
[ML Design Pattern] 추론 시스템 / 2. 동기 추론 패턴
동기 추론 패턴
외부 클라리언트에서 웹 API로 추론 요청이 있을 때의 처리 방법에는 크게 동기처리와 비동기처리 두 가지가 있다. 이번 포스팅에서는 동기적인 처리 방법을 TensorFlow Serving을 활용해서 정리한다.
Use Case
- workflow가 추론 결과에 의존할 경우
- 시스템의 workflow에서 추론 결과가 나올 때까지 다음 단계로 진행이 되지 않는 경우
해결하려는 과제
클라이언트의 애플리케이션은 추론 결과에 따라 이어지는 처리를 달리하는 경우가 있다. 예를 들어, 핸드폰 액정필름 생산라인에서 제조되는 액정필름 표면의 이상을 검지하는 시스템을 생각해 보자. 이때, 시스템은 액정필름을 카메라로 촬영하여 정상이면 출품 라인으로, 이상이 발견되면 사람이 재차 확인하는 라인으로 내보내는 workflow를 가진다. 그렇다면, 제조라인을 따라 들어오는 액정필름에 대해 정상, 비정상으로 판정하는 추론 결과에 따라 후속처리가 결정될 것이므로 계속해서 라인을 타고 이동하는 각 액정필름의 이상 여부를 신속하게 응답해야 한다.
각각의 요청에 대해 즉시, 다시 말해, 요청에 동기화하여 추론해 나가기 때문에 동기 추론 패턴인 것이다.
Architecture
동기 추론 패턴에서는 머신러닝의 추론을 동기적으로 처리해 나간다. 클라이언트는 추론 요청을 전송한 후, 응답을 얻을 때까지 후속처리를 진행하지 않고 대기한다. 머신러닝의 추론 서버를 REST API 또는 gRPC로 구성했을 경우 동기 추론 패턴이 되는 경우가 많다.
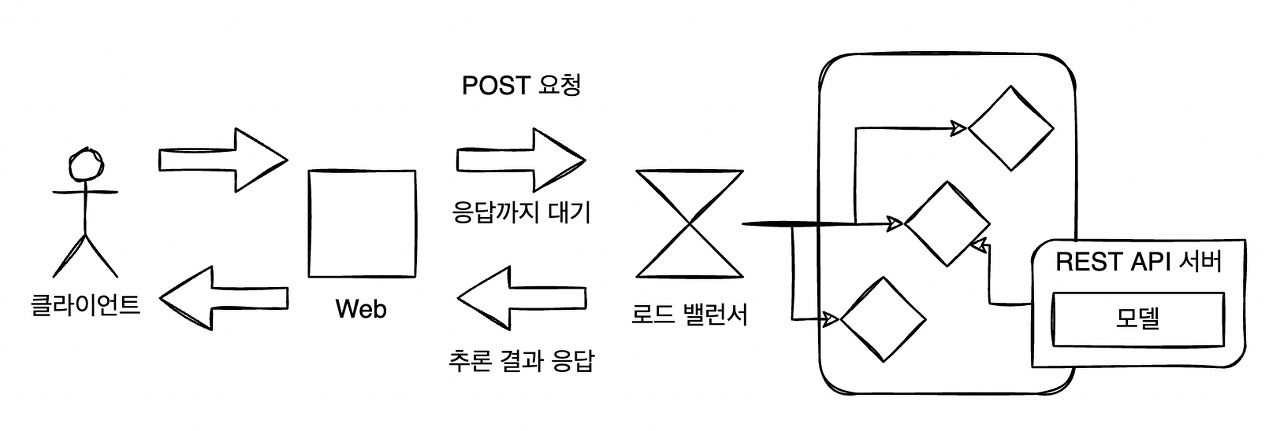
동기 추론 패턴을 사용하면 추론을 포함한 workflow를 순차적으로 만들 수 있고, 동시에 간단한 workflow를 유지할 수 있다. 이 패턴은 구현과 운용이 간단하고 광범위하게 활용할 수 있는 아키텍쳐다.
동기 추론 패턴에서는 데이터 입력부터 전처리, 추론, 후처리, 출력까지를 차례로 실행하는 구성이다. 그렇기 때문에 추론 프로세스 일부에 느린 처리가 들어가 있는 경우, 추론기의 지연으로 클라이언트를 기다리게 하는 사태가 발생한다. 좋은 사용자 경험을 위해 사용자가 기다리는 시간에 제한을 두는 경우에는 추론 프로세스를 고속화하거나 비동기 추론 패턴을 활용하는 것이 좋다.
구현
동기 추론 패턴은 웹 싱글 패턴과 거의 같은 아키텍쳐로 구성할 수 있기 때문에 이번에는 웹 프레임워크인 Fast API 대신 TensorFlow Serving을 활용해 딥러닝 이미지 분류 모델을 기동하는 구현 방식으로 진행한다.
머신러닝 모델이 포함된 추론기를 기동해주는 런타임으로 기존의 웹 프레임워크(Django, Flask, FastAPI)를 사용하는 것 이외에도, TensorFlow Serving이나 ONNX Runtime Server를 사용할 수 있다. 특히 TensorFlow나 Keras에서 개발한 모델은 TensorFlow Serving에서 가동하면 효율적인 자원 사용이 가능해 매우 안정적인 것이 특징이다.
TensorFlow Serving에서는 TensorFlow의 SavedModel이라는 바이너리 형식으로 출력된 파일을 읽어 추론 API를 기동할 수 있다. API는 표준으로 gRPC와 REST API 엔드포인트를 제공한다.
imagenet_inception_v3/extract_inception_v3.py
import json
from typing import List
import tensorflow as tf
import tensorflow_hub as hub
def get_label(json_path: str = "./image_net_labels.json") -> List[str]:
with open(json_path, 'r') as f:
labels = json.load(f)
return labels
def load_hub_model() -> tf.keras.Model:
model = tf.keras.Sequential([hub.KerasLayer("https://tfhub.dev/google/imagenet/inception_v3/classification/4")])
model.build([None, 299, 299, 3])
return model
class InceptionV3Model(tf.keras.Model):
def __init__(self, model: tf.keras.Model, labels: List[str]):
super(InceptionV3Model, self).__init__()
self.model = model
self.labels = labels
# @tf.function 데코레이션을 사용하면 tf 1.x 스타일로 해당 함수 내의 로직이 동작해서 상황에 따라 속도가 약간 빨라질 수 있음
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="image")])
def serving_fn(self, input_img: str) -> tf.Tensor:
def _base64_to_array(img):
img = tf.io.decode_base64(img)
img = tf.io.decode_jpeg(img)
img = tf.image.convert_image_dtype(img, tf.float32)
img = tf.image.resize(img, (299, 299))
img = tf.reshape(img, (299, 299, 3))
return img
# inference
img = tf.map_fn(_base64_to_array, input_img, dtype=tf.float32)
predictions = self.model(img)
def _convert_to_label(predictions):
max_prob = tf.math.reduce_max(predictions) # softmax 결과에서 가장 확률이 높은 클래스 선택
idx = tf.where(tf.equal(predictions, max_prob)) # 클래스 인덱스 get
label = tf.squeeze(tf.gather(self.labels, idx)) # 라벨 목록에서 라벨 get
return label
return tf.map_fn(_convert_to_label, predictions, dtype=tf.string)
def save(self, export_path="./saved_model/inception_v3/"):
signatures = {"serving_default": self.serving_fn}
tf.keras.backend.set_learning_phase(0) # torch의 model.eval()과 비슷 / 0: test 1: train
tf.saved_model.save(self, export_path, signatures=signatures)
def main():
labels = get_label(json_path="./image_net_labels.json")
inception_v3_hub_model = load_hub_model()
inception_v3_model = InceptionV3Model(inception_v3_hub_model, labels)
version_number = 0
inception_v3_model.save(export_path=f"./saved_model/inception_v3/{version_number}")
if __name__ == '__main__':
main()
- 위는 TensorFlow의 operation으로 데이터가 입력된 후의 전처리부터 추론, 후처리까지의 과정을 커버한다. -> 모든 과정을 TensorFlow에 포함하여 서버 간 데이터 통신 횟수를 줄이고 효율적인 추론 수행 가능
- 전체 과정은 tf.saved_model에 포함되어 출력되며 saved_model은 TensorFlow Serving 이미지를 통해 추론기로서 가동시킬 수 있다.
imagenet_inception_v3/Dockerfile
FROM tensorflow/tensorflow:2.5.1 as builder
ARG SERVER_DIR=imagenet_inception_v3
ENV PROJECT_DIR synchronous_pattern
WORKDIR /${PROJECT_DIR}
ADD ./${SERVER_DIR}/requirements.txt /${PROJECT_DIR}/
RUN apt-get -y update && \
apt-get -y install apt-utils gcc && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
pip install --no-cache-dir -r requirements.txt
# apt-get clean: /var/cache/apt/archives 디렉토리에 다운로드한 파일을 삭제해서 공간확보
COPY ./${SERVER_DIR}/extract_inception_v3.py /${PROJECT_DIR}/extract_inception_v3.py
COPY ./${SERVER_DIR}/image_net_labels.json /${PROJECT_DIR}/image_net_labels.json
RUN python -m extract_inception_v3
FROM tensorflow/serving:2.5.2
ARG SERVER_DIR=imagenet_inception_v3
ENV PROJECT_DIR synchronous_pattern
ENV MODEL_NAME inception_v3
ENV MODEL_BASE_PATH /${PROJECT_DIR}/saved_model/${MODEL_NAME}
COPY --from=builder /${PROJECT_DIR}/saved_model/inception_v3 ${MODEL_BASE_PATH}
EXPOSE 8500
EXPOSE 8501
COPY ./${SERVER_DIR}/tf_serving_entrypoint.sh /usr/bin/tf_serving_entrypoint.sh
RUN chmod +x /usr/bin/tf_serving_entrypoint.sh
ENTRYPOINT ["/usr/bin/tf_serving_entrypoint.sh"]
- TF Serving의 구성 방식은 1단계: saved_model 저장, 2단계: 추론 으로 나누어 볼 수 있기 때문에 도커 이미지는 multi stage build 방식으로 생성한다.
- 첫번째 이미지는 saved_model을 컨테이너에 저장하는 역할만 수행하며 실질적으로 추론을 위한 TF Serving 실행은 두번째 이미지에서 이루어 진다.
imagenet_inception_v3/tf_serving_entrypoint.sh
#!/bin/bash
set -eu
PORT=${PORT:-8500}
REST_API_PORT=${REST_API_PORT:-8501}
MODEL_NAME=${MODEL_NAME:-"inception_v3"}
MODEL_BASE_PATH=${MODEL_BASE_PATH:-"/synchronous_pattern/saved_model/${MODEL_NAME}"}
tensorflow_model_server \
--port=${PORT} \
--rest_api_port=${REST_API_PORT} \
--model_name=${MODEL_NAME} \
--model_base_path=${MODEL_BASE_PATH}
- TF Serving 서버 실행을 위한 shell script
TF Seving의 도커 이미지를 빌드하고 컨테이너를 실행해보자.
docker build \
--network=host \
-t visionhong/ml-system-in-actions:synchronous_pattern_imagenet_inception_v3_0.0.1 \
-f imagenet_inception_v3/Dockerfile .
docker run \
-d \
--name imagenet_inception_v3 \
-p 8500:8500 \
-p 8501:8501 \
visionhong/ml-system-in-actions:synchronous_pattern_imagenet_inception_v3_0.0.1
- TF Serving에서는 gRPC와 REST API의 엔드포인트를 표준으로 공개한다. gRPC 포트 번호는 8500, REST API 포트 번호는 8501이다.
이제 파이썬으로 gRPC 및 REST API에 추론 요청을 보내는 코드를 작성해보자.
client/request_inception_v3.py
import base64
import json
import click
import grpc
import requests
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2, prediction_service_pb2_grpc
def read_image(image_file: str="./horse.jpg") -> bytes:
with open(image_file, "rb") as f: # 이미지를 바이트로 read
raw_image = f.read()
return raw_image
def request_grpc(
image: bytes,
model_spec_name: str = "inception_v3",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8500,
timeout_second: int = 5,
) -> str:
serving_address = f"{address}:{port}"
channel = grpc.insecure_channel(serving_address)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
base64_image = base64.urlsafe_b64encode(image) # 바이트를 base64로 인코딩
request = predict_pb2.PredictRequest()
request.model_spec.name = model_spec_name
request.model_spec.signature_name = signature_name
request.inputs["image"].CopyFrom(tf.make_tensor_proto([base64_image]))
response = stub.Predict(request, timeout_second)
prediction = response.outputs["output_0"].string_val[0].decode("utf-8")
return prediction
def request_rest(
image: bytes,
model_spec_name: str = "inception_v3",
address: str = "localhost",
port: int = 8501,
):
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict"
headers = {"Content-Type": "application/json"}
base64_image = base64.urlsafe_b64encode(image).decode("ascii")
request_dict = {"inputs": {"image": [base64_image]}}
response = requests.post(
serving_address,
json.dumps(request_dict),
headers=headers,
)
return dict(response.json())['outputs'][0]
def request_metadata(
model_spec_name: str = "inception_v3",
address: str = "localhost",
port: int = 8501,
):
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}/versions/0/metadata"
response = requests.get(serving_address)
return response.json()
@click.command(name="inception v3 image classification")
@click.option("--format", "-f", default="GRPC", type=str, help="GRPC or REST request")
@click.option("--image_file", "-i", default="./horse.jpg", type=str, help="input image file path")
@click.option("--target", "-t", default="localhost", type=str, help="target address")
@click.option("--timeout_second", "-s", default=5, type=int, help="timeout in second")
@click.option("--model_spec_name", "-m", default="inception_v3", type=str, help="model spec name")
@click.option("--signature_name", "-n", default="serving_default", type=str, help="model signature name")
@click.option("--metadata", is_flag=True)
def main(
format: str,
image_file: str,
target: str,
timeout_second: int,
model_spec_name: str,
signature_name: str,
metadata: bool,
):
if metadata:
result = request_metadata(model_spec_name, address=target, port=8501)
print(result)
else:
raw_image = read_image(image_file) # 바이트
if format.upper() == "GRPC":
prediction = request_grpc(
image=raw_image,
model_spec_name= model_spec_name,
signature_name=signature_name,
address=target,
port=8500,
timeout_second=timeout_second,
)
elif format.upper() == "REST":
prediction = request_rest(
image=raw_image,
model_spec_name=model_spec_name,
address=target,
port=8501,
)
else:
raise ValueError("Undefined format; shoul be GRPC or REST")
print(prediction)
if __name__ == '__main__':
main()
- 코드는 TensorFlow Serving API를 활용해 구현되었고 입력 파라미터에 따라 gRPC, REST API 따로 요청이 가능하도록 하였다.
- gRPC에는 Timeout을 설정하여 지연에 대한 처리 수행
이제 파이썬 커맨드를 날려서 응답이 오는지 확인해보자.
# gRPC 요청
python client/request_inception_v3.py -f GRPC -i horse.jpg
# sorrel
# REST API 요청
python client/request_inception_v3.py -f REST -i horse.jpg
# sorrel

지금까지 동기 추론 패턴의 구현 예시에 대해 알아보았다. 웹 싱글 패턴에서는 웹 API를 FastAPI로 자체 구현했지만, 동기 추론 패턴에서는 TensorFlow Serving이라는 TF의 표준 라이브러리를 사용해 웹 API를 구축했다. 모델 개발에서 사용하는 라이브러리에 다수의 선택지가 존재하듯, 추론기의 가동에도 모델의 종류에 따라 다양한 구현 방법이 존재한다.
scikit-learn 라이브러리에서 학습한 모델이라면 모델을 pickle로 출력해 추론기 내부에서 scikit-learn을 사용할 수도 있고, ONNX 형식으로 출력해 ONNX Runtime을 가동시킬 수도 있다. TensorFlow 또는 Keras의 경우에는 TF Serving, PyTorch를 사용했다면 ONNX Runtime이나 Torch Serve를 선택하는 것이 일반적이다.
이점
- 간단한 구성으로 개발과 운용이 용이함
- 추론이 완료될 때 까지 클라이언트는 다음 처리로 이행하지 않기 때문에 순차적인 workflow를 만들 수 있음
검토사항
동기 추론 패턴의 단점은 추론기가 응답할 때까지 클라이언트를 기다리게 한다는 점이다. 넷플릭스 앱처럼 사용자가 직접 애플리케이션을 조작하는 경우는 지연에 민감하기 때문에 불과 1~2초의 늦고 빠름이 사용자 경험을 좌우한다. 한편, 추론기는 시스템인 이상 예상치 못한 부하나 장애로 인해 성능이 악화되어 지연이 발생할 수 있다. 대기시간이 길어질 경우에는 클라이언트나 프락시에 타임아웃을 설정하고, 허용시간을 넘기면 더 이상 추론을 기다리지 않고 다음 프로세스로 넘어갈 수 있도록 검토해야 한다.
End
이번 포스팅에서는 동기 추론패턴에 대해 알아보았다. 이전까지 구현방식이 모두 동기 추론방식이기 때문에 동기추론 패턴은 웹 API로 FastAPI 대신 TF Serving을 사용했다. 이처럼 모델의 라이브러리에 따라 추론기의 구성 방법이 달라지기 때문에 머신러닝을 실제 시스템에 도입하기 위해서는 모델의 라이브러리 선정 단계에서부터 추론기를 구성하는 방법에 대해 검증해 둘 필요가 있다.
동기추론 패턴의 핵심은 요청에 대한 응답이 오기전까지 다른 요청을 처리할 수 없기 때문에 응답 latency를 줄여 나가는 것이 포인트라고 할 수 있다. 다음 포스팅에서 이와 반대인 비동기 추론 패턴에 대해 알아보자
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/synchronous_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/synchronous_pattern
Leave a comment