
[논문리뷰] VGGNet
VGGNet이란?
VGGNet은 2014년 이미지넷 대회에서 준우승을 한 모델이며 옥스포드 대학의 연구팀 VGG에서 발표를 하였다. 정식명칭이 Visual Geometry Group인 이 모델은 아직까지도 backborn architecture로 사용되고 있을정도로 괜찮은 구조를 가지고 있다.
원래 이 VGGNet의 목적은 CNN의 깊이가 image classification 에 어떤 영향을 끼치는지 알아내기 위함이었다고 한다. 그래서 VGGNet의 이름은 레이어의 수로 구분을 할 수 있게 되는데 현재 많이 인용되는 네트워크는 VGG16 과 VGG19이다. 뒤에붙은 16과 19가 바로 네트워크 레이어의 수 이고 여기서 중요한건 weight를 가진 레이어(convolution layer,fully connected layer)만 세었을때의 숫자이다.(max pooling은 weight를 다루지 않음)
오늘 소개할 네트워크 구조는 VGG16이며 아래와 같다.
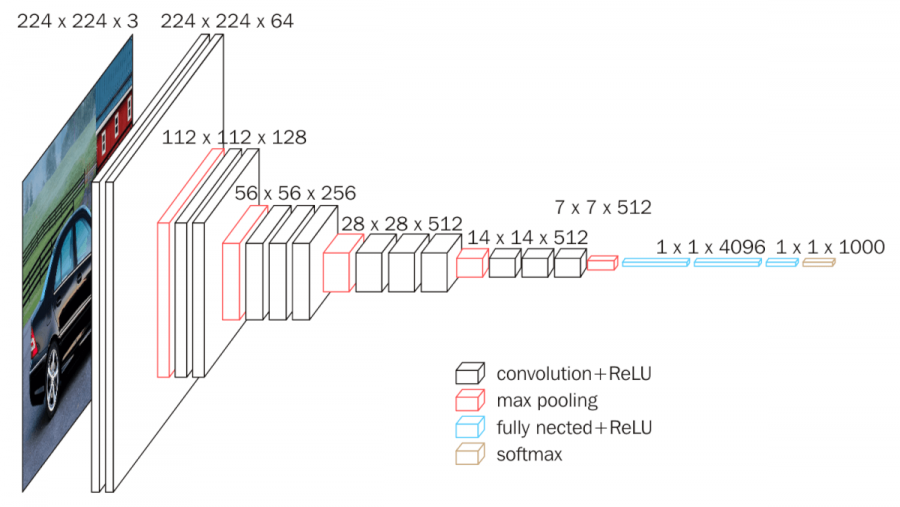
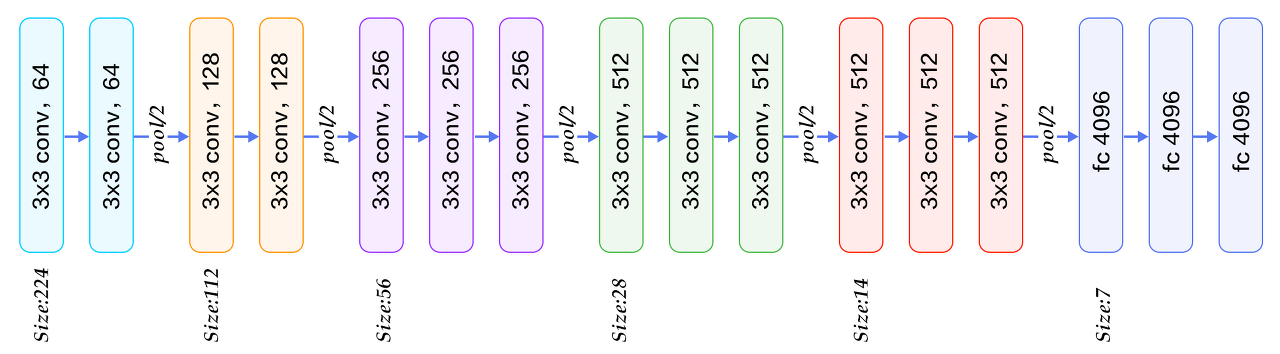
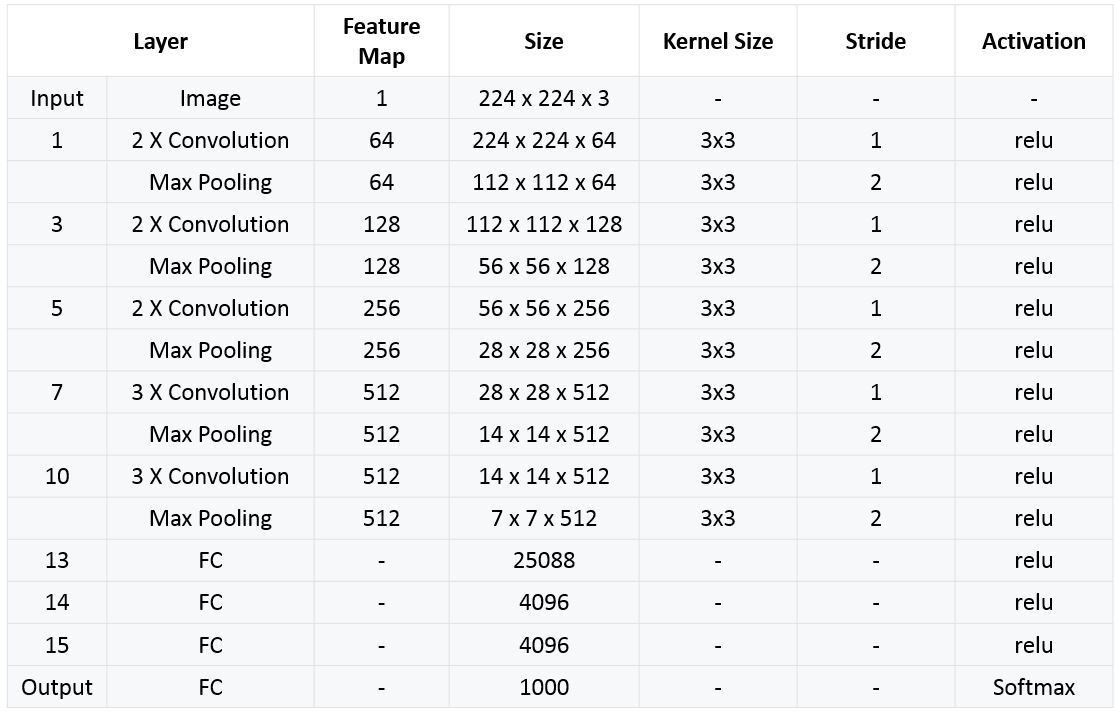
구조를 보면 아이디어는 굉장히 간단하다. 가장 작은 필터사이즈인 3 x 3 을 사용하여 Conv레이어를 형성하고 max pooling으로 image size를 절반으로 줄이고 다시 conv레이어를 쌓고를 반복을 하며 마지막 3개의 단계에서 Fully Connected layer를 사용한다.
여기서 굳이 왜 3 x 3 filter size를 사용했을까?
앞서 말했던것 처럼 VGG팀은 이 모델을 만든 목적이 레이어의 깊이에 따른 모델의 성능 이기 때문에 이미지 사이즈를 최대한 유지( 3 x 3 보다 큰 필터를 사용하면 feature map의 크기가 작아지므로)시키기 위해 3 x 3 filter size를 사용한것이다. (ex. imagesize = 224, filtersize=3, stride=1, padding=1 -> (image_size - filtersize + (2 x padding) / stride) + 1 = (224 - 3 + (2 x 1) / 1) + 1 = 224)
그렇다면 3 x 3 말고 다른 filter size(5 x 5 or 7 x 7)를 써서 padding을 주어서 이미지 사이즈를 유지하면 되지 않냐 라는 질문을 할 수가 있는데 VGGNet은 레이어의 개수가 중요했고 7 x 7 filtersize 를 한번 수행할때 3 x 3 filtersize는 세번을 수행을 할 수 있다. 아래 그림을 보면 이해할 수 있을 것이다.
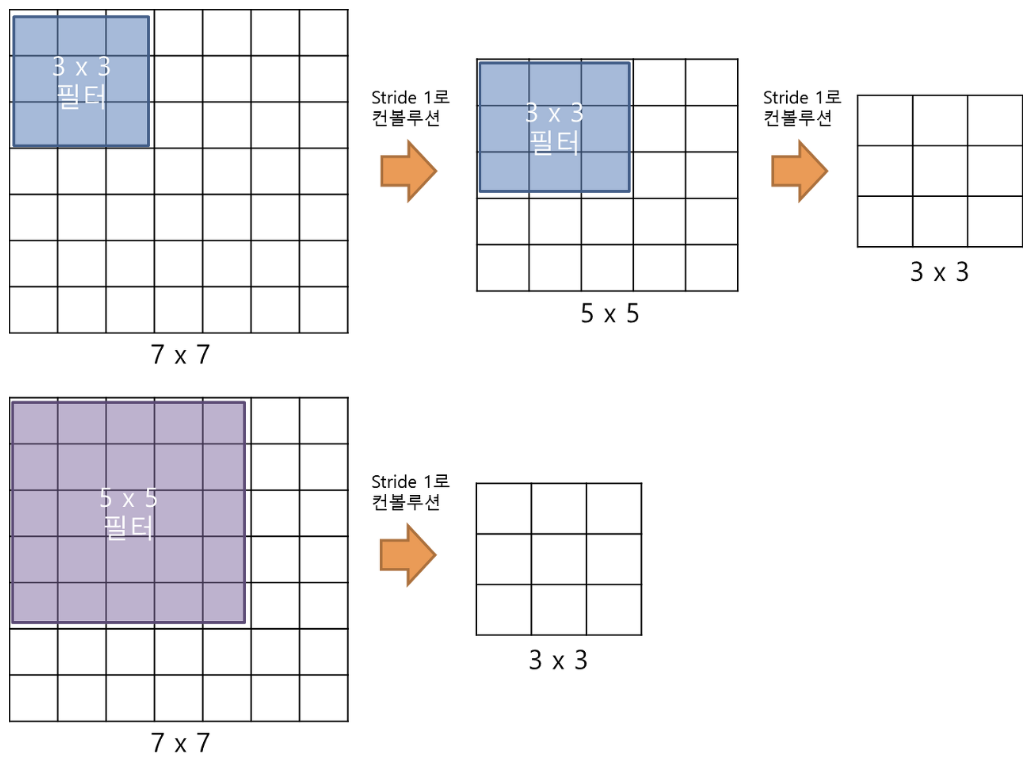
3x3이 7x7보다 나은점은 바로 파라미터의 개수이다. 3 x 3 filter가 3개가 있으면 파라미터는 총 27개가 나오는 반면에 7 x 7 filter는 1 개만 있어도 49개의 파라미터가 나오게 된다. 즉 7 x 7 filter를 사용하게되면 학습해야할 파라미터 수가 더 많아 손해가 된다는 의미이다. 그래서 3 x 3 filter를 사용한다. 그리고 3 x 3 을 여러개 쓴다는 것은 활성화 함수(Relu)도 여러번 쓴다는 의미이기 때문에 feature extraction 특성이 더 좋아진다.
모델 구현 및 학습
학습에 사용될 데이터 : STL10 ( 10개의 클래스로 이루어져 있으며 이미지 사이즈는 96 x 96 x 3 )
대회에 사용된 이미지는 크기가 244 x 244 여서 여러 transform을 통해 224 x 224의 크기로 변환해서 사용했지만 STL10 데이터는 96 x 96 크기이므로 이것을 224 x 224로 늘려야 해서 모델 성능이 생각보다 낮게 나올 수 있다.
Import library and check GPU
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
pytorch를 사용할 것이기때문에 관련 라이브러리들을 import 하고 GPU 설정을 했다.
Define transform and load data
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),
])
trainset = torchvision.datasets.STL10(root='./data', split='train', download=True, transform = transform)
testset = torchvision.datasets.STL10(root='./data', split='test', download=True, transform = transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers = 2)
test_loader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers = 2)
transforms.Resize(224) : 96 x 96 인 STL10데이터를 224 x 224 크기로 변환한다.
transforms.ToTensor() : 데이터를 Tensor형으로 전환한다.
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) : 학습 전에 데이터를 normalize시켜서 특정부분이 어둡거나 밝다면 그것을 일반화 해줌으로서 데이터가 튀는 현상을 막하준다. 여기서는 평균과 표준편차를 0.5로 사용했는데 이 값들은 보통 데이터를 제공하는 곳에서 이미 평균과 표준편차를 계산해놔서 그것을 사용하면 된다.
trainset, testset을 구분해서 데이터셋을 가져오고 그것을 DataLoader로 보낸다. (batch_size는 64를 사용)
Show transfomed images
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # unnormalize
img = img.numpy().transpose(1,2,0)
plt.imshow(img)
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
classes = ['airplane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck']
print(' '.join('%5s' % classes[labels[j]] for j in range(64)))
변환된 이미지를 확인하기위해 imshow라는 함수를 선언하였다. 이미지를 원상태로 바꿔야하므로 몇가지 전처리 후에 imake_grid를 통해 batch_size 만큼의 데이터가 뽑일 수 있도록 했다. classes는 STL10 데이터의 class를 정의해 놓은 리스트이다.(labels가 index값으로 되어있기 때문)
아래 그림은 위의 코드 실행 결과이다. class명과 사진이 64개가 나오는데 사진에서는 class명이 길게 나와서 나머지는 잘라놓은 상태이다. 현재 빨간 선을 보면 이미지와 라벨이 잘 맞는것을 알 수 있다.

Define VGG16 model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),nn.LeakyReLU(0.2), # 224x224x64
nn.Conv2d(64, 64, 3, padding=1),nn.LeakyReLU(0.2), # 224x224x64
nn.MaxPool2d(2, 2), # 112x112x64
nn.Conv2d(64, 128, 3, padding=1),nn.LeakyReLU(0.2), # 112x112x128
nn.Conv2d(128, 128, 3, padding=1),nn.LeakyReLU(0.2), # 112x112x128
nn.MaxPool2d(2, 2), # 56x56x128
nn.Conv2d(128, 256, 3, padding=1),nn.LeakyReLU(0.2), # 56x56x256
nn.Conv2d(256, 256, 3, padding=1),nn.LeakyReLU(0.2), # 56x56x256
nn.Conv2d(256, 256, 3, padding=1),nn.LeakyReLU(0.2), # 56x56x256
nn.MaxPool2d(2, 2), # 28x28x256
nn.Conv2d(256, 512, 3, padding=1),nn.LeakyReLU(0.2), # 28x28x512
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2), # 28x28x512
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2), # 28x28x512
nn.MaxPool2d(2, 2), # 14x14x512
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2), # 14x14x512
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2), # 14x14x512
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2), # 14x14x512
nn.MaxPool2d(2, 2) # 7x7x512
)
self.avg_pool = nn.AvgPool2d(7) # 1 x 1 x 512
self.classifier = nn.Linear(512, 10) # 512 x 10
def forward(self, x):
features = self.conv(x)
x = self.avg_pool(features)
x = x.view(features.size(0), -1)
x = self.classifier(x)
return x, features
net = Net()
net = net.to(device)
param = list(net.parameters())
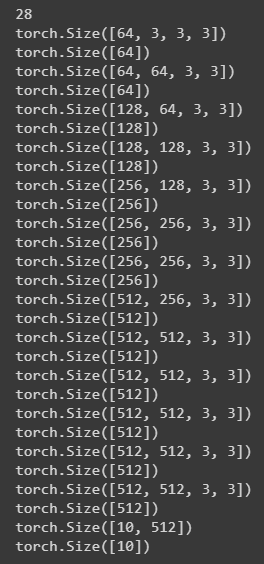
print(len(param))
for i in param:
print(i.shape)
위에서 설명한 바와 같이 모델을 구성을 했다. 다만 마지막 3개의 레이어에서 FC 레이어를 사용하지 않았다. 시간도 오래걸리고 무엇보다 “CUDA out of memory.” 에러가 나와서 배치사이즈도 줄여보고 cuda cache clear를 해보아도 해결이 되지 않아 7x7 Average Pooling을 사용하여 바로 1x1x512 사이즈로 축소시켜 하나의 Linear layer만 통과시키도록 하였다.
모델을 생성하고 Cuda 로 바꾸었다. 위의 코드 실행 결과는 아래와 같다.
Define loss function and optimizer
import torch.optim as optim
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(net.parameters(),lr=0.00001)
loss function은 CrossEntropyLoss를 사용하였다. CrossEntropyLoss는 안에 softmax 활성화 함수가 포함되어있어서 모델에서 마지막에 softmax를 하지 않았다. NLLLoss를 사용하면 softmax가 없는 CrossEntropy를 사용할 수 있는데 이때는 모델에서 따로 softmax를 써줘야 한다.
optimizer는 Adam을 사용했다. Adam은 학습 시 현재의 미분값 뿐만 아니라, 이전 결과에 따른 관성 모멘트를 가지고 있는것이 특징이다.
Train the model
for epoch in range(100):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs,f = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if(loss.item() > 1000):
print(loss.item())
for param in net.parameters():
print(param.data)
running_loss += loss.item()
if i % 50 == 49:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 50))
running_loss = 0.0
print('Finished Training')
pytorch tutorial에서 자주 등장하는 training code와 비슷하게 구성을 하였다.
epoch은 100을 설정 하였고 아래와같이 미니배치 50번째에서 간단하게 현재 loss값을 출력하도록 하였다.
Evaluate the model
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
outputs, f = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
학습된 모델에 test 데이터를 넣은 후 각 클래스별로 정확도를 확인해 보았다.

역시 생각보다 정확도가 낮게 나왔다. 내 GPU(GeForce GTX 1060 3GB)로는 아예 학습조차 되지 않아서 Colab의 가상 Gpu로 학습했고 약 2시간 이상 걸렸다. VGG16은 보기에는 간단한데 파라미터수가 굉장히 많기때문에 나의 환경으로는 학습에 무리가 있었다.
다음 포스트 부터는 pre-trained된 model을 가져와서 사용할 예정이다.
Leave a comment