Scalable Vector Graphics(SVG)는 해상도에 구애받지 않고 품질을 유지하며 손쉽게 편집할 수 있다는 장점으로 현대 디지털 디자인의 핵심 형식으로 자리 잡았습니다. UI/UX 디자인부터 CAD에 이르기까지 널리 쓰이는 SVG는 베지어 곡선이나 폴리곤 같은 벡터 도형들을 정밀하게 정의하여 어떤 해상도에서도 선명한 그래픽을 제공합니다.
Pikachu
Mario
PUBG
그러나 고품질 SVG 콘텐츠를 제작하는 일은 비전문가에게 여전히 어려운 과제로, 전문 툴 사용법이나 복잡한 XML 코드를 익혀야 하는 높은 진입장벽이 있습니다.
기존에 SVG를 자동 생성하려는 시도로 최적화 기반 방법과 오토레그레시브(auto-regressive) 방법이 연구되어 왔습니다. 최적화 기반 기법은 미분 가능한 벡터 그래픽 렌더러를 이용해 원하는 이미지를 반복적으로 맞춰가는 방식인데, 아이콘처럼 단순한 그래픽에는 효과적일지라도 복잡한 SVG로 확장하기엔 계산 비용이 막대하고 생성된 SVG 경로가 구조적으로 정돈되지 않아 불필요한 점이나 선분이 많은 한계가 있었습니다.
반면 Auto-regressive 방법은 트랜스포머 같은 모델이나 대형 언어 모델(LLM)을 사용해 SVG의 XML 코드나 명령 시퀀스를 직접 생성하는 접근입니다. 이 방식은 대량의 SVG 데이터로부터 end-to-end 학습이 가능해 확장성 측면에서 유망하나, 현재까지는 문맥 길이 한계와 복잡한 SVG 데이터 부족 때문에 주로 단순하고 흑백에 가까운 아이콘 생성에 머물렀습니다. 다시 말해, 좌표나 경로 정보가 길어지면 LLM이 처리하기 어렵고 학습 데이터도 복잡도가 낮았던 것이죠.
이러한 한계를 극복하고 고품질·고복잡도 SVG 그래픽 생성을 목표로 제안된 것이 OmniSVG입니다.
OmniSVG Generation Process
OmniSVG는 사전 학습된 비전-언어 모델(VLM)을 활용한 텍스트 및 이미지 기반의 통합 SVG 생성 프레임워크로, 복잡한 컬러 벡터 그래픽도 end-to-end로 생성해냅니다. 핵심 아이디어는 SVG의 도형 명령어들과 좌표들을 Discrete Token으로 파라미터화하여, 구조적인 로직(어떤 도형을 그릴지)과 저수준 기하정보(정확한 좌표 값)를 분리한 것입니다.
이렇게 하면 모델이 좌표 값을 문자 그대로 일일이 생성할 때 나타나는 “좌표 환각”(비현실적이거나 불일치한 좌표 생성) 문제를 줄이고, 복잡한 구조도 효율적으로 학습할 수 있습니다.
나아가 OmniSVG를 학습시키기 위해 MMSVG-2M이라 불리는 2백만 개 규모의 대규모 SVG 데이터셋과 텍스트·이미지 조건부 SVG 생성에 대한 표준 평가 프로토콜도 함께 도입하였습니다.
종합적인 실험 결과 OmniSVG는 기존 방법들을 뛰어넘는 성능을 보였고, 전문 디자인 워크플로에도 통합될 수 있는 가능성을 보여주었습니다.
이번 포스트에서는 OmniSVG 논문의 주요 내용을 정리해 보려고 합니다.
Key Ideas
OmniSVG Demo
OmniSVG의 핵심은 SVG를 텍스트처럼 취급할 수 있도록 하는 것입니다. 앞서 언급했듯이 SVG의 구성 요소(패스 명령어와 좌표 값)를 모두 사전에 정의된 디스크리트 토큰 시퀀스로 변환합니다.
예를 들어 SVG 패스의 <path d="M10 10 L100 100 Z" /> 같은 명령을 토큰화하여 [M, 10, 10, L, 100, 100, Z] 식의 시퀀스로 만드는 식입니다.
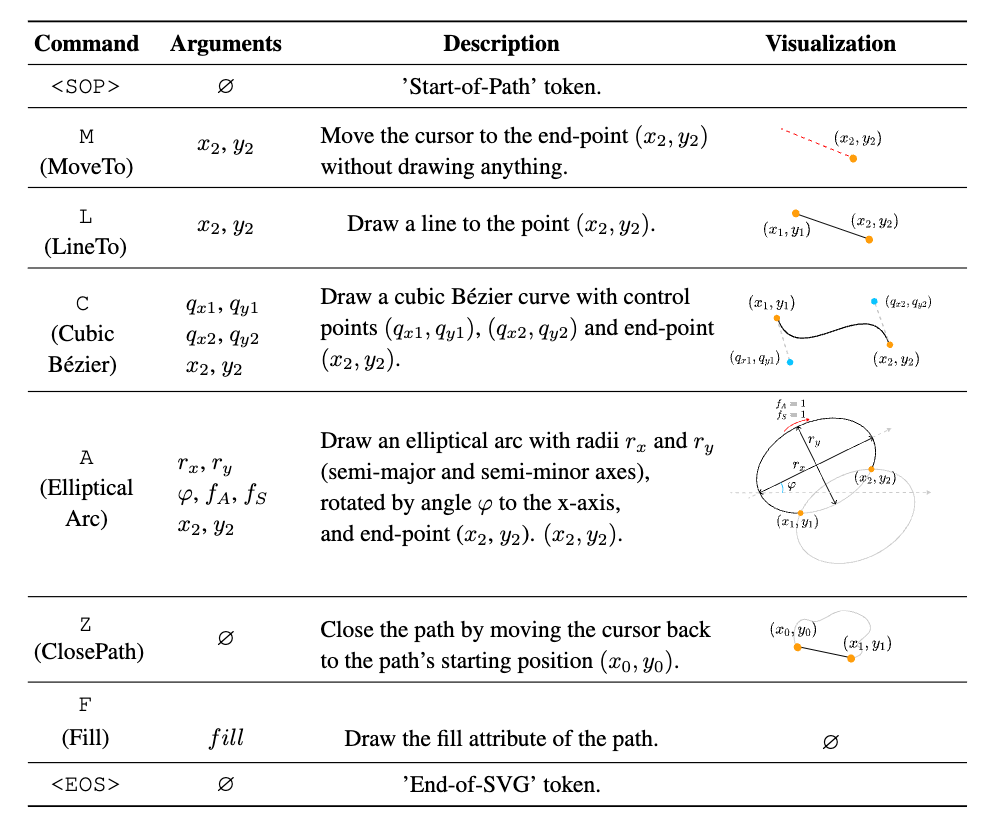
Draw Commands
OmniSVG에서는 SVG를 그리는 다섯 가지 기본 패스 명령, 즉 MoveTo (M), LineTo (L), Cubic Bezier Curve (C), Elliptical Arc (A), ClosePath (Z)만 사용하도록 SVG를 단순화하고 불필요한 속성은 제거했습니다.
그리고 도형의 채색 정보를 위해 별도의 Fill (F) 토큰을 도입하여 경로별 채움색을 표현했습니다. 좌표 값도 개별 숫자 문자 토큰들로 나열하는 대신, 좌표 하나하나를 하나의 토큰으로 취급하도록 범위를 양자화해 부호화했습니다.
이러한 SVG 토크나이저를 통해 긴 좌표 나열을 짧은 토큰 하나로 치환함으로써 시퀀스 길이를 크게 줄이고 복잡한 도형도 30k 토큰 이내에서 표현할 수 있게 되었습니다. 이는 기존 LLM 기반 방법이 2048토큰 한계로 복잡한 SVG를 다루지 못하던 문제를 해결하는 중요한 설계입니다.
Architecture
OmniSVG 모델은 이렇게 토큰화된 SVG 시퀀스를 대형 VLM(비전-언어 모델)을 통해 생성합니다. 구체적으로 Alibaba의 Qwen-VL 모델 구조를 기반으로 하는데, 이 모델은 텍스트와 이미지를 동시에 입력 받아 처리할 수 있는 멀티모달 트랜스포머입니다.
OmniSVG는 여기에 SVG 생성을 위한 토큰 출력 능력을 덧붙이기 위해, 앞서 정의한 SVG 토크나이저를 사용해 SVG 시퀀스를 생성 토큰으로 예측하도록 훈련되었습니다. 훈련 과정에서 모델의 입력으로는 텍스트 설명과 이미지(필요한 경우)가 주어지고, 출력으로 해당 조건에 맞는 SVG의 토큰 시퀀스를 내도록 합니다.
요약하면, OmniSVG는 “프롬프트 → SVG 토큰 시퀀스”로 이어지는 거대한 시퀀스 생성 모델이라고 볼 수 있습니다. 여기서 프롬프트는 텍스트만 있을 수도 있고, 이미지가 포함될 수도 있으며, 둘 다 주어질 수도 있습니다. 이러한 멀티모달 입력은 Qwen-VL 모델의 Prefix Token으로 삽입되어 처리되고, 모델은 그 뒤를 잇는 SVG 토큰들을 한 단계씩 예측하여 완성된 SVG를 출력합니다.
이 접근법의 장점은 크게 두 가지입니다.
첫째, 구조와 기하의 분리입니다. SVG의 복잡한 계층 구조나 경로 순서는 모델이 이해해야 할 논리적 구조이고, 좌표 값이나 세부 색상은 기하학적 세부정보인데, OmniSVG는 구조는 구조대로, 좌표는 좌표대로 적절히 부호화하여 모델이 구조 학습에 집중하면서도 세밀한 그림을 그릴 수 있게 했습니다.
좌표를 문자로 하나하나 생성할 때 흔히 발생하는 불합리한 좌표값 생성이나 좌표 순서 오류를 줄여 일관된 벡터 도형 생성이 가능해졌습니다.
둘째, 사전학습된 거대 멀티모달 지식을 활용한다는 점입니다.
OmniSVG는 거대 언어 모델이 자연어를 이해하고 생성하는 능력, 그리고 거대 비전 모델이 이미지를 인식하는 능력을 그대로 물려받아, 복잡한 그림을 그릴 때 필요한 시각적 추론과 상식을 잘 활용합니다.
예를 들어 “고양이”라는 단어의 의미나, 주어진 입력 이미지에서 추출한 스타일과 형태 정보를 풍부하게 이용해 SVG 출력을 구성할 수 있습니다. 이는 작은 모델을 처음부터 학습시켰을 때보다 훨씬 풍부한 표현력을 제공합니다.
또 하나 주목할 점은 OmniSVG가 단일한 모델로 여러 조건부 생성 작업을 모두 수행한다는 것입니다. 즉, 텍스트→SVG 생성과 이미지→SVG 생성, 캐릭터 참조 생성 등을 각각 따로 모델을 만드는 대신 하나의 모델이 멀티모달 입력을 받아 다양한 SVG 생성 작업을 다 핸들링합니다. 텍스트나 이미지를 입력으로 받는 방식을 일원화함으로써, 실제 응용에서 유연성을 얻고자 한 것입니다.
이처럼 OmniSVG는 거대 멀티모달 모델의 힘과 SVG 토크나이징 기법을 결합하여 복잡하면서도 컬러풀한 SVG를 end-to-end로 뽑아내는 혁신적 접근을 보여줍니다.
MMSVG-2M Dataset
OmniSVG의 성공을 뒷받침한 또 하나의 중요한 요소는 대규모 MMSVG-2M 데이터셋입니다. 이 데이터셋은 저자들이 새롭게 구축한 것으로, 약 2백만 개에 달하는 SVG 이미지 자산을 포함합니다.
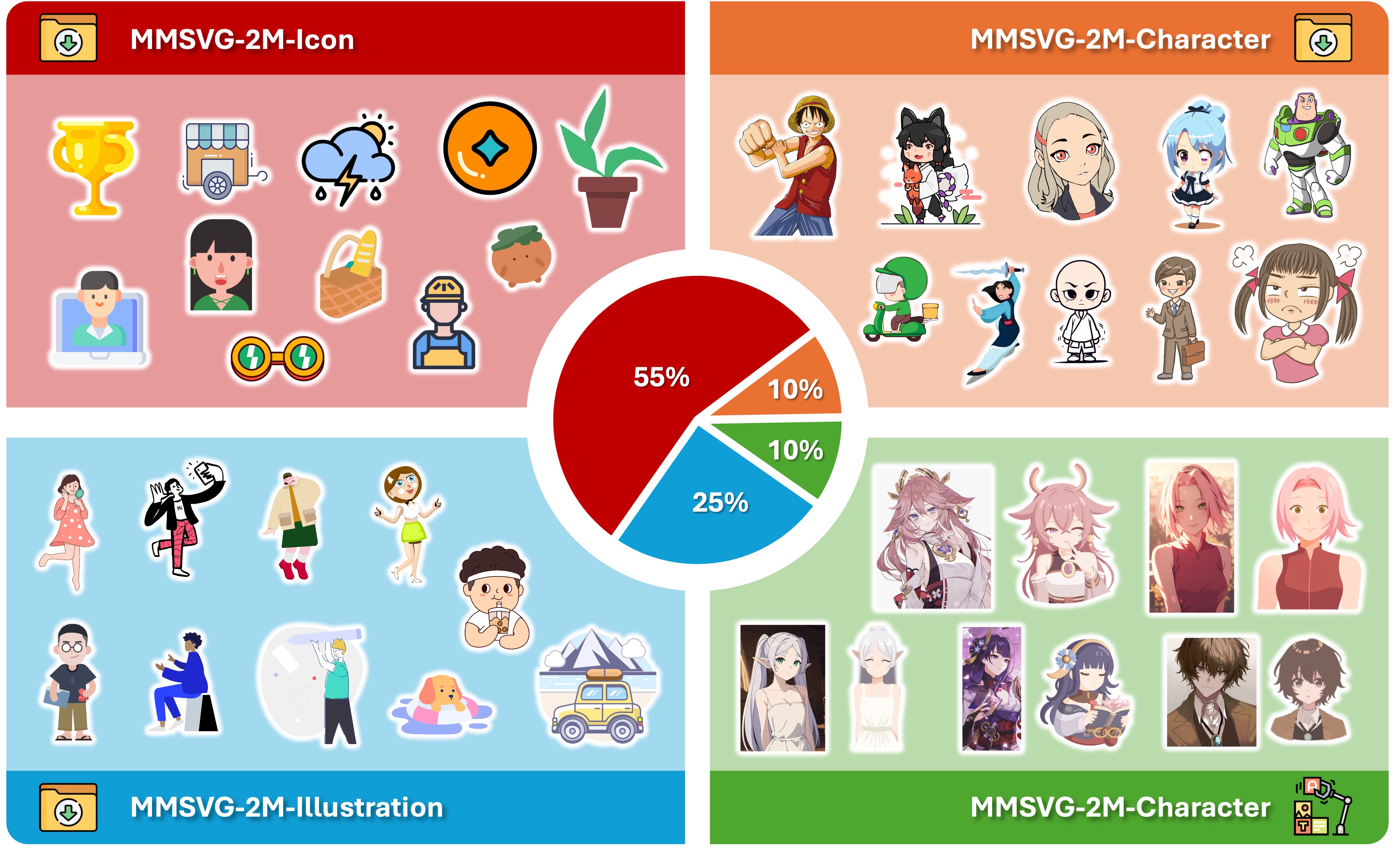
Dataset Visualization
규모 면에서도 이전의 어떤 SVG 데이터보다 크지만, 특히 주목할 점은 멀티모달 주석이 풍부하게 제공된다는 것입니다. 모든 SVG 샘플에는 해당 그래픽을 설명하는 텍스트 설명(label)과, SVG를 래스터화한 PNG 이미지가 함께 포함되어 있습니다. 즉 한 샘플당 “텍스트 설명 – 이미지 – SVG 코드” 세 가지 정보가 짝지어진 형태로, 텍스트로부터 또는 이미지로부터 SVG를 생성하는 모델 학습에 최적화된 구성입니다.
데이터셋의 콘텐츠는 크게 세 가지 부류로 나누어집니다:
Icon (아이콘): 웹/앱 아이콘처럼 비교적 단순한 도형으로 된 그래픽 약 110만 개. 주로 Iconfont 등의 아이콘 공유 사이트에서 수집되었습니다.
Illustration (일러스트): 스티커나 삽화처럼 여러 개의 도형과 색채로 구성된 중간 복잡도의 그래픽 약 50만 개. Iconscout 등에서 수집된 다양한 주제의 벡터 일러스트입니다.
Character (캐릭터 디자인): 애니메이션 캐릭터나 게임 캐릭터 등의 복잡한 인물 그래픽 약 40만 개. 이 중 일부는 Freepik 등의 사이트에서 모았고, 다른 일부는 저자들이 별도의 생성 파이프라인을 통해 만들어 낸 것입니다. 캐릭터 부분은 특히 자연스럽고 다양한 포즈의 데이터가 부족했기 때문에, FLUX라는 이미지 생성 모델에 벡터 스타일 LoRA를 적용해 새로운 캐릭터 이미지를 생성한 뒤, VTracer라는 벡터화 툴로 해당 이미지를 SVG로 변환하는 식으로 데이터 일부를 인공 생성했다고 합니다. 이렇게 해서 얻은 SVG-이미지 쌍 중 품질이 좋은 것만 엄선하여 캐릭터 데이터셋에 추가했다고 합니다 (저자가 밝힌 필터 기준으로 PSNR, SSIM 등의 유사도 지표를 활용).
Data Statistics
구체적인 데이터셋 분포를 보자면, 아이콘 110만, 일러스트 50만, 캐릭터 40만으로 총 200만이며, 각 subset마다 훈련/검증/테스트 세트를 구분해 두었습니다. 예를 들어 아이콘의 경우 약 99만개를 학습에 사용하고 10만개를 검증, 3천여개를 테스트로 사용하도록 되어 있습니다. 이렇게 대량의 데이터를 확보함으로써 모델이 단순 아이콘부터 정교한 캐릭터까지 다양한 복잡도의 SVG를 학습할 수 있었고, 드물거나 복잡한 패턴도 어느 정도 학습이 가능했습니다.
또한 저자들은 MMSVG-Bench라는 표준 평가 벤치마크를 함께 제안했습니다. 이는 위 데이터셋을 활용하여 세 가지 SVG 생성 과제에 대한 성능을 측정하는 프로토콜입니다. 세 과제란 곧 Text-to-SVG, Image-to-SVG, Character-Reference SVG 세 가지로, 각 작업마다 모델이 일정한 조건에서 SVG를 얼마나 잘 생성하는지 평가하게 됩니다.
예를 들어 Text-to-SVG의 평가에서는 주어진 텍스트 설명에 대해 모델이 생성한 SVG를 정답 SVG(데이터셋에 해당 설명으로 라벨링된 실제 SVG)와 비교합니다. Image-to-SVG는 입력 이미지를 보고 벡터화한 결과를 원본 SVG와 비교하게 되고, Character-Reference는 입력 캐릭터 이미지와 동일 캐릭터의 새 포즈 SVG를 그렸을 때 원본 캐릭터와의 유사성 등을 평가합니다.
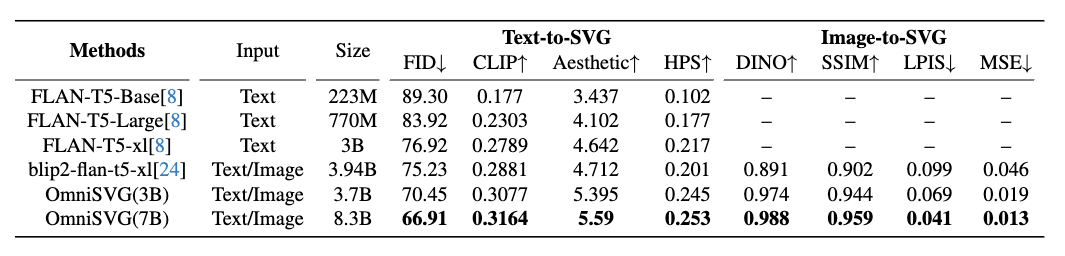
벤치마크에서는 각 작업별로 정량 지표와 정성 평가를 수행하도록 구성되어 있습니다. 정량 지표로는 예를 들어 텍스트 조건의 경우 Fréchet Inception Distance(FID)로 분포 유사도를 보거나 CLIP-score로 텍스트-이미지 내용 일치도를 측정하고, 이미지 조건의 경우 구조적 유사도(SSIM), 픽셀 MSE, LPIPS 등으로 원본 이미지와의 유사도를 측정하는 식입니다.
또한 Human Preference Score(HPS)라는 지표도 포함되는데, 이는 인간 평가자들이 여러 방법의 결과 중 어느 것이 더 나은지 투표한 선호도를 수치화한 것입니다. 이러한 체계적인 벤치마크를 통해 향후 연구들이 공정하게 성능을 비교할 수 있는 기반을 마련한 점도 MMSVG-2M의 큰 공헌입니다.
요약하면, MMSVG-2M은 다양성, 멀티모달성, 규모 면에서 전례없는 SVG 데이터 자원입니다. 간단한 아이콘부터 복잡한 캐릭터 디자인까지 아우르고, 각 샘플마다 텍스트와 이미지 주석이 붙어 있으며, 전문 디자이너 수준의 고품질 벡터 그래픽을 다량 포함하고 있습니다.
현재 아이콘과 일러스트 부분은 Hugging Face에 공개되어 있고, 캐릭터 부분도 추후 공개 예정이라고 합니다.
Feature Descriptions
OmniSVG는 하나의 모델로 다양한 SVG 생성 모드를 지원합니다. 텍스트로 SVG 생성 (Text-to-SVG), 이미지로 SVG 생성 (Image-to-SVG), 캐릭터 참조 SVG 생성 총 세 가지 사용 방법에 대해 살펴보겠습니다.
Text-to-SVG
Text-to-SVG는 말 그대로 텍스트로 묘사된 장면이나 아이디어를 모델이 읽고 그에 해당하는 벡터 이미지를 그려내는 기능입니다. 이는 일반적인 텍스트-투-이미지 생성의 SVG 버전이라고 볼 수 있습니다.
사용자는 원하는 아이콘이나 그림을 문장으로 설명하기만 하면, OmniSVG 모델이 그 내용을 해석하여 SVG 벡터 이미지로 만들어 줍니다.
“A cute cartoon character with a green and yellow mushroom hat, red capes.”라는 프롬프트만으로 초록색과 노란색 버섯 모자를 쓰고 빨간 망토를 두른 귀여운 만화 캐릭터 SVG를 생성해내는 결과를 보여주었습니다. 이렇게 얻은 SVG 그림은 해상도에 상관없이 선명하며 각 요소(모자, 망토 등)가 개별 벡터 경로로 그려져 있기 때문에 색상이나 형태를 후편집하기도 수월합니다.
Text-to-SVG 기능은 아이콘 디자인이나 일러스트 시안 작업 등에 매우 유용할 것으로 기대됩니다. 예컨대 앱 아이콘이 필요할 때 원하는 콘셉트를 문장으로 쓰면 다양한 SVG 아이콘 시안을 얻을 수 있고, 마음에 드는 결과를 골라 세부 수정을 통해 완성도를 높이는 식으로 작업 시간을 단축할 수 있습니다.
기존의 텍스트-투-이미지 생성 모델들이 픽셀 이미지를 출력했다면, OmniSVG는 처음부터 벡터로 생성하므로 포토샵이 아닌 일러스트레이터로 바로 편집 가능한 결과를 준다는 차이가 있습니다. 시각적으로 복잡한 일러스트도 OmniSVG의 Text-to-SVG를 통해 초안을 얻어 수작업을 보완할 수 있으며, 특히 선명한 노트나 간단한 스티커 스타일 그래픽 생성에 강점을 보입니다.
Image-to-SVG
Image-to-SVG는 주어진 래스터 이미지를 보고 동일하거나 유사한 그림을 벡터 형태(SVG)로 자동 변환해주는 기능입니다. 쉽게 말해, AI 벡터라이즈(vectorize) 기능으로 생각할 수 있습니다. 우리가 흔히 사용하는 사진(JPG, PNG)이나 스캔한 손그림을 입력으로 주면, OmniSVG가 그 이미지를 해석하여 비슷한 모양의 경로(path)들로 구성된 SVG 코드를 생성합니다. 결과적으로 원본 이미지를 경로와 곡선으로 표현한 벡터 도형 집합을 얻게 되는 것이죠.
이 기능은 전통적인 일러스트레이터의 이미지 트레이스(Image Trace) 기능이나 Inkscape의 비트맵 벡터라이저와 유사한 역할을 하지만, OmniSVG는 학습된 지능을 통해 더욱 유연하고 똑똑하게 벡터화를 수행한다는 점이 다릅니다. 예를 들어 단순히 경계선을 따라 트레이싱하는 것이 아니라, 이미지 속 의미있는 부분을 구분하여 각각 별도 경로로 생성한다든지, 혹은 노이즈나 그림자 등 불필요한 요소를 무시하고 본질적인 형태만 깨끗하게 벡터화하는 식입니다.
논문에서는 여러 가지 스타일의 이미지를 SVG로 변환하는 실험을 했는데, OmniSVG가 기존 벡터화 알고리즘보다 결과물이 깔끔하고 정확하며 색상이나 형태도 잘 보존함을 보여줍니다. 예컨대 러프한 손그림으로 그린 캐릭터 스케치를 주었을 때, 러프한 선을 모두 살리는 대신 캐릭터의 윤곽과 채색 영역을 파악해 부드러운 벡터 곡선으로 재구성하는 모습을 기대할 수 있습니다. 이 때문에 OmniSVG의 Image-to-SVG는 디지털 일러스트 보정이나 로고 리디자인 작업에 도움이 될 수 있습니다. 디자이너가 러프한 컨셉 아트를 그리면, 모델이 벡터 클린업을 해주는 식의 활용도 상상해볼 수 있습니다.
기존에 DiffVG나 LIVE 같은 알고리즘이 이미지→SVG 변환을 시도했지만, 최적화 기반이라 느리고 복잡한 형상에는 실패하거나 수십 초씩 걸리는 경우가 많았습니다. 반면 OmniSVG는 한 번의 모델 추론으로 결과를 얻으므로 실용적인 속도를 기대할 수 있으며, 사람처럼 이미지를 “이해하고” 변환하기 때문에 중요한 시각적 특징을 유지한 채 경로 최적화가 이뤄집니다. 이를 통해 얻은 SVG는 원본 이미지 대비 편집이 용이하고 파일 크기도 작을 수 있어, 예를 들어 로고를 고해상도로 확대 인쇄해야 하는 경우 OmniSVG로 벡터화를 해두면 품질 저하 없이 활용할 수 있을 것입니다.
캐릭터 참조 SVG 생성
OmniSVG의 독특한 응용으로 캐릭터-레퍼런스(Character-Reference) SVG 생성 기능이 있습니다. 이는 한마디로 주어진 캐릭터 이미지를 참고하여 그 캐릭터의 새로운 모습을 그려주는 것입니다. 예를 들어 여러분이 어떤 애니메이션 캐릭터 그림을 가지고 있다고 합시다. OmniSVG에 그 캐릭터의 이미지를 입력으로 주면, 모델은 해당 캐릭터의 외형적 특징(헤어스타일, 의상, 색감 등)을 인식합니다.
그리고 마치 그 캐릭터를 동일한 스타일로 다시 그린다면 어떻게 나올지 새로운 SVG 그림을 생성해줍니다. 중요한 점은 이 출력 SVG가 입력 이미지를 단순히 벡터화한 복제본이 아니라는 것입니다. OmniSVG는 입력 캐릭터의 프로필을 유지하면서도 다른 포즈나 상황의 새 그림을 그려냅니다. 마치 같은 캐릭터를 주제로 한 새로운 일러스트를 그려주는 셈이죠.
예를 들어, 입력으로 미키마우스의 정면 서 있는 그림을 주고 “이 캐릭터가 웃으며 손을 흔드는 장면을 그려줘”라고 추가 지시를 내릴 수도 있습니다. 그러면 OmniSVG는 미키마우스의 특징을 참고하면서, 손을 흔드는 포즈의 SVG 벡터 그림을 생성해줄 수 있다는 것입니다. (물론 학습 데이터에 아주 비슷한 캐릭터가 없다면 완벽히 동일하게 나오진 않겠지만, 주어진 캐릭터를 최대한 닮은 새로운 그림을 얻는 것이 목표입니다.) 논문에서는 이 기능을 평가하기 위해 입력 캐릭터 이미지와 모델 출력 SVG 간의 유사도를 인간 평가로 측정하기도 했는데, OmniSVG가 참고 이미지를 잘 반영해 캐릭터 정체성은 유지하면서도 새로운 동작을 그려내는 능력을 보였다고 합니다.
캐릭터 참조 생성은 게임 아트나 애니메이션 제작에서 특히 가치가 큽니다. 하나의 캐릭터를 다각도로 그려야 할 때, 기존 이미지를 몇 장 보여주면서 새로운 자세의 벡터 이미지를 얻어낼 수 있다면 작업량을 크게 덜 수 있을 것입니다. 디자이너가 일일이 새 포즈를 스케치하지 않고도, AI가 제시한 결과를 바탕으로 수정·보완하여 쓸 수 있기 때문입니다. 또한 이 기능은 텍스트 설명만으로는 얻기 힘든 일관된 캐릭터 시리즈를 생성할 수 있다는 점에서 일반 Text-to-SVG와 차별화됩니다. 예컨대 “녹색 옷을 입은 소년 캐릭터”를 텍스트로 여러 번 생성하면 매번 다른 소년이 나올 수 있지만, 특정 이미지 하나를 기준으로 잡고 생성하면 동일한 캐릭터가 등장하는 연속된 장면을 얻을 수 있는 것이죠.
OmniSVG의 캐릭터 참조 생성은 아직 초기 단계의 실험적 기능이지만, 그 잠재력은 매우 흥미롭습니다. 다만 입력 캐릭터의 포즈나 표정 등을 얼마나 다양하게 바꿀지는 여전히 도전적인 부분입니다. 현재는 한 장의 이미지를 참고하는 방식이지만, 향후 여러 장의 레퍼런스를 함께 주거나, 원하는 새로운 상황을 텍스트로 추가 명령하여 더 정확히 컨트롤하는 방향으로 발전시킬 수 있을 것입니다.
Analysis and Discussion
OmniSVG의 우수한 성능 뒤에는 몇 가지 핵심 설계 선택이 숨어 있습니다. 저자들은 다양한 ablation 실험을 통해 각각의 설계가 성능에 미치는 영향을 분석하였고, 이를 토대로 몇 가지 흥미로운 통찰을 얻었습니다. 주요 분석 포인트는 SVG 파라미터화 기법의 유효성, 모델 크기, VLM 아키텍처의 영향 세 가지로 정리할 수 있습니다.
첫째, SVG 파라미터화(Tokenization)의 효과입니다. OmniSVG가 좌표와 색상을 토큰화한 것이 실제로 얼마나 도움이 되었는지를 검증하기 위해, 좌표/색상 파라미터화를 적용하지 않은 모델과의 비교가 이루어졌습니다.
좌표 파라미터화를 끄면 모델은 좌표 숫자를 일련의 개별 숫자 토큰으로 출력해야 했고, 색상 파라미터화를 끄면 SVG에 채색을 하지 못하거나 한 가지 색만 쓰게 설정했습니다.
그 결과 파라미터화를 사용하지 않은 경우 출력 SVG의 품질이 크게 저하되었습니다. 예컨대 색상 토큰이 없으면 생성된 아이콘들이 전부 단색 실루엣이 되어버렸고, 좌표를 직접 출력시키면 많은 경우 도형이 어긋나거나 엉성한 그림이 나왔습니다. 반대로 풀 파라미터화 설정에서는 선명한 색상이 채워지고 복잡한 곡선도 정확히 이어져 그려졌습니다.
아래 그림은 한 프롬프트에 대해 (a) 좌표·색상 파라미터화 모두 켠 경우, (b) 좌표 파라미터화만 끈 경우, (c) 색상 파라미터화만 끈 경우, (d) 둘 다 끈 경우의 출력을 비교한 것입니다.
이를 통해 좌표와 색상 정보를 통합 토큰으로 다루는 현재 설계가 모델의 복잡한 형상 표현 능력을 비약적으로 향상시킴을 알 수 있습니다. 특히 저자들은 좌표를 숫자 나열로 처리하면 동일 (123,456) 좌표를 나타내는 데 토큰 6개가 필요한데, 파라미터화하면 토큰 2개로 충분하므로 시퀀스 길이가 크게 단축되고 그만큼 모델이 장기 의존성을 관리하기 수월해진다고 설명합니다. 또한 좌표를 한 번에 하나씩 생성하면 누적 오차가 발생하거나 엉뚱한 좌표(예: 화면 밖 좌표)가 나올 위험이 있는데, OmniSVG는 이를 효과적으로 억제했습니다. 요컨대, SVG 토큰화 전략이 OmniSVG 성능의 기반임이 실험적으로 검증된 것입니다.
둘째, 모델 크기(용량)에 대한 고찰입니다. OmniSVG는 거대 모델일수록 복잡한 SVG 생성에 유리할 것으로 예상되므로, 30억과 70억 규모 모델을 비교했습니다. 결과는 예상대로 더 큰 모델이 전반적인 지표 향상을 가져왔습니다.
특히 텍스트→SVG 생성에서 복잡한 장면(캐릭터 등)을 그릴 때 큰 모델이 작은 모델보다 디테일 표현이 우수했고, 이미지→SVG에서도 작은 모델은 일부 세부를 놓치는 경우가 있었지만 큰 모델은 거의 원본과 차이를 느끼기 어려울 정도로 정확했습니다. 이는 대용량 모델일수록 더 많은 매개변수를 사용해 SVG의 복잡한 패턴을 학습하고 기억할 수 있기 때문입니다. 한편, 작은 OmniSVG-3B 모델로도 아이콘이나 간단한 일러스트 정도는 제법 그럴듯하게 생성했기에, 만약 실시간성이 중요하거나 경량화가 필요한 경우 추후 3억~10억대의 경량 모델로 distillation(지식 증류)하거나, LoRA 등을 이용한 작은 전용 모델로의 특화도 고려해볼 수 있을 것입니다. 그러나 이번 논문의 초점은 최고 품질을 내는 것이었기에, 최종 결과는 모두 OmniSVG-7B 기준으로 보고되었습니다. 향후에는 모델 경량화 역시 한 연구 방향이 될 수 있겠습니다.
셋째, VLM 아키텍처의 효과입니다. OmniSVG는 비전-언어 통합 구조 덕분에 텍스트+이미지 복합 입력도 자연스럽게 처리할 수 있었고, 이는 Character-Reference 생성 등에서 유용했습니다. 만약 이미지 인코더와 텍스트 LLM을 별도로 두고 결합했다면 이렇게 긴 시퀀스를 공동으로 생성하기 어려웠을 것입니다.
저자들은 대조 실험으로, 이미지→SVG 작업을 할 때 텍스트 설명 없이 이미지 만으로도 충분한지 살펴보았는데, OmniSVG의 멀티모달 모델은 이미지 입력만으로도 높은 품질 SVG를 그렸다고 합니다 (사실 대부분의 Image-to-SVG 데이터에는 텍스트 라벨도 있었지만, 굳이 사용하지 않아도 성능이 잘 나왔다는 의미입니다). 이는 시각 정보만으로도 의미 파악을 할 수 있는 VLM 구조의 강점을 보여줍니다.
반대로, LLM4SVG같이 텍스트만으로 SVG를 생성하는 구조의 한계도 지적되는데요, 해당 모델은 복잡한 SVG의 좌표 시퀀스를 제대로 생성하지 못해 2048 토큰 제한에 걸리거나 좌표 실수가 잦았다고 합니다. OmniSVG는 거기에 이미지 이해 능력까지 통합함으로써 보다 강인한 생성기가 되었습니다.
또한 Qwen-VL같이 대용량 멀티모달 모델은 사전학습 동안 이미지와 텍스트의 연관성을 충분히 학습했기 때문에, 소량의 SVG 데이터로도 효과적으로 fine-tuning이 가능했습니다. 이는 사전학습된 VLM을 활용하는 것이 효율적이라는 교훈을 줍니다. 향후 더 뛰어난 VLM (예: GPT-4V 같은)으로 OmniSVG 방식을 적용한다면 성능이 더욱 올라갈 여지도 있을 것입니다.
Conclusion
OmniSVG는 복잡한 벡터 그래픽 생성이라는 어려운 문제에 대해 새로운 해결책을 제시했습니다. 텍스트 또는 이미지를 조건으로 받아, 사람이 직접 그린 것 같은 고품질 SVG 이미지를 자동으로 만들어내는 이 모델은 디자인 분야의 생산성 혁신 가능성을 엿보게 합니다.
논문에서 강조하듯, OmniSVG는 멀티모달 거대 모델과 SVG 파라미터화 기법의 결합으로 기존 방법들의 한계를 뛰어넘었으며, 방대한 MMSVG-2M 데이터셋의 공개를 통해 후속 연구의 토대를 마련했습니다. 물론 몇 가지 제한과 개선 과제가 남아 있지만, OmniSVG의 성취는 향후 AI 기반 그래픽 도구의 발전 방향을 잘 보여줍니다.
현재 OmniSVG의 모델이 아직 공개되지 않아 테스트를 할 수 없습니다. 추후 공개되고 유의미한 결과가 있다면 실험에 대해 공유해 보겠습니다.
Scalable Vector Graphics (SVG) have become a core format in modern digital design thanks to their ability to maintain quality regardless of resolution and ease of editing. Widely used across UI/UX design to CAD, SVG precisely defines vector shapes such as Bézier curves and polygons, offering crisp graphics at any resolution.
Pikachu
Mario
PUBG
However, creating high-quality SVG content remains a challenging task for non-experts, as it requires learning how to use specialized tools or grappling with the complexity of XML code, posing a high barrier to entry.
Previous attempts to automatically generate SVGs have explored optimization-based methods and auto-regressive approaches. Optimization-based techniques use a differentiable vector graphics renderer to iteratively match a desired image. While effective for simple graphics like icons, they are computationally expensive for complex SVGs and often result in SVG paths that are structurally unorganized with excessive unnecessary points or line segments.
On the other hand, the auto-regressive approach uses models such as transformers or large language models (LLMs) to directly generate the XML code or command sequence of an SVG. This method is promising in terms of scalability because it allows end-to-end learning from large amounts of SVG data. However, so far it has been mostly limited to generating simple and near-monochrome icons due to the context length limits and the lack of complex SVG data. In other words, as coordinate or path information grows longer, it becomes difficult for LLMs to handle, and the training data tends to be less complex.
To overcome these limitations and aim for high-quality, high-complexity SVG graphic generation, OmniSVG was proposed.
OmniSVG Generation Process
OmniSVG is an integrated SVG generation framework based on text and image conditions that leverages a pre-trained vision-language model (VLM) to generate complex color vector graphics in an end-to-end manner. The key idea is to parameterize SVG shape commands and coordinates as discrete tokens, thereby separating the logical structure (what shape to draw) from low-level geometric details (exact coordinate values).
This approach reduces the issue of “coordinate hallucination” (generating unrealistic or inconsistent coordinates) seen when models generate coordinate values character by character, and it enables the efficient learning of complex structures.
Furthermore, to train OmniSVG, a large-scale SVG dataset called MMSVG-2M consisting of 2 million SVG data points has been introduced, along with a standard evaluation protocol for text/image-conditional SVG generation.
Comprehensive experiments have shown that OmniSVG outperforms previous methods and demonstrates the potential to be integrated into professional design workflows.
In this post, we will summarize the key points of the OmniSVG paper.
Key Ideas
OmniSVG Demo
At its core, OmniSVG treats SVG as if it were text. As mentioned earlier, all the components of an SVG (path commands and coordinate values) are converted into a pre-defined discrete token sequence.
For example, an SVG path command like <path d="M10 10 L100 100 Z" /> is tokenized into a sequence such as [M, 10, 10, L, 100, 100, Z].
Draw Commands
OmniSVG simplifies SVG by using only the five basic path commands used for drawing—MoveTo (M), LineTo (L), Cubic Bézier Curve (C), Elliptical Arc (A), and ClosePath (Z)—and removes unnecessary attributes. To represent the fill information of shapes, a separate Fill (F) token is introduced. Instead of listing coordinate values as individual number tokens, each coordinate is treated as a single token by quantizing the range.
Using this SVG tokenizer, long lists of coordinates can be replaced by a single short token, dramatically reducing the sequence length and allowing even complex shapes to be represented within 30k tokens. This is a significant design improvement, addressing the issue where existing LLM-based methods were limited to 2048 tokens and thus could not handle complex SVGs.
Architecture
The OmniSVG model generates these tokenized SVG sequences via a large VLM (Vision-Language Model). Specifically, it builds on Alibaba’s Qwen-VL model structure, a multimodal transformer capable of processing both text and images simultaneously. To enable SVG token output for SVG generation, OmniSVG is trained to predict the SVG token sequence using the pre-defined SVG tokenizer. During training, the model receives text descriptions and, if required, an image as input, and it outputs the corresponding token sequence of an SVG that meets the given conditions.
In summary, OmniSVG is a massive sequence generation model that goes from “prompt → SVG token sequence.” The prompt can be text alone, an image, or both. The multimodal input is inserted as a Prefix Token of the Qwen-VL model, and then the model predicts the subsequent SVG tokens one step at a time until a complete SVG is generated.
This approach has two major advantages:
First, the separation of structure and geometry. The complex hierarchical structure or drawing order in SVGs represents the logical organization to be learned, while the coordinate values and fine color details represent geometric specifics. OmniSVG encodes these separately, allowing the model to focus on learning the structure while drawing detailed images. Generating coordinate values character-by-character often leads to unreasonable coordinate values or ordering errors. By contrast, this method facilitates consistent vector shape generation.
OmniSVG inherits the ability of large language models to understand and generate natural language, as well as the ability of large vision models to recognize images. It effectively uses the visual reasoning and common sense needed to draw complex images. For example, it can richly incorporate the meaning of the word “cat” or exploit the style and shape information extracted from an input image to construct the SVG output. This provides a much richer expressive power compared to training a smaller model from scratch.
Another notable point is that OmniSVG performs various conditional generation tasks with a single model. Instead of designing separate models for text-to-SVG, image-to-SVG, or character-reference SVG generation, one model handles all these tasks from multimodal inputs. This unification of text and image inputs provides increased flexibility in real-world applications.
In this way, OmniSVG demonstrates an innovative approach that combines the power of a massive multimodal model with an SVG tokenization technique to produce complex and colorful SVGs in an end-to-end manner.
MMSVG-2M Dataset
Another key factor behind OmniSVG’s success is the large-scale MMSVG-2M dataset. Built by the authors, this dataset contains nearly 2 million SVG image assets.
Dataset Visualization
In terms of scale, it is larger than any previous SVG dataset, but what is especially noteworthy is that it includes rich multimodal annotations. Every SVG sample is paired with a text description (label) that explains the graphic and a corresponding PNG image obtained by rasterizing the SVG. In other words, each sample consists of “text description – image – SVG code”, making it optimally configured for training models that generate SVGs from text or image inputs.
The dataset’s content is divided into three main categories:
Icon: Approximately 1.1 million graphics composed of relatively simple shapes similar to web/app icons, mostly collected from icon-sharing sites like Iconfont.
Illustration: Around 500,000 medium-complexity graphics composed of multiple shapes and colors, such as stickers or illustrations, collected from diverse vector illustrations on sites like Iconscout.
Character (Character Design): About 400,000 complex character graphics including animated or game characters. Some of these were collected from sites like Freepik, while others were generated via a separate creation pipeline developed by the authors. Because there was a noticeable lack of varied data for natural and diverse poses in characters, the authors applied vector-style LoRA to an image generation model called FLUX to create new character images. These images were then converted into SVGs using a vectorization tool named VTracer. Only those SVG–image pairs with high quality (selected based on filters such as PSNR and SSIM similarity metrics, as specified by the authors) were included in the character dataset.
Data Statistics
Specifically, the distribution in the dataset is 1.1 million icons, 500,000 illustrations, and 400,000 characters, totaling 2 million. Each subset is further split into training/validation/test sets. For example, in the case of icons, about 990,000 samples are used for training, 100,000 for validation, and roughly 3,000 for testing. By securing such a large volume of data, the model is able to learn SVGs ranging from simple icons to intricate character designs, and even learn rare or complex patterns to some extent.
The authors also proposed a standard evaluation benchmark called MMSVG-Bench. This protocol evaluates three SVG generation tasks using the dataset: Text-to-SVG, Image-to-SVG, and Character-Reference SVG. For each task, the model’s ability to generate SVGs under certain conditions is evaluated.
For instance, in the Text-to-SVG evaluation, the SVG generated by the model based on a given text description is compared with a ground truth SVG (the actual SVG paired with that description in the dataset). Image-to-SVG evaluates how well the SVG generated from an input image (i.e., the vectorized result) matches the original SVG, while Character-Reference measures the similarity between the input character image and the new pose SVG generated.
The benchmark involves both quantitative metrics and qualitative evaluations for each task. Quantitative metrics include, for example, Fréchet Inception Distance (FID) to assess distribution similarity or CLIP-score for text-image consistency in text-conditioned tasks, and Structural Similarity Index (SSIM), pixel MSE, LPIPS, etc., for image-conditioned tasks. There is also a Human Preference Score (HPS), which quantifies which results human evaluators prefer among various methods. This systematic benchmark lays a foundation for fair comparisons in future research, marking a significant contribution of MMSVG-2M.
In summary, MMSVG-2M is an unprecedented SVG data resource in terms of diversity, multimodality, and scale. It spans from simple icons to complex character designs; each sample comes with text and image annotations, and includes a vast collection of high-quality vector graphics at a professional design level.
Currently, the icon and illustration portions are publicly available on Hugging Face, and the character portion is expected to be released later.
Feature Descriptions
OmniSVG supports various SVG generation modes with a single model. Let’s review the three primary usage modes: Text-to-SVG, Image-to-SVG, and Character-Reference SVG.
Text-to-SVG
Text-to-SVG literally refers to the model reading a scene or idea described in text and then drawing the corresponding vector image. This can be seen as the SVG version of a typical text-to-image generation.
The user simply describes the desired icon or drawing in a sentence, and the OmniSVG model interprets it and produces an SVG vector image.
It demonstrated a result where a prompt such as “A cute cartoon character with a green and yellow mushroom hat, red capes.” generated an SVG of a cute cartoon character wearing a green and yellow mushroom hat with a red cape. The resulting SVG remains crisp regardless of resolution, and each element (hat, cape, etc.) is rendered as a separate vector path, making post-editing of colors or shapes straightforward.
The Text-to-SVG feature is expected to be very useful for icon design or illustration drafts. For example, when an app icon is needed, one can simply write a sentence describing the concept to obtain various SVG icon drafts and then choose the preferred result to further refine the details. Unlike traditional text-to-image models that output pixel images, OmniSVG produces vector graphics from the start, meaning you get results that are directly editable in Illustrator rather than Photoshop. Even for visually complex illustrations, OmniSVG’s Text-to-SVG can be used to generate an initial draft that can be augmented manually, and it is especially strong at generating crisp notes or simple sticker-style graphics.
Image-to-SVG
Image-to-SVG converts a given raster image into an equivalent or similar drawing in vector format (SVG). In simple terms, it can be thought of as an AI vectorization feature. When you input a photo (JPG, PNG) or a scanned hand drawing, OmniSVG interprets the image and generates an SVG code composed of paths that mimic the shapes. The end result is a set of vector shapes created from the original image’s paths and curves.
This function is similar to traditional tools like Adobe Illustrator’s Image Trace or Inkscape’s bitmap vectorizer. However, OmniSVG performs vectorization in a more flexible and intelligent manner through learned knowledge. Instead of merely tracing along the edges, it distinguishes the meaningful parts of the image and generates separate paths for each, or it ignores unnecessary elements such as noise or shadows to vectorize only the essential shapes.
The paper demonstrates experiments converting various styles of images into SVG, showing that OmniSVG produces results that are cleaner and more accurate than conventional vectorization algorithms, preserving both color and shape effectively. For example, when given a rough hand-drawn character sketch, instead of simply preserving all the rough lines, the model is able to identify the character’s contours and fill areas, reconstructing them as smooth vector curves. This makes OmniSVG’s Image-to-SVG feature useful for digital illustration refinement or logo redesign. Imagine a designer who sketches a rough concept; the model could clean up the vector paths, saving significant time.
Previous algorithms like DiffVG or LIVE attempted image-to-SVG conversion based on optimization, but they were slow or failed with complex shapes, often taking tens of seconds. In contrast, OmniSVG produces results with a single model inference, offering practical speed and, by “understanding” the image similarly to a human, performs path optimization while preserving critical visual features. The resulting SVGs are not only easier to edit but also smaller in file size, making them ideal for scenarios such as high-resolution logo printing without quality loss.
Character-Reference SVG Generation
A unique application of OmniSVG is the Character-Reference SVG Generation feature. In short, this function takes an input character image and generates a new appearance for that character. For example, if you have a drawing of an animated character, you can input the character’s image into OmniSVG. The model recognizes the character’s visual features (hairstyle, costume, colors, etc.)
and then produces a new SVG vector drawing of the character in a different pose, as if it were redrawn in the same style. It is important to note that the output SVG is not a mere vectorized replica of the input image. Instead, OmniSVG generates a new illustration that resembles the provided character while introducing a different pose or context.
For instance, you might provide an image of Mickey Mouse standing frontally and add the instruction “draw a scene where this character is smiling and waving.” The model will then generate an SVG vector drawing of Mickey Mouse in a waving pose while still retaining his defining characteristics. (Of course, if there is no similar character in the training data, the output may not be identical, but the goal is to produce a new drawing that most closely resembles the given character.) The paper even includes human evaluation on the similarity between the input character image and the generated SVG, demonstrating that OmniSVG effectively maintains character identity while rendering new actions.
The character-reference generation feature is especially valuable in game art or animation production. When there is a need to draw a character from multiple angles, if one can provide a few images as references to obtain new pose vector images, the workload can be significantly reduced. Instead of having the designer manually sketch every new pose, they can tweak the AI-generated results. Moreover, this feature differentiates itself from ordinary text-to-SVG as it can produce a consistent series of character illustrations. For example, generating a “boy in green clothes” solely by text might result in different characters each time. However, using a specific reference image allows the creation of a sequence of scenes featuring the same character.
While the character-reference generation feature is still in its experimental stage, its potential is very exciting. There remain challenges in how diversely the input character’s poses and expressions can be varied. Currently, it relies on a single image as reference, but in the future, improvements may include providing multiple reference images or additional textual instructions to more precisely control the output.
Analysis and Discussion
Behind the excellent performance of OmniSVG lie several key design choices. The authors conducted various ablation experiments to analyze the impact of each design choice on performance, yielding several interesting insights. The main analysis points can be summarized into three aspects: the effectiveness of SVG parameterization techniques, model size, and the impact of the VLM architecture.
First, the effect of SVG parameterization (tokenization). To verify how much tokenizing coordinates and colors helped, the authors compared the model with one where coordinate/color parameterization was not applied.
Without coordinate parameterization, the model had to output coordinate numbers as a series of individual tokens; without color parameterization, it was forced to either not color or use only a single color in the SVG. The results showed that the output SVG quality degraded dramatically without parameterization. For example, when the color token was removed, the generated icons turned into monochrome silhouettes, and when coordinates were output directly, shapes were often misaligned or poorly drawn. In contrast, with full parameterization enabled, the shapes were filled with vivid colors and complex curves were rendered accurately.
The image below compares the outputs for one prompt under (a) both coordinate and color parameterization enabled, (b) coordinate parameterization disabled, (c) color parameterization disabled, and (d) both disabled.
This experiment shows that treating coordinate and color information as integrated tokens has dramatically enhanced the model’s ability to represent complex shapes. The authors point out that if coordinates were treated as a sequence of individual number tokens, representing the same coordinate (e.g., (123,456)) would require six tokens, whereas parameterization can represent it with only two tokens. This greatly reduces the sequence length, making it easier for the model to manage long-term dependencies. Moreover, generating coordinates one by one can lead to cumulative errors or the risk of generating off-screen coordinates, which OmniSVG effectively suppresses. In short, the SVG tokenization strategy is the foundation of OmniSVG’s performance, as verified by the experiments.
Second, the discussion on model size (capacity). OmniSVG was expected to benefit from larger models in generating complex SVGs, so models with 3B and 7B parameters were compared. As anticipated, the larger model demonstrated overall improvements across various metrics.
In particular, for text-to-SVG generation of complex scenes (such as characters), the larger model rendered details much better than the smaller model. In Image-to-SVG tasks, while the smaller model occasionally missed some details, the larger model’s output was almost indistinguishable from the original. This is because larger models can learn and remember the complex patterns inherent in SVGs with a greater number of parameters. On the other hand, the smaller OmniSVG-3B model produced pretty good results for icons or simple illustrations. Therefore, if real-time performance or lighter models are needed, it might be possible in the future to distill a smaller model (in the 300M~1B range) using distillation or techniques like LoRA for specialized tasks. However, the focus of this paper was on achieving the highest quality, so all final results are reported with OmniSVG-7B. Model compression remains an interesting direction for future research.
Third, the effect of the VLM architecture. Thanks to its integrated vision-language structure, OmniSVG naturally handles combined text+image inputs, which is particularly beneficial for Character-Reference generation. If separate image encoders and text LLMs had been used and later combined, generating such long sequences jointly would have been very difficult.
In a comparative experiment for image-to-SVG tasks, the authors explored whether using only the image (without text descriptions) was sufficient. It turned out that the OmniSVG multimodal model generated high-quality SVGs even when only the image was used as input (noting that most Image-to-SVG data also had accompanying text labels, the model performed well even when they were omitted). This demonstrates the strength of the VLM structure in understanding semantics from visual information alone.
In contrast, models such as LLM4SVG, which generate SVGs from text only, failed to properly generate long coordinate sequences for complex SVGs—hitting a 2048-token limit or making frequent coordinate errors. By integrating image understanding, OmniSVG becomes a more robust generator.
Moreover, a large-scale multimodal model like Qwen-VL has learned the associations between image and text during pre-training, making it possible to effectively fine-tune on a relatively small amount of SVG data. This underscores the efficiency of leveraging a pre-trained VLM. In the future, applying the OmniSVG approach with even more advanced VLMs (e.g., GPT-4V) could further boost performance.
Conclusion
OmniSVG offers a novel solution to the challenging problem of generating complex vector graphics. By taking text or image inputs and automatically producing high-quality SVG images that look hand-drawn, this model hints at a potential productivity revolution in the design field.
As emphasized in the paper, OmniSVG overcomes the limitations of existing methods by combining a massive multimodal model with an SVG parameterization strategy, and it lays a foundation for subsequent research by releasing the expansive MMSVG-2M dataset. Although there remain some limitations and areas for improvement, the achievements of OmniSVG clearly indicate the future direction for AI-based graphic tools.
Currently, the OmniSVG model has not been released for testing. Once it is made public and meaningful results are available, further experiments will be shared.












Leave a comment