
Linear Regression
Linear Regression이란?
- 독립변수와 종속변수의 관계를 분석하는 것.
- 데이터의 분포경향을 학습하여 새로운 데이터가 들어왔을 때 결과값을 예측하는 것
- 결과값이 연속적인 수로 나타난다. -> 회귀
예를 들면 학생들의 성적을 좌우하는 요소에는 공부시간이 있을 것이다. 공부 시간이 길수록 상대적으로 성적이 잘 나올 것이고 공부 시간이 짧다면 성적도 좋지 않을 확률이 높다. 이렇듯 공부시간 즉 정보가 변함에 따라 성적이 변하게 되는 것이다.
그러므로 우리는 정보를 독립변수라고 하고 성적을 종속변수라고 할 수 있다. 선형회귀는 이 독립변수 X를 이용해서 종속변수 Y를 예측하고 설명하는 작업을 한다.
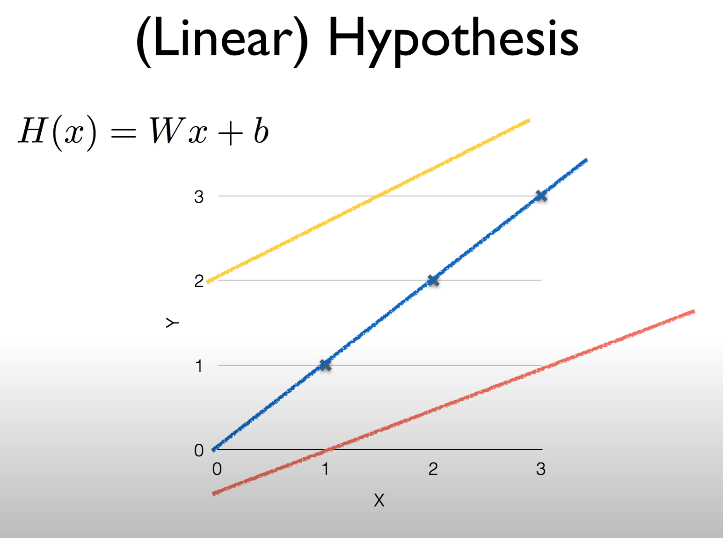
Linear Regression에서의 핵심은 데이터를 나타내는 하나의 직선을 찾아내는 것이고 이 직선은 어느정도의 기울기가 있어야 한다. (기울기가 있다는것은 X와 Y가 서로 상관관계가 있음을 의미하기 때문)
직선은 Weight(기울기)와 bias(편차)를 가지고 있으며 H(x) = WX + b 와 같은 식으로 나타낼 수 있다. 이 식에서 우리가 눈여겨 봐야 할 것은 무엇일까?
직선의 모양을 좌우하는것은 기울기와 편차 즉 W와 b이다. 직선의 모양이 좌우 된다는 의미는 변할수 있다는 것이므로 W와 b는 변수 인 것이다. 그러므로 우리는 데이터의 종속변수(Y)와 독립변수(X)같은 이미 주어진 값 즉 상수를 통해 데이터를 가장 잘 나타낼 수 있는 W와 b를 찾는것이 목적이고 이것이 Linear Regression 학습 목적이다.
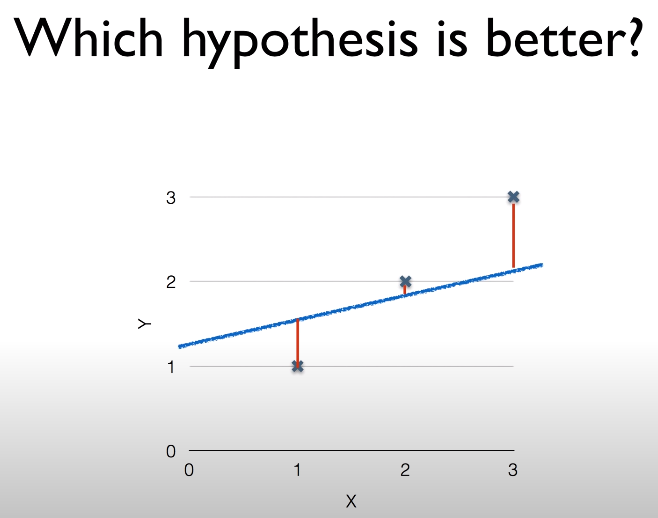
그렇다면 어떻게 W와 b가 가장 데이터를 잘 나타낼수 있도록 학습하기 위해서는 무엇이 필요할까?
바로 위의 그림을 보면 알 수 있듯이 우리의 가설인 H(x) 직선과 데이터 사이의 빨간 선 즉 오차가 있을 것이고 이 오차를 줄이게 된다면 직선은 점점 데이터의 점들에 가까워 지게 될 것이다.
그렇다. 우리는 이 오차를 구할수만 있다면 이 오차를 줄여감으로서 우리의 데이터를 잘 근사하는 직선을 얻을 수 있게 되는 것이다.
여기서 오차는 Loss Function(Cost Function)으로 구하게 되는데 그 식은 다음과 같다.
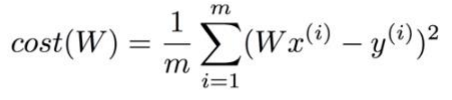
위 수식은 MSE(Mean Square Error)라고 불리며 그 내용은 우리의 가설 H(x)와 실제 값과의 차이를 제곱한 것의 평균을 취함으로서 loss(cost)를 구할 수 있게 된다. 당연히 데이터는 여러개 있기때문에 이것들의 평균을 취하는 것은 이해가 바로 가지만 제곱을 해주는 이유가 뭘까?
그 이유는 두가지가 있다.
- 수식을 보면 데이터와 직선의 거리를 단순히 빼주기 때문에 어떤곳은 negative이고 어떤곳은 positive일텐데 단순히 이것들을 평균 내버리면 직선은 데이터를 충분히 근사하지 못했음에도 불구하고 loss가 매우 낮게 나오는 불상사가 생기기 때문
- 제곱을 취해줌으로서 데이터와 직선의 거리가 큰 구간은 더 큰 패널티를 받게되기 때문에 학습에 도움을 주기 때문
우리는 이제 Loss Function을 통해 cost를 구할 수 있게 되었다. 그런데 어떻게 cost를 줄여나갈 수 있을까? 여기서 Gradient Descent라는 개념이 필요하다.
Gradient Descent
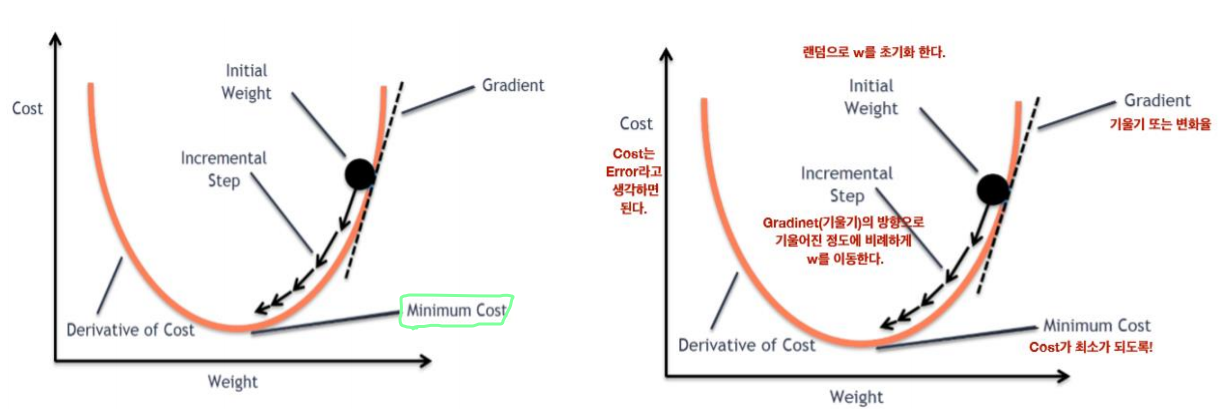
Gradient Descent(경사 하강법)이란 말 그대로 Cost가 매우 작아질 때 까지 경사를 하강하는 것을 의미한다. 다른말로 Cost가 0에 가까워질때 까지 파라미터(Weight, bias)를 조절하는 알고리즘이다.
그런데 어떤 방식으로 파라미터들이 움직이게 되는지 알아야 한다. 우리가 깜깜한 저녁에 산에서 긿을 잃었을때 하산할 수 있는 방법은 무엇이 있을까? 단순하다. 그냥 경사를 확인하고 아래로 향한 경사면 그 길을 따라 가게 될 것이다.
경사 하강법도 마찬가지이다. 현재 W의 위치가 위 그림의 점이라고 할때 그 위치에서의 경사도를 통해 방향을 찾고 그곳으로 이동을 하게 되는 것이다.
자 그럼 경사도 즉 기울기는 어떻게 구할 수 있을까? 바로 미분을 통해 구할 수 있다. (미분 = 기울기) 그런데 위에서 언급했지만 우리는 변수가 2개(W, b)가 있기 때문에 일반적인 상미분이 아니라 편미분(독립변수가 2개 이상일때 필요)을 사용해서 Weight를 구해야 한다.

위의 사진처럼 편미분을 하여 W와 b의 기울기를 얻게되고 최종적으로 업데이트 할 W와 b 식을 구할 수 있게 된다. 그렇게 업데이트 된 W와 b를 통해 우리는 다시 H(x) 즉 Ŷ(예측) 을 세울 수 있고 이 가설은 파라미터들을 기울기만큼 움직였으므로 Cost가 낮아져 이전 가설보다 Y(정답)과 더 가까워 지게 되는 것이다. 즉 추세선이 정답을 근사해 갔다고 할 수 있다.
이 Cost minimize과정을 코드로 보면 아래와 같다.
num_epoch = 100000
learning_rate = 0.0003
X = C = np.random.randint(0, 100, 100)
Y = F = 1.8 * C + 32
# weight, bias 초기화
w = np.random.uniform(-1.0, 1.0)
b = np.random.uniform(-1.0, 1.0)
for epoch in range(num_epoch):
y_predict = w*X + b
loss = ((y_predict - Y)**2).mean()
if(loss < 0.1):
break
else:
w = w - learning_rate * ((y_predict - Y)*X).mean()
b = b - learning_rate * (y_predict - Y).mean()
if epoch % 10000 == 0:
print(f'EPOCH: {epoch} w: {w:.3f}, b: {b:.3f}, loss={loss:.3f}')
X는 섭씨온도이고 Y는 화씨온도로 주어졌다. 우리의 목표는 어떤 섭씨온도를 주었을때 그것을 화씨온도로 변환해주는 모델을 만드는게 목적이다. 여기서 모델이란 것은 바로 섭씨온도와 화씨온도를 잘 표현하는 추세선을 말한다.
우리는 이 데이터에 맞는 추세선을 좌지우지하는 W와 b를 구해야 하는데 그러기 위해서는 우선 초기값이 있어야 하므로 -1~1사이의 임의의 실수값을 지정하였다.
매 iteration마다 가설과 loss(cost)를 구해주고 loss가 0.1보다 클 경우 계속해서 파라미터를 업데이트해주는 로직이다.
위 과정을 반복적으로 수행하게 되면 cost는 0에 가까워 질 것이며 그렇다는 것은 우리의 H(x)는 정답과 거의 근사해서 더이상 학습은 의미가 없어질 것이다. 그렇게되면 학습을 멈추고 그때의 W와 b를 최종 파라미터로 정하여 고정시키게 된다.
위의 코드를 실행하면 아래와 같은 결과가 도출된다.
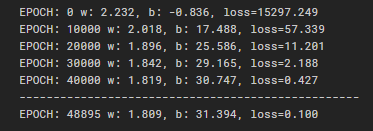
실제로 섭씨를 화씨로 변환하는 식은 F = 1.8 * C + 32 인데 결과값을 보면 W가 1.809로 b가 31.394로 거의 실제 식과 유사해진 것을 볼 수 있다.
학습된 W와 b를 가지고 실제로 화씨를 예측해보자
farad = w * 50 + b
print('예측 화씨온도: ',farad)
print('실제 화씨온도: ',1.8*50 + 32)

위와같이 학습이 잘 된것을 알 수 있다.
End
이번 포스팅에서는 Linear Regression에 대해서 알아보았다.
Linear Regression이란 정보를 나타내는 어떤 X의 변화에 따른 정답 Y가 어떻게 변하는지 예측하고자 그 데이터들의 점을 잘 따르는 추세선을구하는 것이 목적이다.
그 추세선을 좌지우지하는것은 바로 Weight(기울기)와 Bias(절편)이며 우리는 이 파라미터들을 잘 조정해서 오차를 최소로 줄일 수 있는 파라미터로 만들어야 하며 이 과정을 cost minimize라고 한다.
그리고 그 cost minimize는 바로 Gradient Descent 알고리즘으로 작동하게 된다.
Keep going
Reference
Explanation - www.youtube.com/watch?v=TxIVr-nk1so&list=PLlMkM4tgfjnLSOjrEJN31gZATbcj_MpUm&index=6
Leave a comment