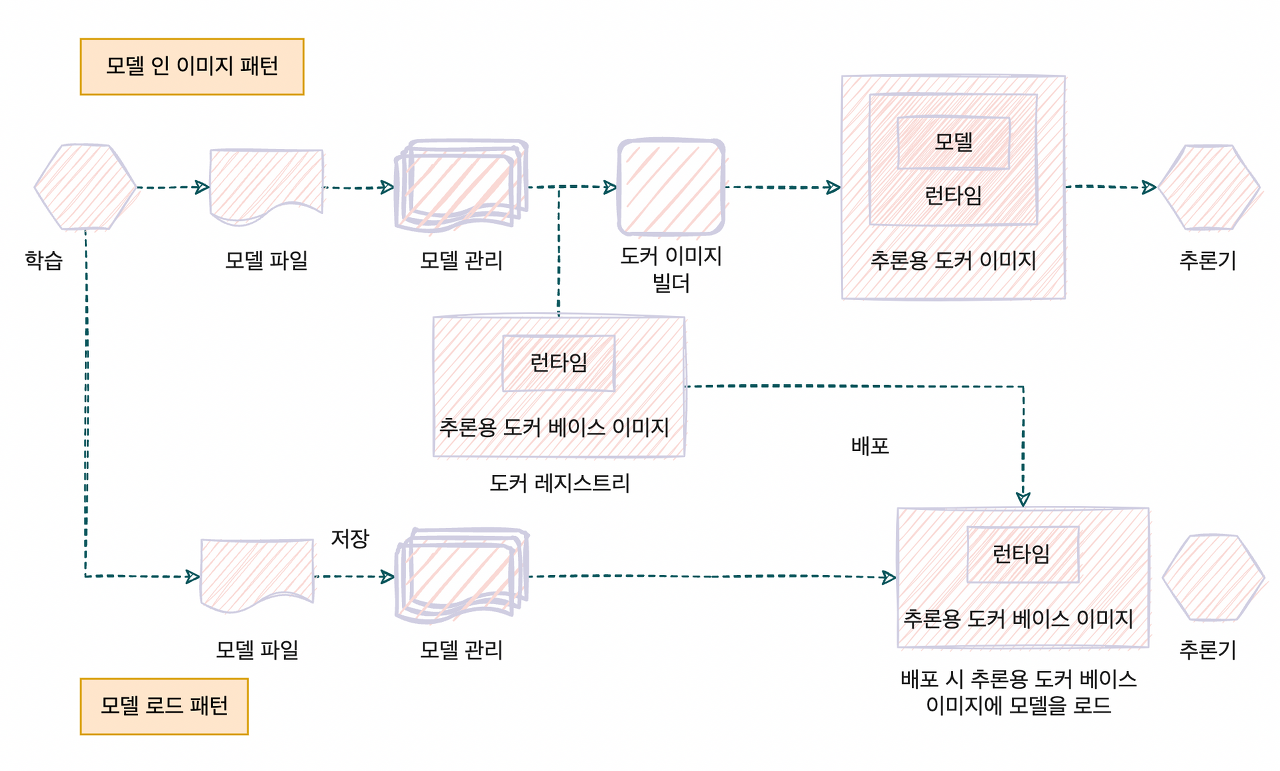
모델을 릴리스하는 방법으로 크게 두 가지를 들 수 있다. 모델을 서버에 포함해 빌드하는 패턴과 가동이 끝난 서버로 외부에서 모델을 불러오는 패턴이다. 아래에서는 모델 인 이미지 패턴에 대해 자세히 다뤄보고 다음 포스팅에서는 모델 로드 패턴에 대해 알아볼 것이다.
모델 인 이미지 패턴
모델 인 이미지 패턴은 추론기의 이미지에 모델 파일을 포함해서 빌드하는 방식이다. 모델을 포함해서 빌드하기 때문에 해당 모델의 전용 추론기 이미지를 생성할 수 있다.
Use Case
- 서버 이미지와 추론 모델의 버전을 일치시켜 한번에 관리하고 싶은 경우
- 추론 모델에 개별 서버 이미지를 준비하는 경우
해결하려는 과제
서버나 모델의 수가 늘어남에 따라 테스트해야 하는 가짓수가 점차 많아지기 때문에 서버와 모델의 모든 조합을 검증하는 것은 불가능하다. 이에 모델 인 이미지 패턴에서는 모델을 포함한 서버(추론기)를 빌드함으로써 오직 built-in 모델만을 가동시키는 서버를 구축한다. 다시 말해, 서버와 모델의 버전을 일치시킬 수 있기 때문에 정상적인 가동이 가능한 서버를 모델과 1대1로 정리할 수 있다는 장점이 있다.
Architecture
모델 인 이미지 패턴에서는 추론 서버의 이미지에 학습이 끝난 모델을 포함시키기 때문에 학습과 서버 이미지의 구축을 일련의 워크를로로 만들 수 있다. 이렇게 하면 서버 이미지와 모델 파일의 버전을 동일하게 관리할 수 있기 때문에 추론기에 설치된 라이브러리의 버전에 따라 가동 가능한 모델을 선정할 필요가 없어진다.
이 패턴은 이미지에 모델이 담겨있기 때문에 추론용 서버 이미지를 빌드하는데 소요되는 시간이 길고, 용량이 증가한다는 단점이 있다. 서버 이미지의 구축은 모델의 학습이 완료된 이후에 이뤄지기 때문에 전 과정을 아울러 구축을 완료하는 파이프라인이 필요하다. 게다가 서버 이미지의 용량이 증가함에 따라 이미지를 pull하고 시스템이 가동될 때까지 소요시간이 길어질 수 있다.
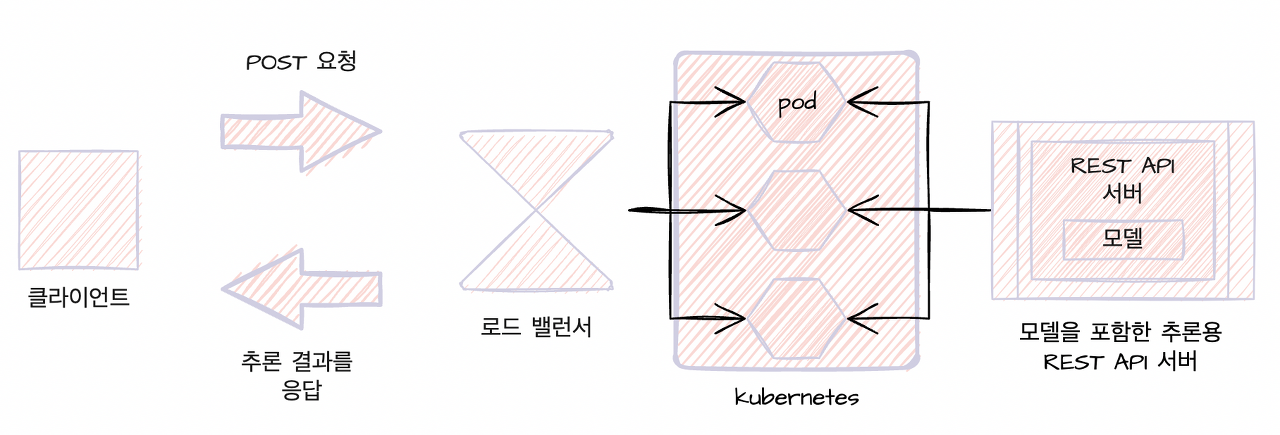
구현
추론기의 인프라로서 쿠버네티스 클러스터를 사용한다. 추론기는 웹 API인 FastAPI + Gunicorn 으로 가동시켜 GET / POST 요청으로 접근을 가능하게 한다. 사용하는 소프트웨어는 아래와 같다.
- Docker
- Kubernetes(GKE)
- 언어: Python 3.8
- 웹 프레임워크: Gunicorn + FastAPI
- 라이브러리: scikit-learn
- 추론 프레임워크: ONNX Runtime
코드가 많기때문에 모델 인 이미지에서 중요한 부분만 가져와 설명을 하고 나머지 부분은 생략하였다.
Dockerfile
FROM python:3.8-slim
ENV PROJECT_DIR model_in_image_pattern
WORKDIR /${PROJECT_DIR}
ADD ./requirements.txt /${PROJECT_DIR}/
RUN apt-get -y update && \
apt-get -y install apt-utils gcc curl && \
pip install --no-cache-dir -r requirements.txt
# apt-get update: 설치가능한 패키지들과 그 버전에 대한 정보를 업데이트
# --no-cache-dir: 하드디스크 용량절약 및 이미지 크기 축소
COPY ./src/ /${PROJECT_DIR}/src/
COPY ./models/ /${PROJECT_DIR}/models/
# 컨테이너에서 활용할 환경변수 설정
ENV MODEL_FILEPATH /${PROJECT_DIR}/models/iris_svc.onnx
ENV LABEL_FILEPATH /${PROJECT_DIR}/models/label.json
ENV LOG_LEVEL DEBUG
ENV LOG_FORMAT TEXT
COPY ./run.sh /${PROJECT_DIR}/run.sh
RUN chmod +x /${PROJECT_DIR}/run.sh
CMD ["./run.sh"]
- 우분투 OS에 Python 3.8 버전을 설치하고 requirements.txt에 작성한 필요 라이브러리를 설치한다.
- 컨테이너에서 사용할 환경변수를 작성하고 gunicorn으로 웹 어플리케이션(FastAPI)를 실행하는 run.sh 파일을 준비한다.
src/app/routers/routers.py
from logging import getLogger
from typing import Dict, List
from fastapi import APIRouter
from src.ml.prediction import Data, classifier
logger = getLogger(__name__)
router = APIRouter()
@router.get('/health')
def health() -> Dict[str, str]:
return {'health': 'ok'}
@router.get('/metadata')
def metadata():
return {
'data_type': 'float32',
'data_structure': '(1,4)',
'data_sample': Data().data, # [[5.1, 3.5, 1.4, 0.2]]
'prediction_type': 'float32',
'prediction_structure': "(1, 3)", # 3 classes
'prediction_sample': [0.971, 0.015, 0.014],
}
@router.get('/label')
def label():
return classifier.label # Classifier 클래스의 self.label은 초기화 과정에서 이미 load_label() 함수를 실행
# 샘플 데이터로 predict test를 진행하는 router
@router.get('/predict/test')
def predict_test() -> Dict[str, List[float]]:
prediction = classifier.predict(data=Data().data)
return {'prediction': list(prediction)}
@router.get('/predict/test/label')
def predict_test_label() -> Dict[str, str]:
prediction = classifier.predict_label(data=Data().data)
return {'predictiom': prediction}
# 입력 데이터를 predict
@router.post('/predict')
def predict(data: Data) -> Dict[str, List[float]]:
prediction = classifier.predict(data=data.data)
return {'prediction': list(prediction)}
@router.post('/predict/label')
def predict_label(data:Data) -> Dict[str, str]:
prediction = classifier.predict_label(data=data.data)
return {'prediction': prediction}
- routers.py 코드는 FastAPI 앱의 엔드포인트에 따른 처리를 정의한다. 간단한 health check와 sample data에 대한 예측, 입력 데이터에 대한 예측을 하는 기능을 작성하였다.
- 여기서 classifier.predict는 ONNX파일을 ONNX Runtime으로 inference하는 사전에 정의된 클래스의 메서드이다.
src/ml/prediction.py
import json
from logging import getLogger
from typing import Dict, List
import numpy as np
import onnxruntime as rt
from pydantic import BaseModel
from src.configurations import ModelConfigurations
logger = getLogger(__name__)
class Data(BaseModel):
data: List[List[float]] = [[5.1, 3.5, 1.4, 0.2]]
class Classifier(object):
def __init__(
self,
model_filepath: str,
label_filepath: str,
):
self.model_filepath: str = model_filepath
self.label_filepath: str = label_filepath
self.classifier = None
self.label: Dict[str, str] = {}
self.input_name: str = ""
self.output_name: str = ""
self.load_model()
self.load_label()
def load_model(self):
logger.info(f"load model in {self.model_filepath}")
self.classifier = rt.InferenceSession(self.model_filepath)
self.input_name = self.classifier.get_inputs()[0].name
self.output_name = self.classifier.get_outputs()[0].name
logger.info("initialized model")
def load_label(self):
logger.info(f"load label in {self.label_filepath}")
with open(self.label_filepath, "r") as f:
self.label = json.load(f)
logger.info(f"label: {self.label}")
def predict(self, data: List[List[int]]) -> np.ndarray:
np_data = np.array(data).astype(np.float32)
prediction = self.classifier.run(None, {self.input_name: np_data})
output = np.array(list(prediction[1][0].values()))
logger.info(f"predict proba {output}")
return output
def predict_label(self, data: List[List[int]]) -> str:
prediction = self.predict(data=data)
argmax = int(np.argmax(np.array(prediction)))
return self.label[str(argmax)]
classifier = Classifier(
model_filepath=ModelConfigurations().model_filepath,
label_filepath=ModelConfigurations().label_filepath,
)
- Classifier 클래스가 초기화되면서 모델과 라벨정보를 로드하게 된다.
- predict 메서드는 모델의 순수 output으로 softmax를 거친 numpy array가 return되고 predict_label 메서드는 predict의 output을 라벨로 인코딩하여 return하는 역할을 한다.
- 아랫줄레 model_filepath와 label_filepath는 Dockerfile에 작성한 환경변수를 활용한다.
쿠버네티스에서 도커 이미지를 활용하기 위해 Dockerfile을 빌드하고 도커 허브에 push한다. 쿠버네티스에서는 YAML 형식의 파일을 통해 사용할 리소스를 정의한다.
manifests/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-in-image
namespace: model-in-image
labels:
app: model-in-image
spec:
replicas: 4
selector:
matchLabels:
app: model-in-image
template:
metadata:
labels:
app: model-in-image
spec:
containers:
- name: model-in-image
image: visionhong/ml-system-in-actions:model_in_image_pattern_0.0.1
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
---
apiVersion: v1
kind: Service
metadata:
name: model-in-image
namespace: model-in-image
labels:
app: model-in-image
spec:
ports:
- name: rest
port: 8000
protocol: TCP
selector:
app: model-in-image
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: model-in-image
namespace: model-in-image
labels:
app: model-in-image
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: model-in-image
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- deployment 에서는 이미지의 이름과 버전이 맞는지, 컨테이너 port가 맞는지 잘 확인해야 한다.
- 현재 gunicorn에 바인딩 된 서버 소켓의 컨테이너 port는 8000번(run.sh 확인) 이기 때문에 containerPort를 8000으로 적어주었다.
- replicas: 4로 인해 pod는 4개가 생성될 것이며 각 pod의 리소스는 cpu 0.5 코어, memory 300MB로 제한하였다.
- 서비스 타입은 ClusterIP(내부 네트워크) 8000번 포트로 공개된다.
- cpu 사용률을 체크하여 pod의 개수를 scaling하는 기능인 HPA(HorizontalPodAutoscaler를 추가하였다. cpu의 평균 사용률이 50%가 유지되도록 pod의 개수를 최소 3개부터 최대 10개까지 조정 가능하도록 설정했다.
매니페스트 파일을 쿠버네티스 클러스터에 배포했을때 아래와 같이 pod가 running 상태가 된다면 정상 작동하는 것이다.
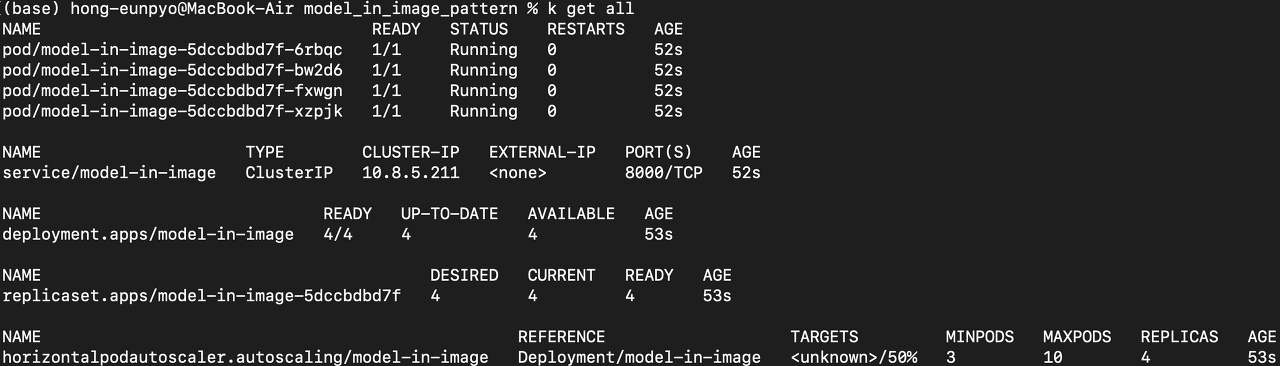
쿠버네티스 클러스터 내부 엔드포인트에 포트 포워딩하기 위해 다음 명령어를 실행한다. (& 옵션으로 백그라운드 실행)
k -n model-in-image port-forward deployment/model-in-image 8000:8000 &
지난 포스팅에서도 말했듯이 FastAPI는 작성한 router에 대해 자동으로 API 문서(swagger)를 만들어준다. swagger는 http://localhost:8000/docs 주소로 접속할 수 있다.
이제 배포한 추론기에 테스트 데이터를 POST 요청해보자.
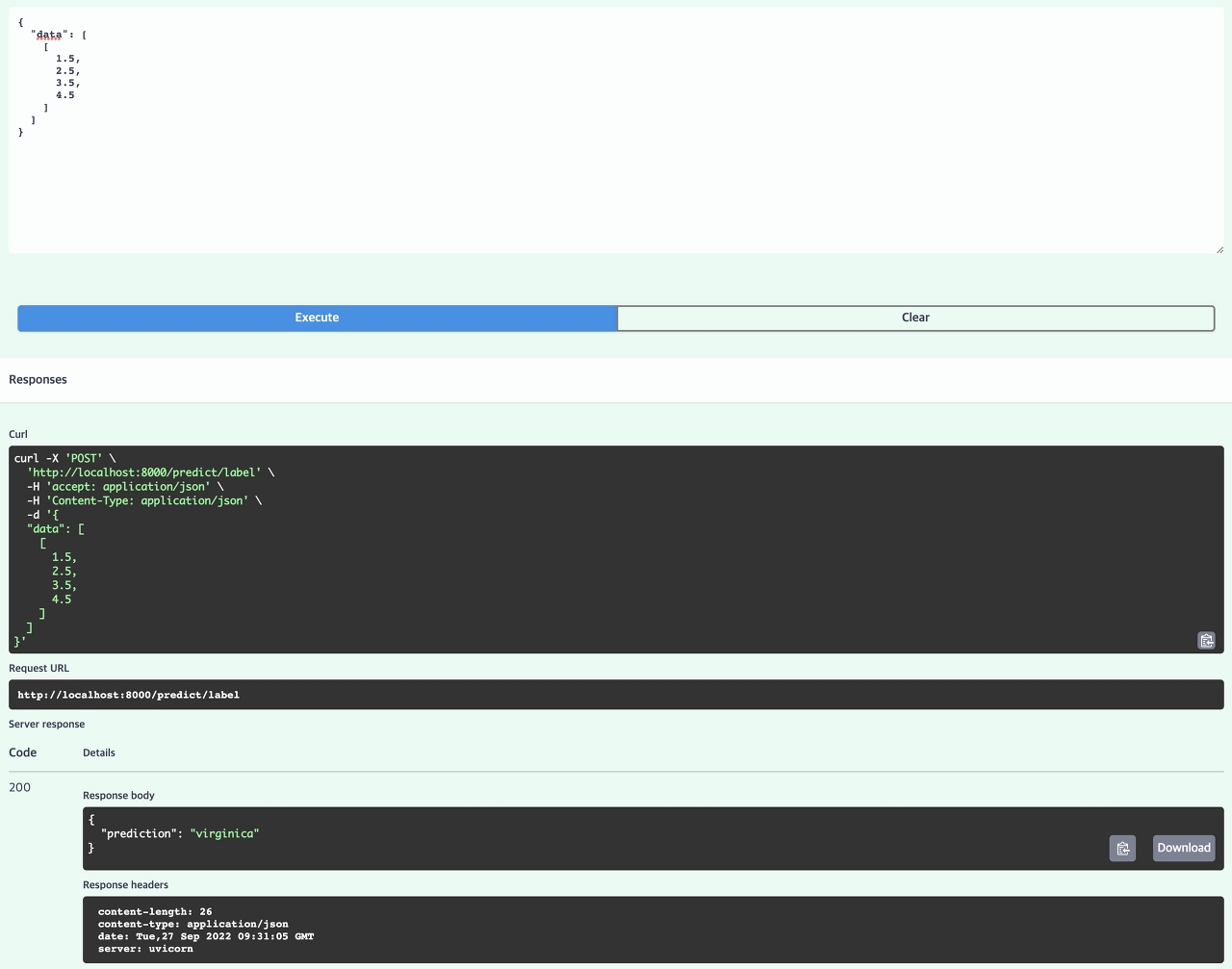
- 데이터를 형식에 맞게 입력하고 실행하면 아래와 같이 virginica 라는 예측 결과가 정상적으로 나온것을 확인할 수 있다.
이점
- 가동 확인이 끝난 서버와 모델의 편성을 하나의 추론용 서버 이미지로 관리가 가능함
- 서버와 모델을 1대1 대응으로 관리할 수 있어 운용상 간편함
검토사항
모델 인 이미지 패턴에서 도커 이미지를 사용한다면 Dockerfile에 모델을 포함하는 과정이 필요하고, 빌드할때 모델 파일을 가져오는 처리가 필요하다.
결국 모델 인 이미지 패턴은 학습한 모델의 수만큼 서버 이미지의 수도 늘어나는 구조다. 따라서 모델 파일과 서버 이미지를 모두 저장하기 위해 필요한 스토리지 용량도 점차 증가하기 마련이다. 불필요한 서버 이미지를 삭제하지 않으면 스토리지 비용이 증가하기 때문에 정기적으로 불필요한 이미지를 삭제하는 작업이 필요하다.
서버 이미지 자체가 모델을 포함하고 있는 만큼 사이즈는 커지게 되고, 추론기를 가동하기 위해 서버 이미지를 다운받는 시간도 길어진다. 추론기를 도커 이미지를 통해 가동하는 경우 도커 컨테이너를 실행하는 호스트 인스턴스에 도커 이미지를 pull하지 않으면 해당 도커 이미지를 다운로드 해야 한다. 이 소요 시간을 추론기의 가동과 스케일 아웃의 소요 시간으로 생각할 수 있다. 이를 해결하기 위해 서버의 베이스 이미지를 미리 다운로드 받아놓고 모델 파일 추가 레이어부터 다운로드 할 수 있도록 한정 짓는 등의 방법을 고려할 수도 있을 것이다.
결과적으로, 모델 인 이미지 패턴에서 해결해야 할 과제는 서버 이미지의 사이즈가 늘어남에 따라 발생하는 스토리지의 비용과 스케일 아웃의 지연으로 볼 수 있다.
End
이번 포스팅에서는 모델 릴리스 관점에서 학습 환경과 추론 환경의 차이와 모델 릴리스 패턴중 하나인 모델 인 이미지 패턴에 대해 알아보았다. 모델 로드 패턴은 이어지는 포스팅에서 다룰 예정이다.
Keep Going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter3_release_patterns/model_in_image_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/release_patterns/model_in_image_pattern
Leave a comment