
[ML Design Pattern] 추론 시스템 / 5. 전처리 · 추론 패턴
전처리-추론 패턴
ML모델 개발에서 데이터의 전처리와 학습은 동시에 이루어지지만, 서로 다른 라이브러리를 사용하는 경우가 많다. 결과적으로 모델은 모델 추론용 파일로 저장되지만, 전처리는 여전히 코드의 형태로 남게 된다. 이번 포스팅에는 추론기에서 전처리와 추론을 서로 다른 서버에서 실행하여 각 서버의 유지보수를 용이하게 할 수 있는 전처리-추론 패턴에 대해 알아보자.
Use Case
- 머신러닝의 전처리와 추론에서 필요로 하는 라이브러리나 코드베이스, 미들웨어, 리소스가 크게 다를 경우.
- 전처리와 추론을 컨테이너 레벨로 분리해서 장애의 격리 및 가용성, 유지보수성이 향상될 경우
해결하려는 과제
머신러닝의 전처리와 추론은 서로 다른 라이브러리로 구현될 수 있다. 특히 딥러닝이라면 전처리에 scikit-learn이나 OpenCV, Numpy를 사용하고 모델은 PyTorch나 TensorFlow로 구현하는 것이 일반적이다.
전처리와 모델은 파이썬에서 동일한 라이브러리를 사용해 개발하지만, 학습 이후 결과물은 전처리와 모델이 반드시 동일한 파일로 집약된다고 단정할 수 없다. scikit-learn 라이브러리만을 사용해서 모델을 개발한다면 scikit-learn pipeline으로 pickle을 통해 dump, 저장할 수 있지만, 딥러닝과 같이 전처리가 포함되지 않은 라이브러리를 사용한다면 전처리 코드와 모델파일이 따로 취급되는 경우가 있다.
딥러닝 모델로 추론하기 위해 데이터는 학습때와 동일한 방법으로 전처리해야 한다. 따라서 전처리 코드와 모델 파일을 한 세트로 만들어 추론기로 릴리스한다. 한편, TensorFlow Serving이나 ONNX Runtime Server와 같이 딥러닝 라이브러리를 단독 추론기로 가동시키는 방법이 제공되기도 한다. 이때는 전처리를 수행하는 서버와 추론기 서버를 별도로 배치하고, 네트워크를 통해 결합된 추론기로 가동시키는 것이 좋다.
Architecture
먼저 클라이언트에서 전처리 서버로 요청을 보내면 전처리 서버에서 데이터를 변환한다. 이후 추론기에 요청을 보내 추론 결과를 취득하고 클라이언트로 응답하는 흐름이 전처리-추론 패턴이다.
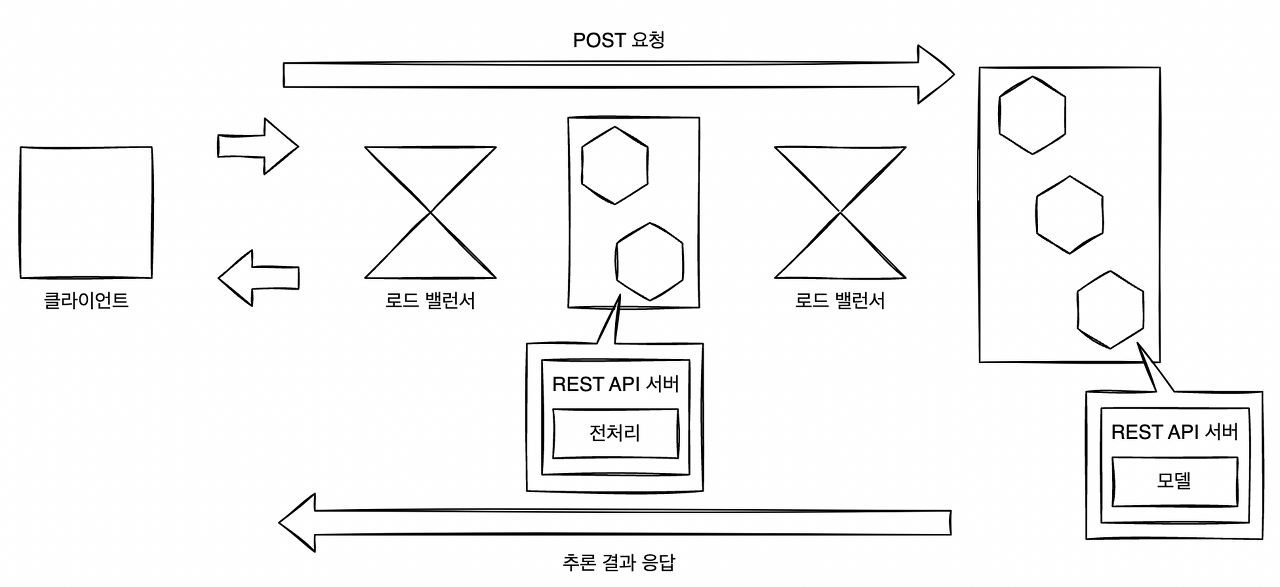 간단한 전처리·추론 패턴
간단한 전처리·추론 패턴
전처리와 추론기를 개별 REST API 서버나 gRPC 서버로 배치하고 전처리 측에 추론기로의 클라이언트 기능을 구현한다. 전처리 서버 및 추론기는 서로 다른 서버이기 때문에 서버를 여럿 배치할 경우에는 전처리와 추론기 사이에 부하 분산기인 LoadBalancer가 필요하다.
전처리 서버와 추론기를 분할하기 위해서는 각각의 리소스 튜닝이나 상호 네트워크 설계, 버저닝이 필요하다. 웹 싱글 패턴보다 구성은 복잡하지만, 효율적인 리소스의 활용이나 별도의 개발, 장애 격리 등의 이점을 얻을 수 있다.
아래 그림과 같이 앞단에 프락시 서버를 배치하여 전처리와 추론을 마이크로서비스화하는 방식도 가능하다. 프락시를 중개시켜 데이터의 취득, 전처리, 추론을 분할한 구성이다. 이 구성에서는 데이터 취득 서버, 전처리 서버, 추론 서버를 독립적인 라이브러리나 코드베이스, 리소스로 개발할 수 있지만, 컴포넌트가 늘어나기 때문에 코드베이스나 버전 관리, 장애 대응이 어려워지는 단점이 있다.
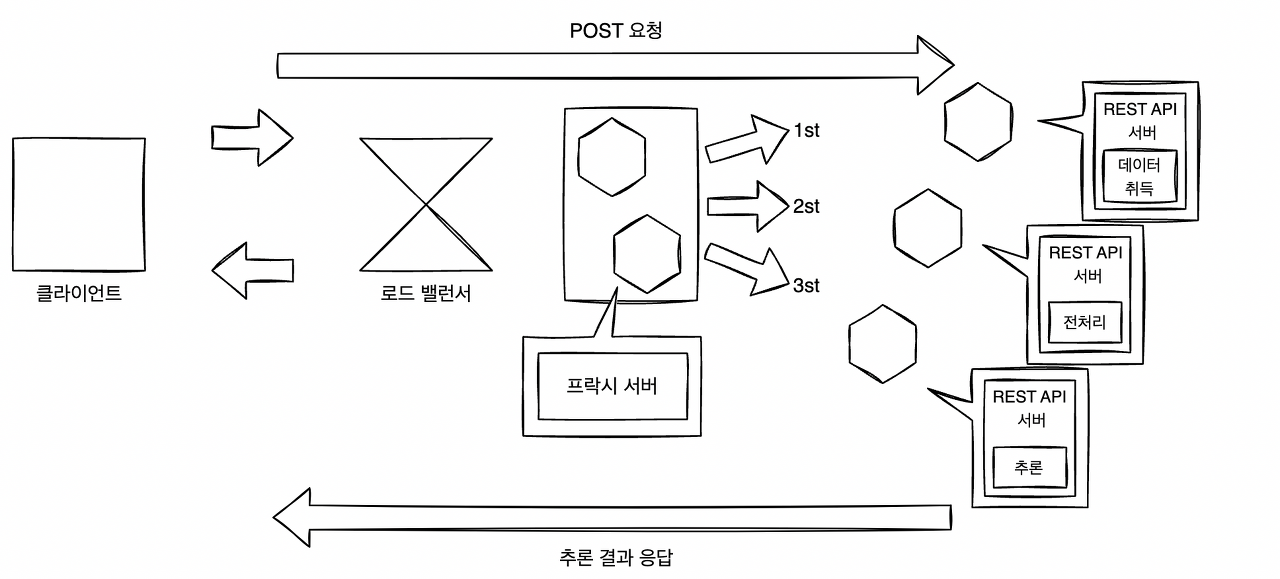 앞단에 프락시를 두는 구성
앞단에 프락시를 두는 구성
구현
이번 패턴에서는 전처리 서버와 추론 서버를 따로 구축한다. 2개의 리소스로 구성하기 때문에 Docker Compose를 통해 부팅한다. 비동기 추론 패턴 예시와 같이 전처리와 추론을 TensorFlow Serving으로 동일한 추론기에 포함시킬 수 있다면 이상적이지만 전처리나 라이브러리의 버전을 통일하기 어려울 때도 있다. 예를 들어 PyTorch 모델을 ONNX 형식으로 변환했을 경우에 이미지 전처리까지 ONNX 형식으로 출력할 수 없기 때문에 ONNX를 실행하는 추론 서버와는 별도로 개발해야 한다. 그래서 이번 구현에서는 PyTorch로 학습된 ResNet50 모델을 사용해 이미지 분류 추론기를 전처리 서버와 추론 서버로 나누어 구현한다.
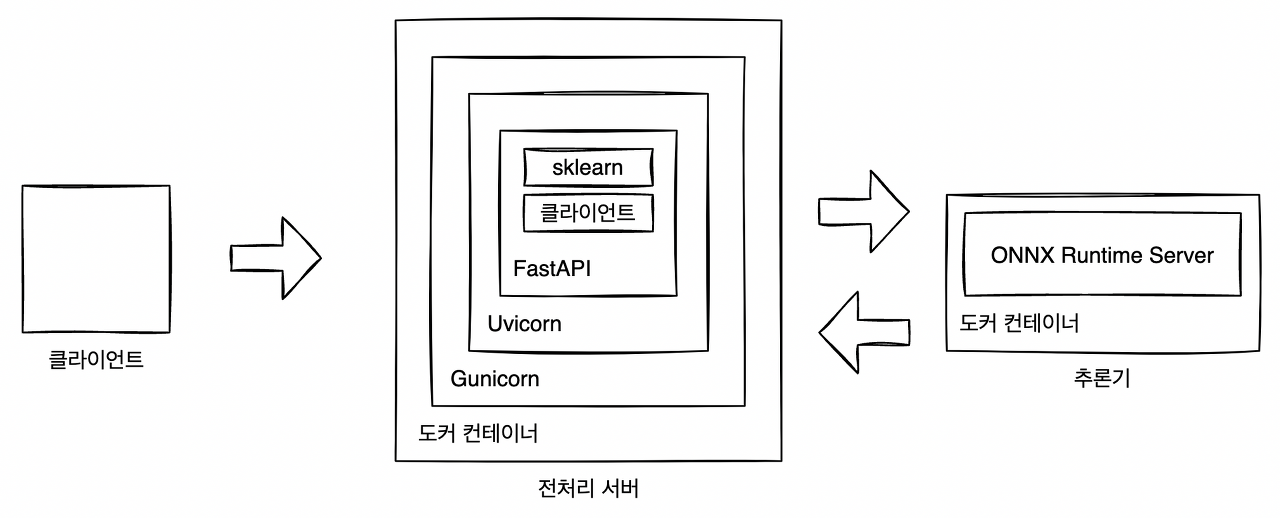 전처리·추론 패턴
전처리·추론 패턴
resnet50_onnx_runtime/extract_resnet50_onnx.py
import json
import os
from typing import List
import click
import joblib
import numpy as np
import onnxruntime as rt
import torch
from PIL import Image
from src.ml.transformers import PytorchImagePreprocessTransformer, SoftmaxTransformer
from torchvision.models.resnet import resnet50
def dump_sklearn(model, name: str):
joblib.dump(model, name)
def get_label(json_path: str = "./data/image_net_labels.json") -> List[str]:
with open(json_path, "r") as f:
labels = json.load(f)
return labels
@click.command(name="extract resnet50 onnx runtime and preprocessing")
@click.option("--pred", is_flag=True)
@click.option("--prep", is_flag=True)
def main(pred: bool, prep: bool):
model_directory = "./models/"
os.makedirs(model_directory, exist_ok=True)
onnx_filename = "resnet50.onnx"
onnx_filepath = os.path.join(model_directory, onnx_filename)
preprocess_filename = f"preprocess_transformer.pkl"
preprocess_filepath = os.path.join(model_directory, preprocess_filename)
postprocess_filename = f"softmax_transformer.pkl"
postprocess_filepath = os.path.join(model_directory, postprocess_filename)
if pred: # 예측을 위해 미리 PyTorch 모델을 ONNX 형식으로 변환
model = resnet50(pretrained=True)
x_dummy = torch.rand((1, 3, 224, 224), device="cpu")
model.eval()
torch.onnx.export(
model,
x_dummy,
onnx_filepath,
export_params=True,
opset_version=10,
do_constant_folding=True,
input_names=["input"],
output_names=["output"],
verbose=False,
)
if prep: # 전처리 클래스를 pkl로 dump
preprocess = PytorchImagePreprocessTransformer()
dump_sklearn(preprocess, preprocess_filepath)
postprocess = SoftmaxTransformer()
dump_sklearn(postprocess, postprocess_filepath)
if prep and pred: # sample 이미지로 onnxruntime inference 수행
image = Image.open("./data/cat.jpg")
np_image = preprocess.transform(image)
print(np_image.shape)
sess = rt.InferenceSession(onnx_filepath)
inp, out = sess.get_inputs()[0], sess.get_outputs()[0]
print(f"input name='{inp.name}' shape={inp.shape} type={inp.type}")
print(f"output name='{out.name}' shape={out.shape} type={out.type}")
pred_onx = sess.run([out.name], {inp.name: np_image})
prediction = postprocess.transform(np.array(pred_onx))
labels = get_label(json_path="./data/image_net_labels.json")
print(prediction.shape)
print(labels[np.argmax(prediction[0])])
if __name__ == "__main__":
main()
- 전처리 서버를 실행하기 전에 sciket-learn의 Custom Transformer(BaseEstimator, TransformerMixin)의 인스턴스를 pickle로 덤프해 저장한다.
- 추론 서버를 실행하기 전에 PyTorch로 학습된 모델을 가져오고, ONNX 형식으로 변환한다.
- ResNet50 모델의 추론 결과를 Softmax 취하는 처리도 scikit-learn의 Transformer(SoftmaxTransformer)로 구현한다.
src/app/routers/routers.py
import base64
import io
from logging import getLogger
from typing import Any, Dict, List
from fastapi import APIRouter
from PIL import Image
from src.ml.prediction import Data, classifier
logger = getLogger(__name__)
router = APIRouter()
@router.get("/health")
def health() -> Dict[str, str]:
return {"health": "ok"}
@router.get("/metadata")
def metadata() -> Dict[str, Any]:
return {
"data_type": "str",
"data_structure": "(1,1)",
"data_sample": "base64 encoded image file",
"prediction_type": "float32",
"prediction_structure": "(1,1000)",
"prediction_sample": "[0.07093159, 0.01558308, 0.01348537, ...]",
}
@router.get("/label")
def label() -> Dict[int, str]:
return classifier.label
# 샘풀 데이터로 추론
@router.get("/predict/test")
def predict_test() -> Dict[str, List[float]]:
prediction = classifier.predict(data=Data().data)
return {"prediction": list(prediction)}
@router.get("/predict/test/label")
def predict_test_label() -> Dict[str, str]:
prediction = classifier.predict_label(data=Data().data)
return {"prediction": prediction}
# 입력 데이터로 추론
@router.post("/predict")
def predict(data: Data) -> Dict[str, List[float]]:
image = base64.b64decode(str(data.data))
io_bytes = io.BytesIO(image)
image_data = Image.open(io_bytes)
prediction = classifier.predict(data=image_data)
return {"prediction": list(prediction)}
@router.post("/predict/label")
def predict_label(data: Data) -> Dict[str, str]:
image = base64.b64decode(str(data.data))
io_bytes = io.BytesIO(image)
image_data = Image.open(io_bytes)
prediction = classifier.predict_label(data=image_data)
return {"prediction": prediction}
- /predict로의 요청에 대해 Classifier 클래스에 정의한 predict 함수를 호출하여 전처리를 실행하고, 추론서버에 gRPC로 추론 요청을 보낸다. 즉 이 시점에서 전처리 서버는 추론 서버에 대해 gRPC 클라이언트로서 가동되고 있다.
src/ml/prediction.py
import json
from logging import getLogger
from typing import Any, List
import grpc
import joblib
import numpy as np
from PIL import Image
from pydantic import BaseModel
from src.configurations import ModelConfigurations
from src.ml.transformers import PytorchImagePreprocessTransformer, SoftmaxTransformer
from src.proto import onnx_ml_pb2, predict_pb2, prediction_service_pb2_grpc
logger = getLogger(__name__)
class Data(BaseModel):
data: Any = ModelConfigurations.sample_image
class Classifier(object):
def __init__(
self,
preprocess_transformer_path: str = "/prep_pred_pattern/models/preprocess_transformer.pkl",
softmax_transformer_path: str = "/prep_pred_pattern/models/softmax_transformer.pkl",
label_path: str = "/prep_pred_pattern/data/image_net_labels.json",
serving_address: str = "localhost:50051",
onnx_input_name: str = "input",
onnx_output_name: str = "output",
):
self.preprocess_transformer_path: str = preprocess_transformer_path
self.softmax_transformer_path: str = softmax_transformer_path
self.preprocess_transformer: PytorchImagePreprocessTransformer = None
self.softmax_transformer: SoftmaxTransformer = None
self.serving_address = serving_address
self.channel = grpc.insecure_channel(self.serving_address)
self.stub = prediction_service_pb2_grpc.PredictionServiceStub(self.channel)
self.label_path = label_path
self.label: List[str] = []
self.onnx_input_name: str = onnx_input_name
self.onnx_output_name: str = onnx_output_name
self.load_model()
self.load_label()
def load_model(self): # pkl로 저장해두었던 전처리 관련 sklearn 클래스 load
logger.info(f"load preprocess in {self.preprocess_transformer_path}")
self.preprocess_transformer = joblib.load(self.preprocess_transformer_path)
logger.info(f"initialized preprocess")
logger.info(f"load postprocess in {self.softmax_transformer_path}")
self.softmax_transformer = joblib.load(self.softmax_transformer_path)
logger.info(f"initialized postprocess")
def load_label(self):
logger.info(f"load label in {self.label_path}")
with open(self.label_path, "r") as f:
self.label = json.load(f)
logger.info(f"label: {self.label}")
def predict(self, data: Image) -> List[float]:
preprocessed = self.preprocess_transformer.transform(data)
input_tensor = onnx_ml_pb2.TensorProto()
input_tensor.dims.extend(preprocessed.shape)
input_tensor.data_type = 1
input_tensor.raw_data = preprocessed.tobytes()
request_message = predict_pb2.PredictRequest()
request_message.inputs[self.onnx_input_name].data_type = input_tensor.data_type
request_message.inputs[self.onnx_input_name].dims.extend(preprocessed.shape)
request_message.inputs[self.onnx_input_name].raw_data = input_tensor.raw_data
response = self.stub.Predict(request_message) # gRPC로 추론서버에 추론요청
output = np.frombuffer(response.outputs[self.onnx_output_name].raw_data, dtype=np.float32)
softmax = self.softmax_transformer.transform(output).tolist()
logger.info(f"predict proba {softmax}")
return softmax
def predict_label(self, data: Image) -> str:
softmax = self.predict(data=data)
argmax = int(np.argmax(np.array(softmax)[0]))
return self.label[argmax]
classifier = Classifier(
preprocess_transformer_path=ModelConfigurations().preprocess_transformer_path,
softmax_transformer_path=ModelConfigurations().softmax_transformer_path,
label_path=ModelConfigurations().label_path,
serving_address=f"{ModelConfigurations.api_address}:{ModelConfigurations.grpc_port}", # 추론서버 uri
onnx_input_name=ModelConfigurations().onnx_input_name,
onnx_output_name=ModelConfigurations().onnx_output_name,
)
- 전처리서버에서는 추론 서버에 대해 gRPC로 요청을 보내는 것을 확인할 수 있다.
resnet50_onnx_runtime/onnx_runtime_server_entrypoint.sh
#!/bin/bash
set -eu
HTTP_PORT=${HTTP_PORT:-8012}
GRPC_PORT=${GRPC_PORT:-50051}
LOGLEVEL=${LOGLEVEL:-"debug"}
NUM_HTTP_THREADS=${NUM_HTTP_THREADS:-4}
MODEL_PATH=${MODEL_PATH:-"/prep_pred_pattern/models/resnet50.onnx"}
./onnxruntime_server \
--http_port=${HTTP_PORT} \
--grpc_port=${GRPC_PORT} \
--num_http_threads=${NUM_HTTP_THREADS} \
--model_path=${MODEL_PATH}
- 추론 서버는 ONNX Runtime 서버로 기동한다. ONNX Runtime 서버는 TensorFlow Serving과 마찬가지로 ONNX 형식의 모델 파일을 열고 REST API 겸 gRPC 서버로서 기동할 수 있다.
run.sh
#!/bin/bash
set -eu
HOST=${HOST:-"0.0.0.0"}
PORT=${PORT:-8011}
WORKERS=${WORKERS:-4}
UVICORN_WORKER=${UVICORN_WORKER:-"uvicorn.workers.UvicornWorker"}
LOGLEVEL=${LOGLEVEL:-"debug"}
LOGCONFIG=${LOGCONFIG:-"./src/utils/logging.conf"}
BACKLOG=${BACKLOG:-2048}
LIMIT_MAX_REQUESTS=${LIMIT_MAX_REQUESTS:-65536}
MAX_REQUESTS_JITTER=${MAX_REQUESTS_JITTER:-2048}
GRACEFUL_TIMEOUT=${GRACEFUL_TIMEOUT:-10}
APP_NAME=${APP_NAME:-"src.app.app:app"}
gunicorn ${APP_NAME} \
-b ${HOST}:${PORT} \
-w ${WORKERS} \
-k ${UVICORN_WORKER} \
--log-level ${LOGLEVEL} \
--log-config ${LOGCONFIG} \
--backlog ${BACKLOG} \
--max-requests ${LIMIT_MAX_REQUESTS} \
--max-requests-jitter ${MAX_REQUESTS_JITTER} \
--graceful-timeout ${GRACEFUL_TIMEOUT} \
--reload
- 전처리 서버는 FastAPI를 사용해 REST API 서버로 구축한다.
docker-compose.yml
version: "3"
services:
prep:
container_name: prep
image: visionhong/ml-system-in-actions:prep_pred_pattern_prep_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- API_ADDRESS=pred
ports:
- "8011:8000"
command: ./run.sh
depends_on:
- pred
pred:
container_name: pred
image: visionhong/ml-system-in-actions:prep_pred_pattern_pred_0.0.1
restart: always
environment:
- HTTP_PORT=8001
- GRPC_PORT=50051
ports:
- "8012:8001"
- "50051:50051"
entrypoint: ["./onnx_runtime_server_entrypoint.sh"]
- 전처리서버와 추론 서버는 도커 컴포즈로 가동하며 먼저 추론서버 컨테이너를 실행한다.
이제 도커 컴포즈로 컨테이너를 실행시켜 전처리 서버에 JPEG 고양이 이미지 파일의 분류를 요청해보자.
docker-compose \
-f ./docker-compose.yml \
up -d
docker ps | grep prep_pred_pattern
# 3a7fec6c0072 visionhong/ml-system-in-actions:prep_pred_pattern_prep_0.0.1 "./run.sh" 26 hours ago Up 26 hours 0.0.0.0:8011->8000/tcp, :::8011->8000/tcp prep
# a6f6572d5a72 visionhong/ml-system-in-actions:prep_pred_pattern_pred_0.0.1 "./onnx_runtime_serv…" 26 hours ago Up 26 hours 0.0.0.0:50051->50051/tcp, :::50051->50051/tcp, 0.0.0.0:8012->8001/tcp, :::8012->8001/tcp pred
(echo -n '{"data": "'; base64 data/cat.jpg; echo '"}') | \
> curl \
> -X POST \
> -H "Content-Type: application/json" \
> -d @- \
> localhost:8011/predict/label
# {"prediction":"Siamese cat"}
 Siamese cat
Siamese cat
이점
- 전처리와 추론기를 통해 서버나 코드베이스를 분할하여 효율적인 리소스 사용이나 장애 분리가 가능함.
- 리소스의 증감을 유연하게 구현할 수 있음.
- 사용할 라이브러리의 버전을 전처리와 추론기에서 독립적으로 선택할 수 있음.
검토사항
전처리와 추론기가 분리되었지만 학습이 완료된 모델이 받는 입력값은 전처리에 의존하기 때문에 전처리 방식이 바뀐다면 추론 결과는 달라지는 것이 당연하다. 따라서 전처리와 추론기의 버전은 릴리스할 때 반드시 일치시켜야 한다. 전처리와 추론기의 버전이 일치하지 않아도 데이터의 형식이 바뀌지 않는 한 추론 자체는 에러 없이 성공할 것이기 때문에 전처리 · 추론 패턴을 사용할 때는 반드시 추론 결과에 대해 검증해 볼 필요가 있다.
End
전처리 · 추론 패턴처럼 한 종류의 모델을 추론기로 가동시키려 해도 여러 서버로 구성해야 하는 경우가 있다는 것을 알게 되었다. 다음 포스팅에서는 동일 시스템 안에서 여러 모델을 추론기로 가동시키는 마이크로서비스 패턴에 대해 알아보자.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/prep_pred_pattern
My Code: https://github.com/visionhong/MLOps-DP/tree/main/serving_patterns/prep_pred_pattern
Leave a comment