
[ML Design Pattern] 추론 시스템 / 3. 비동기 추론 패턴
비동기 추론 패턴
시스템에 따라 클라이언트는 추론 요청만을 보내놓고, 추론 결과는 클라이언트에서 사용하지 않는 경우도 존재한다. 추론 요청에 대해서 추론 결과를 바로 응답하지 않고 요청과는 다른 과정으로 가져오는 것을 비동기 추론 패턴이라고 한다. 머신러닝으로 실현 가능한 시스템의 폭을 넓힐 수 있는 비동기 추론 패턴에 대해 알아보자.
Use Case
- 클라이언트 애플리케이션에서 추론 요청 직후의 처리가 추론 결과에 의존하지 않는 workflow일 경우
- 클라이언트와 추론 결과의 output destination을 분리하고 싶은 경우
- 추론에 시간이 걸려 클라이언트를 기다리게 하고 싶지 않은 경우
해결하려는 과제
최근 DALL-E와 같이 텍스트를 통해 새로운 이미지를 창조하거나 이미지 편집, 변형 등 복잡한 데이터를 추론하는 멀티모달 머신러닝이 계속해서 발전하고 있다. 이러한 모델들은 연산량이 커서 추론에 다소 시간이 걸릴 수 있다는 문제가 있다. 동기적인 시스템에서 이와 같은 머신러닝 모델을 활용하려면 추론 결과를 기다리는 동안 후속 처리를 중지해야 하며, 속도가 느린 추론 처리는 결국 시스템 전체의 성능 저하로 이어지게 된다.
이와는 다른 느낌으로 동기적으로 처리할 필요가 없는 workflow도 있다. 예를 들어, 사진을 클라우드에 올리고 SR(Super Resolution) 딥러닝 기술로 화질을 개선해서 사용자에게 제공하는 앱의 workflow를 생각해보자. 이러한 앱에서는 파일 업로드하기 버튼을 누르고 난 다음의 처리를 비동기적으로 실시한다. 스마트폰 화면에 “사진을 업로드 했습니다.” 라는 푸시 메시지를 송신하고 화면은 사진첩을 유지한 채 계속해서 업로드 작업을 할 수 있도록 처리하면 클라이언트의 조작을 멈추지 않고 SR 모델이 추론 할 수 있는 시간을 확보할 수 있다. 추론이 완료된 이미지는 결과 보기 화면에 자동으로 추가되도록 하면 사용자 경험은 그리 나쁘지 않을 것이다.
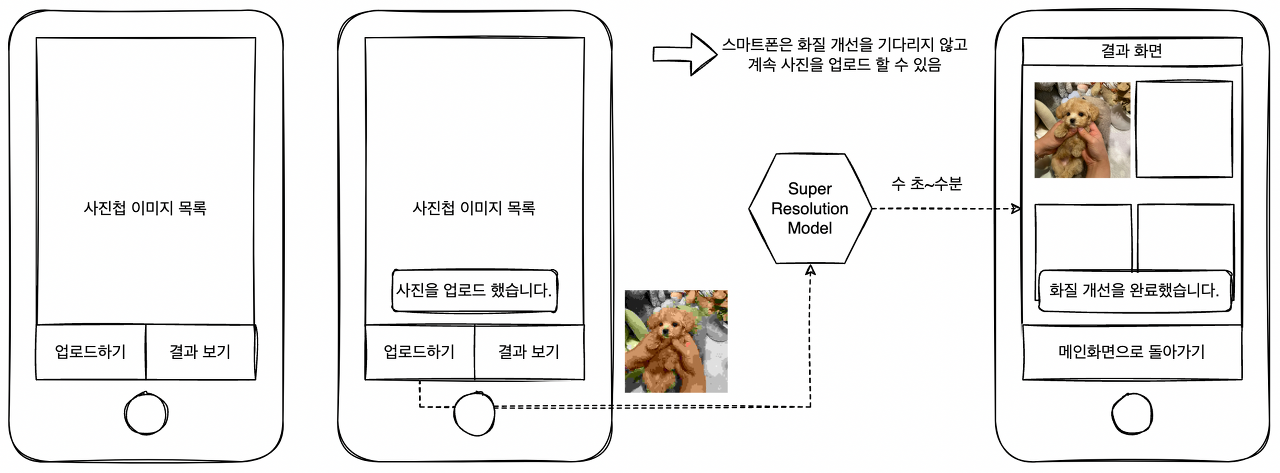
많은 시스템은 상황에 따라 클라이언트의 요청과 추론의 workflow를 비동기적으로 분리하고 있다. 특히 추론에 시간이 많이 소요되는 무거운 모델이 존재한다면 비동기적인 workflow를 활용해 시스템의 전체 성능을 유지할 것을 권장하는 추세다.
Architecture
요청과 추론을 분리해 클라이언트의 workflow에서 추론을 기다릴 필요가 없게 하려면 어떻게 해야할까? 비동기 추론 패턴에서는 요청과 추론기 사이에 큐(Apach Kafka)나 캐시(Redis Cache)를 배치해 추론 요청과 추론 결과의 취득을 비동기화 한다. 추론 결과를 얻기 위해서는 클라이언트에서 직접 추론결과가 출력되는 곳으로 정기적으로 접속해 결과를 얻어내야 한다.
비동기 추론 패턴은 추론 결과가 출력되는 곳에 따라 여러 아키텍쳐로 구현할 수 있다. 추론 결과는 큐나 캐시에 저장할 수도 있고(패턴 1), 전혀 다른 시스템에 출력할 수도 있다.(패턴 2)
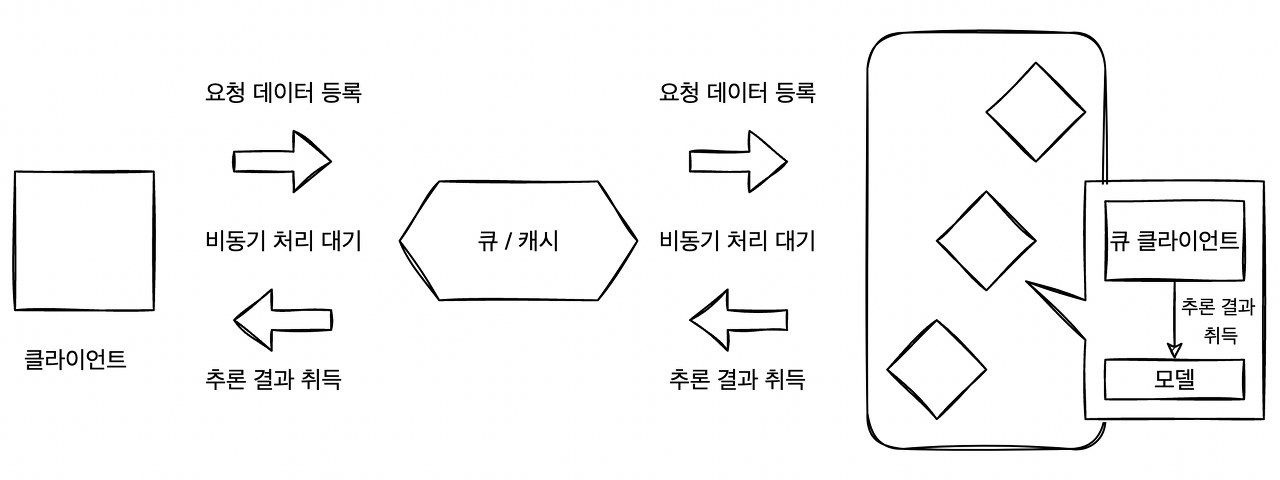 비동기 추론 패턴1
비동기 추론 패턴1
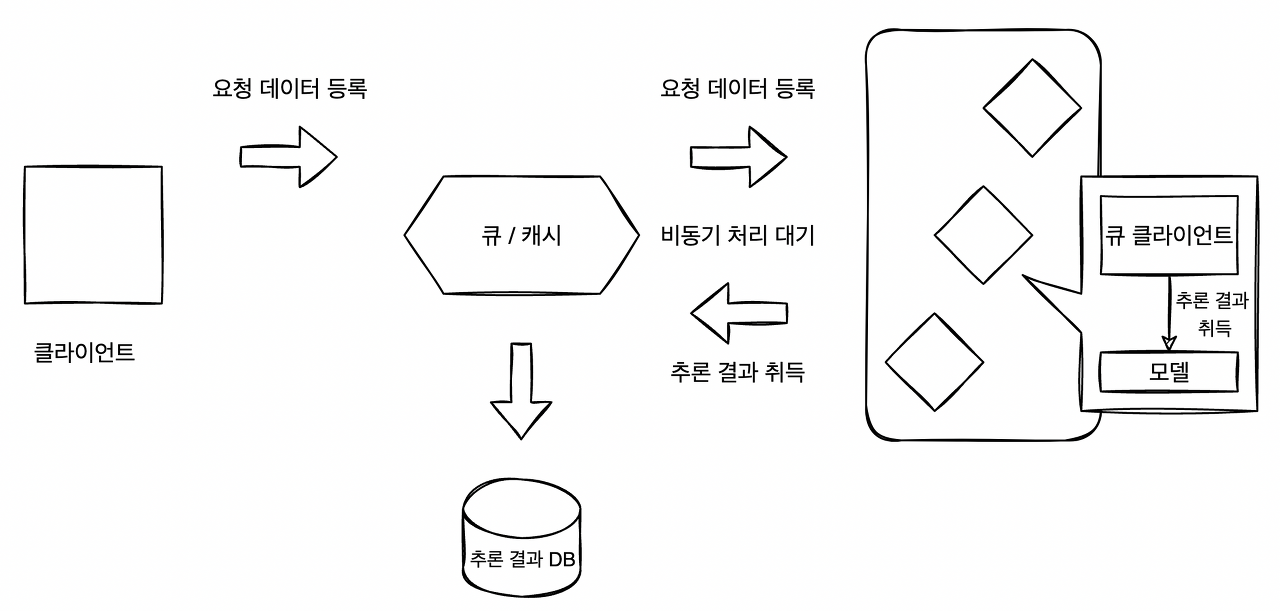 비동기 추론 패턴2
비동기 추론 패턴2
추론 결과를 출력하는 곳은 시스템의 workflow에 따라 구성한다. 추론 결과를 클라이언트에 직접 전달할 수도 있지만, 추론기 측이 클라이언트에 추론을 반환하기 위한 커넥션이 필요하게 되고 시스템이 복잡해지기 때문에 권장되지 않는다.
구현
비동기 추론 패턴에서도 동기 추론 패턴에서 사용한 TF Serving을 활용한다. 추론기에서는 전처리, 후처리를 포함한 InceptionV3 모델을 TF Serving으로 기동한다. 클라이언트로부터의 추론 요청 엔드포인트에서는 FastAPI로 Proxy가 중개한다. Proxy는 추론 요청에 대해 작업 ID를 응답하고, 백그라운드에서 Redis에 요청 데이터를 등록한다. Redis에 등록된 요청 데이터는 배치로 TF Serving이 추론하고, 추론 결과는 다시 Redis에 등록된다. 클라이언트가 작업 ID를 Proxy에 요청하면 추론이 완료되었을 때 그 결과를 얻게 되는 구성이다.
 비동기 추론 패턴 구현 아키텍쳐
비동기 추론 패턴 구현 아키텍쳐
위 그림은 클라이언트와 추론기 사이에 FastAPI, Redis, 배치 서버가 있는 아키텍쳐다. 클라이언트는 비동기화로 인해 추론이 완료될 때 까지 작업을 중지할 필요가 없다. 다만, 클라이언트에서 추론 결과를 얻기 위해서는 Proxy를 polling(주기적으로 새로운 정보가 있는지 계속 확인하는 행위)해야 한다.
그림처럼 비동기 추론 패턴은 여러 리소스를 조합해서 구현하기 때문에 각 리소스를 개별 컨테이너로 구축하고, Docker Compose로 가동시키는 구성을 고려할 수 있다.
src/app/routers/routers.py
import base64
import io
import uuid
from logging import getLogger
from typing import Any, Dict
import requests
from fastapi import APIRouter, BackgroundTasks
from PIL import Image
from src.app.backend import background_job, store_data_job
from src.app.backend.data import Data
from src.configurations import ModelConfigurations
logger = getLogger(__name__)
router = APIRouter()
# health check
@router.get("/health")
def health() -> Dict[str, str]:
return {"health", "ok"}
# 모델에 대한 metadata를 TF Serving에 get 요청
@router.get("/metadata")
def metadata() -> Dict[str, Any]:
model_spec_name = ModelConfigurations.model_spec_name
address = ModelConfigurations.address
port = ModelConfigurations.rest_port
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}/versions/0/metadata" # TFServing 엔드포인트 규칙
response = requests.get(serving_address)
return response.json()
# 라벨 인덱스와 값을 return
@router.get('/label')
def label() -> Dict[int, str]:
return ModelConfigurations.labels
@router.get('/predict/test')
def predict_test(background_tasks: BackgroundTasks) -> Dict[str, str]:
job_id = str(uuid.uuid4())[:6]
data = Data()
data.image_data = ModelConfigurations.sample_image
background_job.save_data_job(data.image_data, job_id, background_tasks, True)
return {'job_id': job_id}
# 이미지를 redis에 새로 등록 -> 추론은 background에서 이미 loop를 돌면서 추론중
@router.get('/predict')
def predict(data: Data, background_tasks: BackgroundTasks) -> Dict[str, str]:
image = base64.b64decode(str(data.image_data))
io_bytes = io.BytesIO(image)
data.image_data = Image.open(io_bytes)
job_id = str(uuid.uuid4())[:6]
background_job.save_data_job(
data=data.image_data,
job_id=job_id,
background_tasks=background_tasks,
enqueue=True
)
return {'job_id': job_id}
# 해당 job의 결과값 get
@router.get("/job/{job_id}")
def prediction_result(job_id: str) -> Dict[str, Dict[str, str]]:
result = {job_id: {'prediction': ""}}
data = store_data_job.get_data_redis(job_id)
result[job_id]["prediction"] = data
return result
- 먼저 프락시는 웹 싱글패턴과 마찬가지로 Guicorn과 FastAPI로 구성하였다. 엔드포인트중 중요한 부분은 /predict/test, /predict, /job/{job_id}이다. 내부데이터에 의한 테스트는 /predict/test를 사용하고, 클라이언트로부터의 요청은 /predict를 사용한다. 추론 결과를 요청하는 엔드포인트는 /job/{job_id} 이다.
- /predict 엔드포인트를 통해 클라이언트로 요청이 들어오면 이미지를 pillow 형식으로 변환하여 백그라운드에서 Redis에 데이터를, 큐에는 job_id를 등록한다. 백그라운드 처리는 FastAPI의 BackgroundTasks를 사용하여 요청에 응답 후 실행하게 예약할 수 있다.
- /job/{job_id} 엔드포인트로부터 redis에 등록된 해당 job_id의 추론 결과를 리턴받을 수 있다.
src/app/backend/store_data_job.py
import base64
import io
import logging
from typing import Any, Dict
from PIL import Image
from src.app.backend.redis_client import redis_client
logger = logging.getLogger(__name__)
# 큐에 등록할 키 작성
def make_image_key(key: str) -> str:
return f"{key}_image"
# 큐 등록
def left_push_queue(queue_name: str, key: str) -> bool:
try:
redis_client.lpush(queue_name, key)
return True
except Exception:
return False
# 큐 취득
def right_pop_queue(queue_name: str) -> Any:
if redis_client.llen(queue_name) > 0:
return redis_client.rpop(queue_name)
else:
return None
# Redis에 데이터 등록
def set_data_redis(key: str, value: str) -> bool:
redis_client.set(key, value)
return True
# Redis로부터 데이터 취득
def get_data_redis(key: str) -> Any:
data = redis_client.get(key)
return data
# Redis에 이미지 데이터 등록
def set_image_redis(key:str, image: Image.Image) -> str:
byte_io = io.BytesIO()
image.save(byte_io, format=image.format)
image_key = make_image_key(key)
encoded = base64.b64encode(byte_io.getvalue())
redis_client.set(image_key, encoded)
return image_key
# Redis로부터 이미지 데이터 취득
def get_image_redis(key:str) -> Image.Image:
redis_data = redis_client.get(key)
decoded = base64.b64decode(redis_data)
io_bytes = io.BytesIO(decoded)
image = Image.open(io_bytes)
return image
# Redis에 데이터와 작업 ID 등
def save_image_redis_job(job_id: str, image: Image.Image) -> bool:
set_image_redis(job_id, image)
redis_client.set(job_id, "")
return True
- 해당 스크립트는 redis client의 행동을 정의한 파일이다. job id를 큐에 등록하거나 pop 시키는 함수, 이미지 데이터를 이미지 job id와 함께 redis에 등록을 위한 set과 추론을 위한 get 함수가 포함되어 있다.
- Queue에는 job_id만 등록하게되며 Queue에 등록된 job_id를 통해 Redis에 저장된 데이터를 불러오는 로직
src/app/backend/prediction_batch.py
import asyncio
import base64
import io
import os
from concurrent.futures import ProcessPoolExecutor
from logging import DEBUG, Formatter, StreamHandler, getLogger
from time import sleep
import grpc
from src.app.backend import request_inception_v3, store_data_job
from src.configurations import CacheConfigurations, ModelConfigurations
from tensorflow_serving.apis import prediction_service_pb2_grpc
log_format = Formatter("%(asctime)s %(name)s [%(levelname)s] %(message)s")
logger = getLogger("prediction_batch")
stdout_handler = StreamHandler()
stdout_handler.setFormatter(log_format)
logger.addHandler(stdout_handler)
logger.setLevel(DEBUG)
# 큐가 존재하면 추론을 실행
def _trigger_prediction_if_queue(stub: prediction_service_pb2_grpc.PredictionServiceStub):
# queue 에는 job_id만 담고 실제 데이터(이미지)는 redis 에 담음
job_id = store_data_job.right_pop_queue(CacheConfigurations.queue_name) # None or job_id
logger.info(f"predict job_id: {job_id}")
if job_id is not None:
data = store_data_job.get_data_redis(job_id)
if data != "": # 공백이 아니라면 이미 예측값이 저장되어 있다는 의미
return True
# Job id는 있지만 data(추론결과)가 없는 경우는 추론을 수행 해야 함
image_key = store_data_job.make_image_key(job_id)
image_data = store_data_job.get_data_redis(image_key) # 이미지 id로 부터 이미지 취득
decoded = base64.b64decode(image_data)
io_bytes = io.BytesIO(decoded)
prediction = request_inception_v3.request_grpc(
stub=stub,
image=io_bytes.read(),
model_spec_name=ModelConfigurations.model_spec_name,
signature_name=ModelConfigurations.signature_name,
timeout_second=5
)
if prediction is not None: # 응답이 성공적으로 오면
logger.info(f"{job_id} {prediction}")
store_data_job.set_data_redis(job_id, prediction) # job id에 예측값 등록
else:
store_data_job.left_push_queue(CacheConfigurations.queue_name, job_id) # 응답이 지연된 경우나 오지 않은 경우 다시 큐에 등록
def _loop():
serving_address = f"{ModelConfigurations.address}:{ModelConfigurations.grpc_port}"
channel = grpc.insecure_channel(serving_address)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
while True:
sleep(1)
_trigger_prediction_if_queue(stub=stub)
# 멀티 프로세스로 기동
def prediction_loop(num_procs: int=2):
excutor = ProcessPoolExecutor(num_procs) # 병렬 연산을 위한 ProcessPoolExecutor
loop = asyncio.get_event_loop()
for _ in range(num_procs):
asyncio.ensure_future(loop.run_in_executor(excutor, _loop()))
loop.run_forever()
def main():
NUM_PROCS = int(os.getenv("NUM_PROCS", 2))
prediction_loop(NUM_PROCS)
if __name__ == '__main__':
logger.info('start backend')
main()
- 배치 처리를 위해 해당 스크립트를 실행하는 컨테이너를 실행한다. 무한루프를 돌면서 큐의 마지막 job_id를 pop 시킨 뒤에 job_id 데이터에 대한 예측결과가 담기지 않았다면 추론을 실행하여 추론 결과를 Redis에 저장하는 역할을 한다.
- 배치서버는 멀티 프로세스로 기동하기 위해 Python의 병렬처리를 위한 ProcessPoolExcutor를 사용한다.
추론기는 동기처리패턴 포스팅과 동일하기 때문에 생략한다. 비동기 추론 패턴에서 사용할 이미지가 4개(프락시, 배치처리(backend), 추론기, Redis)이고 실행 순서가 중요하기 때문에 docker-compose.yaml 파일을 작성하여 관리한다.
docker-compose.yaml
version: "3"
services:
asynchronous_proxy:
container_name: asynchronous_proxy
image: visionhong/ml-system-in-actions:asynchronous_pattern_asynchronous_proxy_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- QUEUE_NAME=tfs_queue
- API_ADDRESS=imagenet_inception_v3
ports:
- "8400:8000"
command: ./run.sh
depends_on:
- redis
- imagenet_inception_v3
- asynchronous_backend
imagenet_inception_v3:
container_name: imagenet_inception_v3
image: visionhong/ml-system-in-actions:asynchronous_pattern_imagenet_inception_v3_0.0.1
restart: always
environment:
- PORT=8500
- REST_API_PORT=8501
ports:
- "8500:8500"
- "8501:8501"
entrypoint: ["/usr/bin/tf_serving_entrypoint.sh"]
asynchronous_backend:
container_name: asynchronous_backend
image: visionhong/ml-system-in-actions:asynchronous_pattern_asynchronous_backend_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- QUEUE_NAME=tfs_queue
- API_ADDRESS=imagenet_inception_v3
entrypoint: ["python", "-m", "src.app.backend.prediction_batch"]
depends_on:
- redis
redis:
container_name: asynchronous_redis
image: "redis:latest"
ports:
- "6379:6379"
- Redis와 추론기 컨테이너가 먼저 실행이 되고 배치서버(backend)와 프락시가 차례대로 실행된다.
작성한 도커파일들을 빌드했다고 가정하고 docker-compose up 시켜서 4개의 컨테이너를 실행해보자
docker-compose \
-f ./docker-compose.yaml \
up -d # 백그라운드
# [+] Running 5/5
# ⠿ Network asynchronous_pattern_default Created 0.1s
# ⠿ Container asynchronous_redis Started 1.4s
# ⠿ Container imagenet_inception_v3 Started 2.4s
# ⠿ Container asynchronous_backend Started 1.6s
# ⠿ Container asynchronous_proxy Started
- 각 컨테이너가 백그라운드에서 실행이 되는것을 확인할 수 있다.
프락시의 health체크를 하고 내장된 test 데이터로 요청을 보내보자. 프락시는 8400번 포트로 열어두었다.
curl localhost:8400/health
# ["health","ok"]
curl localhost:8400/predict/test
# {"job_id":"c560e9"}
curl localhost:8400/job/c560e9
# {"c560e9":{"prediction":"golden retriever"}}
- /predict/test 엔드포인트로 요청을 하게되면 job id와 내장된 이미지 데이터를 큐와 Redis에 등록하게 된다.
- 배치서버에서는 1초에 한번씩 Redis를 폴링해서 추론 대기중인 작업을 꺼내 TF Serving 컨테이너에 요청을 하게된다.
- 추론이 완료되면 해당 job id의 prediction 값이 등록된다.
- 클라이언트가 추론결과를 얻을 땐 job/{job id} 엔드포인트에 요청을 할 수 있으며 추론이 아직 되지 않았다면 빈 문자열이, 추론이 완료되었다면 추론 결과 예측 라벨이 출력된다.
 {“c560e9”:{“prediction”:”golden retriever”}}
{“c560e9”:{“prediction”:”golden retriever”}}
실제로 백그라운드에서 루프를 돌고있는 배치서버의 로그를 확인해보면 다음과 같다.
docker logs asynchronous_backend
# 2022-11-03 06:49:13,522 prediction_batch [INFO] predict job_id: None
# 2022-11-03 06:49:14,523 prediction_batch [INFO] predict job_id: None
# 2022-11-03 06:49:15,525 prediction_batch [INFO] predict job_id: 8d42fb
# 2022-11-03 06:49:15,628 prediction_batch [INFO] 8d42fb golden retriever
# 2022-11-03 06:49:16,630 prediction_batch [INFO] predict job_id: da07b5
# 2022-11-03 06:49:16,702 prediction_batch [INFO] da07b5 golden retriever
# 2022-11-03 06:49:17,704 prediction_batch [INFO] predict job_id: 6637a0
# 2022-11-03 06:49:17,770 prediction_batch [INFO] 6637a0 golden retriever
# 2022-11-03 06:49:18,773 prediction_batch [INFO] predict job_id: 3b0c5f
# 2022-11-03 06:49:18,844 prediction_batch [INFO] 3b0c5f golden retriever
# 2022-11-03 06:49:19,847 prediction_batch [INFO] predict job_id: 571f91
# 2022-11-03 06:49:19,915 prediction_batch [INFO] 571f91 golden retriever
# 2022-11-03 06:49:20,917 prediction_batch [INFO] predict job_id: None
# 2022-11-03 06:49:21,918 prediction_batch [INFO] predict job_id: None
# 2022-11-03 06:49:22,920 prediction_batch [INFO] predict job_id: None
- 정상적으로 1초마다 Redis를 폴링하는것을 확인할 수 있으며 클라이언트에서 프락시로 predict 요청을 하면 job_id가 인식이 되며 이때 TF 서버에 요청을 보내게 된다.
- 위와같은 경우는 같은 이미지를 5번 연속으로 요청한 경우인데 추론시간이 1장의 이미지를 처리하는데 1초가 넘지 않기 때문에 많은 추론요청을 보내도 응답이 일정하게 오지만 1개의 배치만 처리가능한 구조이기 때문에 요청이 몰리면 확인하는데 선형적으로 시간이 걸리게 된다.
이점
- 클라이언트의 workflow와 추론의 결합도를 낮출 수 있음
- 추론의 지연이 긴 경우에서도 클라이언트에 대한 악영향을 피할 수 있음
검토사항
비동기 추론 패턴에서는 추론을 실행하는 타이밍에 따라 아키텍처를 검토해야 한다.
이번에 다룬 아키텍처와 같이 요청을 FIFO로 추론하는 경우, 클라이언트와 추론기의 중간에 큐를 이용한다. 클라이언트는 요청 데이터를 큐에 enqueue 하고, 추론기는 큐에서 데이터를 dequeue하는 식이다. 서버 장애 등으로 추론에 실패해서 이를 재시도하기 위해서는 dequeue한 데이터를 큐로 되돌릴 필요가 있지만, 장애의 원인에 따라서는 되돌릴 수 없는 사태가 발생하기도 한다. 따라서 큐 방식으로 모든 데이터를 추론할 수 있다고는 할 수 없다.
추론의 순서에 구애되지 않는 경우는 캐시를 이용한다. 클라이언트와 추론기의 중간에 캐시 서버를 준비하고 클라이언트로부터 요청 데이터를 캐시 서버에 등록한다. 추론기는 추론 이전의 캐시 데이터를 가져와 추론하고, 추론 결과를 캐시에 등록한다. 그리고 추론 전 데이터를 추론이 끝난 상태로 변경하는 workflow를 취한다. 이런 방식이라면 서버 장애로 인해 추론에 실패하더라도 재시도 할 수 있다.
에러가 발생해서 추론을 재시도하는 방식의 경우, 재시도에 필요한 TTL(Time to live)이나 시도 횟수로 제한하는 것이 좋다. 데이터의 미비로 추론이 성공하지 못하는 경우, 데이터의 추론을 요청으로부터 5분이내 또는 재시도 3회 이내로 설정하고 이를 초과한 경우는 요청을 파기하는 대처 등이 필요하다.
또한, 비동기 추론 패턴에서는 순서가 엄밀하게 보장되지 않기 때문에 데이터나 이벤트에 대한 추론 순서를 반드시 지켜야 하는 시계열 추론 시스템에서는 비동기 추론 패턴이 아닌 동기 추론 패턴을 선택하는 것이 권장된다.
End
두 포스팅에 걸쳐서 동기 추론패턴과 비동기 추론패턴에 대해 알아보았다. 특히나 이번 두가지 패턴 중 어떤것을 선택할지는 비즈니스의 특성에 매우 밀접되어 있다. 추론 순서가 중요하고 클라이언트에게 빠른 응답이 필요하다면 동기 추론패턴, 모델이 무거워서 사용자 경험이 나빠질 우려가 있거나, 추론 결과를 클라이언트에게 즉시 응답할 필요가 없거나 추론 결과를 다른 시스템으로의 출력으로 고려한다면 비동기 추론패턴이 적합 할 것이다.
다음 포스팅에서는 대량의 데이터를 하나로 정리하여 추론하고 싶은 경우 사용할 수 있는 배치 추론 패턴에 대해 알아볼 것이다.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/asynchronous_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/asynchronous_pattern
Leave a comment