Intro
몇일 전 Stable Diffusion 레딧 커뮤니티에 zer0int라는 유저가 이미지 생성 모델에서 핵심 역할을 하는 CLIP 모델의 개선 버전인 CLIP-Registers-Gated 을 공개하였습니다.
작성자는 글에서 기존 CLIP-L 모델을 보다 정밀하게 학습시켜, 텍스트 프롬프트와 이미지 간의 매칭 성능을 향상시켰고 Stable Diffusion(SDXL), Flux, HunyuanVideo 등 다양한 AI 이미지 생성 워크플로우에서 보다 자연스럽고 디테일한 결과물을 얻을 수 있다고 주장합니다.
궁금해서 해당 모델을 테스트 해 보았는데 디테일이 유의미하게 개선되는 모습이 보여서 소개해 드리면 좋을 것 같아 해당 모델에 대한 기술적인 핵심과 테스트 결과를 포스팅으로 정리해 보려고 합니다.
CLIP-Registers-Gated
텍스트-이미지 매칭 성능 향상
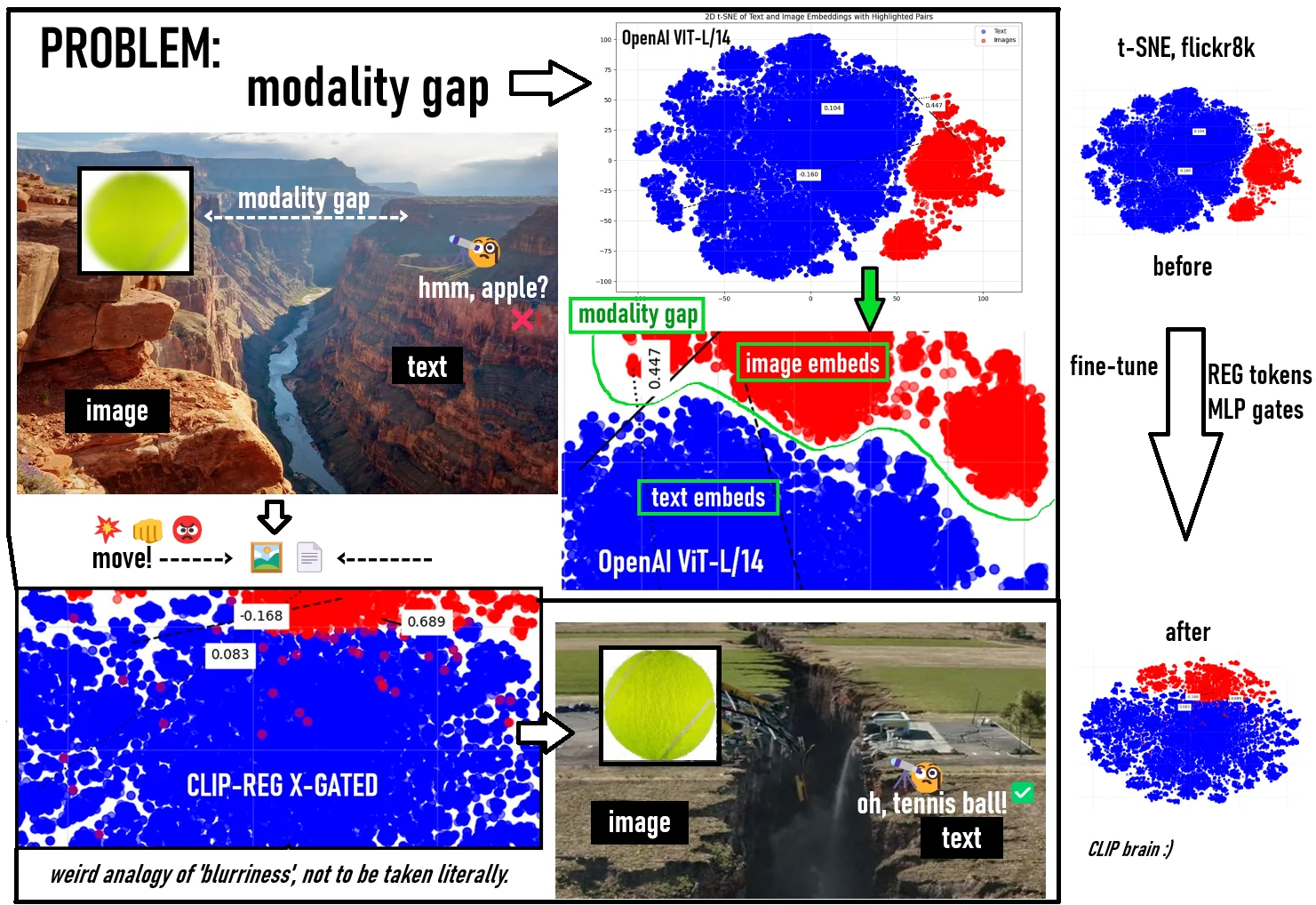
- 기존 CLIP 모델에서는 텍스트와 이미지 간의 모달리티 차이(modality gap)가 커서 정확한 매칭이 어려웠음.
- 새로운 모델에서는 모달리티 차이를 줄여 텍스트가 이미지에 미치는 영향을 더욱 직관적으로 개선.
- 기존 CLIP의 모달리티 차이(Modality Gap): 0.8276
- 새로운 CLIP 모델의 모달리티 차이(Modality Gap): 0.4740
- 이는 텍스트가 이미지의 특징과 더 잘 연결되도록 학습되었음을 의미함.
“레지스터 토큰(Register Tokens)” 활용
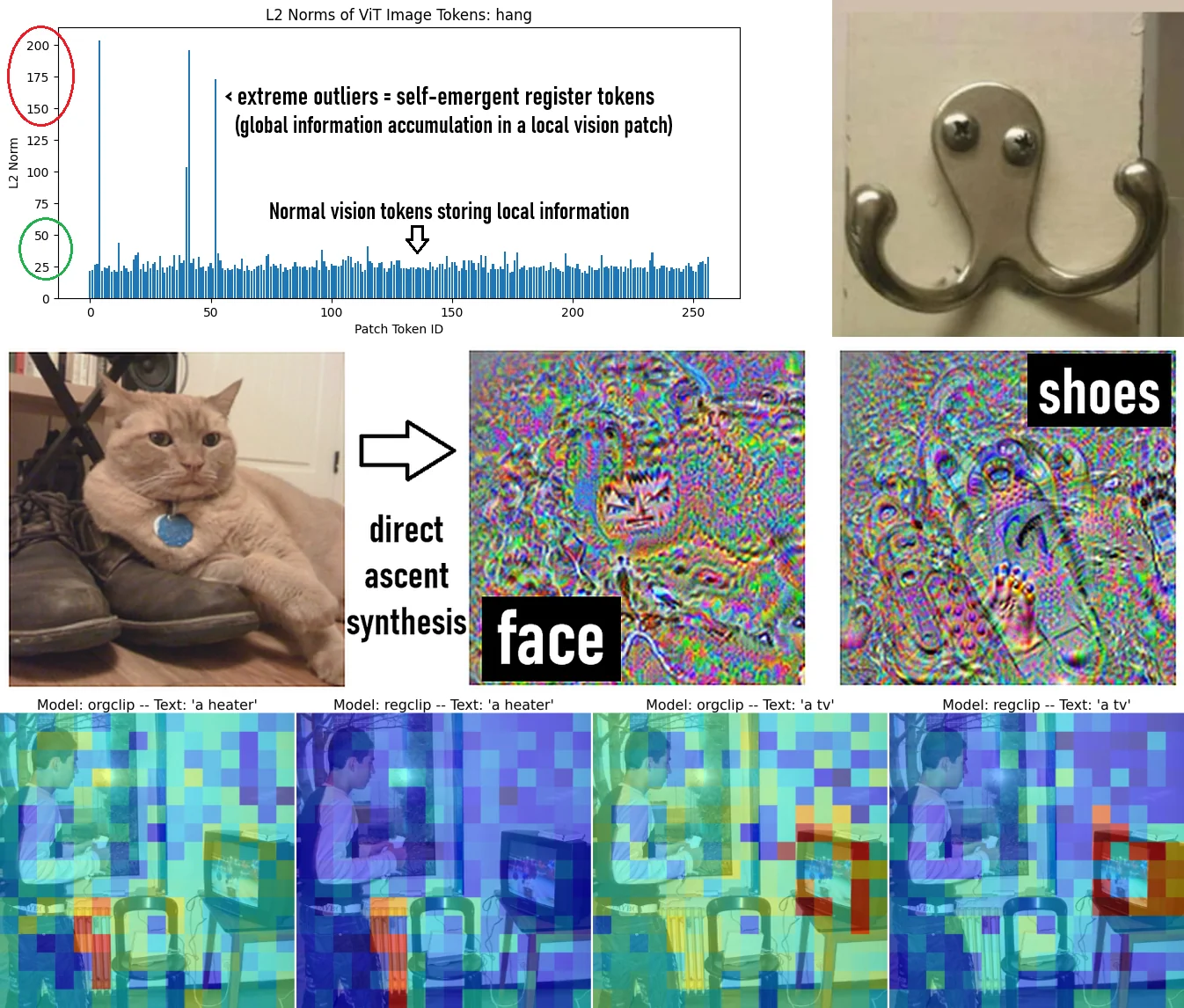
- CLIP 모델은 이미지의 특정 패치(Patch)에서 전역적인 정보를 수집하는 특징이 있음.
- 이를 활용하여, 특정 레이어(Transformer의 12~15층)에서 자연스럽게 나타나는 “레지스터 토큰”(이미지를 대표하는 중요한 정보)을 학습하여 더욱 최적화된 모델을 생성.
- 이로 인해 텍스트와 이미지의 매칭이 더 정확해지고, 불필요한 정보의 혼선이 줄어듦.
MLP 게이트 추가 및 ViT 레이어 개선

- CLIP 모델이 전역 정보를 너무 많이 저장하는 현상(heatmap이 전체적으로 강하게 나타남)이 문제였음.
- 이를 해결하기 위해 MLP 게이트(Multi-Layer Perceptron Gates)와 ReLU 활성화 함수를 추가하여 학습을 조정.
- 결과적으로 패치 정보와 전역 정보를 균형 있게 활용할 수 있도록 개선.
- 이로 인해 CLIP이 텍스트에 맞는 이미지를 찾는 능력이 향상됨.
- 잘못된 특징을 과도하게 강조하는 문제를 완화할 수 있음.
잘못된 세부 묘사 오류 개선
- 기존 CLIP 모델은 이미지 생성 시 손가락 개수가 잘못되거나, 특정 세부 묘사가 이상하게 표현되는 문제가 있었음.
- 새로운 모델은 이러한 오류를 줄여 보다 현실적이고 논리적인 이미지 생성을 돕도록 개선됨.(테스트 결과, Zero-shot 정확도가 91%로 향상됨.)
- 그러나, CLIP 모델이 잘못된 확신(confidently wrong)으로 인해 예상치 못한 디테일을 추가하는 경우도 있음 (예: 손가락 개수를 정확히 맞추지만, 필요하지 않은 장갑을 추가하는 경우).
How to Use
Registers-Gated CLIP 모델은 기존 CLIP-L 모델을 교체해서 바로 사용할 수 있습니다. SDXL, Flux, HunyuanVideo 등 다양한 이미지 및 비디오 생성 모델에서 바로 적용 가능합니다.
Registers-Gated CLIP 모델은 huggingface에서 다운로드 받을 수 있습니다.
zer0int의 주장에 따르면 Vision Transformer(ViT)까지 포함된 풀 모델(GATED)보다는 “TE-Only(텍스트 인코더 전용)” 모델을 사용할 것을 권장하고 있습니다.
텍스트 기반 이미지 생성에서는 Vision Transformer 부분이 필요하지 않으며, TE-Only 모델이 더 가볍고 최적화 되어있다고 합니다. (추천 모델)
ComfyUI workflow
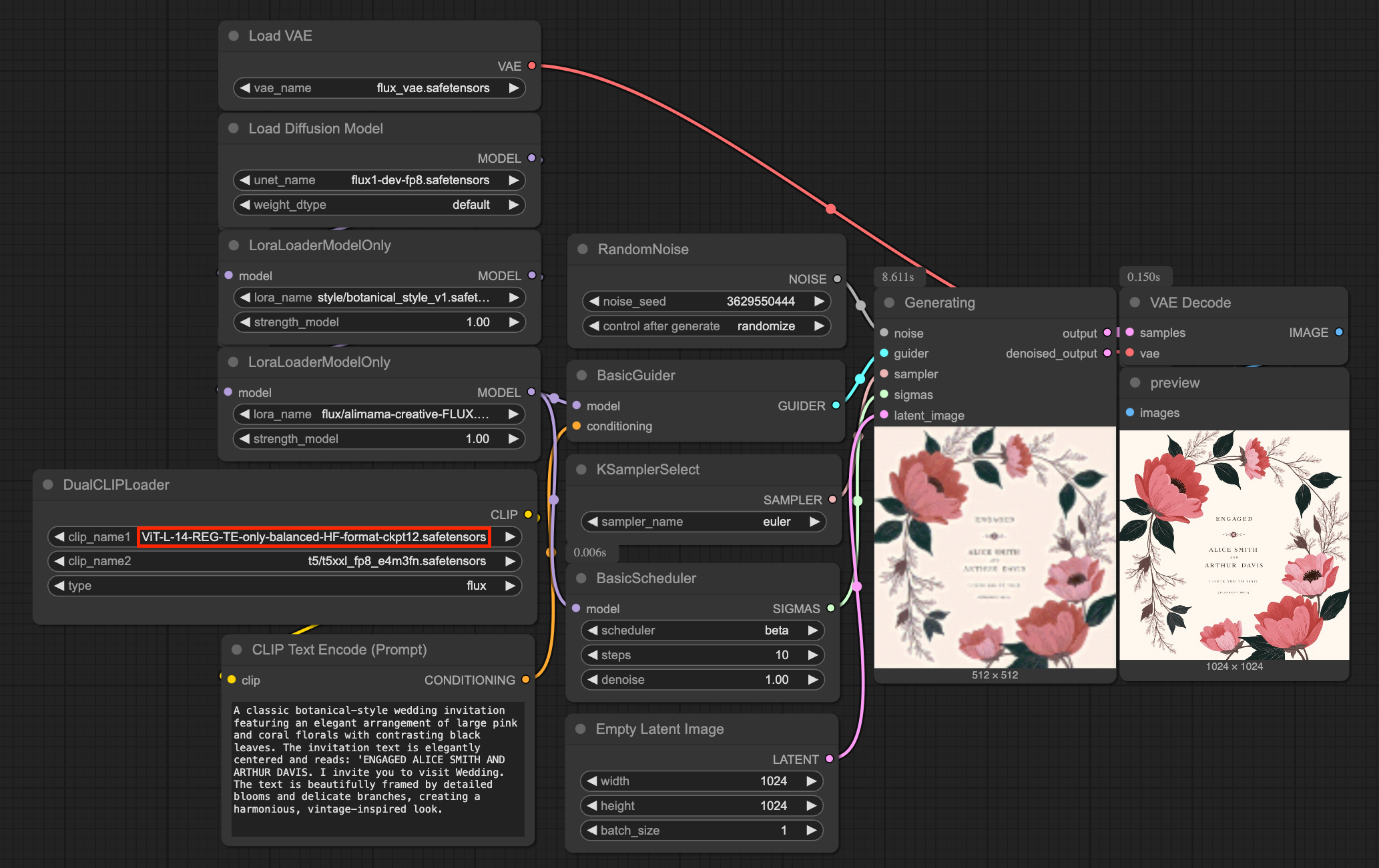
저는 간단하게 Flux-dev 모델에 alimama의 FLUX.1-Turbo-Alpha 모델을 사용해서 테스트를 진행했습니다. 기본 workflow의 DualCLIPLoader에서 기존에 사용하던 CLIP-L 모델을 다운받은 Registers-Gated CLIP 모델로 교체하기만 하면 됩니다.
Experiment Results
아래 실험은 동일한 프롬프트에 대해 CLIP-L, GmP, REG-TE-Only 총 3가지 텍스트 인코더를 사용한 결과 비교입니다. (GmP는 Geometric Parametrization 방식의 동일한 사람이 개발한 다른버전의 CLIP 모델입니다. 해당 모델에 대한 자세한 내용은 여기를 참고해주세요.)
PROMPT: Four bio-luminescent miniature dragons, engineered with crystalline wings and metallic scales, sit poised on a futuristic rooftop overlooking a city of neon lights.

세개의 모델 모두 프롬프트를 잘 따랐지만 CLIP-L 모델은 파란색용이 새끼용이 되어있고 꼬리가 부자연스럽게 되어있습니다. GmP모델에서는 중간의 파란색 용의 날개의 디테일이 아쉽지만 전반적으로 CLIP-L에 비해 디테일이 많이 추가되었습니다. REG 모델은 파란색 용들의 꼬리가 하나로 이어져 있는 문제가 있고 디테일은 가장 우수해 보입니다.
Comparer


CLIP-L
REG-TE-Only
PROMPT: Three cream cheese garlic breads illustrated in a drawing watercolor style, arranged beautifully on a decorative plate. Each round loaf showcases a crispy, golden-brown crust filled with soft cream cheese and sprinkled generously with herbs. Set against a simple, textured background, the illustration includes elegant watercolor brush lettering above, clearly displaying the words “Cream cheese garlic bread”.
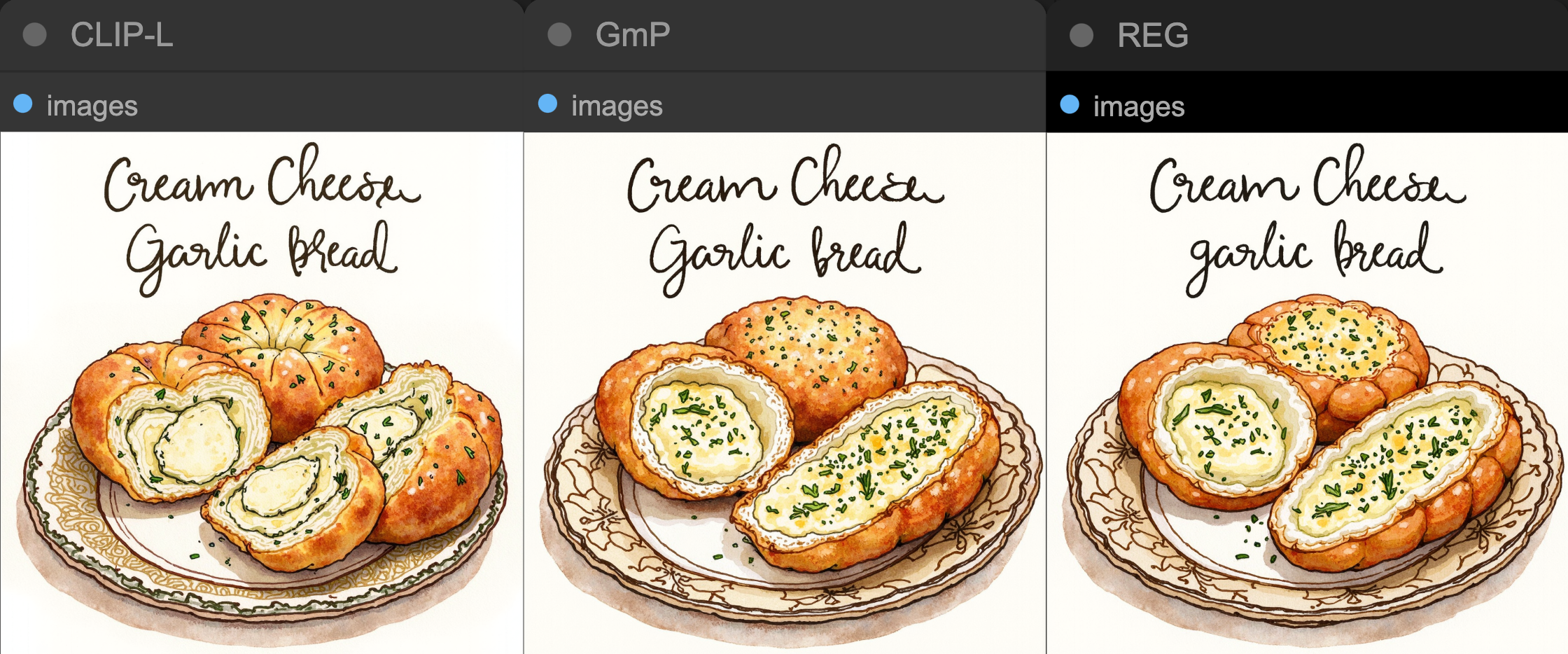
프롬프트에 세개의 빵을 요청했는데 CLIP-L 모델은 4개의 빵이 생성된 모습을 볼 수 있습니다. GmP에서는 우측에 있던 빵이 하나로 합쳐졌지만 무언가 부자연스러워 보이고 가장 위쪽에 있는 빵에 크림치즈가 보이지 않습니다. REG 모델은 전반적으로 안정적이고 디테일이 많이 표현되어 보입니다.
Comparer


CLIP-L
REG-TE-Only
PROMPT: A classic botanical-style wedding invitation featuring an elegant arrangement of large pink and coral florals with contrasting black leaves. The invitation text is elegantly centered and reads: ‘ENGAGED ALICE SMITH AND ARTHUR DAVIS. I invite you to visit Wedding. The text is beautifully framed by detailed blooms and delicate branches, creating a harmonious, vintage-inspired look.
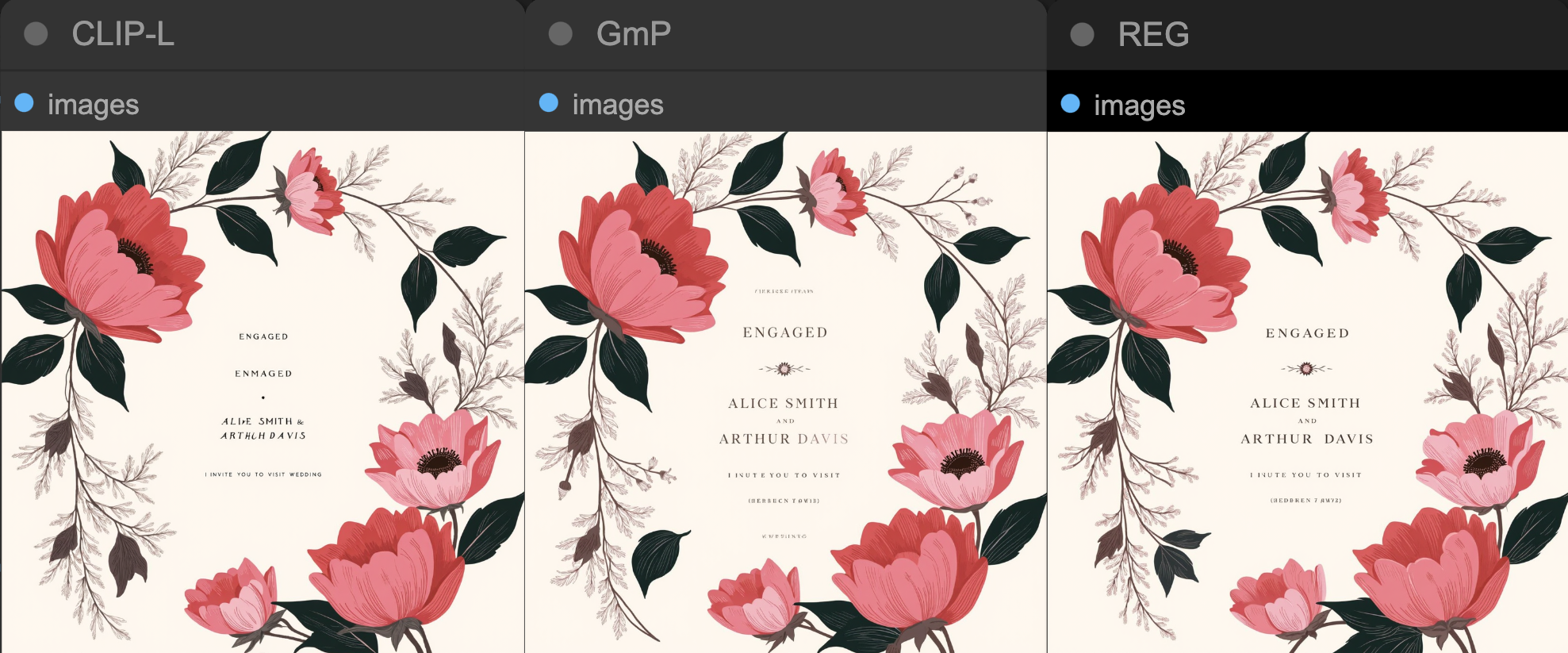
이번에는 텍스트를 위주로 생성해 보았습니다. CLIP-L 모델은 중요한 텍스트를 잘 표현하지 못하고 오히려 아주 작은 텍스트(“I invite you to visit wedding”)를 다른 모델보다 더 잘 표현하는 모습을 보였습니다. GmP와 REG 모델은 전반적으로 텍스트를 잘 표현했지만 GmP의 경우 텍스트 끝부분의 색상이 옅어지는 문제가 있습니다.
Comparer


CLIP-L
REG-TE-Only
Conclusion
지금까지 새로운 텍스트 인코더 모델인 Registers-Gated CLIP 모델에 대해 알아보았습니다. 확실히 CLIP-L 모델을 사용하는 것 보다 GmP, REG 모델을 사용했을때 확률적으로 더 좋은 결과를 얻을 수 있습니다.(Flux with T5 기준)
이미지 생성에서 GmP, REG, LongCLIP 등과 같이 CLIP-L의 개선된 모델들은 생성하고자 하는 이미지의 특징에 따라 장점이 두드러질수도 있고 미미할 수도 있습니다. 무조건 CLIP-L 모델을 사용하는 것 보다 자신의 도메인에 더 좋은 결과를 내는 텍스트 인코더가 있을 수 있으니 여러분들도 실험해보고 적합한 텍스트 인코더를 찾으실 수 있으면 좋을 것 같습니다.
keep going
GitHub: https://github.com/zer0int/CLIP-fine-tune-registers-gated
Reddit: https://www.reddit.com/r/StableDiffusion/comments/1j7cr1y/new_clip_text_encoder_and_a_giant_mutated_vision
Huggingface: https://huggingface.co/zer0int/CLIP-Registers-Gated_MLP-ViT-L-14
Intro
A few days ago on the Stable Diffusion Reddit community, a user named zer0int released CLIP-Registers-Gated, an improved version of the CLIP model which plays a critical role in image generation models.
In the post, the author explained that by training the existing CLIP-L model more precisely, they enhanced the matching performance between text prompts and images, claiming that more natural and detailed results could be achieved across various AI image generation workflows, including Stable Diffusion (SDXL), Flux, and HunyuanVideo.
Curious about it, I decided to test the model myself. I saw a significant improvement in detail, so I thought it would be worth sharing. I’ve therefore organized a post that introduces the key technical points of this model and my test results.
CLIP-Registers-Gated
Enhanced text-image matching performance
- In the original CLIP model, the “modality gap” between text and images was large, making accurate matching difficult.
- The new model reduces this gap, allowing text to have a more intuitive influence on the image.
- Modality Gap in the original CLIP: 0.8276
- Modality Gap in the new CLIP model: 0.4740
- This indicates that text features have been learned to better connect with image features.
Use of “Register Tokens”
- The CLIP model naturally gathers global information from specific patches in the image.
- By focusing on the “register tokens” (key information representing the image) that emerge in certain layers (12–15th layers of the Transformer), a more optimized model is created.
- As a result, text-image matching becomes more accurate, and unnecessary confusion of information is reduced.
Adding MLP gates and improving ViT layers
- A known issue with CLIP was excessive retention of global information (strong overall heatmap).
- To fix this, MLP gates (Multi-Layer Perceptron Gates) and ReLU activation functions were added to adjust learning.
- This improvement allows a balanced use of patch-specific information and global context.
- Consequently, CLIP’s ability to find images that match the text is enhanced.
- Overemphasis of incorrect features is mitigated.
Reduction of incorrect detail depiction errors
- Previously, the CLIP model sometimes generated images with the wrong number of fingers or bizarre details.
- The new model reduces such errors, leading to more realistic and logically consistent image generation (with test results indicating a zero-shot accuracy of 91%).
- However, CLIP can still become “confidently wrong”, occasionally adding unexpected details (e.g., it might correctly depict the number of fingers but add unnecessary gloves).
How to Use
The Registers-Gated CLIP model can directly replace the existing CLIP-L model. It can be applied immediately to various image and video generation models like SDXL, Flux, and HunyuanVideo.
You can download the Registers-Gated CLIP model from huggingface.
According to zer0int, it is recommended to use the “TE-Only (Text Encoder only)” version of the model rather than the full model (GATED) that includes the Vision Transformer (ViT).
For text-based image generation, the Vision Transformer part isn’t necessary, and the TE-Only model is lighter and more optimized. (Recommended model)
ComfyUI workflow
For a simple test, I used Flux-dev with alimama’s FLUX.1-Turbo-Alpha model. In the basic workflow’s DualCLIPLoader, you only need to replace the previously used CLIP-L model with the newly downloaded Registers-Gated CLIP model.
Experiment Results
Below are the comparison results of three text encoders—CLIP-L, GmP, and REG-TE-Only—using the same prompt. (GmP is another version of the CLIP model by the same developer, based on Geometric Parametrization. For more details, visit here.)
PROMPT: Four bio-luminescent miniature dragons, engineered with crystalline wings and metallic scales, sit poised on a futuristic rooftop overlooking a city of neon lights.
All three models followed the prompt quite well, but the CLIP-L model generated smaller, blue dragons with an awkwardly shaped tail. In the GmP model, the middle blue dragon’s wings lacked detail, though overall, it’s more detailed than CLIP-L. The REG model has an issue where the blue dragons’ tails merge into one, but it appears the most detailed among the three.
Comparer
CLIP-L
REG-TE-Only
PROMPT: Three cream cheese garlic breads illustrated in a drawing watercolor style, arranged beautifully on a decorative plate. Each round loaf showcases a crispy, golden-brown crust filled with soft cream cheese and sprinkled generously with herbs. Set against a simple, textured background, the illustration includes elegant watercolor brush lettering above, clearly displaying the words “Cream cheese garlic bread”.
Although the prompt asked for three breads, the CLIP-L model generated four. In the GmP model, the bread on the right merged into one piece but appears somewhat unnatural, and the topmost bread lacks visible cream cheese. The REG model appears more stable overall, with more visible details.
Comparer
CLIP-L
REG-TE-Only
PROMPT: A classic botanical-style wedding invitation featuring an elegant arrangement of large pink and coral florals with contrasting black leaves. The invitation text is elegantly centered and reads: ‘ENGAGED ALICE SMITH AND ARTHUR DAVIS. I invite you to visit Wedding. The text is beautifully framed by detailed blooms and delicate branches, creating a harmonious, vintage-inspired look.
In this test focusing on text, the CLIP-L model failed to properly display the important text, yet unexpectedly did a better job with the very small text (“I invite you to visit wedding”) than the other models. Both GmP and REG models displayed the text more accurately, though GmP’s text fades slightly toward the end.
Comparer
CLIP-L
REG-TE-Only
Conclusion
So far, we’ve looked into the new text encoder model, Registers-Gated CLIP. Indeed, compared to using the CLIP-L model, using GmP or REG can more often produce better results (based on Flux with T5).
In image generation, enhanced versions of CLIP-L like GmP, REG, and LongCLIP can stand out depending on the characteristics of the image you want to generate. Sometimes the improvements may be dramatic, and sometimes they may be minimal. Instead of unconditionally using the CLIP-L model, it’s worth experimenting to see if there’s a text encoder better suited to your domain. You might discover a more fitting text encoder for your specific needs.
keep going
GitHub: https://github.com/zer0int/CLIP-fine-tune-registers-gated
Reddit: https://www.reddit.com/r/StableDiffusion/comments/1j7cr1y/new_clip_text_encoder_and_a_giant_mutated_vision
Huggingface: https://huggingface.co/zer0int/CLIP-Registers-Gated_MLP-ViT-L-14

Leave a comment