
[논문리뷰] RandAugment
RandAugment: Practical automated data augmentation with a reduced search space
Ekin D. Cubuk ∗ , Barret Zoph∗ , Jonathon Shlens, Quoc V. Le Google Research, Brain Team
이번 포스팅에서는 google brain에서 2019년 10월에 발표한 RandAugment라는 논문에 대해 알아보려고 한다. 이 논문의 중점은 기존의 Auto Augmentation의 search space보다 훨씬 낮은 space로 비슷한 성능을 낼 수 있다는 것이다.
What is RandAugment?
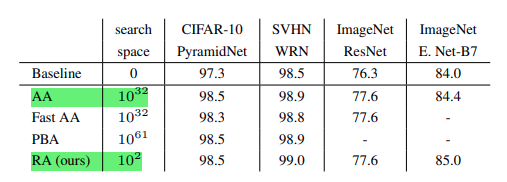
- data augmentation은 딥러닝 모델을 일반화시키는데에 도음을 주는 중요한 작업이다. 하지만 data augmentation은 그냥 적용한다고 좋은것이 아니라 도메인에 대한 prior knowledge가 필요하기 때문에 이에따른 cost(time, money)가 요구된다.
- 이런 문제 때문에 NAS가 최적의 neural network architecture를 찾는 것 처럼 data augmentation에서도 최적의 policy를 찾으려고 여러가지 시도가 있었다.(Auto Augment, Fast Auto Augment 등)
- 하지만 이러한 방식들은 최적화 절차가 복잡하고 계산이 많이 필요해서 현실적으로 적용하기에는 무리가 있었고 이에대해 저자들은 데이터셋과 모델의 크기에 따라 augmentation의 최적 기점이 달라진다는 것을 확인하였다.
- 그래서 오직 두개의 parameter(N, M)의 grid search 방법만으로 search space를 줄이면서 충분이 좋은 성능을 내는 RandAugment를 제시하였다.
How work RandAugment?

- RandAugment는 위 코드에서 볼 수 있듯이 단 두개의 파라미터와 두줄의 코드만으로 적용이 가능하다.
- 논문에서는 14개의 augmentation을 사용하였고 파라미터 N은 적용할 augmentation개수, M은 적용할 augmentation의 magnitude(변환정도)를 의미한다.
- 각 기법마다 최소 최대 변환값을 정해놓고 magnitude를 통해 N개의 augmentation 기법들이 모두 같은 정도의 변환이 일어나게 한다.
- 왼쪽 그림은 N은 2이고 M은 한줄씩 9, 17, 28을 적용한 RandAugment 예시이다. (아래로 갈수록 변환이 커진다.)
- 참고로 논문에서 14개가 아닌 더 많은 augmentation을 추가하면 성능이 더 좋아진다고 말한다.
Experiment
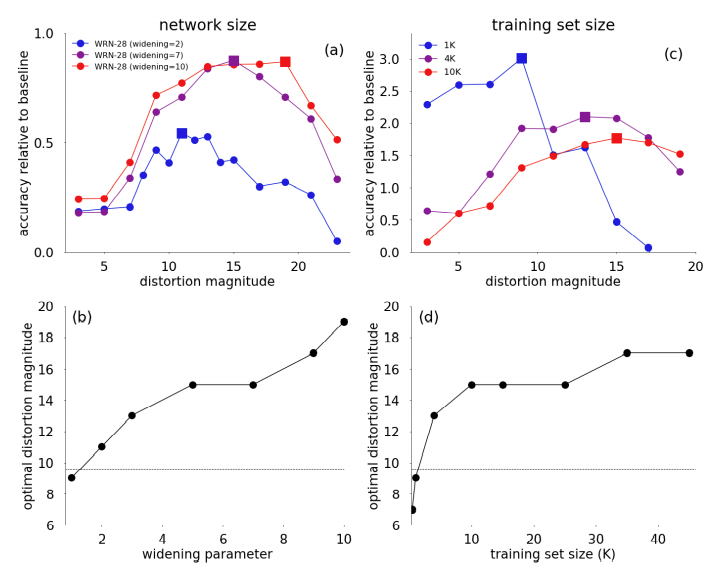
- 이 논문에서 주장하는것은 모델과 데이터셋의 크기에 따라 augmentation의 적용시의 효과가 다르다는 것이다.
- 모델 사이즈가 클수록 augmentation 적용시 큰 magnitude와 함께 더 좋은 보상을 얻음 [그래프 (a)]
- dataset의 크기가 작을수록 augmentation 적용시 큰 magnitude를 적용하면 보상이 적어짐 [그래프 (c)].
- 결국 모델과 데이터셋이 클수록 magnitude를 크게 설정해야 RandAugment의 효과를 볼 수있다.
PyTorch Implement
학습코드에 앞서서 먼저 RandAugment의 작동 방식을 시각화 해 보았다.
def augment_list():
l = [
(AutoContrast, 0, 1),
(Equalize, 0, 1),
(Invert, 0, 1),
(Rotate, 0, 30),
(Posterize, 0, 4),
(Solarize, 0, 256),
(SolarizeAdd, 0, 110),
(Color, 0.1, 1.9),
(Contrast, 0.1, 1.9),
(Brightness, 0.1, 1.9),
(Sharpness, 0.1, 1.9),
(ShearX, 0., 0.3),
(ShearY, 0., 0.3),
(CutoutAbs, 0, 40),
(TranslateXabs, 0., 100),
(TranslateYabs, 0., 100),
]
return l
class RandAugment:
def __init__(self, n, m):
self.n = n
self.m = m # [0, 30]
self.augment_list = augment_list()
def __call__(self, img):
ops = random.choices(self.augment_list, k=self.n)
org_img = img.copy()
for op, minval, maxval in ops:
val = (float(self.m) / 30) * float(maxval - minval) + minval
img_list.append(op(org_img, val))
fn_names.append(str(op).split(' ')[1])
img = op(img, val)
return img
if __name__ == '__main__':
import matplotlib.pyplot as plt
def visualize(images, names):
fig = plt.figure(figsize=(10, 10))
for i, (img, name) in enumerate(zip(images, names)):
fig.add_subplot(3, 3, i+1)
plt.imshow(img)
plt.title(name)
plt.show()
path = '../dogs/Golden retriever/n158409.jpeg'
image = Image.open(path).convert('RGB')
img_list = [image]
fn_names = ['Original']
ra = RandAugment(3,2)
transform_img = ra(image)
img_list.append(transform_img)
fn_names.append('All')
visualize(img_list, fn_names)

위 결과는 N=3 M=2로 했을때의 변환결과이다. 14개의 augmentation 중에 Equalize, SolarizeAdd, ShearY가 선택되었고 All은 이 세가지 변환결과가 순서대로 중첩된 결과이고 실제로 All 이미지가 모델의 input으로 사용된다.
PyTorch로 RandAugment가 구현된 모듈이 2개정도 있는데 하나는 논문과 같이 N과 M을 하이퍼 파라미터로 설정을 해야하고 나머지 모듈은 N과M 마저 랜덤하게 선택된다.
성능 비교를 ResNet18로 CIFAR10데이터 셋에서 진행하였다. N과 M을 직접 설정하는 1번모듈을 사용해서 파라미터를 몇번 바꿔가면서 실험해 보았는데 논문의 환경과 많이 다르기 때문에 accuracy가 오히려 떨어지는 상황이 벌어졌다. 그래서 2번모듈을 사용해 N과 M마저 랜덤한 값을 주었다. 2번 모듈은 아래 코드와 같이 간단하게 적용할 수 있다.
!pip install randaugment # module install
from randaugment import RandAugment # import module
train_transform = transforms.Compose(
[
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
RandAugment(), # Rand Augmentation
transforms.ToTensor(),
]
)
[학습결과]
| accuracy | training time(1 epoch) | |
|---|---|---|
| Base(mixup + label smoothing) | 95.17% | 15 second |
| Base + RandAugment | 96.16% | 34 second |
- 논문에서 사용한 14가지 Augmentation에 cutout, mixup을 추가 하였고 label smoothing기법으로 regularization을 하였다.
- 실험결과 Base보다 약 1%의 accuracy가 상승하였고 training time은 약 두배정도 늘어난 것을 확인하였다.
End
이번 포스팅에서는 RandAugment에 대해 간단히 알아보고 실제로 실험을 해 보았다. 성능을 높이는 대회에서 적용을 해보면 좋을 것 같고 그때는 더 많은 augmentation을 추가해서 RandAugment를 활용해 볼 것이다.
Reference
- Paper : https://arxiv.org/abs/1909.13719
- train code : https://github.com/visionhong/Vision/tree/master/Basics/rand_augment
- RandAugment code : https://github.com/jizongFox/pytorch-randaugment
Leave a comment