Intro
최근 GPT-4o image generation 기능이 발표되면서 다양한 이미지를 생성해서 결과물을 공유하는것이 하나의 문화로 자리잡았습니다. 이미지 생성이야 꽤 오래전부터 가능했지만 일반인에게 가장 친숙한 Chat-GPT의 공식 발표로 인해 모든 사람들이 쉽게 이미지 생성에 다가갈 수 있게 된 것 같습니다.
“이 사진을 지브리 스타일로 만들어줘.”

Original

Ghibli Style
왜 하필 지브리 스타일로 사진을 바꾸는 것이 유행이었을까요? 이것이 밈이 되어버리기 전에 다양한 편집 결과중 지브리 풍으로 이미지를 만드는것이 유독 높은 퀄리티로 생성되었기 때문이라고 생각합니다.
처음부터 이미지 생성을 하거나 지브리 밈처럼 이미지의 전체적인 스타일을 바꾸는것은 꽤 좋은 결과를 얻을 수 있지만 다른부분을 유지한채 명령에 따라 특정 부분만 섬세하게 수정하는 과제만큼은 여전히 까다롭습니다.
“머리카락 색만 살짝 바꾸고, 배경은 그대로 두고, 인물의 표정은 유지해 줘” 같은 복합 지시를 한 번에 만족시키려면 정교한 편집 능력이 필요합니다.
이와 관련해 최근에 In-Context Edit 이라는 논문이 발표되었습니다. 이 어려운 문제를 Large Scale Diffusion Transformer의 문맥 이해 능력”을 적극 활용해 풀어내어 해결해 내려는 시도를 하였습니다.
그 결과 수백만 장의 편집 데이터를 다시 학습하지 않아도, 모델 구조를 대대적으로 뜯어고치지 않아도, 비교적 적은 데이터와 파라미터만으로도 GPT-4o 수준의 자연어 이해를 그대로 살려 정밀한 이미지 편집을 실현시켰습니다.
이번 포스팅에서는 In-Context Edit의 핵심 아이디어를 살펴보고 직접 ComfyUI에서 테스트한 결과를 공유해보려 합니다.
Introduction
지시에 따른 이미지 편집은 사용자가 자연어 지침만으로 이미지를 원하는 대로 수정할 수 있게 해주는 기술입니다. 예를 들어 “이 인물의 머리카락을 금발로 바꿔줘” 혹은 “배경에 노을이 지도록 해줘” 같은 간단한 문장만으로도 이미지에 정교한 변경을 가할 수 있다면, 이미지 편집은 훨씬 손쉬워질 것입니다.
이러한 명령어 기반 이미지 편집의 가장 큰 장점은 아주 적은 텍스트 지시만으로도 원하는 이미지를 만들어낼 수 있다는 점입니다. 이는 자동화된 이미지 편집이나 사용자가 주도하는 콘텐츠 제작에 새로운 가능성을 열어주기 때문에, 최근 몇 년간 학계와 업계에서 큰 주목을 받아왔습니다.
그러나 현재의 이미지 편집 방법들은 정밀도와 효율성 사이의 딜레마에 직면해 있습니다. 전통적으로 두 가지 접근법이 널리 사용되어 왔는데요:
-
Fine-Tuning 기반 방법: 사전 학습된 거대 확산 모델을 대규모 편집 데이터셋에 다시 훈련(finetune)시켜서, 주어진 지시를 따르는 능력을 모델에 학습시키는 방식입니다. 이 접근법은 정확도 측면에서 뛰어난 결과를 내곤 하지만, 대가가 있습니다. 새로운 작업에 맞게 모델을 다시 훈련하려면 막대한 양의 데이터(수십만~수백만 장)와 계산 자원이 필요하며, 경우에 따라 모델 구조 자체를 변경하거나 추가 모듈을 붙여서 성능을 향상시키기도 합니다. 마치 능숙한 편집 기술을 가진 전문가를 새로 키워내는 과정과 비슷한데, 매우 비용이 크고 시간이 오래 걸리는 방법이죠.
- Training-Free(zero-shot) 방법: 반면, 추가 훈련 없이 바로 사전 학습된 모델을 활용해 이미지를 편집하려는 시도도 있습니다.
- image inversion:
- 주어진 이미지를 생성 모델의 잠재 공간(latent space)에 매핑하는 과정.
- 이렇게 매핑된 잠재 벡터를 통해 원본 이미지를 재구성하거나, 잠재 공간에서의 조작을 통해 새로운 이미지를 생성할 수 있음.
- prompt swapping:
- 지시문을 특징 묘사와 같은 일반적인 프롬프트로 변경.
- ex. 고양이를 강아지로 바꿔줘 -> 강아지가 소파에 앉아있는 모습.
- manipulating attention:
- 이미지 생성 과정에서, 텍스트의 각 단어에 주목하는 정도(=어텐션)를 수동으로 조정하여 결과 이미지를 제어하는 기법.
- 편집 시 “sofa”의 색상만 바꾸고 싶다면, “sofa”라는 단어에 관련된 어텐션 부분만 조작해서 편집.
- 이들은 모델을 새로 훈련하지 않기 때문에 비교적 빠르고 간단하다는 장점이 있지만, 지시문을 정확히 이해하거나 원하는 품질의 결과물을 내는 데 한계가 있습니다.
Fine-Tuning 방식은 높은 정밀도를 달성하지만, 훈련에 시간과 자원이 너무 많이 들어간다는 문제가 있으며 Training-Free 방식은 간편하고 빠르지만, 편집 지시의 이해 부족이나 편집 품질 저하로 이어질 수 있습니다.
다행히도, 최근 대규모 확산 변환기(Diffusion Transformer, DiT) 모델들이 등장하면서 실마리가 보이기 시작했습니다. DiT는 거대한 생성 능력과 고유한 문맥 파악 능력을 겸비한 새로운 유형의 이미지 생성 모델이며 정밀도와 효율성 간의 균형 문제를 해결할 새로운 가능성을 열어주었습니다.
이번에 소개하는 “In-Context Edit” 연구는, 대규모 확산 변환기(DiT)의 능력을 활용하여 최소한의 데이터와 파라미터 수정만으로도 지시 기반 이미지 편집을 정확하고 효율적으로 해내는 방법을 제시하고 있습니다.
In-context Edit
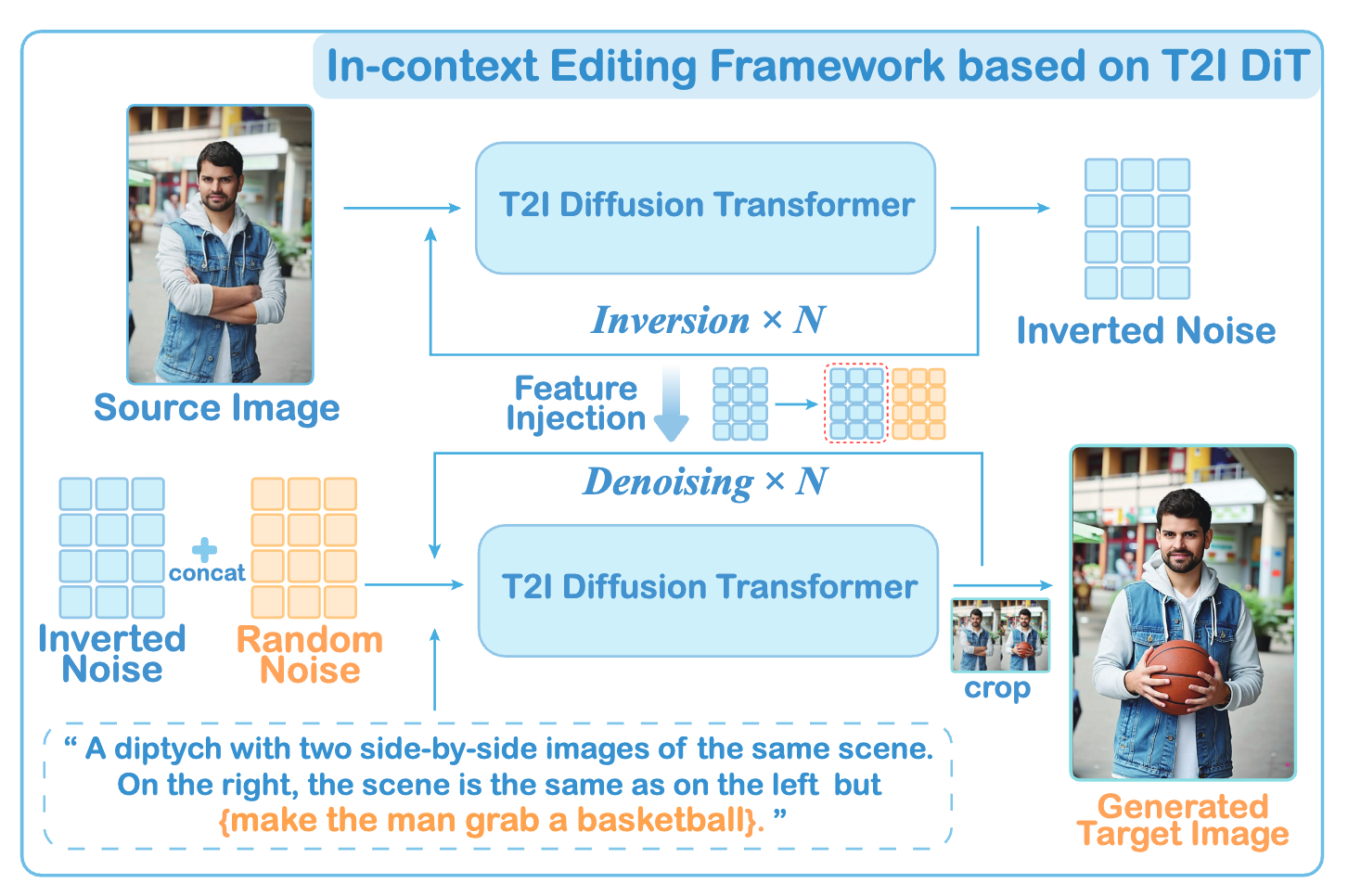
새롭게 제안된 In-Context Edit(ICEdit)은 추가 학습 없이도 모델이 텍스트 지시에 따라 이미지를 편집하도록 유도하는 똑똑한 방식을 취하고 있습니다. 핵심 아이디어는 문맥(Context)을 활용한다는 것인데요, 이는 마치 모델에게 편집 전후의 예시를 한꺼번에 보여주어 스스로 변화 내용을 이해하고 적용하게 만드는 것과 같습니다.
구체적으로, 이 연구에서는 특수한 형태의 프롬프트를 설계합니다. 예를 들어 “두 장의 나란한 이미지가 있습니다. 왼쪽에는 원본 이미지의 {상세설명}이 있고, 오른쪽에는 왼쪽 이미지와 같지만 거기에 {편집 지시}가 적용되어 있습니다.” 와 같은 문장을 만들어내는 겁니다. 이때 실제 왼쪽 자리에는 원본 이미지가 주어지고, 오른쪽은 모델이 생성해야 할 편집된 이미지가 됩니다. 이렇게 하면 모델은 한 번의 프롬프트로 “원본과 편집본”을 동시에 인식하게 됩니다.
이 아이디어의 놀라운 점은, 모델이 구조를 바꾸지 않고도 편집을 수행하게 된다는 것입니다. 왼쪽에 제시된 원본 컨텍스트를 참고하기 때문에, 모델은 “어떤 부분을 유지하고 무엇을 바꿔야 하는지” 자연스럽게 이해하게 됩니다. 모델이 예시로 주어진 맥락(컨텍스트)을 보고 거기에 맞춰 편집을 수행하니, 불필요한 구조 변화 없이 지시된 부분만 정확히 수정할 수 있게 됩니다.
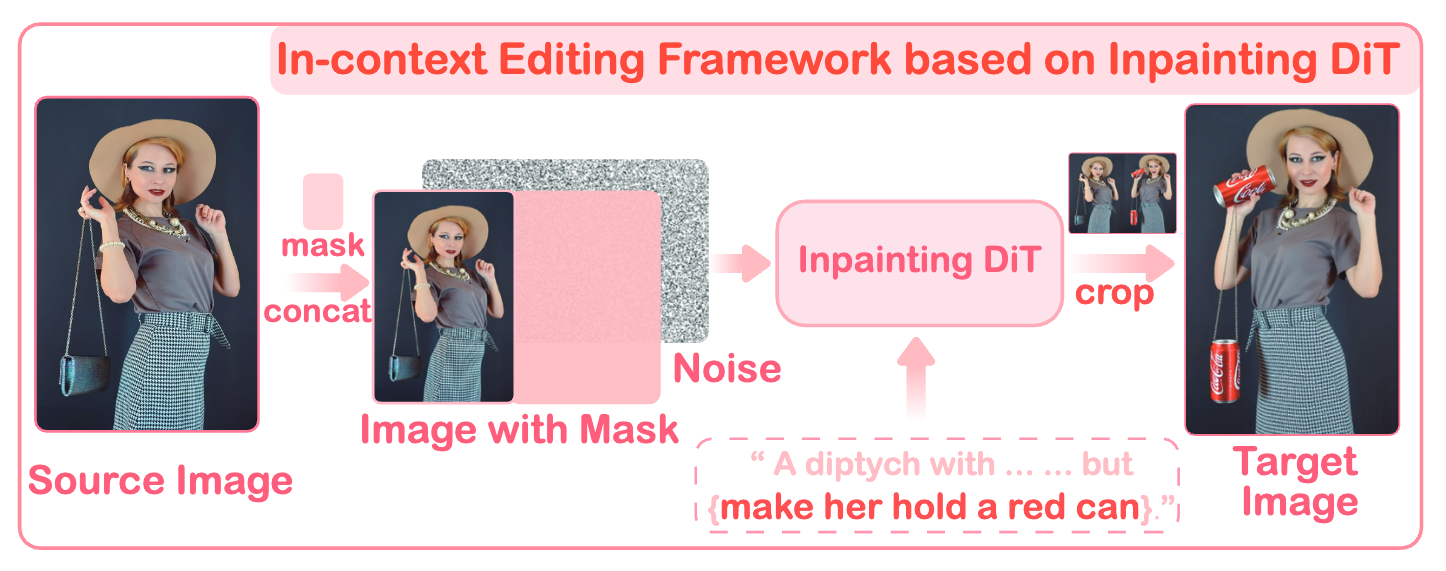
이 프레임워크의 구성은 두 가지 변형으로 디자인되었습니다:
즉, In-Context Edit 프레임워크는 “문맥 속 편집 지시” 라는 교묘한 트릭으로 추가 학습 없이도 모델에게 편집 능력을 불어넣었습니다.
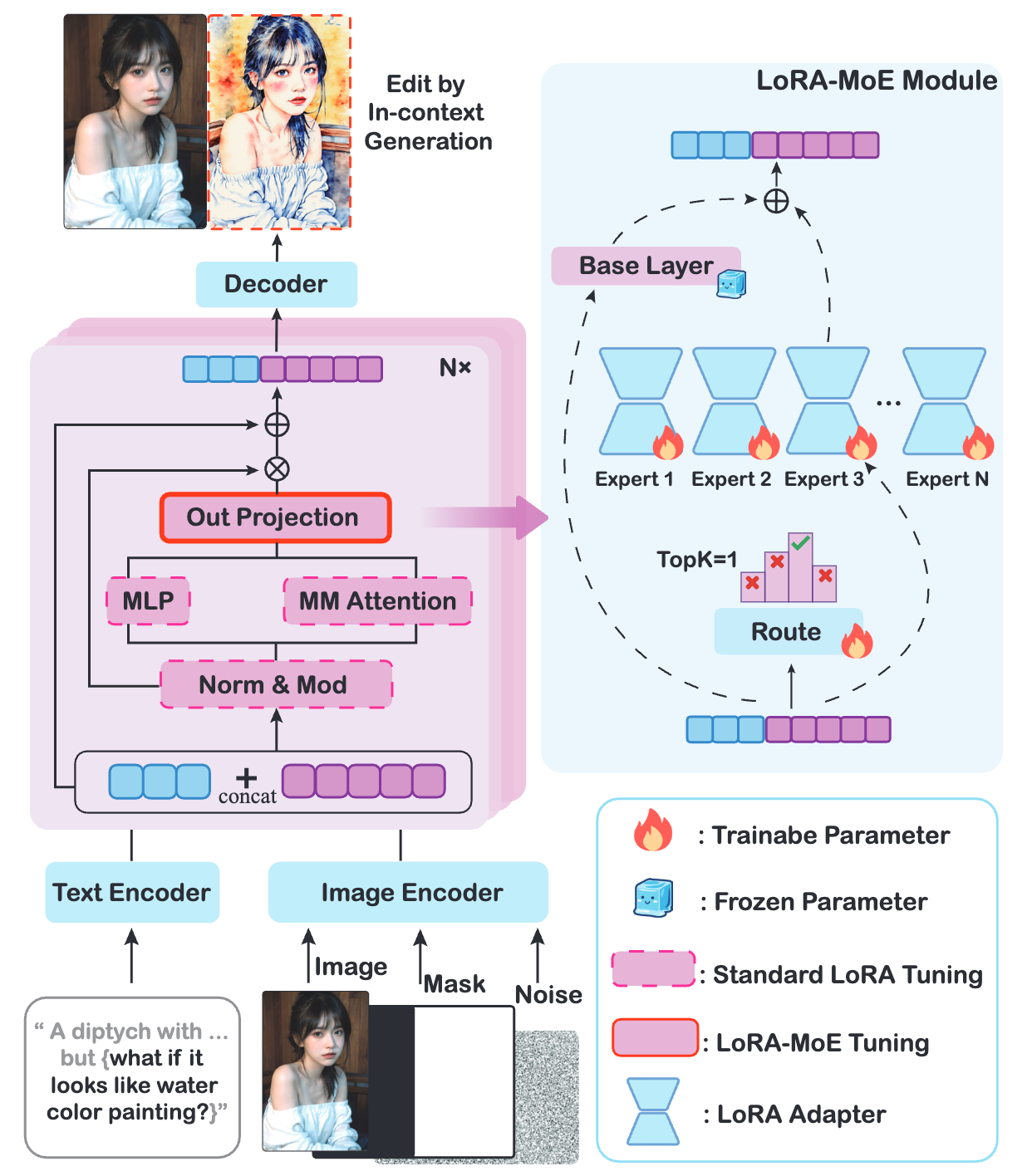
LoRA-MoE Hybrid Fine-tuning
In-Context Edit의 두 번째 핵심은 LoRA-MoE 하이브리드 튜닝 전략입니다. 여기서 LoRA와 MoE의 의미는 다음과 같습니다:
-
LoRA(Low-Rank Adaptation): 거대 모델을 효율적으로 미세조정하기 위한 기법입니다. 거대한 모델의 모든 가중치를 일일이 업데이트하는 대신, 적은 수의 매개변수로 구성된 작은 모듈(저차원 행렬)을 추가하여 모델의 출력만 살짝 조정하는 방식입니다. LoRA를 사용하면 기존 모델의 1% 정도의 파라미터만 학습하면 되기 때문에 매우 효율적입니다.
-
MoE(Mixture of Experts): 이것은 모델 내부에 여러 명의 ‘전문가’ 서브모델을 두고, 필요한 순간에 가장 적합한 전문가를 선택해 활용하는 구조입니다. 거대한 하나의 뇌로 모든 것을 처리하는 대신, 전문 분야가 다른 작은 뇌 여러 개가 있고 그중 상황에 맞는 뇌를 쓰는 셈입니다. 예를 들어 어떤 전문가는 색상 변경에 능하고, 또 다른 전문가는 물체 추가에 능한 식입니다. MoE 구조에서는 입력에 따라 어느 전문가를 쓸지 결정하는 **라우터(router)**가 존재해, 모델이 동적으로 전문가를 골라 작업을 수행합니다.
LoRA-MoE 하이브리드 전략이란 이 두 가지를 결합한 접근을 말합니다. In-Context Edit에서는 Diffusion Transformer 모델 내부에 LoRA 어댑터를 활용한 MoE 구조를 통합하였습니다. 구체적으로는, DiT 모델의 몇몇 계층에 여러 개의 **전문가 블록(Experts)**을 두고, 각 전문가에 LoRA 어댑터를 달아주었습니다. 그리고 학습 가능한 라우팅 분류기를 도입하여 시각적 토큰 내용이나 텍스트 임베딩에 따라 가장 알맞은 전문가를 골라 활성화하도록 만들었습니다.
이 LoRA-MoE 하이브리드 튜닝 전략을 통해 In-Context Edit 모델은 최소한의 미세조정으로도 놀라울 만큼 향상된 편집 성능과 유연성을 얻을 수 있었습니다. 특히 대규모 재훈련 없이 새로운 편집 작업에 대응할 수 있다는 점에서 실용적 이점이 큽니다.
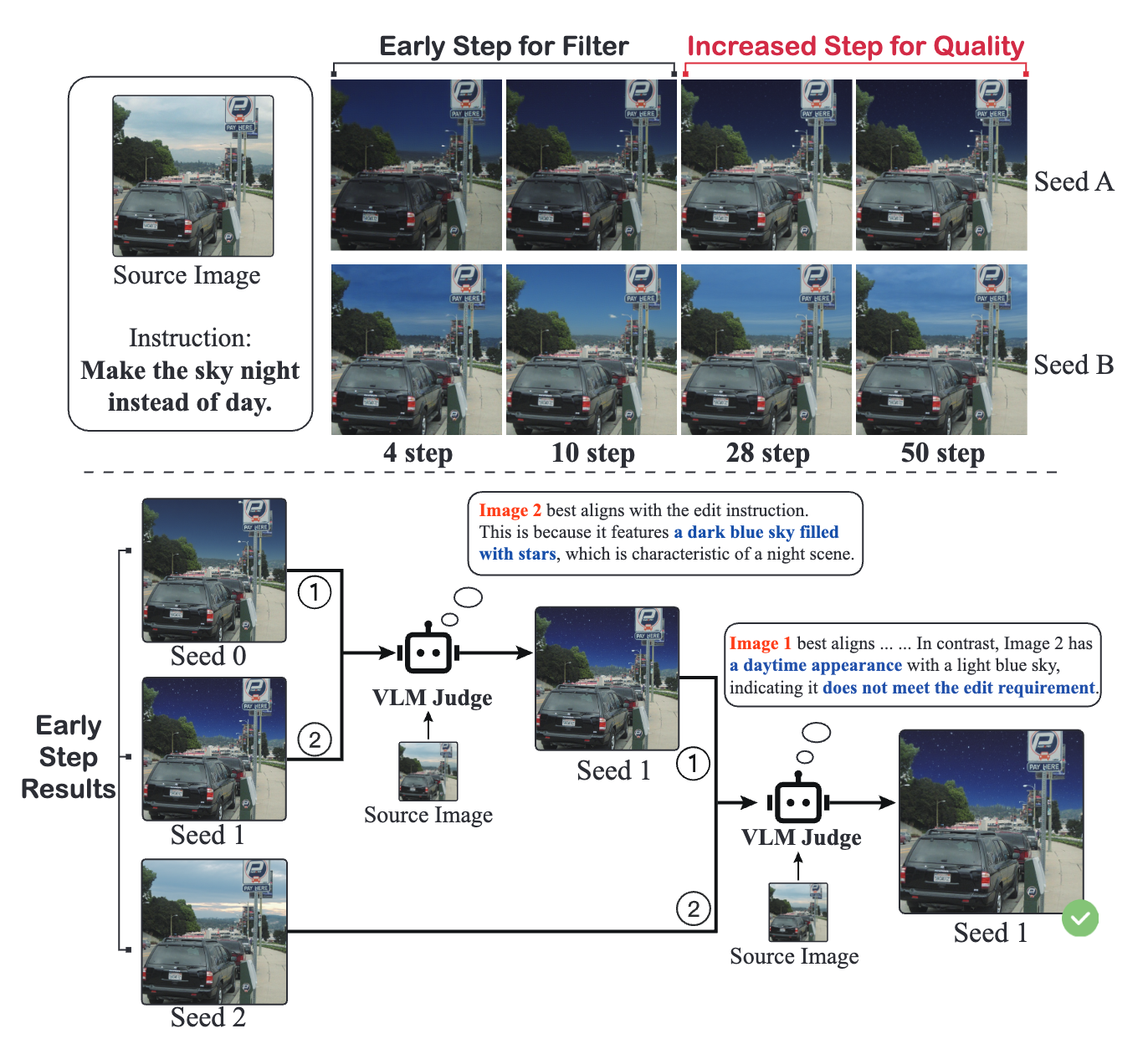
Early Filter Inference Time Scaling
마지막 핵심 기법은 Early Filter Inference-Time Scaling입니다. 이 방법은 모델이 이미지를 생성하는 추론(inference) 과정 자체를 개선하여 편집 품질을 높이는 기술입니다.
배경 지식으로, 확산 모델(Diffusion Model)의 이미지를 생성하는 과정은 노이즈를 점진적으로 제거하며 원하는 이미지를 얻어가는 과정이라고 이해할 수 있습니다. 이때 초기 노이즈의 상태가 최종 결과에 큰 영향을 주는 경우가 많은데요, Early Filter Inference-Time Scaling은 바로 이 초기 단계를 똑똑하게 관리하는 것을 목표로 합니다.
구체적으로, Vision-Language Model(VLM)이라고 불리는 이미지-텍스트 결합 모델을 활용합니다. 대표적인 VLM으로 CLIP 모델을 예로 들 수 있는데, 주어진 이미지와 텍스트(설명 또는 지시)가 얼마나 잘 맞는지 점수를 매겨줄 수 있는 모델입니다. In-Context Edit에서는 이러한 VLM을 편집 품질 평가자로 사용합니다.
작동 방식은 다음과 같습니다:
-
처음에 확산 모델이 이미지를 생성할 때, 여러 가지 초기 노이즈 후보로부터 시작할 수 있습니다. 각기 다른 시드(seed)를 주어 여러 초기 이미지를 만들어볼 수도 있죠.
-
초기 몇 단계의 노이즈 제거가 진행된 이미지들을 VLM으로 평가합니다. 즉, 각 후보 이미지가 텍스트 지시와 얼마나 부합하는지 그리고 이미지 품질은 어떤지를 아주 이른 단계에서 가늠해보는 것입니다. 마치 그림을 처음 스케치했을 때 대략적인 형태를 보고 “어, 이러면 안 되겠는데?”하고 판단하는 것과 비슷합니다.
-
그 다음, 가장 유망한 후보를 골라 남기고 나머지 후보들은 버리거나 스케일을 조정합니다. 선택된 후보는 초기 노이즈 분포가 잘 잡힌 케이스이므로, 계속해서 후반부 생성 과정을 진행하면 최종적으로 더 좋은 편집 결과를 얻을 가능성이 높습니다.
이렇게 초반에 거르는 작업(Early Filter)을 거치면, 모델이 잘못된 방향으로 이미지를 만들어가는 것을 방지할 수 있습니다. 처음부터 하나만 그리고 나중에야 “엥, 지시랑 다르게 그렸네”하고 고치는 것보다, 애초에 올바른 방향으로 시작하는 것이 효율적이고 결과도 훨씬 좋겠죠.
Early Filter Inference-Time Scaling 기법의 효과는 편집 성공률과 결과 품질의 향상으로 나타났습니다. 이 방법을 통해 초기에 지시와 부합하지 않는 경로는 배제하고 가장 그럴듯한 경로로 집중할 수 있으니, 편집의 정확성 및 일관성이 높아집니다. 게다가 필요한 경우 추론 단계를 유연하게 조절할 수도 있어(예를 들어 더 많은 후보를 평가하거나 특정 기준을 강화하는 등), 편집의 robust도 증가합니다. 연구 결과에 따르면, 이 추론 단계 스케일링을 도입했을 때 편집 성능 지표가 상당히 개선되었는데, 이후 실험 결과 요약 부분에서 조금 더 살펴보겠습니다.
Experiments
이제 In-Context Edit(ICEdit) 기법이 실제로 얼마나 효과적인지, 실험 결과와 함께 살펴보겠습니다. 연구진은 다양한 벤치마크 데이터셋과 평가 지표를 사용하여 ICEdit의 성능을 측정하고 다른 방법들과 비교했습니다. 결과는 매우 인상적이었습니다.
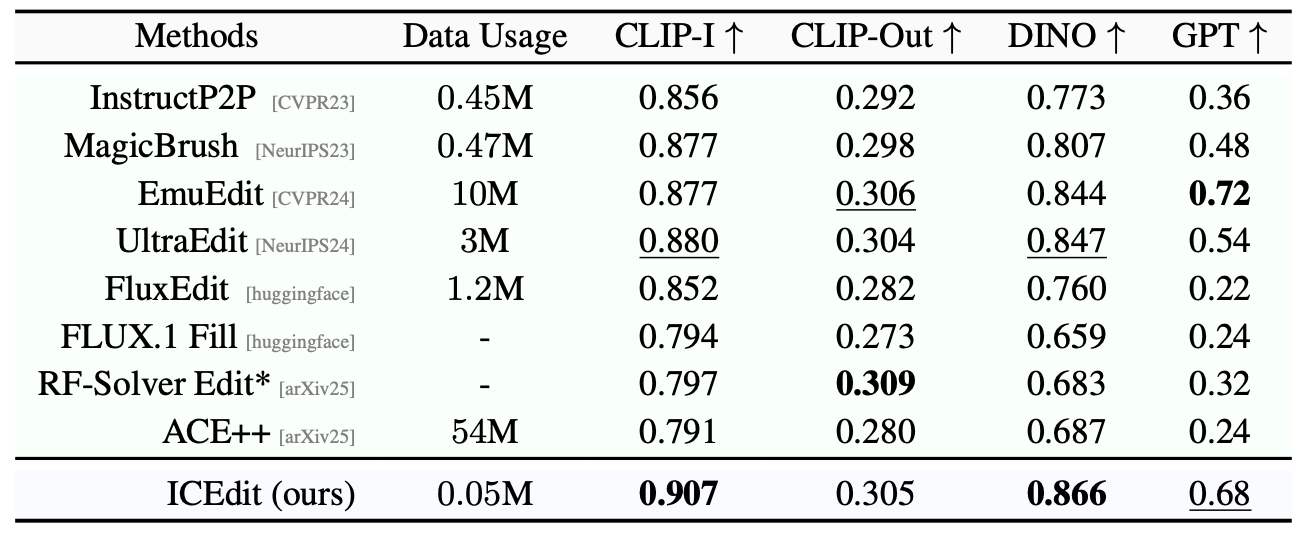
Data
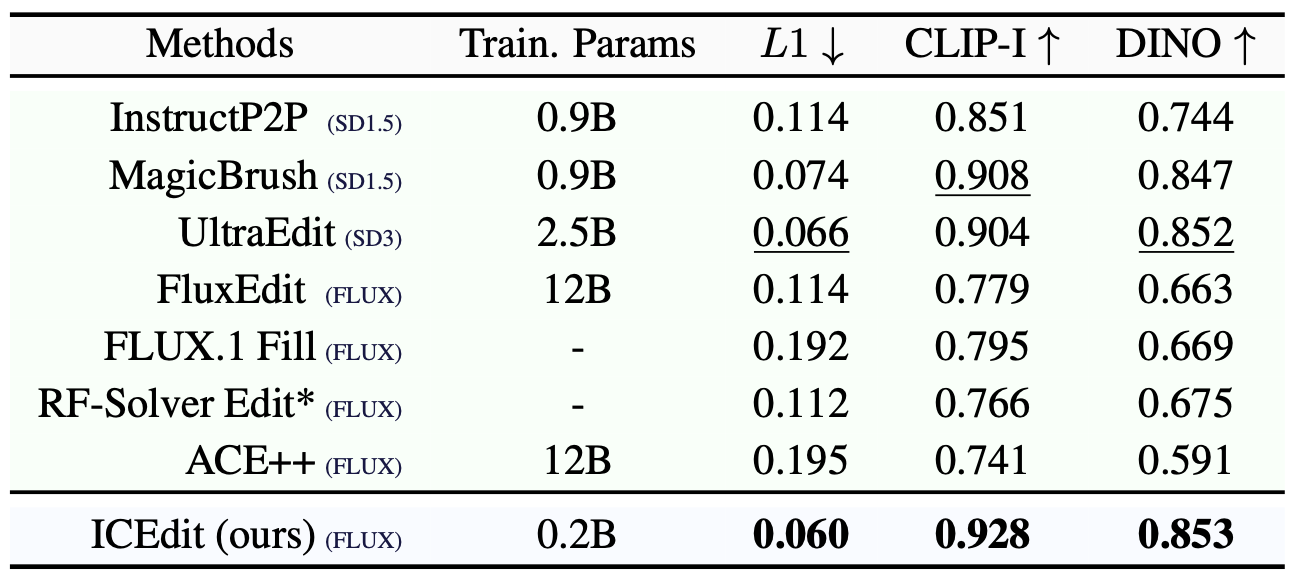
Parameters
우선, 가장 눈에 띄는 점은 데이터 효율성의 극적인 향상입니다. ICEdit 모델은 기존 방법들 대비 극히 일부인 약 0.5%의 훈련 데이터만을 사용하고도, 최신의 다른 방법들보다 우수한 성능을 달성했습니다. 또한 미세조정에 필요한 가중치 양도 기존 대비 1% 수준에 불과했습니다. 이를 통해 정밀도와 효율성을 모두 잡았다는 것을 알 수 있는데요, 불과 5만 장 정도의 공개 데이터로 훈련하여 거둔 성과라는 점은 놀랍습니다 (타 방법들은 수백만 장 이상의 데이터로 훈련됩니다). 다시 말해, ICEdit는 0.5%의 데이터와 1%의 파라미터로 기존 최첨단 방법들을 능가했다고 요약할 수 있습니다.
실제 예시를 통해 결과를 확인해보겠습니다. 아래 그림은 ICEdit를 이용한 다단계 이미지 편집의 한 사례입니다. 원본 이미지에서 시작해, 단계별로 연속적인 지시를 주었을 때 어떻게 변해가는지를 보여줍니다.
이 예시에서 볼 수 있듯이, ICEdit는 여러 번의 편집 지시를 연달아 받아도 각각을 정확히 수행하면서 이전 변경 내용도 잘 보존합니다. 처음에는 네자(Ne Zha) 캐릭터였지만 나중에는 스폰지밥 캐릭터로 완전히 바뀌고, 배경과 분위기도 바뀌었지만, 지시한 부분 외에는 불필요한 변경이 없었고 원하는 효과들이 단계마다 제대로 적용되었습니다.
특히 ID 일관성(인물의 동일성 유지) 면에서 GPT-4o 모델보다도 우수하다는 언급이 있을 정도로, ICEdit는*지시를 따른 수정과 비지시 영역 보존을 모두 잘 해냅니다.
또한, 단일 단계 편집에서도 다양하고 어려운 편집 작업들을 높은 품질로 수행해냈습니다. 예를 들어 사람 사진에 대해 머리 색을 바꾸거나 (예: 갈색 -> 초록머리), 액세서리를 추가 (예: 귀걸이, 왕관), 주변 환경을 바꾸거나 (실내 -> 해변), 화풍을 변경 (실사 -> 수채화 스타일) 하는 등의 상당히 서로 다른 종류의 편집들을 모두 한 모델이 해낼 수 있었습니다. 아래 그림은 한 인물 사진에 대한 여러 가지 편집 결과를 시각적으로 보여줍니다.
보시다시피, ICEdit는 하나의 인물 이미지에 대해서도 색상, 사물 추가, 배경 변화, 스타일 변환 등 다양한 요구를 뛰어나게 수행합니다. 중요한 점은 이 모든 것이 하나의 통합된 모델로 이루어졌으며, 특정 작업마다 별도의 전문 모델이 필요한 것이 아니라는 것입니다. 이는 앞서 설명한 LoRA-MoE 전략 덕분에 한 모델이 여러 전문가의 능력을 겸비하게 되었기 때문입니다. 예를 들어 머리 색 변경과 화풍 변환은 성격이 다른 작업인데도, ICEdit 모델 내에서는 알아서 다른 전문가 경로를 사용하여 둘 다 훌륭히 해낸 것이죠.
Early Filter Inference-Time Scaling을 적용했을때와 단순히 고정된 seed로 생성했을 때를 비교했을때도 확실히 Inference Scaling에서 instruction 텍스트을 가잘 잘 반영한 초기 latent를 선택하여 최선의 방향으로 이미지를 생성했기 때문에 instruction을 더 잘 반영한 것을 볼 수 있습니다
마지막으로 속도와 자원 측면에서도 ICEdit는 실용적인 장점을 지닙니다. 연구팀에 따르면, 이 모델은 한 장의 이미지를 편집하는 데 약 9초 정도밖에 걸리지 않으며, 필요한 GPU 메모리도 불과 4GB VRAM 수준이면 충분하다고 합니다. 이는 거대 모델이면서도 경량화에 성공했다는 뜻이죠. 요즘 고성능 그래픽카드가 없어도 일반 PC에서 돌아갈 수 있는 수준이니, 향후 많은 사용자가 쉽게 활용할 수 있으리라 기대됩니다.
종합하면, ICEdit는 매우 적은 자원으로도 뛰어난 편집 성능을 내는 혁신적인 프레임워크임이 다양한 실험을 통해 입증되었습니다. 여러 실제 예시와 수치 결과가 이를 뒷받침하고 있으며, 정밀한 지시 수행, 다양한 편집 적용, 높은 효율이라는 결과를 내었습니다.
Test on ComfyUI
Installation
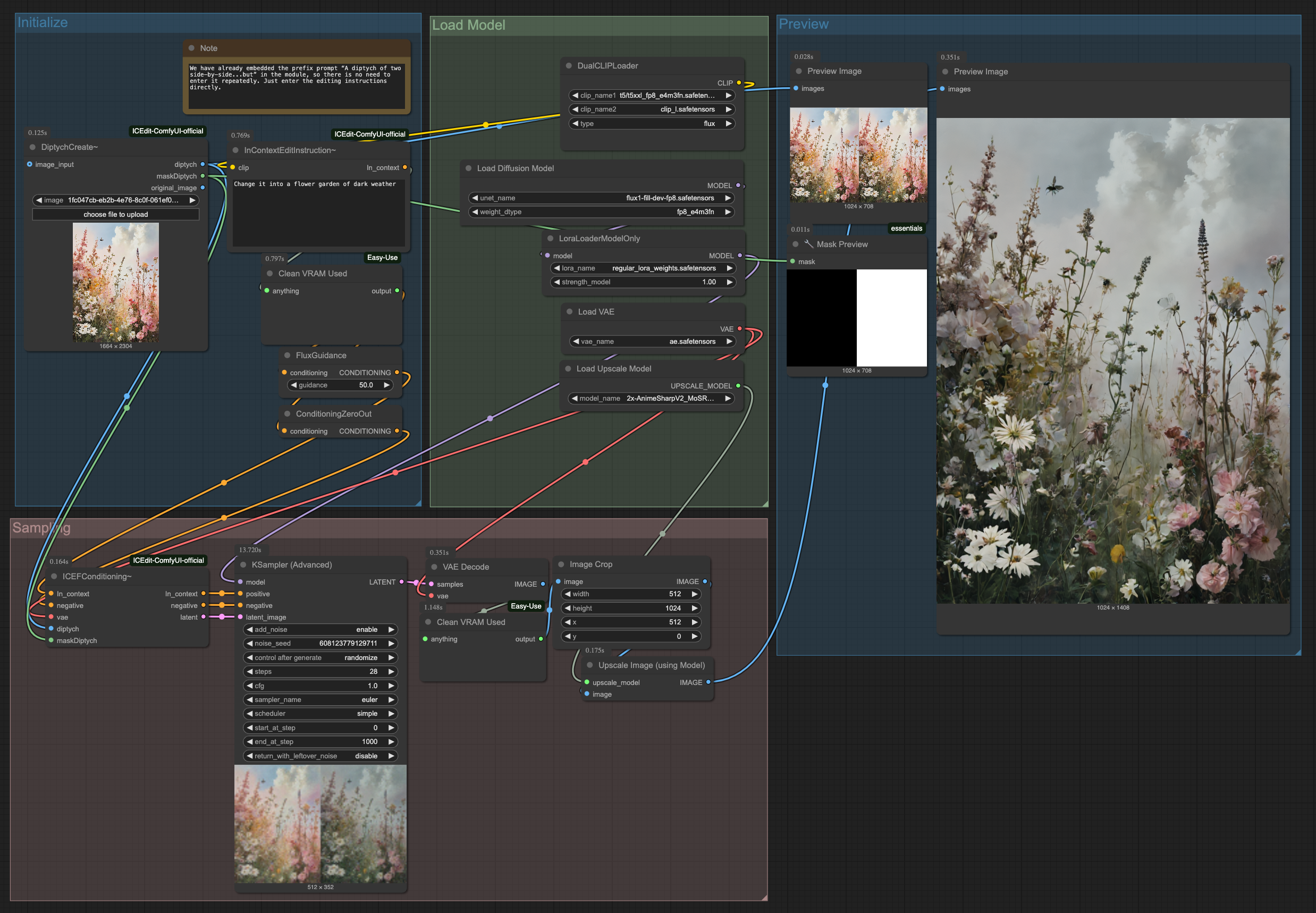
ComfyUI에서 ICEdit을 사용하려면 ICEdit-ComfyUI-official의 가이드를 따라 커스텀 노드를 설치하고 ICEdit-normal-LoRA를 다운로드 받아 ComfyUI/models/loras 경로에 저장하면 됩니다.(더 자세한 내용은 GitHub repo를 참고해 주세요.)
기존에 Flux-fill 관련 워크플로우와 매우 유사하니 쉽게 적용할 수 있습니다.
workflow
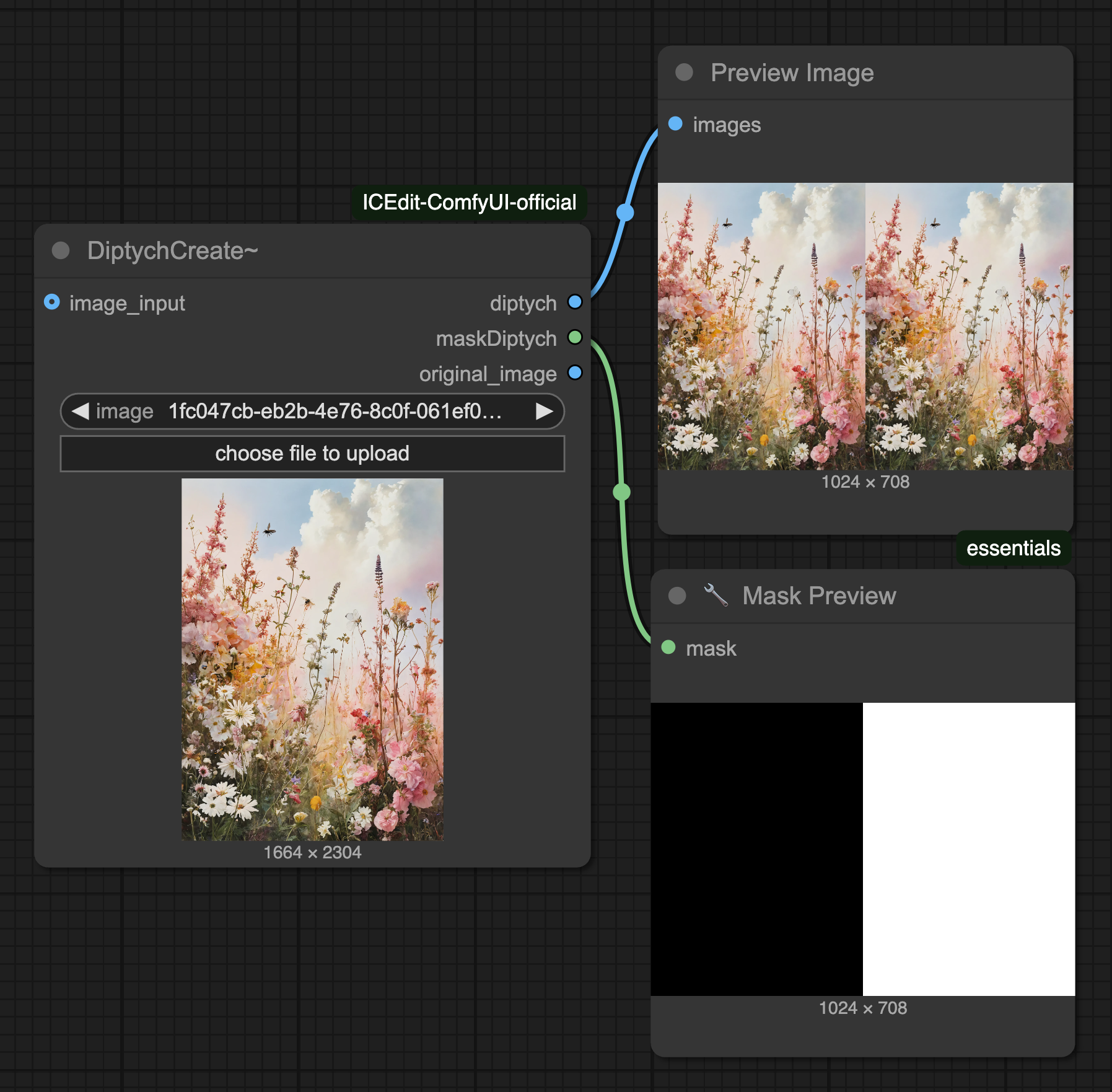
DiptychCreate
논문 내용에 언급된 것 처럼 ICEdit은 왼쪽에 원본(입력) 이미지, 오른쪽에 변화할 이미지가 입력되어야 하며 마스크도 마찬가지로 오른쪽 영역이 편집될 영역이므로 흰색으로 마스킹을 해야합니다. DiptychCreate 노드는 이 전처리 작업을 수행해주며 입력 이미지 사이즈를 1024 스케일로 자동 변환합니다.
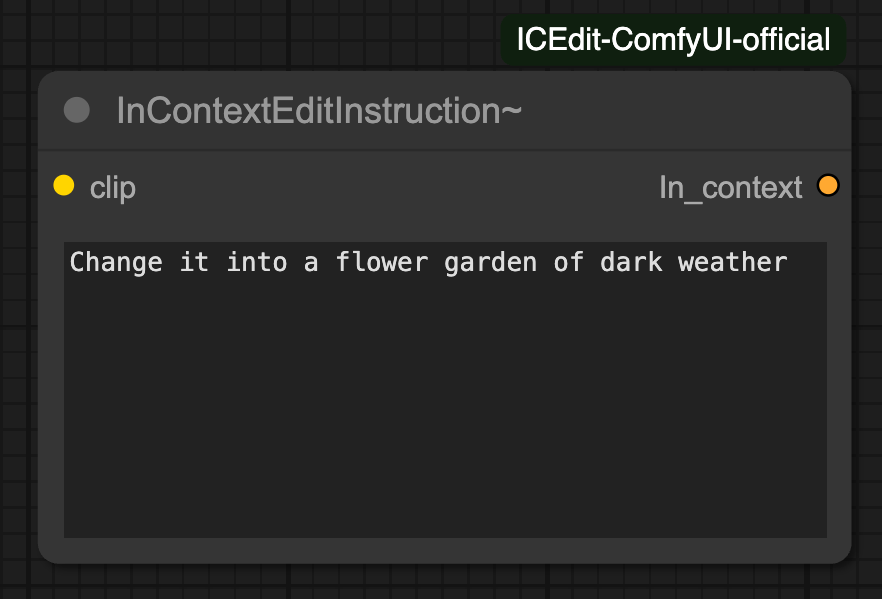
InContextEditInstruction
ICEdit은 학습할때 "A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}" 이라는 pre-prompt를 사용했습니다. 그렇기 때문에 inference에서도 이 pre-prompt가 반드시 필요합니다.(LoRA의 Trigger word 라고 이해하시면 됩니다.)
InContextEditInstruction 커스텀 노드에는 내부적으로 해당 pre-prompt가 내장되어 있기 때문에 해당 노드를 사용할때는 원하는 instuction만 작성하면 됩니다.
일반적인 CLIP Text Encode 노드를 사용하신다면 pre-prompt를 반드시 입력해주세요.
Results
Change it into a flower garden of dark weather

Original

Result
What would it look like if the dog’s nose was red and horn instead of the ear like Rudolph?

Original

Result
What would it look like if the dog’s nose was red and horn instead of the ear like Rudolph?
여러 가지 테스트를 진행해본 결과, 전체 스타일을 변경하거나 특정 요소 하나만 바꾸는 작업은 비교적 잘 작동했습니다. 다만, 위 루돌프처럼 강아지의 코 색상을 바꾸고 뿔 추가하려고 했을 때에는 원하는 결과가 바로 나오지 않고, 강아지 전체가 빨간색으로 변하려는 경향이 있었습니다. attention이 코와 뿔로 분산되어야 하는데 강아지 전체에 집중되는 느낌이었습니다.
가장 인상적이었던 점은 기존의 inpainting 방식에 비해 마스크 자국이 거의 남지 않는다는 것이었습니다. 이전 방식은 편집하고 싶은 영역을 직접 마스크로 지정해야 했고, 이로 인해 마스크 라인이 남아있는 결과가 종종 발생했습니다. 반면, 이 방식은 보다 자연스럽고 매끄러운 편집이 가능해 보입니다.
하지만 아쉬운 점도 있습니다. 두 이미지를 나란히 배치한 뒤 입력으로 사용하는 구조 때문에, 편집하려는 이미지의 가로 길이가 너무 길어질 경우 결과물이 좋지 않게 나오는 문제가 있었습니다. 이는 base model(flux)이 16:9나 9:16을 초과하는 비율의 이미지에 대해 충분히 학습되지 않았기 때문으로 보입니다.
이러한 한계로 인해 실제 이미지 편집 작업에 바로 적용하기에는 어려움이 있지만, 재미있는 기능으로 활용하기에는 충분히 매력적인 성능을 보여주었습니다.
Conclusion
지금까지 In-Context Edit(ICEdit) 논문의 핵심 내용에 대해 살펴보았습니다. 논문을 보면서 입,출력방식(나란히 배치하는 방식)이 6개월전에 발표된 object를 이미지에 추가하는 방식의 In-Context LoRA와 동일해서 조금 아쉬웠습니다.
하지만 IC-LoRA는 작업별로 LoRA 파일을 별도로 사용해야하지만 ICEdit은 MoE 라우터가 적절한 LoRA 모듈을 알아서 사용한다는 접근과 Early-Filter방식으로 초기에 최적의 시드를 찾아내는 방식은 매우 인상적이었습니다.
최근 GPT-4o 기반 이미지 생성 기술이 등장하면서 이미지 편집 관련 연구도 활발히 진행되고 있는 만큼 앞으로의 Image Edit의 행보가 기대되네요.
Keep going
Project Page:https://river-zhang.github.io/ICEdit-gh-pages/
Paper: https://arxiv.org/pdf/2504.20690
GitHub: https://github.com/River-Zhang/ICEdit
Intro
With the recent announcement of GPT-4o’s image generation capability, generating and sharing a wide variety of images has become a cultural trend. Although image generation has been around for quite some time, the official launch through ChatGPT — the most familiar tool for the general public — has made this technology accessible to everyone.
“Make this photo look like it’s from a Studio Ghibli film.”
Original
Ghibli Style
Why did the trend of transforming photos into Ghibli-style become so popular? I believe it’s because, among the many image generation outputs, the Ghibli-style transformations stood out with particularly high quality — even before it became a meme.
Starting from scratch or transforming an image’s entire style (like with the Ghibli meme) can produce impressive results. However, selectively editing specific parts of an image while keeping everything else intact remains a difficult task.
Instructions like “change only the hair color slightly, keep the background the same, and preserve the facial expression” require highly sophisticated editing capabilities.
In this context, a new research paper called In-Context Edit was recently published. It tackles this challenge by leveraging the contextual understanding capabilities of large-scale Diffusion Transformers.
The result? Without having to retrain on millions of edited image samples or radically modify the model architecture, the researchers achieved highly precise image editing using relatively small datasets and parameter tweaks — all while retaining GPT-4o-level language comprehension.
In this post, we’ll explore the core concepts behind In-Context Edit and share hands-on testing results using ComfyUI.
Introduction
Instruction-based image editing is a technology that enables users to modify images simply through natural language commands. For instance, commands like “Change this person’s hair color to blonde” or “Make the background look like a sunset” allow for detailed modifications with minimal effort.
The biggest advantage of such command-driven image editing is that very little textual input can still result in highly specific visual output. This opens new doors for automated image editing and user-driven content creation, which is why it has attracted significant attention from both academia and industry in recent years.
However, current image editing methods are caught in a dilemma between precision and efficiency. Traditionally, two main approaches have been used:
-
Fine-Tuning-Based Methods: These involve retraining a large pre-trained diffusion model on massive editing datasets to teach it how to follow specific instructions. This approach often achieves high accuracy, but at a steep cost: retraining a model for each new task requires hundreds of thousands to millions of image samples and massive computational resources. Sometimes, the model architecture must be modified or extended to improve performance. It’s akin to training a highly skilled editor from scratch — extremely expensive and time-consuming.
-
Training-Free (zero-shot) Methods: Alternatively, some approaches attempt to edit images without any additional training by leveraging pre-trained models.
-
Image inversion:
- This involves mapping an input image into the model’s latent space.
- Once mapped, the latent vector can be used to reconstruct the original image or generate variations through latent manipulation.
-
Prompt swapping:
- This technique rephrases the instruction into a generic descriptive prompt.
- e.g., “Change the cat into a dog” → “A dog sitting on a sofa”.
-
Manipulating attention:
- During image generation, the attention paid to each word in the prompt is manually adjusted to control the output.
- If you only want to change the color of a “sofa,” you manually tweak the attention weights associated with the word “sofa.”
-
These methods are relatively fast and simple because they don’t require retraining, but they often lack understanding of the instruction or fail to deliver the desired quality.
Fine-tuning yields high precision but suffers from extreme cost and time requirements, while training-free methods are simple and quick but can result in poor comprehension or subpar image edits.
Fortunately, the rise of large-scale Diffusion Transformers (DiT) is beginning to offer a way forward. DiTs combine immense generative power with strong contextual understanding, making them a promising solution to the trade-off between precision and efficiency.
The In-Context Edit study introduced here presents a novel method that harnesses the capabilities of Diffusion Transformers to achieve accurate, efficient instruction-based image editing with minimal data and parameter changes.
In-context Edit
The newly proposed In-Context Edit (ICEdit) adopts a clever strategy to enable models to follow editing instructions without additional training. The key idea is to leverage context — by presenting the model with before-and-after examples of edits, it learns to infer and apply the transformation on its own.
Specifically, the study designs a special kind of prompt. For example:
“There are two side-by-side images. On the left is the original image described as {detailed description}. On the right is the same image, but with {editing instruction} applied.”
In this case, the left side receives the original image, while the right side is what the model must generate. This setup allows the model to understand both the original and the edited context simultaneously from a single prompt.
What’s remarkable is that the model performs editing without any architectural changes. By referencing the original context on the left, the model naturally learns which parts to keep and which to change. Since the model sees both the “before” and “desired after” context, it can make precise edits without unnecessary changes.
This framework is implemented in two variations:
In summary, the In-Context Edit framework injects editing capabilities into the model through a clever use of instructional context, eliminating the need for additional training.
LoRA-MoE Hybrid Fine-tuning
The second core component of In-Context Edit is the LoRA-MoE hybrid tuning strategy. Here’s what LoRA and MoE mean:
-
LoRA (Low-Rank Adaptation): A technique designed to fine-tune large models efficiently. Instead of updating all the weights of a massive model, LoRA adds small modules (low-rank matrices) with only a few trainable parameters to subtly adjust the model’s output. Since only around 1% of the original model’s parameters need to be learned, it’s highly efficient.
-
MoE (Mixture of Experts): This refers to a model structure that contains multiple ‘expert’ sub-models, and dynamically selects the most suitable expert for a given input. Rather than processing everything with a single massive brain, it uses multiple smaller brains specialized in different tasks, choosing the best one for the situation. For example, one expert might excel at color editing, while another is specialized in object insertion. MoE uses a router to determine, based on the input, which expert to activate.
The LoRA-MoE hybrid strategy combines these two approaches. In In-Context Edit, the Diffusion Transformer model incorporates an MoE structure enhanced with LoRA adapters. Specifically, several expert blocks are placed in selected layers of the DiT model, and each expert is augmented with a LoRA adapter. A trainable routing classifier is also added, which decides which expert to activate based on visual token content or text embedding.
Thanks to this LoRA-MoE hybrid tuning, the In-Context Edit model achieves remarkable editing performance and flexibility with minimal fine-tuning. Most importantly, it can adapt to new editing tasks without the need for extensive retraining, making it highly practical.
Early Filter Inference-Time Scaling
The final key technique is Early Filter Inference-Time Scaling — a method that enhances the image generation process itself during inference to improve editing quality.
To understand this, recall that diffusion models generate images by gradually removing noise to reconstruct the desired output. The initial noise conditions often have a significant impact on the final image. Early Filter Inference-Time Scaling aims to cleverly manage this early stage.
It uses a Vision-Language Model (VLM) — such as CLIP — which can score how well a given image matches a text description or instruction. In In-Context Edit, such a VLM acts as a quality assessor for editing results.
Here’s how it works:
-
When the diffusion model starts generating an image, it can begin from multiple initial noise seeds. That means it can create several early-stage images using different seeds.
-
These early-stage images are evaluated using the VLM to determine how well they match the editing instruction and how good their quality is, even before the final image is produced — like glancing at a sketch and judging whether it’s headed in the right direction.
-
Then, the system selects the most promising candidate and either discards or scales back the others. Since the selected candidate has a well-aligned initial noise distribution, continuing the diffusion process will more likely yield a high-quality, instruction-faithful result.
By filtering early, the model avoids progressing in a wrong direction and eliminates the need to correct errors later. It’s far better to start with a good base than to fix a mismatch at the end.
This Early Filter Inference-Time Scaling significantly improves editing accuracy and consistency. It ensures that paths which don’t align with the instruction are eliminated early, allowing the model to focus on the most plausible path. Moreover, this method is flexible — you can adjust the number of candidates or the strength of the selection criteria — making it more robust. According to the study, this scaling approach resulted in noticeable improvements across editing performance metrics, which we’ll now explore in the experiment section.
Experiments
Let’s now examine how effective In-Context Edit (ICEdit) really is, based on experimental results. The researchers evaluated ICEdit using various benchmark datasets and metrics, and the outcomes were highly impressive.
Data
Parameters
The most striking result is the dramatic improvement in data efficiency. The ICEdit model used only about 0.5% of the training data required by prior methods and still outperformed the latest state-of-the-art models. The amount of fine-tuned weights was also only about 1% of the total parameters, confirming that ICEdit achieved both precision and efficiency. Notably, it was trained using only around 50,000 publicly available images, while competing methods often require millions. In short, ICEdit beat cutting-edge methods using only 0.5% of the data and 1% of the parameters.
Let’s look at a concrete example. The image below shows a multi-stage editing process using ICEdit, where a sequence of editing instructions are applied progressively starting from the original image.
As shown, ICEdit accurately performs multiple consecutive edits while preserving prior changes. It starts with a Ne Zha character, then transforms into SpongeBob, with changes in background and mood as well. All edits were applied as instructed, with no unintended modifications, showing that the model precisely followed each command.
ICEdit even outperformed GPT-4o in ID consistency — maintaining the identity of characters during editing — which highlights its excellent instruction adherence and preservation of non-targeted areas.
For single-step edits, ICEdit also handled a wide range of complex tasks with high quality, such as changing hair color (e.g., brown → green), adding accessories (e.g., earrings, crown), changing environments (indoor → beach), or switching artistic styles (photo → watercolor). Below is a visual of multiple edits performed on a single portrait.
As you can see, ICEdit handles color shifts, object additions, background swaps, and style changes — all with a single unified model. It doesn’t need separate expert models for each task. This is possible thanks to the LoRA-MoE strategy, which equips the model with diverse expert pathways. Tasks as different as hair recoloring and artistic transformation are handled by activating different expert blocks, all within the same model.
When comparing results with and without Early Filter Inference-Time Scaling, it is clear that this technique allows the model to select an initial latent path that best reflects the instruction text, resulting in far more faithful generations than with a fixed seed alone.
Lastly, ICEdit offers practical advantages in speed and resource use. According to the researchers, the model can edit an image in around 9 seconds and only requires 4GB of VRAM, making it a lightweight yet powerful solution. This means that even without high-end GPUs, users could eventually run ICEdit on standard PCs — opening up accessibility to a wider audience.
In conclusion, ICEdit is a groundbreaking framework that delivers powerful image editing with minimal resources. Backed by real-world examples and quantitative results, it demonstrates excellence in instructional accuracy, editing versatility, and computational efficiency.
Test on ComfyUI
Installation
To use ICEdit with ComfyUI, follow the guide provided in ICEdit-ComfyUI-official to install the custom nodes. Then, download ICEdit-normal-LoRA and place it in the ComfyUI/models/loras directory.
(For more details, refer to the GitHub repo.)
It is very similar to the existing Flux-fill workflow, so integration should be straightforward.
Workflow
DiptychCreate
As mentioned in the paper, ICEdit requires the input to be a pair of side-by-side images — the original image on the left, and the target image on the right. The same applies to the mask — the area to be edited must be on the right side and masked in white. The DiptychCreate node performs this preprocessing and automatically resizes the input images to a 1024 scale.
InContextEditInstruction
ICEdit was trained using the pre-prompt:
"A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}".
This pre-prompt is essential during inference as well (you can think of it as the LoRA’s “trigger word”).
The InContextEditInstruction custom node internally includes this pre-prompt, so you only need to input the specific instruction when using this node.
If you’re using a standard CLIP Text Encode node, be sure to manually add the pre-prompt.
Results
Change it into a flower garden of dark weather
Original
Result
What would it look like if the dog’s nose was red and horn instead of the ear like Rudolph?
Original
Result
What would it look like if the dog’s nose was red and horn instead of the ear like Rudolph?
From various tests, we found that both full style transformations and localized edits (changing a single element) generally worked well. However, with more nuanced prompts like the “Rudolph dog” — where we tried changing only the nose color and adding a horn — the model sometimes transformed the entire dog to red instead. The attention seemed to overly focus on the whole dog, rather than isolating the nose and horn as intended.
One of the most impressive aspects was how seamlessly it handled masking, leaving almost no visible mask artifacts. Traditional inpainting methods often left behind visible mask edges due to manual masking. In contrast, ICEdit offered smooth, natural edits.
However, there were limitations. Because the framework requires placing two images side-by-side, wider input images led to degraded results. This appears to be due to the base model (Flux) not being well-trained on extreme aspect ratios like 16:9 or 9:16.
Despite these drawbacks, ICEdit showed promising and entertaining performance — though it may not yet be ready for production-level editing, it’s certainly a fun and powerful tool to experiment with.
Conclusion
We’ve now explored the core ideas behind the In-Context Edit (ICEdit) paper. While the side-by-side input/output approach reminded me of the In-Context LoRA method for object insertion announced six months ago, and felt somewhat unoriginal…
…ICEdit makes notable innovations — especially in how it uses a MoE router to dynamically select appropriate LoRA modules instead of requiring different LoRA files per task, and in how it uses an Early-Filter strategy to identify the optimal seed path early in inference.
As GPT-4o-based image generation tech continues to evolve, it’s exciting to watch image editing research like this push new boundaries.
Keep going.
Project Page: https://river-zhang.github.io/ICEdit-gh-pages/
Paper: https://arxiv.org/pdf/2504.20690
GitHub: https://github.com/River-Zhang/ICEdit







Leave a comment