
[ML Design Pattern] 추론 시스템 / 4. 배치 추론 패턴
배치추론 패턴
대량의 데이터를 하나로 정리하여 추론하고 싶은 경우, 배치 추론 패턴을 사용할 수 있다. 배치 추론 패턴에서는 작업(job)으로서 전처리와 추론을 실행하고 추론 결과를 저장한다.
Use Case
- 실시간 또는 실시간에 준하는 추론을 할 필요가 없는 경우
- 과거의 데이터를 정리해 추론하고 싶은 경우
- 야간, 시간 단위 또는 월 단위 등 정기적으로 쌓인 데이터를 추론하고 싶은 경우
해결하려는 과제
머신러닝의 역할은 실시간으로 흐르는 데이터를 추론하는 것에 그치지 않는다. 지금까지 축적된 데이터에 대해 의미를 부여하기 위해 배치 처리로 데이터는 추론하는 경우가 있다.
예를 들어 클라이언트용 웹 서비스에 새로운 위반행위를 발견했을 경우, 해당 위반행위를 실시간으로 검지하는 머신러닝 모델을 준비하고 과거에 축적된 데이터를 정리해 추론하는 방법이 있다. 또는 지난 3개월 동안의 데이터를 바탕으로 다음 달의 인력 배치를 계획하는 모델이라면 월말에 한 번 추론을 하게 될 것이다. 실시간으로 추론할 필요가 없을 때나 정리된 데이터에 대해 추론하는 경우, 배치 처리로 추론 실행을 스케줄링 할 수 있다.
Architecture
배치 추론 패턴에서는 밀린 데이터를 야간 등 정기적으로 추론하고 결과를 저장한다. 반드시 야간에 실행할 필요는 없으며, 상황에 따라 한 시간에 한 번, 1개월에 한 번 실행하는 것도 가능하다. 단, 배치 추론 패턴에서는 배치 작업을 관리하는 서버가 필요한데, 이 서버는 정해진 규칙이 출족되면 추론 작업을 실행시킨다. 추론기는 배치 작업을 수행할 때만 가동하고, 클라우드 및 쿠버네티스로 서버의 시작/정지를 제어하면 인스턴스 비용도 아낄 수 있다.
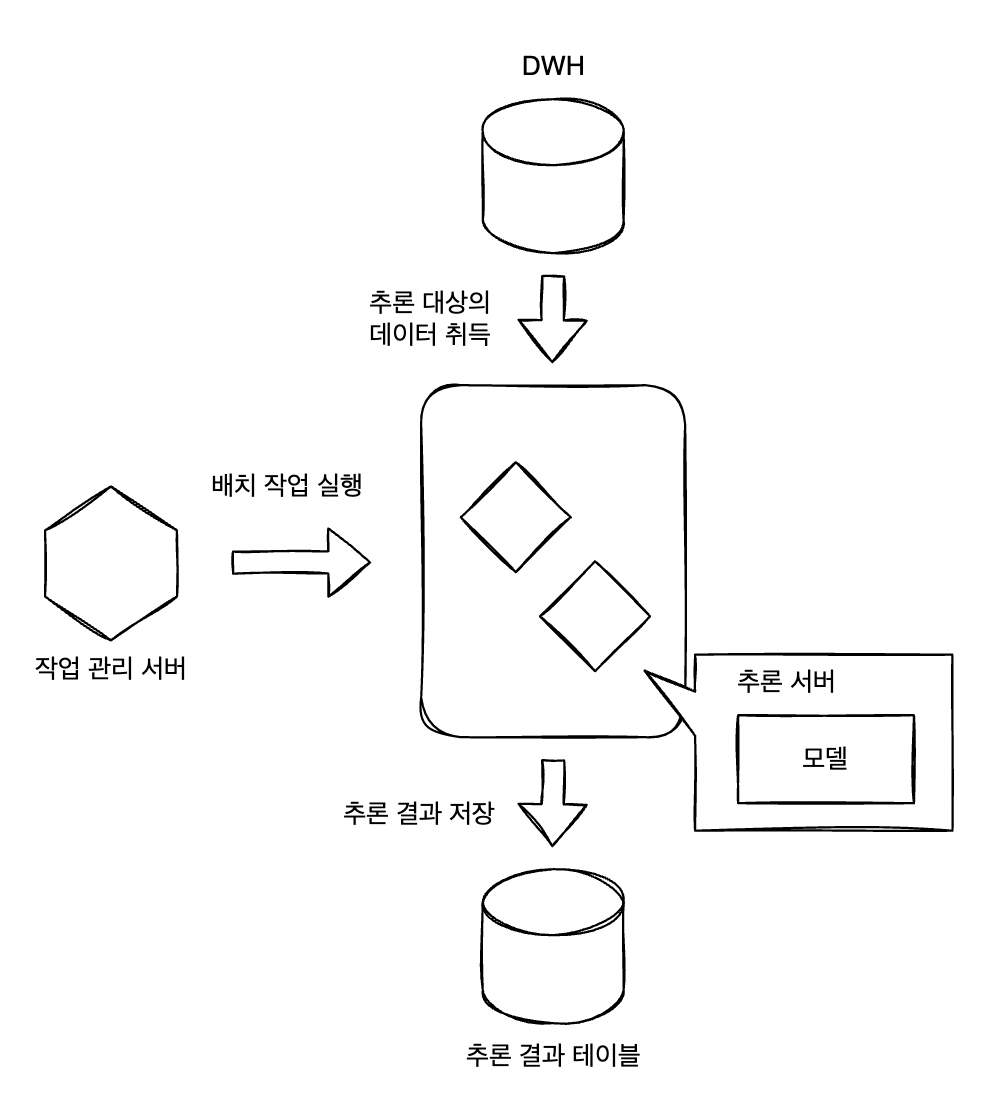
구현
배치 추론 패턴에서는 배치 작업을 정기적으로 실행하는 배치 서버가 데이터베이스에서 정기적으로 배치 대상 데이터를 취득하여 추론하고 추론 결과를 데이터베이스에 등록하는 구성을 취한다. 구현을 위해 리소스로 배치 서버와 DB 서버를 준비해야 한다. DB는 MySQL을 사용하고 배치 서버부터는 SQL Alchemy 라고 하는 파이썬의 ORM(Object Relational Mapping) 라이브러리로 액세스한다. 모델은 붓꽃 데이터셋의 SVM 모델을 다시 사용한다. (참고)
먼저 SQL Alchemy와 Pydantic을 조합해 테이블의 스키마 정의와 CRUD를 작성한다. 테이블을 표로 정리하면 아래와 같다.
| Column | Type | Info |
|---|---|---|
| ID | Integer | 기본 키 |
| VALUES | JSON | 추론 대상 데이터 |
| PREDICTION | JSON | 추론 결과 |
| CREATED_DATETIME | TIMESTAMP | 데이터 등록 타임스탬프 |
| UPDATED_DATETIME | TIMESTAMP | 데이터 갱신 타임스탬프 |
src/db/models.py
from logging import getLogger
from sqlalchemy import Column, Integer
from sqlalchemy.dialects.mysql import TIMESTAMP
from sqlalchemy.sql.expression import text
from sqlalchemy.sql.functions import current_timestamp
from sqlalchemy.types import JSON
logger = getLogger(__name__)
from src.db.database import Base
class Item(Base):
__tablename__ = "items"
id = Column(
Integer,
primary_key=True,
autoincrement=True,
)
values = Column(
JSON,
nullable=False,
)
prediction = Column(
JSON,
nullable=True,
)
created_datetime = Column(
TIMESTAMP,
server_default=current_timestamp(),
nullable=False,
)
updated_datetime = Column(
TIMESTAMP,
server_default=text("CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP"),
nullable=False,
)
def create_tables(engine, checkfirst: bool = True):
logger.info("Initialize table")
Base.metadata.create_all(engine, checkfirst=checkfirst)
src/db/cruds.py
import datetime
from typing import Dict, List
from sqlalchemy.orm import Session
from src.db import models, schemas
# 전체 데이터 취득
def select_all_items(db: Session) -> List[schemas.Item]:
return db.query(models.Item).all()
# predictions을 대기중인 데이터 취득
def select_without_prediction(db: Session) -> List[schemas.Item]:
return db.query(models.Item).filter(models.Item.prediction == None).all()
# prediction이 끝난 데이터 취득
def select_with_prediction(db: Session) -> List[schemas.Item]:
return db.query(models.Item).filter(models.Item.prediction != None).all()
# ID로 검색
def select_by_id(db: Session, id: int) -> schemas.Item:
return db.query(models.Item).filter(models.Item.id == id).first()
# 데이터 등록
def register_item(db: Session, item: schemas.ItemBase, commit: bool = True):
_item = models.Item(values=item.values)
db.add(_item)
if commit:
db.commit()
db.refresh(_item)
# 하나 이상의 데이터를 등록
def register_items(db: Session, items: List[schemas.ItemBase], commit: bool = True):
for item in items:
register_item(db=db, item=item, commit=commit)
# 추론 결과를 등록
def register_predictions(db: Session, predictions: Dict[int, Dict[str, float]], commit: bool = True):
for id, prediction in predictions.items():
item = select_by_id(db=db, id=id)
item.prediction = prediction
if commit:
db.commit()
db.refresh(item)
- CRUD에서는 데이터의 취득, 등록 및 업데이트 함수를 정의한다.
- 추론이 진행되지 않은 데이터를 파악하고 추론을 진행하기 위해 select_without_prediction과 select_with_prediction 함수로 구분하여 데이터를 탐색할 수 있도록 한다.
- 배치 서버에서는 위 함수들을 정기적으로 호출하여 추론 결과를 테이블의 PREDICTION 컬럼에 등록한다.
src/db/initialize.py
from logging import getLogger
from src.configurations import PlatformConfigurations
from src.db import cruds, models, schemas
from src.db.database import get_context_db
logger = getLogger(__name__)
def initialize_database(engine, checkfirst: bool = True):
models.create_tables(engine=engine, checkfirst=checkfirst)
with get_context_db() as db:
sample_data = PlatformConfigurations.sample_data
items = [schemas.ItemBase(values=values) for values in sample_data]
cruds.register_items(db=db, items=items, commit=True)
- DB를 초기화하고 추론용 데이터를 DB에 저장해둔다.
src/task/job.py
import time
from concurrent.futures import ThreadPoolExecutor
from logging import DEBUG, Formatter, StreamHandler, getLogger
from typing import Tuple
import numpy as np
from src.db import cruds, schemas
from src.db.database import get_context_db
from src.ml.prediction import classifier
logger = getLogger(__name__)
logger.setLevel(DEBUG)
strhd = StreamHandler()
strhd.setFormatter(Formatter("%(asctime)s %(levelname)8s %(message)s"))
logger.addHandler(strhd)
# 추론
def predict(item: schemas.Item) -> Tuple[int, np.ndarray]:
prediction = classifier.predict(data=[item.values])
logger.debug(f"prediction log: {item.id} {item.values} {prediction}")
return item.id, prediction
def main():
logger.info("waiting for batch to start")
time.sleep(60)
logger.info("starting batch")
with get_context_db() as db:
data = cruds.select_without_prediction(db=db)
logger.info(f"predict data size: {len(data)}")
predictions = {}
with ThreadPoolExecutor(4) as executor:
results = executor.map(predict, data) # 추론을 실행해서 결과 취득
for result in results:
predictions[result[0]] = list(result[1]) # {item.id: prediction}
# 결과를 DB에 등록
cruds.register_predictions(
db=db,
predictions=predictions,
commit=True,
)
logger.info("finished batch")
if __name__ == '__main__':
main()
- Job은 CRUD의 select_without_prediction 함수를 통해 추론 결과가 등록되지 않은 데이터를 일괄적으로 취득해서 추론하고 테이블에 등록하는 작업을 수행한다. 이 작업을 정기적으로 수행하여 테이블에 쌓인 데이터에 추론 결과를 등록하는 구성이다.
배치 시스템에서는 작업을 정기적으로 실행해 작업의 성패를 관리하는 작업 관리 서버를 사용하는 경우가 많다. 이번 배치 추론 패턴에서는 쿠버네티스에 DB와 웹(FastAPI)서버를 배포하고 배치단위 추론기를 쿠버네티스의 CronJob 기능으로 활용한다.
manifests/cron_jobs.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job
namespace: batch
spec:
schedule: "19 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: batch-job
image: visionhong/ml-system-in-actions:batch_pattern_batch_0.0.1
env:
- name: MYSQL_DATABASE
value: sample_db
- name: MYSQL_USER
value: user
- name: MYSQL_PASSWORD
value: password
- name: MYSQL_PORT
value: "3306"
- name: MYSQL_SERVER
value: mysql.batch.svc.cluster.local
command:
- python
- -m
- src.task.job
resources:
requests:
cpu: 1000m
memory: "1000Mi"
restartPolicy: OnFailure
- 위 yaml 파일을 쿠버네티스에 배포하게 되면 매시간 19분(ex 1시 19분, 2시 19분)에 CronJob이 실행되면서 추론이 이루어지게 된다. (CronJob의 schedule 및 자세한 내용은 공식문서 참고)
- 배치추론 서버에서 DB 작업을 할 수 있어야 하기 때문에 환경변수로 DB에 접속관련 정보를 포함시킨다.
manifests/namespace.yaml, mysql.yaml, deployment.yaml
# namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: batch
---
# mysql.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql
namespace: batch
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
imagePullPolicy: Always
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: password
- name: MYSQL_DATABASE
value: sample_db
- name: MYSQL_USER
value: user
- name: MYSQL_PASSWORD
value: password
resources:
requests:
cpu: 1000m
memory: "1000Mi"
---
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: batch
labels:
app: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
---
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: api
namespace: batch
labels:
app: api
spec:
replicas: 3
selector:
matchLabels:
app: api
template:
metadata:
labels:
app: api
spec:
containers:
- name: api
image: visionhong/ml-system-in-actions:batch_pattern_api_0.0.1
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
cpu: 500m
memory: "300Mi"
requests:
cpu: 500m
memory: "300Mi"
command:
- ./run.sh
env:
- name: MYSQL_DATABASE
value: sample_db
- name: MYSQL_USER
value: user
- name: MYSQL_PASSWORD
value: password
- name: MYSQL_PORT
value: "3306"
- name: MYSQL_SERVER
value: mysql.batch.svc.cluster.local
---
apiVersion: v1
kind: Service
metadata:
name: api
namespace: batch
labels:
app: api
spec:
ports:
- name: rest
port: 8000
protocol: TCP
selector:
app: api
- namespace와 DB(mysql), 웹 API(FastAPI)를 배포하기 위한 manifest도 준비한다.
이미지를 모두 빌드했다고 가정하고 쿠버네티스 환경에 배포한 뒤 진행상태를 확인해보자. 쿠버네티스는 On-premise kubeadm v1.21 환경이다.
1. 네임스페이스 생성
kubectl apply -f manifests/namespace.yaml
2. DB 파드 및 서비스 생성
kubectl apply -f manifests/mysql.yaml -n batch
3. 웹 API 디플로이먼트 및 서비스 생성
kubectl apply -f manifests/deployment.yaml -n batch
4. 웹 API 포트포워딩 및 request
kubectl -n batch port-forward svc/api 8000:8000 # 포트포워딩
curl localhost:8000/health
# {"health":"ok"}
curl localhost:8000/data/predicted
# []
- DB초기화를 하면서 추론용으로 넣어둔 데이터는 아직 job을 수행하지 않았기 때문에 추론이 완료된 데이터는 없는 것으로 확인된다.
5. CronJob 배포(*시 19분까지 대기)
kubectl apply -f manifests/cron_jobs.yaml -n batch
kubectl get cronjob batch-job -n batch
# NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
# batch-job 19 * * * * False 0 <none> 14s
6. 19분에 CronJob을 통해 생성된 pod 및 로그 확인
kubectl get pod -n batch | grep batch-job
# batch-job-27800119-6ppmp 1/1 Running 0 1m20s
kubectl logs batch-job-27800119-6ppmp -n batch
# 2022-11-09 15:19:06,116 INFO waiting for batch to start
# 2022-11-09 15:20:06,147 INFO starting batch
# 2022-11-09 15:20:07,742 INFO predict data size: 65322
# 2022-11-09 15:20:07,745 DEBUG prediction log: 1 [4.3, 2.4, 3, 2.1] [0.13043216 0.5781998 0.29136813]
# 2022-11-09 15:20:07,746 DEBUG prediction log: 2 [4.3, 2.4, 3, 2.1] [0.13043216 0.5781998 0.29136813]
# 2022-11-09 15:20:07,748 DEBUG prediction log: 3 [4, 3.9, 3, 6] [0.36126029 0.25740659 0.3813332 ]
# 2022-11-09 15:20:07,749 DEBUG prediction log: 4 [6, 3.9, 5.3, 5.7] [0.35905859 0.25630024 0.3846412 ]
7. 웹 API request를 통해 추론 결과 확인
curl localhost:8000/data/predicted
# [{"created_datetime":"2022-11-09T14:41:07",
# "values":[4.3,2.4,3,2.1],
# "updated_datetime":"2022-11-09T15:21:19",
# "id":1,
# "prediction":[0.1304321587085724,0.5781998038291931,0.29136812686920166]}
# ...
이점
- 서버 리소스 관리를 유연하게 실시하여 비용 절감이 가능하다.
- 시간적인 여유를 두고 스케줄링 할 수 있다면 서버 장애 등으로 추론에 실패하더라도 재시도가 가능하다.
검토사항
한 번의 배치 작업에서 추론의 대상으로 삼는 데이터의 범위를 정의해야 한다. 데이터의 많고 적음에 따라 추론의 소요 시간은 달라지기 때문에 추론 결과가 필요한 시점까지 추론이 완료될 수 있도록 데이터의 양이나 실행 빈도 조정을 해야한다.
또한 배치 처리가 실패한 경우에 대한 방침도 정해 두는 것이 좋다. 여기서 방침은 크게 세가지로 나눌 수 있다.
- 전체 재시도: 실패 시 대상이 되는 모든 데이터에 대해 재시도한다. 데이터 간의 상관관계가 추론에 영향을 미치는 경우에 적용한다. (일부의 실패한 추론에 의해 다른 성공한 추론이 불량한 결과로 이어질 수 있는 경우)
- 일부 재시도: 실패한 데이터만 다시 추론한다.
- 방치: 실패해도 재시도하지 않고, 다음 배치 작업에서 정리해 추론하거나 일절 추론하지 않을 수 있다. 시간 경과에 따라 추론이 필요하지 않게되는 상황에서는 실패한 추론은 방치하는 경우가 있다.
배치 추론 패턴에서는 추론 일정이 매월이나 매년 계획되어 정기 실행의 빈도가 낮은 경우도 있다. 이러한 사례에서는 소량의 샘플데이터라도 정기적으로 배치 추론을 실행하는것이 권장된다. 특히 데이터의 경향이 정기적으로 바뀌는 케이스에서는 ML 모델이 유효성을 상실하기 때문에 불량한 추론 결과를 초래할 수 있다. 또한 클라우드와 같이 정기적으로 업데이트가 발생하는 시스템이라면 정작 배치 추론을 실행하려고 해도 시스템을 기동할 수 없는 사태가 일어나기도 한다. 다소 비용이 들더라도 정기적으로 소량의 데이터로 배치 추론을 실행한다면 트러블슈팅하는 큰 비용을 절감할 수 있어 안정적인 시스템 운영이 가능 할 것이다.
End
이번 포스팅에서는 상시추론이 아닌 정기적으로 추론을 실행할 필요가 있는 경우에 활용할 수 있는 배치 추론 패턴에 대해 알아보았다. 다음 포스팅에서는 전처리와 추론을 서로 다른 서버에서 실행하여 각 서버의 유지보수를 용이하게 하는 전처리-추론 패턴에 대해 정리 할 것이다.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/batch_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/batch_pattern
Leave a comment