
[논문리뷰] MobileNet v1
MobileNets : Efficient Convolutional Neural Networks for Mobile Vision Applications
이번 포스팅에서는 구글에서 2017년 10월에 발표한 논문 MobileNet에 대하여 다뤄 보려고 한다.
사실 이 논문에서는 어떤 새로운 방법론에 대해 다뤘다기 보다 기존의 CNN의 무거운 네트워크를 수정하는 내용을 다루고 있다.
컴퓨터 비전에 대한 상업적인 요구사항을 두가지 관점에서 생각해 보면 다음과 같다.
1. Data-centers(clouds)
- Rarely safety-critical
- Low power is nice to have
- Real-time is preferable
2. Gadgets= Smartphones, Self,driving cars, Drones, etc.
- Usually safety-critical(except smartphone)
- Low power is must-have
- Real-time is required
앞으로 점점 더 이런 딥러닝 모델이 서버 뿐만이 아니라 자율주행자동차나 스마트폰과 같은 곳에 들어가게 될텐데 이때는 안정성이 요구되고 저전력이어야 하며 실시간으로 탐지가 가능한 수준이어야 한다.
그러기 위해서는 충분히 높은 정확도, 낮은 연산량 및 에너지 사용량, 작은 모델사이즈가 필요하게 되는데 지금의 CNN 모델은 이런 device에 들어가기에 논문에서는 버겁다고 이야기하고 있다.
작은 네트워크가 필요한 이유는 다음과 같다.
- train faster on distributed hardware
- more deployable embedded processors
- easily updatable Over-The-Air(OTA : 통신망으로 소프트웨어를 업데이트 할 수 있는 기술)
Small Deep Neural Network를 만들기 위한 기법
- Remove FC layers -> Fully-connected layer는 CNN 기준으로 전체 파라미터의 90%를 차지한다.(convolution layer와 달리 파라미터 sharing을 하지 않기 때문에)
- Kernel size Reduction -> 3 x 3 ->1 x 1 을 통해 파라미터 수를 줄일 수 있다.
- Channel Reduction
- Evenly Spaced Downsampling -> 초반에 Downsampling을 많이 하게되면 네트워크가 작아지지만 정확도가 떨어지고 후반에 Downsampling을 몰아서 하게 되면 정확도가 좋지만 파라미터 수가 많아지게 되는 단점이 있다. 그러므로 균일하게 Downsampling을 해줘야 한다.
- Depthwise Separable Convolutions
- Shuffle Operations
- Distillation & Compression
이 논문내용의 거의 대부분이 Depthwise Separable Convolutions에 대해 다루고 있다.
Background
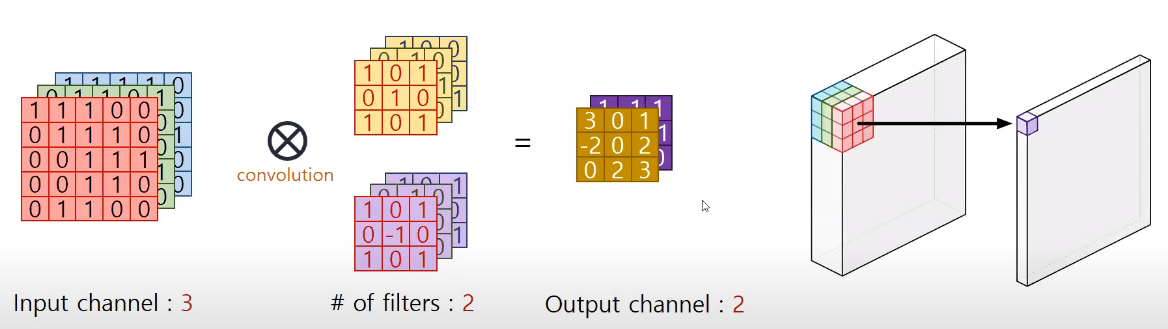
위 그림은 일반적인 Convolution 연산에 대한 그림이다. 3 x 3 filter를 쓰게되면 width와 height는 포함이 되지만 channel은 filter를 몇개 쓰느냐에 따라서 다음 input의 channel이 결정이 된다.
즉 Convolution은 width height channel을 한꺼번에 고려해서 만약에 3 x 3 filter 1개를 사용한다면 width height channel을 한꺼번에 elementwise multiplication 한 다음에 전체를 다 summention 하여 27개의 숫자쌍을 1개의 숫자로 표현하게 된다.
VGGNet에서 3 x 3 filter를 여러번 사용하는 것이 5 x 5나 7 x 7 filter를 사용하는 것보다 파라미터 수도 적을 뿐더러 활성함수가 여러번 사용되므로 Non-linearity가 더 좋아진다고 나왔고 이후에 GoogleNet의 Inception v2부터 5 x 5 filter를 3 x 3 filter 2개를 사용하는 것으로 바꾸고 또한 3 x 3 을 1 x 3 과 3 x 1 같이 인수분해를 통해 파라미터를 줄였다.
여기서 width와 height는 신나게 쪼개서 활용하는데 channel은 꼭 한번에 다 곱해야 하는 것인가? 라는 의문이 자연스럽게 든다. 그래서 이 논문는 Depthwise Separable Convoution을 제시하였다.
Depthwise Separable Convolutions
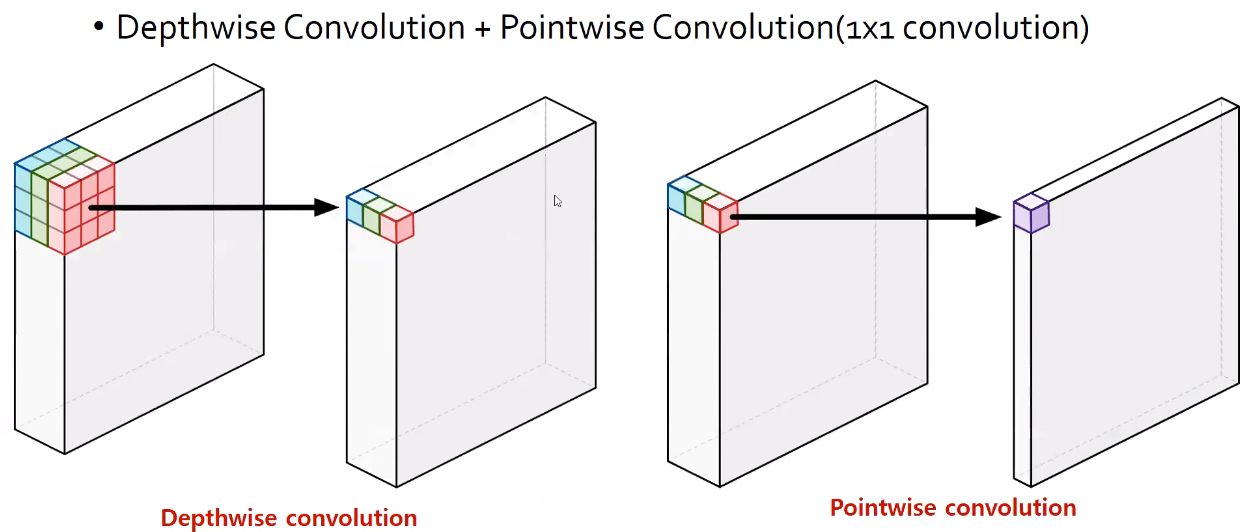
Depthwise Separable Convolution은 위 그림과 같이 먼저 각각의 채널에 대한 3 x 3 filter연산을 적용을 하여 channel reduction이 일어나지 않도록 Depthwide convolution 해주고 이 값들의 채널 방향 correlation을 뽑아내는 연산은 Pointwise convolution을 통해 진행이 된다.
이렇게 되면 standart convoution과 결과는 같게 나오지만 파라미터 수는 훨씬 줄어들게 된다.

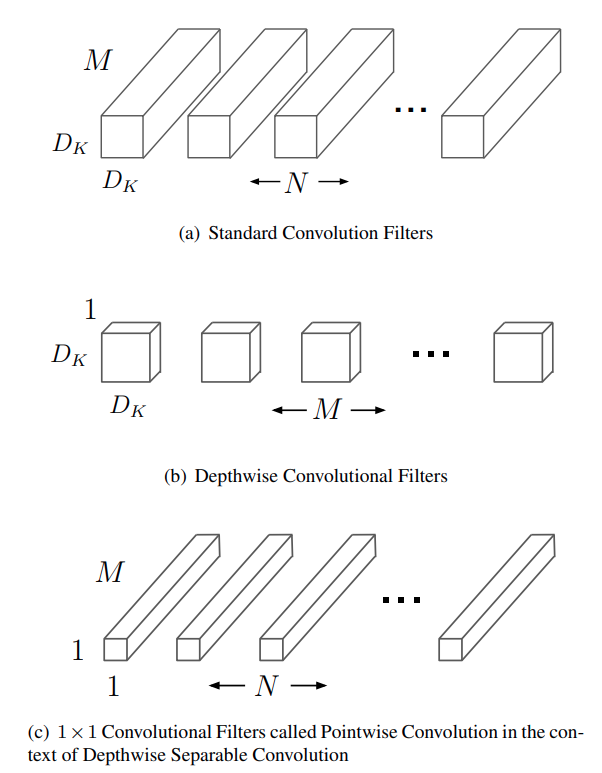
Standard Convolution의 파라미터 : Dk x Dk x M x N
Depthwise Convolution의 파라미터 : Dk x Dk x 1 x M + 1 x 1 x M x N
Standard Convolution의 연산량 : Dk x Dk x M x N x Df x Df
Depthwise Convolution의 연산량 : Dk x Dk x 1 x M x Df x Df + 1 x 1 x M x N x Df x Df
Depthwise / standard = Dk^2 + N / Dk^2 x N < 1
계산 결과를 보면 Depthwise separable convolution의 연산량이 훨씬 작다는 것 짐작할 수 있다. 실제 값을 넣어봐서 정말로 파라미터가 줄어 드는지 확인해보자
input : 3 x 28 x 28 filter : 3 x 3output : 32 x 28 x 28 Dk = 3, M = 3, N = 32
Standard Convolution = Dk x Dk x M x N = 3 x 3 x 3 x 32 = 864개
Depthwise Separable Convolution = Dk x Dk x 1 x M + 1 x 1 x M x N = 3 x 3 x 1 x 3 + 1 x 1 x 3 x 32 = 123개
계산결과 Depthwise Separable Convolution의 파라미터가 약 7배 적다는 것을 확인 할 수 있다.
Depthwise Separable Convolutions 구조
아래에서 왼쪽은 일반적인 standard conv 이고 오른쪽이 논문에서 제시하는 depthwise separable conv 이다.
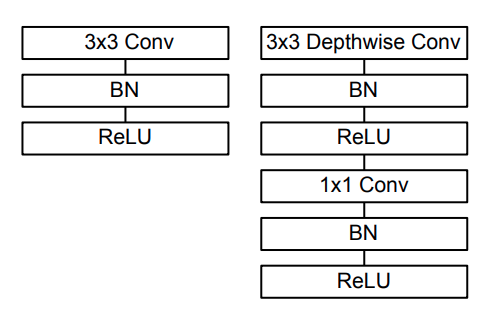
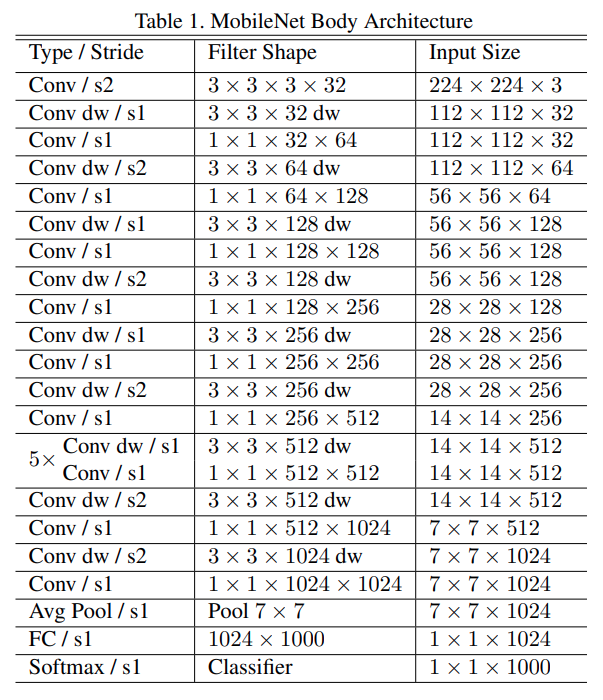
전체적인 구조를 살펴보면 224x224x3 이미지에 대해 첫번째 레이어는 standard conv를 사용하고 그 이후부터 depthwise conv 와 pointwise conv를 번갈아 가면서 수행한다. feature-map의 사이즈는 S2(stride=2)로 해서 크기를 절반으로 줄여주고 채널수(필터의 수)는 pointwise conv 레이어에서 지정해준다.
feature-map의 크기가 7 x 7 x 1024가 되면 global avg-pooling을 이용하여 1x1x1024 로 만들고 한개의 FC레이어와 softmax를 통해 최종적으로 1 x 1 x 1000이 된다. (1000은 ILSVRC 대회의 클래스 개수)
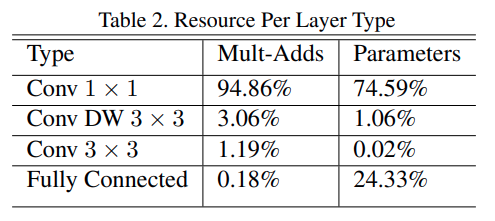
논문에서는 아래와 같이 위에 나온 구조의 각각의 레이어에 대한 파라미터 분포를 계산을 하였다. 초반에 일반적인 CNN구조에서는 FC layer가 전체 파라미터의 90%정도를 차지한다고 설명하였는데 아래를 보면 FC layer가 아닌 Conv 1 x 1 layer의 파라미터가 74.59%로 훨씬 많다는 것을 알 수 있고 이말은 즉슨 그만큼 파라미터 수가 줄어들었다는 의미가 된다.
Width Multiplier & Resolution Multiplier
논문에서는 Depthwise Separable Convolution 말고도 두가지의 옵션을 추가하였는데 바로 Width Multiplier 와 Resolution Multiplier 이다.
Width Multiplier는 입력채널수 M을 αM(α : 1, 0.75, 0.5, 0.25)으로 단순히 채널을 줄여서 αN만큼의 output channel 을 내보내고 Resolution Multiplier는 해상도 즉 이미지 사이즈 Df 를 ρDf(ρ : 1, 0.857, 0.714, 0.571)로 줄이는 것을 말한다.
- Computational cost : Dk x Dk x αM x ρDf x ρDf + αM x αN x ρDf x ρDf
MobileNet V1 구현코드
import torch.nn as nn
from torchsummary import summary
class MobileNetV1(nn.Module):
def __init__(self, ch_in, n_classes):
super(MobileNetV1, self).__init__()
self.ch_in = ch_in
self.n_classes = n_classes
def conv_st(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True))
def conv_dw(inp, oup, stride):
return nn.Sequential(
# depthwise
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# pointwise
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential( # 224x224x3
conv_st(self.ch_in, 32, 2), # 112x112x32
conv_dw(32, 64, 1), # 112x112x64
conv_dw(64, 128, 2), # 56x56x128
conv_dw(128, 128, 1), # 56x56x128
conv_dw(128, 256, 2), # 28x28x256
conv_dw(256, 256, 1), # 28x28x256
conv_dw(256, 512, 2), # 14x14x512
conv_dw(512, 512, 1), # 14x14x512
conv_dw(512, 512, 1), # 14x14x512
conv_dw(512, 512, 1), # 14x14x512
conv_dw(512, 512, 1), # 14x14x512
conv_dw(512, 512, 1), # 14x14x512
conv_dw(512, 1024, 2), # 7x7x1024
conv_dw(1024, 1024, 1), # 7x7x1024
nn.AdaptiveAvgPool2d(1) # 1x1x1024
)
self.fc = nn.Linear(1024,self.n_classes)
def forward(self, x):
x = self.model(x)
x = x.view(-1,1024)
x = self.fc(x)
return x
if __name__=='__main__':
# model check
model = MobileNetV1(ch_in=3, n_classes=1000)
summary(model, input_size=(3, 224, 224), device='cpu')
논문에 있는 구조 그대로 구현된 코드이다. Pytoch에서는 Depthwise Separable Convolution layer가 따로 존재하지 않고 Conv2d의 파라미터인 groups를 이용해 input channel의 크기를 적어주면(이전 레이어의 채널값이 현재필터사이즈의 차원이므로) channel reduction이 일어나지 않고 Depthwise convolution을 수행하게 된다. 이때 output channel의 크기가 input channel크기와 동일해야 한다는 것을 유의해야 한다.
torchsummary 의 summary를 사용하면 네트워크의 구성, 파라미터의 개수, 파라미터의 용량, 연산 수를 확인할 수 있다. 기본적으로 모델과 input_size를 입력받게 되어있는데 여기서 주의할 점은 input_size에 width x height x channel이 아닌 channel x width x height 순으로 입력해주어야 한다.
코드 실행 결과는 아래와 같다.


ENDING
이번 포스팅에서는 MobileNet V1에서 알아보았다. MobileNet V1은 기존의 filter size 만으로 파라미터 수를 줄이려고 했던 고정관념에서 벗어나 Depthwise Separable Convolution을 적용하여 각각의 채널에 대해 filter연산을 하고 채널끼리의 correlation을 합쳐서 약간의 성능 개선과 연산량을 획기적으로 줄임으로써 embedded processors에 조금 더 적합한 네트워크를 제시하였다.
Refference
paper : arxiv.org/abs/1704.04861
paper review : www.youtube.com/watch?v=7UoOFKcyIvM&t=1292s
Leave a comment