
[ML Design Pattern] 모델 릴리스 / 2.모델 로드 패턴
모델 로드 패턴
지난 포스팅에서는 릴리스 과정에 있어서 모델을 서버 이미지에 포함하는 방법인 모델 인 이미지 패턴에 대해 알아보았다. 이번에는 모델을 서버 이미지에 built-in 하지 않고 추론기를 가동할 때 다운로드 받아 적용하는 모델 로드 패턴에 대해 알아보자
Use Case
- 서버 이미지 버전보다 추론 모델의 버전을 더 빈번하게 갱신하는 경우
- 동일한 서버 이미지로 여로 종류의 추론 모델 가동이 가능한 경우
해결하려는 과제
모델 인 이미지 패턴은 서버 이미지의 빌드가 빈번하게 발생하고 서버 이미지의 사이즈가 증가한다는 단점이 있었다. 예를 들어 동일한 전처리 기법과 동일한 알고리즘을 다른 데이터셋으로 여러 번 학습하는 경우, 학습할 때마다 서버 이미지를 빌드하는 것은 운용면에서 합리적이라고 볼 수 없다. 이미 범용적인 학습 파라미터가 선정되어 있을 때는 데이터셋만 지속적으로 바꾸어 가며 새로운 모델을 생성하는 것이 바람직하다. 이러한 워크플로에서 개발이 진행된다면 모델 로드 패턴이 최적의 모델 배포 방법이 될 수 있다.
Architecture
모델 로드 패턴에서는 추론 서버의 이미지 구축과 모델의 저장이 따로 이뤄지므로 서버 이미지를 경량화할 수 있다. 또한, 서버 이미지의 범용성을 높여 동일한 서버 이미지를 여러 개의 추론 모델에 응용할 수도 있다.
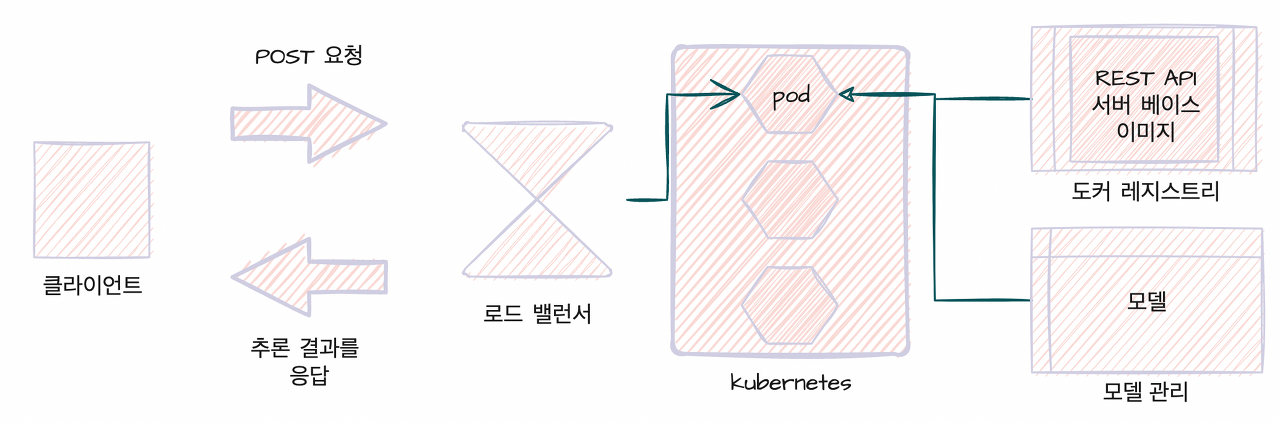
추론기를 배치할 때 서버 이미지를 pull 하고 난 뒤 추론기를 기동하고, 이후에 모델 파일을 로드해서 추론기를 본격적으로 가동한다. 환경변수 등으로 추론 서버에서 가동하는 모델을 유연하게 변경할 수도 있다.
이 패턴의 단점은 모델이 라이브러리의 버전에 의존적일 경우에 서버 이미지의 버전 관리와 모델 파일의 버전관리를 별도로 수행해야 한다는 것이다. 서버 이미지와 모델의 지원 여부를 지속적으로 작성해야 하기 때문에 서버 이미지와 모델이 많아지고 복잡해질수록 운용 부하가 커질 위험이 있다.
구현
구현 환경은 모델 인 이미지 패턴과 동일하며 소스코드와 모델파일 또한 모델 인 이미지 패턴과 동일하다. 중요하게 변경된 부분만 짚고 넘어가보자
모델 로드 패턴은 어딘가에 저장되어있는 모델을 추론기로 가져와야 하기 때문에 먼저 모델을 등록해 놓을 필요가 있다. 현재 쿠버네티스 환경이 GKE 이기 때문에 GCP Cloud Storage(gcs)에 bucket을 생성하고 학습된 모델파일을 업로드 하였다.
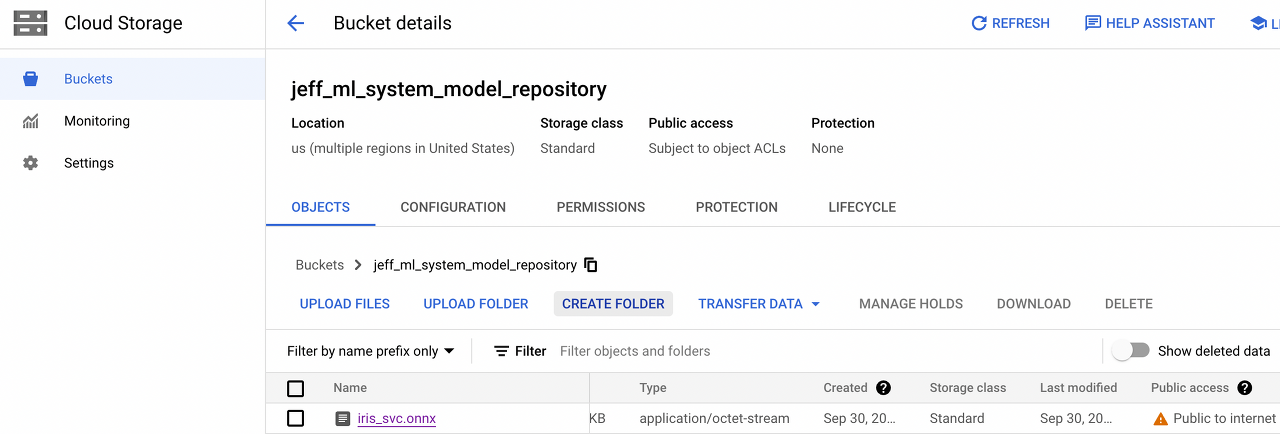
- bucket 이름: jeff_ml_system_model_repository
- 모델 파일 이름: iris_svc.onnx
gcs에 모델파일을 저장했으니 실제 컨테이너에서 gcs에 저장된 모델을 불러오는 코드를 작성해보자.
model_loader/main.py
import os
from logging import DEBUG, Formatter, StreamHandler, getLogger
import click
from google.cloud import storage
logger = getLogger(__name__)
logger.setLevel(DEBUG)
strhd = StreamHandler()
strhd.setFormatter(Formatter("%(asctime)s $(levelname)8s %(message)s"))
logger.addHandler(strhd)
@click.command(name="model loader")
@click.option("--gcs_bucket", type=str, required=True, help="GCS bucket name")
@click.option("--gcs_model_blob", type=str, required=True, help="GCS model blob path")
@click.option("--model_filepath", type=str, required=True, help="Local model file path")
def main(gcs_bucket, gcs_model_blob, model_filepath):
logger.info(f"download from gs://{gcs_bucket}/{gcs_model_blob}")
dirname = os.path.dirname(model_filepath) # 인자값으로 들어온 경로에서 맨 뒤 파일명을 제외한 경로 반환
os.makedirs(dirname, exist_ok=True)
client = storage.Client.create_anonymous_client()
bucket = client.bucket(gcs_bucket)
blob = bucket.blob(gcs_model_blob)
blob.download_to_filename(model_filepath)
logger.info(f"download from gs://{gcs_bucket}/{gcs_model_blob} to {model_filepath}")
if __name__ == '__main__':
main()
- 모델을 로드하기 위해 사용되는 추가 라이브러리는 google-cloud-storage와 click 이다. google-cloud-storage는 gcs의 파일을 가져올때 사용되며 click은 argparse처럼 파이썬 스크립트의 command를 추가할때 사용된다.
- 이 파이썬 스크립트가 실행되는 환경은 컨테이너이기 때문에 model_filepath는 모델파일을 저장할 컨테이너 경로가 된다.
- Client.create_anonymous.client()를 사용해서 bucket내의 blob에 접근하려면 public 설정이 되어 있어야 한다. (참고)
- 만약 public을 원하지 않는 경우 service account key를 생성하고 컨테이너 환경변수로 key file(json)의 경로를 설정하여야 한다. (참고)
위 파이썬 스크립트를 실행할 컨테이너는 추론기를 실행하는 컨테이너와 별개로 둘 것이기 때문에 모델 로드 전용 이미지가 필요하다. 모델 로드 이미지를 빌드하기 위한 Dockerfile은 다음과 같다. (추론기 컨테이너 Dockerfile 변경점은 MODEL_FILEPATH 환경변수가 사라진 것 외에 동일하므로 생략)
model_loader/Dockerfile
FROM python:3.8-slim
ENV PROJECT_DIR model_load_pattern
WORKDIR /${PROJECT_DIR}
COPY ./model_loader/requirements.txt /${PROJECT_DIR}/
COPY ./model_loader/main.py /${PROJECT_DIR}/src/
RUN apt-get -y update && \
apt-get -y install apt-utils gcc && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
pip install --no-cache-dir -r requirements.txt
- 명령어는 작성하지 않고 파이썬 3.8환경에 두개의 라이브러리(google-cloud-storage, click)를 설치만 해둔다. (실행 명령어는 kubernetes manifest 파일에서 작성)
이제 쿠버네티스에 컨테이너를 배포하기 위한 manifest를 작성해보자. 모델 인 이미지 패턴과는 다르게 init container가 추가된다.
manifests/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-load
namespace: model-load
labels:
app: model-load
spec:
replicas: 4
selector:
matchLabels:
app: model-load
template:
metadata:
labels:
app: model-load
spec:
containers:
- name: model-load
image: visionhong/ml-system-in-actions:model_load_pattern_api_0.0.1 # 추론 이미지
ports:
- containerPort: 8000
resource:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
volumeMounts:
- name: workdir
mountPath: /workdir
env:
- name: MODEL_FILEPATH # 두 컨테이너가 mount하고 있는 폴더의 모델 경로
value: "/workdir/iris_svc.onnx"
initContainers:
- name: model-loader
image: visionhong/ml-system-in-actions:model_load_pattern_loader_0.0.1 # 모델 로드 이미지
imagePullPolicy: Always
command:
- python
- "-m"
- "src.main"
- "--gcs_bucket"
- "jeff_ml_system_model_repository"
- "--gcs_model_blob"
- "iris_svc.onnx"
- "--model_filepath"
- "/workdir/iris_svc.onnx"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes: # 컨테이너 간의 파일 공유를 위해 emptyDir volume 사용
- name: workdir
emptyDir: {}
- 모델이 없는 상태에서 추론을 실행할 수 없기 때문에 initContainer를 활용해 모델을 먼저 로드하도록 한다. init container는 컨테이너를 기동하기 전에 필요한 초기화를 진행할 수 있다.(init container는 자신의 역할만 수행하고 종료되기 때문에 컨테이너 개수로 잡히지 않는다.)
- 모델 로드 Dockerfile에 없던 파이썬 스크립트 파일 실행 명령어를 여기서 작성한다. (오타 주의)
- 두 컨테이너의 같은경로에 볼륨을 생성하여 모델 파일을 주고받을 수 있도록 한다.
- 모델 인 이미지 패턴과 달리, 추론기 컨테이너에서는 imagePullPolicy: Always는 지정하지 않는다. 추론기 도커 이미지가 노드에 존재하면 매번 pull하지 않고 기존의 이미지를 사용하며, 모델의 업데이트는 initContainers가 커버하는 구조다.
Pod를 조회해서 배포한 추론기가 정상적으로 작동하는지 확인해보자.
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# model-load-8c66566bd-4vx85 1/1 Running 0 14s
# model-load-8c66566bd-hdhgr 1/1 Running 0 14s
# model-load-8c66566bd-rphr5 1/1 Running 0 14s
# model-load-8c66566bd-ztflm 1/1 Running 0 14s
- 4개의 pod가 정상적으로 작동한다. 이때 READY를 보면 Pod당 1개의 컨테이너가 존재한다는 것을 유의하자.(init container는 잡히지 않음)
추론서버에 inference 요청을 테스트하기 전에 특정 Pod의 추론기 컨테이너의 mount path에 모델이 존재하는지 추론기 컨테이너에 접속해서 확인해보자.
kubectl exec -it model-load-8c66566bd-hdhgr -c model-load -- ls /workdir
# iris_svc.onnx
- 모델 로드 컨테이너로부터 모델이 잘 로드되어 추론서버(pod)에 모델이 포함된 것을 볼 수 있다.
이제 서비스를 port-forward 하여 테스트 데이터로 inference를 진행해보자.
# 포트포워딩
kubectl port-forward svc/model-load 8000:8000 &
# test data request
curl -X 'POST' \
'http://localhost:8000/predict/label' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"data": [
[
2.1,
4.5,
3.7,
5.2
]
]
}'
# {"prediction":"virginica"}
- swagger 대신 CLI에서 curl 명령어로 요청을 해보았을때 예측한 라벨로 응답이 정상적으로 반환되는 것을 볼 수 있다.
지금까지 모델 로드 패턴의 구현 방법에 대해 살펴보았다. 모델 인 이미지 패턴과 마찬가지로 쿠버네티스 manifest를 사용한 예시를 보였지만 실제 시스템에 도입하는 경우에는 추론기의 실행 환경에 따라 모델을 가져오는 방법을 변경해야 한다.(BentoML Serving 에서 MLflow 모델 로드 등)
이점
- 서버 이미지의 버전과 모델 파일의 버전이 분리 가능함
- 서버 이미지의 응용성이 향상됨
- 서버 이미지가 가벼워짐
검토사항
모델 로드 패턴에서는 서버 이미지와 모델의 버전 불일치를 해결하는 구조가 필요하다. 학습에서 사용한 라이브러리의 업데이트가 발생하면 추론기의 입장에서도 라이브러리의 업데이트가 수반되어야 한다. 그리고 추론기에서 사용 중인 라이브러리에 취약성(보안 등)이 발견되면 학습에 사용한 라이브러리를 포함해서 업데이트해야 하는 경우도 발생한다. 이러한 경우에는 범용적으로 사용할 추론 서버 이미지를 다시 만들 필요가 있다.
End
모델 로드 패턴이 항상 신속하게 추론기를 가동시킬 수 있는 것은 아니다. 모델 로드 패턴에서는 기동할 때마다 모델 파일을 다운로드하기 때문에 리드 타임을 고려할 필요가 있다. 그러나 모델 인 이미지 패턴에서는 한 번의 도커 이미지 다운로드를 통해 추론기를 기동시킬 수 있다. 초기 기동에 관해서는 모델 로드 패턴이 확실히 모델 인 이미지 패턴보다 빠르지만, 스케일 아웃 하는 경우라면 모델 인 이미지 패턴이 효율적인 경향이 있다.
모델 인 이미지 패턴으로 도커 이미지 다운로드 속도를 높이고 싶다면 해당 도커 이미지 용량을 줄여야 한다. 도커 이미지에 불필요한 라이브러리나 자원을 저장하지 않아야 하며, 도커 이미지의 레이어를 필요 이상으로 늘리지 않도록 대책이 필요하다.
신속한 모델 로드 패턴을 추구한다면 모델의 다운로드 속도를 높이기 위한 대책이 필요하다. 모델 파일을 추론기 근처에 저장하거나 CDN(Contents Delivery Network)를 이용해 배포하는 방법이 있다. (CDN: 지리적 제한 없이 전 세계 사용자에게 빠르고 안전하게 콘텐츠를 전송할 수 있는 콘텐츠 전송 기술)
추론기를 실제 시스템에서 가동하기 위해서는 모델의 작동뿐만 아니라, 시스템으로서 비즈니스 요구를 충족시키는 기능과 비기능 등을 준비해야 한다. 이를 위해서는 추론기의 아키텍처로서 비즈니스 요구를 충족시키는 구현이 필요하다.
이제부터는 모델을 실제 시스템에서 가동시키기 위한 추론기를 만드는 방법을 다양한 패턴으로 정리할 것이다.
Keep going
Reference
Book: AI 엔지니어를 위한머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter3_release_patterns/model_load_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/release_patterns/model_load_pattern
Leave a comment