
[논문리뷰] SSD : Single Shot Multibox Detector
SSD : Single Shot Multibox Detector는 2016년 ECCV(European Conference on Computer Vision) 학회에서 발표되었다. 이름에서부터 알 수 있듯이 Object Detection 논문이며 당시 SOTA였던 Faster_RCNN 과 YOLO v1의 단점들을 보완하면서 화제가 된 논문이다.
1. Introduction
Faster_RCNN 과 YOLO v1은 다음과 같은 단점들을 가지고 있었다.
Faster_RCNN 단점 : 이름은 Faster이지만 그에 걸맞지 않게 연산량이 많고 너무 느리다. (only 7 FPS with mAP 73.2%)
YOLO v1 단점 : 다른 Object Detector에 비해 빠르지만 accuracy가 낮다. (45 FPS with mAP 63.4%)
그래서 저자들은 이 두 모델의 단점을 보완을 하는 1-stage detector인 SSD를 제시하였고 최종적으로 VOC2007 test 데이터에 대해서 59 FPS with mAP 74.3% 이라는 성능을 내었다.
2. Model
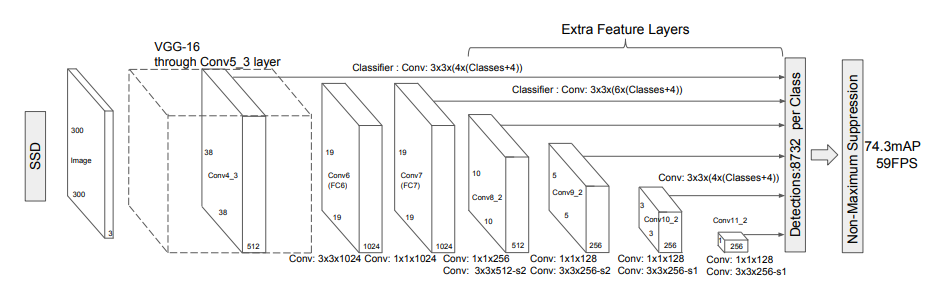
SSD의 모델의 가장 큰 특징은 레이어 끝단에서 Bounding box와 class를 예측하는 것이 아니라 중간중간 6개의 Feature map에서 Bounding box와 class를 예측을 하여 최종적으로 8732개의 bounding box와 class별 예측을 하게 된다. YOLO v1 에서는 98개를 예측을 하는데 거의 100배 가까이 차이가 나는 것을 알 수 있다.
그런데 왜 이렇게 box를 여러 feature_map에서 뽑으려고 하는 것일까?

위의 그림에서 알 수 있듯이 feature_map이 클수록 작은 물체를 잘 찾고 feature_map이 작아질수록 좀 더 큰 물체를 잘 찾게 된다. 왜냐하면 feature_map이 작아진다는 것은 개념적으로 특징이 같이 작아짐으로서 같은 비율의 박스가 있을때 feature_map이 축소되면서 물체(특징)가 박스 안으로 들어오기 때문이다.
이제 모델 구조를 앞쪽부터 천천히 살펴보자.
SSD는 입력 이미지로 300 x 300 의 resolution을 사용하며(SSD300인 이유) Base network으로 시작이 된다. Base network는 VGG16을 사용하였는데 모든 레이어를 그대로 가져온 것이 아니라 기존의 FC6와 FC7 레이어를 사용하는 대신 convolution으로 대체하면서 채널수를 줄이는 선택을 하였다.
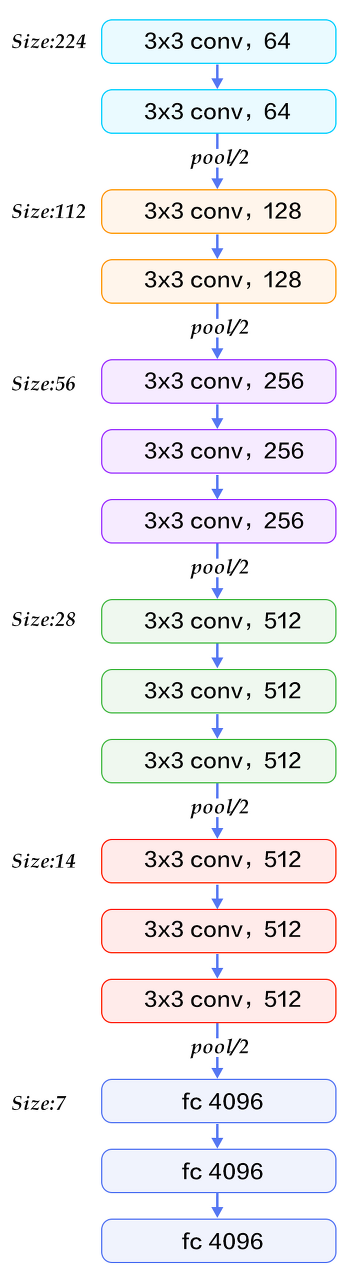
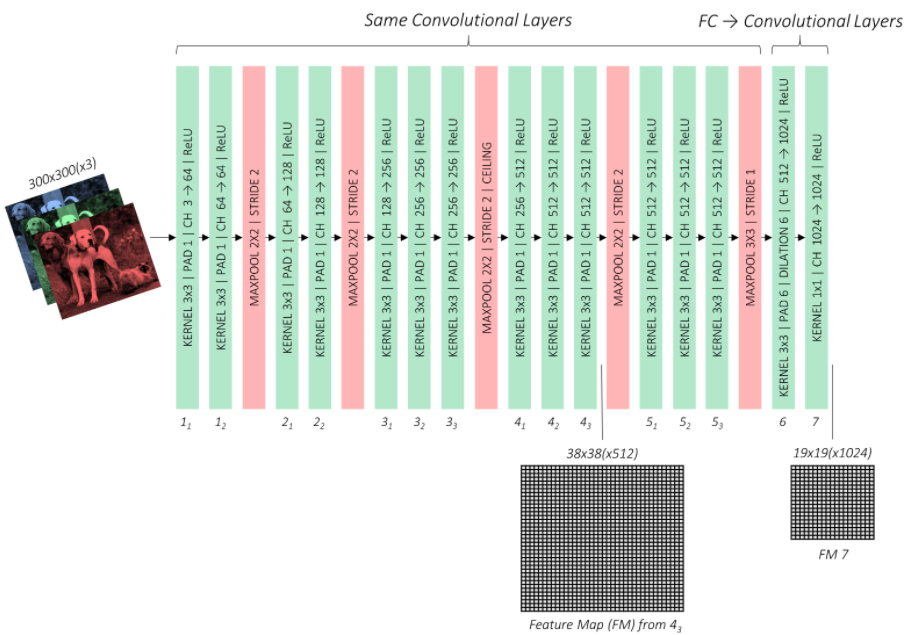
기존의 (4096 x 512 x 19 x 19) FC6을 atrous convolution을 이용해 (1024, 512, 19, 19)로 feature_map의 size를 유지하면서 채널수를 줄였고 FC7은 1x1 convolution을 통해 (1024 x 1024 x 19 x 19) 차원의 파라미터로 만들어 주었다.
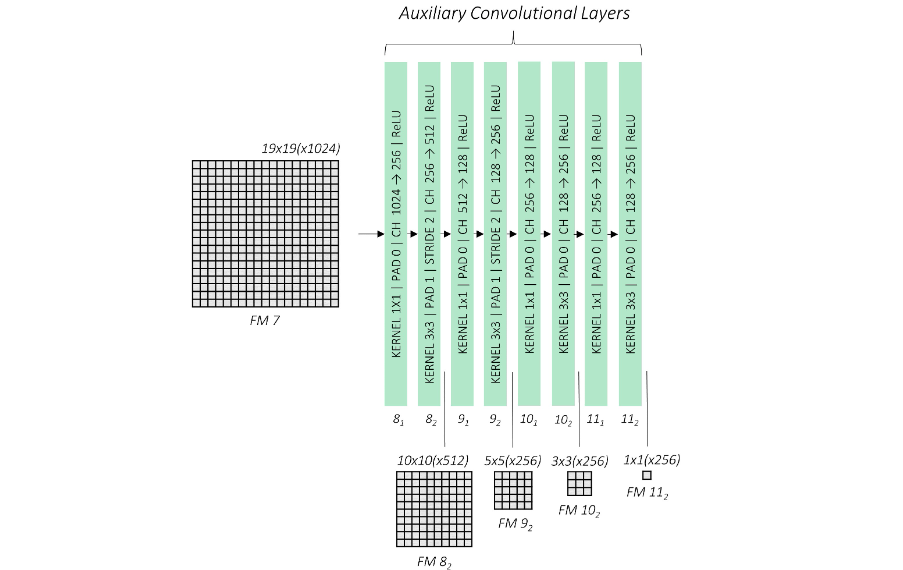
VGG network에 이어서 위와 같은 레이어 들을 추가적으로 붙였고 전체 레이어에서 총 6개의 Feature_map에서 예측을 하고 최종적으로 Non-Max Suppression을 진행하는 구조로 되어있다.
모델을 보면 알 수 있듯이 SSD의 가장 중요한 특징은 Multi-scale Feature Maps for Detection이다.
위에서 언급한 작은 물체를 앞쪽에서 찾고 큰 물체를 뒤쪽에서 찾는것 외에 앞쪽 레이어에서는 공간정보를 많이 가지고 있고 뒤쪽으로 갈수록 이미지 특징에 대한 정보를 가지고 있으므로 마지막 단에서만 예측을 하는것이 아니라 중간중간 레이어에서 예측을 해서 좀 더 다양한 정보를 활용하겠다는 의도를 가지고 있다.
3. Priors
SSD에서는 ground truth와 predict box이외에도 default prior box를 미리 정해두어 loss에서 사용을 하게 된다.
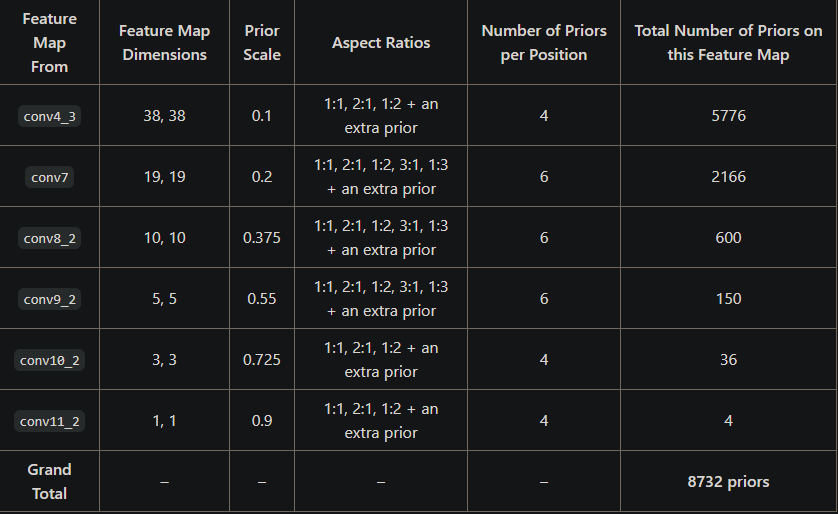
각각의 Feature_map에서 각 그리드 셀마다 4개 혹은 6개의 prior box가 있으며 (conv4_3 에서는 38 x 38 x 4 = 5776 개의 prior box) prior box의 비율은 기본적으로 1:1, 2:1, 1:2, an extra prior(조금 더 스케일이 큰1:1)를 가지고 있으며 6개를 가진 feature_map은 추가적으로 3:1, 1:3의 비율도 가지고 있다.
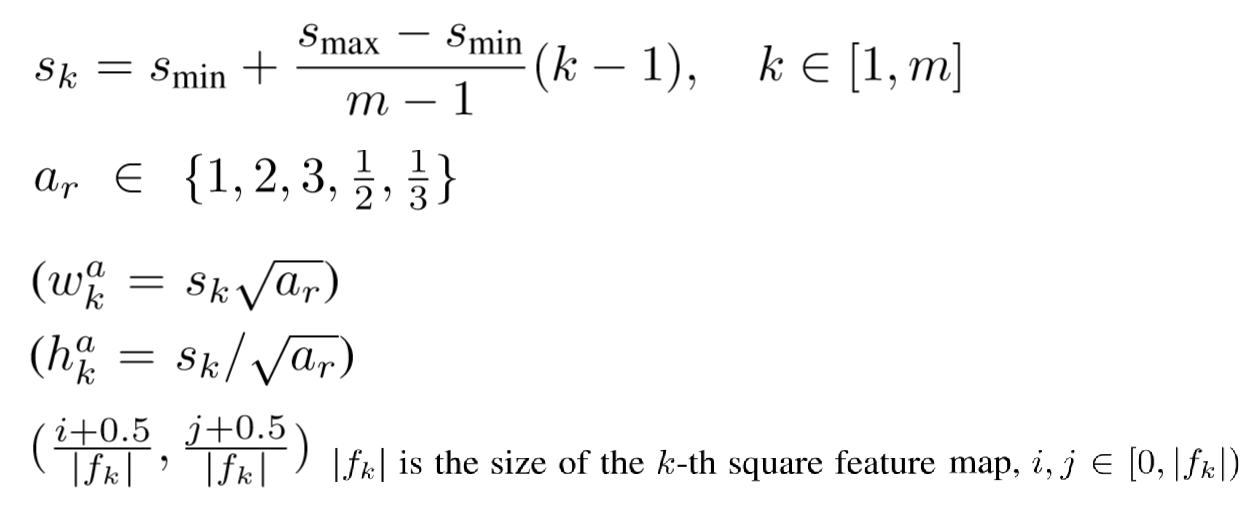
그렇다면 각각의 prior box의 실제 길이는 어떻게 구할까?
논문에서는 위와같은 식을 제시하였는데 우선 cx와 cy는 모든 그리드 셀의 중심이기 때문에 넘어가고 w와 h는 Prior Scale과 Aspect Ratio를 통해 길이를 구하게 된다.
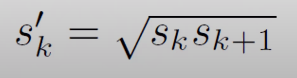
그리고 조금 더 스케일이 큰1:1 Aspect Ratio인 extra prior은 위의 식으로 구하게 된다.
4. Training
- Matching strategy
먼저 해당 이미지에서 ground truth와 default prior box의 IOU가 가장 높은 값을 가지는 box를 찾고 추가적으로 IOU가 0.5 이상인 것들만 따로 매칭(1)을 시키고 나머지는 0으로 바꿔 놓는다.
- Training objective (Loss)
object detection에서는 confidence loss와 locization loss 둘 다 고려해야 하기 때문에 논문에서도 위와같은 loss 수식을 제시 하였다.
N : ground truth와의 IOU가 0.5 이상으로 매칭된 defalt prior box
α : 0< α <1 사이의 상수값인데 논문에서는 1을 사용하였음
먼저 localization loss를 살펴보자
x : 이미지의 k라는 클래스에 대해서 i번째 default box와 j번째 ground truth의 매칭이 1이라면(즉 물체가 있다면) loss를 구하게 되고 0이라면 넘어가게 된다. (IOU가 0.5 이하이면 loss를 계산하지 않겠다.)
l : predicted bounding box
g_hat : ground truth와 default prior box와의 관계에서 얻은 조정값
g : ground truth
d : default box
여기서 w,h 에대한 조정값을 구할때 log를 쓴 이유는 w,h는 박스의 크기에 따라 편차가 심하기 때문에 스케일 조정을 했다고 생각하면 된다.
다음으로 confidence loss를 살펴보면
일반적으로 많이 사용하는 Cross-Entropy 식인것을 알 수 있고 중요 포인트는 Positive항과 Negative항이 있다는 것인데 이것은 아래에서 자세히 설명할 것이다.
5. Hard Negative Mining
Object Dection의 가장 큰 문제중에 하나가 바로 predicted에 대한 imbalance이다. SSD는 한 이미지에 대해 8732개의 classification과 localization을 예측하는데 우리의 이미지는 물체가 100개정도 있다고 쳐도 나머지 8632개는 다 background 정보를 가지고 있다는 것이다. 이런 상황에서 이 모든 데이터를 가지고 학습을 하게 된다면 당연히 좋은 성능을 낼 수 가 없을 것이다.
그래서 논문에서는 Hard Negative Mining이라는 것을 제시하였다. Hard Negative라는 뜻은 실제로 background인데 background라고 하지않고 confidence가 높은것들을 의미한다. 논문에서는 positive 수의 3배의 negative를 confidence loss에 사용을 했다.
다시 정리하면 우선 전체 confidence loss를 계산을 하고 positive인 것들을 뺀 후에 confidence가 높은 순으로 정렬을 하면 background인데 confidence가 높은 순으로 정렬이 될 것이고 이것을 위에서부터 positive의 3배만큼 negative loss로 사용한다는 의미이다.
6. Non-Max Suppression
SSD에서는 출력을 하기 전에 NMS를 사용을 하게 된다. NMS는일정 기준을 바탕으로 상대적으로 중요하지 않은 점이나 데이터를 제거 또는 무시하여 데이터를 처리하는 기법을 말한다.
7. Data Augmentation
- Randomly adjust brightness, contrast, saturation, and hue, each with a 50% chance and in random order.
- With a 50% chance, perform a zoom out operation on the image. This helps with learning to detect small objects. The zoomed out image must be between 1 and 4 times as large as the original. The surrounding space could be filled with the mean of the ImageNet data.
- Randomly crop image, i.e. perform a zoom in operation. This helps with learning to detect large or partial objects. Some objects may even be cut out entirely. Crop dimensions are to be between 0.3 and 1 times the original dimensions. The aspect ratio is to be between 0.5 and 2. Each crop is made such that there is at least one bounding box remaining that has a Jaccard overlap of either 0, 0.1, 0.3, 0.5, 0.7, or 0.9, randomly chosen, with the cropped image. In addition, any bounding boxes remaining whose centers are no longer in the image as a result of the crop are discarded. There is also a chance that the image is not cropped at all.
- With a 50% chance, horizontally flip the image.
- Resize the image to 300, 300 pixels. This is a requirement of the SSD300.
- Convert all boxes from absolute to fractional boundary coordinates. At all stages in our model, all boundary and center-size coordinates will be in their fractional forms.
- Normalize the image with the mean and standard deviation of the ImageNet data that was used to pretrain our VGG base.
End
SSD논문 구현 코드를 이해하는데 어려움이 많았었다. 단순히 이미지에 대한 transform 기법들은 함수가 있지만 Object Detection에서는 이미지가 변하면서 bounding box의 transform을 같이 생각을 해서 직접 코딩을 해야 하기 때문에 수작업이 많이 필요한 것 같다. 또한 detection의 여러 기법들을 코드로 구현할때 그 개념을 정확히 알지 않고 시작하면 다시 되돌아 간다는것을 경험했다.
Reference
paper : arxiv.org/abs/1512.02325
review : www.youtube.com/watch?v=ej1ISEoAK5g&t=1338s
code : github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection
Leave a comment