Intro
텍스트를 통해 이미지를 생성해주는 diffusion model은 놀라운 결과물로 이미지 생성분야에 붐을 일으켰습니다.
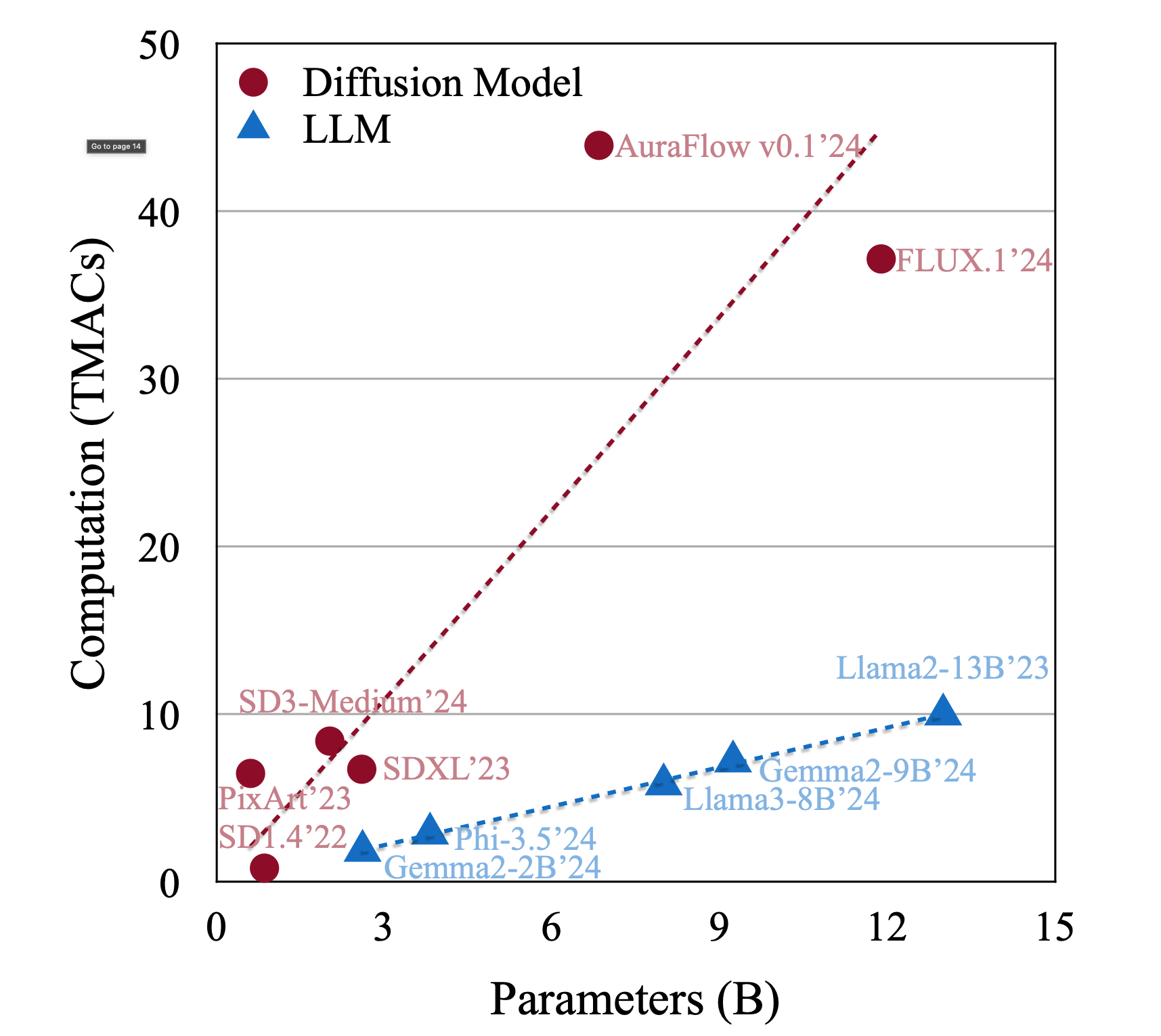
초기 Stable Diffusion 1.4는 약 8억 개의 파라미터로 동작했지만, 이제 최신 모델들은 수십억 파라미터 규모로 확장되어 더욱 정교하고 자세한 이미지를 만들어낼 수 있습니다.
품질 향상을 위해 이러한 초거대 모델들이 등장했지만, 동시에 막대한 메모리와 연산량을 요구하여 속도가 느려지고 실시간 활용이 어려워지는 문제가 있습니다.
computation vs parameters
한편, 하드웨어 발전이 예전만 못해지자(소위 무어의 법칙 둔화), 낮은 정밀도의 연산으로 효율을 높이려는 시도가 늘고 있습니다.
실제로 최신 GPU 아키텍처(예: NVIDIA Blackwell)에서는 4비트 부동소수점(FP4) 연산을 지원하기 시작했습니다.
양자화(Quantization)란 이런 낮은 비트로 데이터 표현 범위를 줄여 연산을 가볍게 하는 기법입니다.
거대한 언어 모델(LLM)에서는 주로 가중치만 8비트 등으로 줄여 모델 크기와 메모리를 감소시켜 왔습니다.
하지만 diffusion model은 상황이 조금 달라서, 단순히 가중치만 줄여서는 속도 향상이 제한적입니다. 이미지 생성 모델은 연산량 자체가 많아, 가중치뿐 아니라 활성화 값(중간 계산 결과)도 동일하게 낮은 비트로 줄여야 진정한 가속 효과를 얻을 수 있습니다.
그렇지 않고 한쪽만 낮추면 연산 시 다시 높은 정밀도로 변환되기 때문에 실익이 없어집니다.
요컨대 “4비트 모델”이라고 하려면 가중치(weight)와 활성값(activation) 모두 4비트여야 합니다.
4비트 양자화가 어려운 이유?
4비트라는 것은 데이터를 16단계(2^4) 정도의 구분으로 표현한다는 뜻입니다.
이렇게 표현 범위가 작으면, 원래 값들 중 튀는 값(이상치, outlier)이 있을 때 심각한 문제가 됩니다.
예를 들어, 대부분 값이 1~10 사이인데 몇 개가 100에 가까운 경우, 이 큰 값들 때문에 전체 범위를 맞추면 나머지 값들의 표현이 엉망이 되거나 큰 값들은 잘릴 수 있습니다.
마치 키가 훨씬 큰 학생 몇 명 때문에 옷 치수를 모두 크게 맞춰야 해서, 다른 학생들에게는 옷이 너무 헐렁해지는 격이죠.
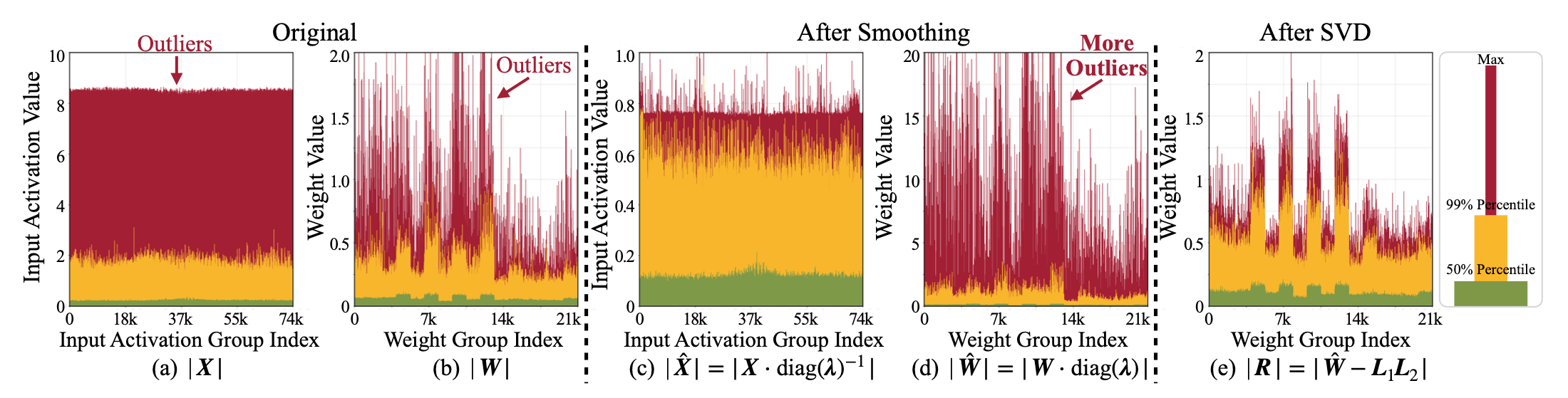
실제 확산 모델의 가중치 W나 활성값 X 분포를 보면 드물지만 매우 큰 값들이 존재하여 4비트로 그대로 양자화하기 어렵게 만듭니다.
이러한 극단적인 값들이 양자화 오차를 크게 만들어 자칫 생성되는 이미지 품질이 급격히 떨어질 수 있습니다.
이 문제를 완화하기 위해 제안된 기존 방법 중 하나가 SmoothQuant와 같은 “스무딩” 기법입니다.
이 접근법은 간단히 말해, 활성값의 이상치를 가중치 쪽으로 이전시켜(active→weight) 전체 분포를 완만하게 만드는 것입니다.
이렇게 하면 활성값 쪽의 범위는 좁아져 4비트 표현이 한결 수월해지지만, 대신 가중치 쪽에 이상치 부담이 몰리게 되는 단점이 있습니다.
결국 한쪽 문제를 다른 쪽으로 떠넘긴 셈이라, 4비트라는 극단적인 조건에서는 여전히 부족합니다.
다시 비유하자면, 교실의 키 큰 학생들을 한 반에서 다른 반으로 옮겼더니 옮겨간 반에서 문제가 되는 상황입니다.
이 딜레마를 해결하기 위해 SVDQuant가 등장하게 되었습니다.
SVDQuant
SVDQuant는 4비트 양자화를 위한 완전히 새로운 발상으로, 문제의 이상치들을 아예 별도로 처리할 “저랭크(low-rank) 분기”를 추가하는 방법입니다. 복잡한 수식을 떠나 개념을 풀어 보면, 기존 모델에 작지만 고급스러운 보조 회로를 하나 더 붙이는 것입니다.
이 보조 회로는 소수의 극단적 값을 16비트 고정밀도로 전담 처리하고, 나머지 대부분의 값들은 본래 모델이 4비트로 처리하도록 역할을 분담합니다.
이렇게 두 부분이 협력하여 최종 결과를 합치면 전체적인 정확도를 유지하면서도 4비트의 이점을 살릴 수 있게 됩니다.
SVDQuant는 먼저 앞서 말한 스무딩 단계를 거쳐 활성값의 이상치를 가중치로 옮겨둡니다. 그 결과 얻은 새로운 가중치 W_hat에는 이상치 영향이 크게 실리게 되는데, 다음으로 SVD(특이값 분해)라는 기법을 활용해 이 W_hat을 두 부분으로 쪼갭니다.
하나는 W_hat의 low-rank 구성요소로, 쉽게 말해 W_hat에서 가장 에너지(변동성)가 큰 축 몇 개만 뽑아낸 부분입니다.
나머지는 그걸 제외한 잔여(residual) 부분으로 보면 됩니다.
흥미롭게도, 큰 모델의 가중치를 SVD로 들여다보면 대부분의 영향력은 소수의 특이값(주요 성분)에 몰려있다는 것이 알려져 있습니다.
SVDQuant는 이 점을 이용하여, 가장 큰 특이값들로 이루어진 low-rank 부분을 16비트 고정밀도로 처리하도록 빼내버립니다.
이렇게 지배적인 성분들을 제거하고 나면 W_hat의 남은 부분은 전체 크기 범위나 이상치가 크게 줄어들기 때문에 4비트로 양자화하기 한결 수월해집니다.
결국 low-rank 분기가 양쪽(가중치와 활성값)의 양자화 난이도를 모두 흡수해 완화시켜 주는 효과를 내는 것이죠.
이 아이디어 덕분에, SVDQuant 적용 후의 모델은 4비트로 표현해도 원본에 가까운 이미지 품질을 유지할 수 있습니다.
Nunchaku
SVDQuant로 알고리즘적인 문제를 풀었다면, Nunchaku는 이를 실제 시스템 성능 측면에서 최적화하는 비법입니다.
두 개의 분기가 협력한다고 했지만, 이를 컴퓨터에서 단순하게 구현하면 오히려 속도가 느려질 수도 있습니다.
왜냐하면 low-rank 분기와 4비트 분기가 각자 별도로 동작할 경우, 동일한 입력 데이터에 대해 두 번 계산하고 메모리에도 두 번 접근해야 할 수 있기 때문입니다.
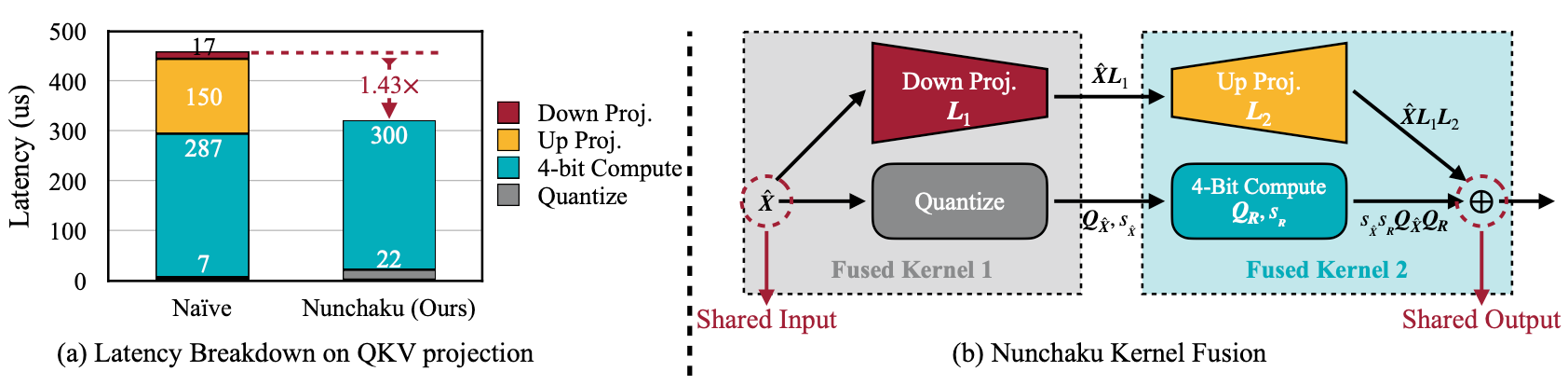
논문 저자들의 분석에 따르면, 보조 분기를 별개로 돌리면 4비트 분기 단독 대비 추로 지연이 약 50%나 발생할 수 있다고 합니다.
low-rank로 계산량 자체는 크지 않지만, 입출력 활성값의 데이터 이동이 병목이 되는 것이죠.
Nunchaku는 SVDQuant와 함께 설계된 맞춤형 추론 엔진으로, 두 분기의 연산을 똑똑하게 한데 묶어 이중 작업을 없애줍니다. 구체적으로는, low-rank 분기의 다운 프로젝션(low-rank로 입력을 투영하는 연산)이 메인 4비트 연산과 동일한 입력을 사용하므로 이를 하나의 커널로 합치고, low-rank 분기의 업 프로젝션(low-rank 결과를 출력으로 합치는 연산)도 메인 4비트 연산의 출력 단계와 결합해 동시에 처리합니다.
이렇게 두 경로가 입출력을 실시간으로 공유하게 되면, 원래 따로 계산할 때 필요했던 불필요한 메모리 왕복을 제거하고 커널 호출 횟수도 절반으로 줄일 수 있습니다. 그 결과 보조 분기가 추가로 차지하는 시간은 전체의 5~10% 수준에 불과하게 되어 성능 영향이 거의 무시될 정도가 되었습니다.
비유하자면, 두 갈래로 나뉘었던 작업을 하나의 생산라인으로 통합해 두 번 하던 일을 한 번에 끝내는 셈입니다. 재미있게도 Nunchaku(쌍절곤)는 두 개의 막대가 연결된 무기인데, 여기서도 두 연산 분기를 하나로 묶어 처리한다는 의미를 담은 이름인 듯합니다.
또한 Nunchaku 덕분에 최근 확산 모델에서 널리 쓰이는 LoRA와의 호환성도 좋아졌습니다. LoRA는 사전 학습된 모델에 저랭크로 새로운 스타일이나 기능을 추가하는 기법인데, 기존 양자화 방식에서는 LoRA를 적용하면 모델을 다시 양자화해야 하는 번거로움이 있었습니다.
반면 SVDQuant + Nunchaku 조합에서는 이러한 저랭크 추가 분기를 자연스럽게 받아들일 수 있어, 훈련된 LoRA 모듈을 그대로 붙여 써도 문제가 없습니다. 이는 사용자가 다양한 스타일의 LoRA를 4비트 모델에 손쉽게 적용할 수 있다는 의미이기도 합니다.
Experiments
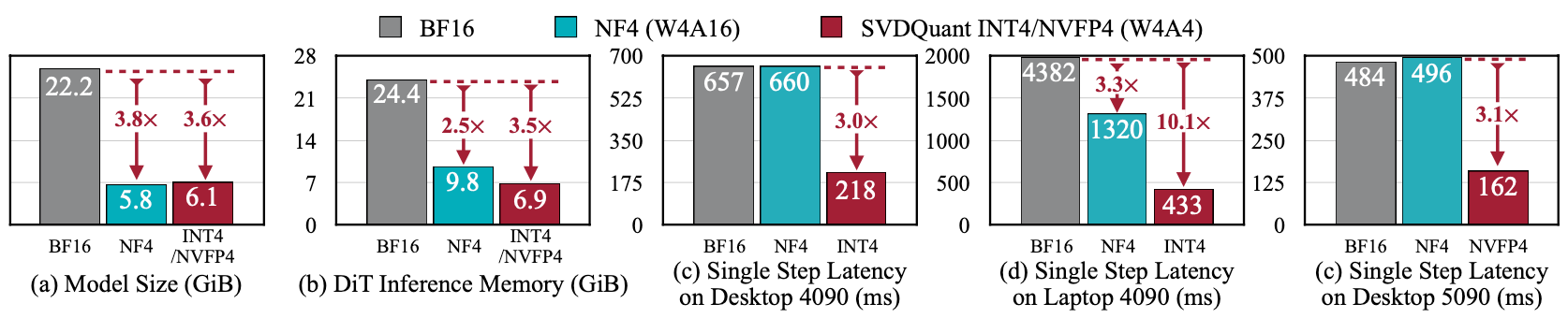
제안된 SVDQuant와 Nunchaku의 효과는 다양한 대규모 확산 모델 실험에서 입증되었습니다. 우선 모델 크기와 메모리 사용량 측면에서 획기적인 개선이 나타났습니다. 저자들은 파라미터 약 120억 개 규모(12B)의 FLUX.1 모델을 대상으로, 16비트 부동소수점(BF16) 기반 원본과 4비트 SVDQuant 모델을 비교했습니다.
그 결과 SVDQuant 적용 4비트 모델은 메모리 사용량이 약 3.6배 감소하여 동일한 GPU 메모리에서 훨씬 큰 모델을 다룰 수 있게 되었습니다. 더욱이 Nunchaku 최적화까지 적용하면, 16비트 모델 대비 메모리 사용을 총 3.5배로 줄일 수 있었고, 이전의 4비트 가중치만 양자화한 기준 모델(W4A16)보다도 추론 속도가 3.0배 빨라지는 놀라운 성능 향상을 보였습니다. 쉽게 말해, 동일한 하드웨어로 3배 빠르게 이미지 생성을 할 수 있다는 뜻입니다.
흥미로운 점은, 이러한 최적화로 소비자용 GPU에서도 초대형 모델을 구동할 수 있게 되었다는 것입니다. 예를 들어 16GB 메모리의 랩탑용 RTX 4090 GPU에서 원래 16비트 FLUX.1 모델을 돌리면 메모리가 부족해 일부 데이터를 CPU로 넘겨야 했습니다.
CPU와 GPU 간 데이터를 주고받느라 속도가 크게 저하됐지만, 4비트로 압축한 모델은 모든 연산을 GPU 메모리에 올려둘 수 있었기에 전체 속도가 8배 이상 향상되었고, CPU 오프로딩이 완전히 제거된 경우 최대 10배까지 속도 증진을 달성했습니다. 이는 곧 방대한 확산 모델도 고가의 서버 GPU가 아닌 상대적으로 평범한 GPU 한 장으로 실시간에 가깝게 활용 가능함을 보여줍니다.
생성 이미지 품질 역시 중요한 평가 요소입니다. SVDQuant를 적용한 4비트 모델은 원본 16비트 모델과 비교해봐도 이미지 퀄리티나 텍스트-이미지 일치도에서 큰 차이가 없을 정도로 우수한 성능을 유지했습니다.
또한 PixArt-∑나 SDXL와 같은 다양한 모델들에 대해서도, SVDQuant 4비트 결과는 이전의 4비트 또는 8비트 양자화된 모델들보다 더 뛰어난 시각적 품질을 보여주었습니다.
ComfyUI-nunchaku
Installation
nunchaku를 사용하기 위해서는 README.md 가이드에 따라 nunchaku를 파이썬 가상환경에 설치하고 ComfyUI-nunchaku 커스텀 노드를 설치해야 합니다.
⚠️
주의사항 -
nunchaku는 CUDA 커스텀 연산을 직접 컴파일하기 때문에, 컴파일러와 환경 세팅이 필수입니다. CUDA, python, torch 버전에 신경써 주세요.
설치과정은 README.md 에 자세히 나와있기 때문에 여기서는 생략하겠습니다.
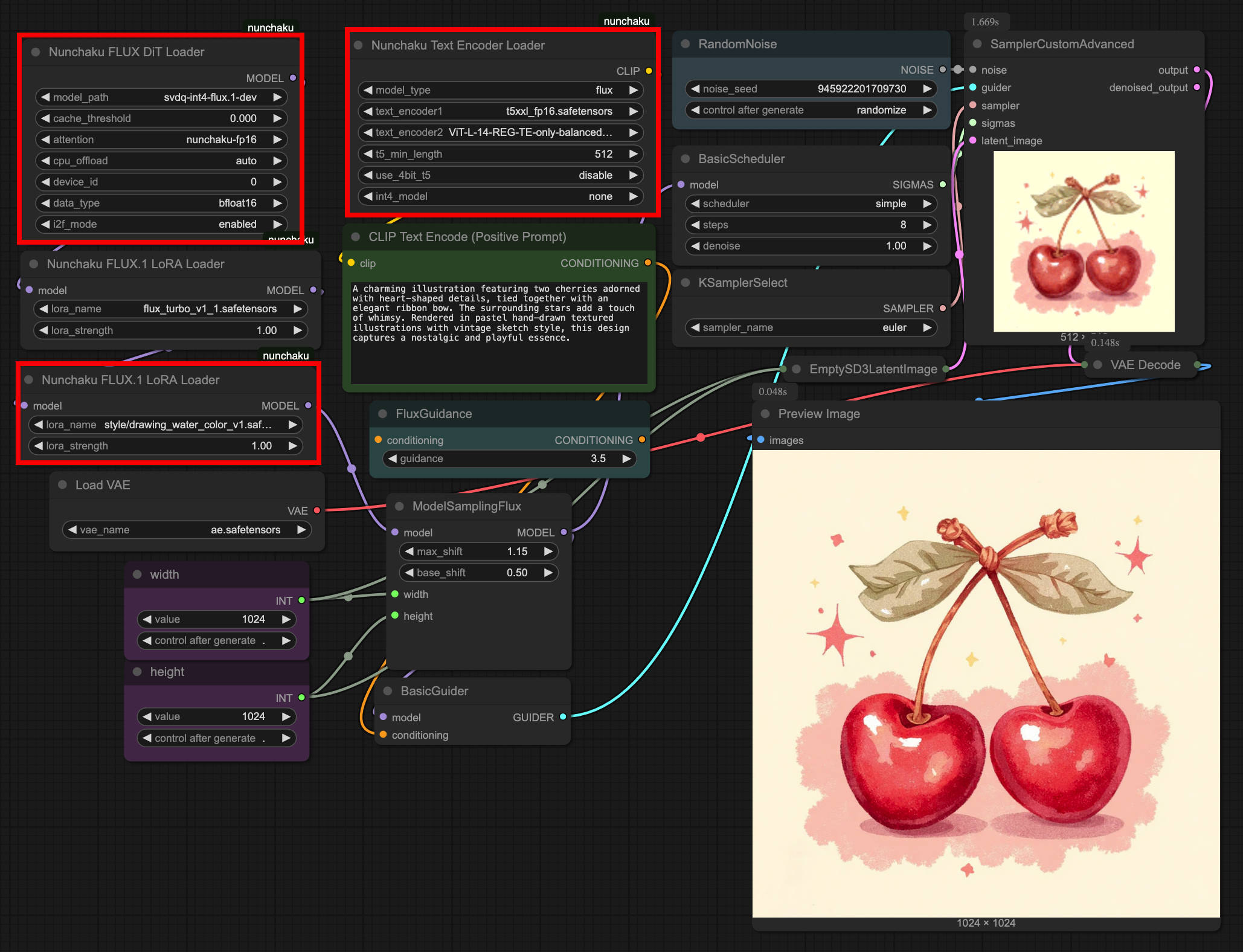
Workflow
nunchaku는 기존 ComfyUI workflow에 아주 쉽게 적용할 수 있습니다. 위 workflow 예시에서 일반적인 Flux 모델을 사용할때와 달라진 점은 Base Model, Text Encoder, 그리고 Lora와 관련된 노드입니다.
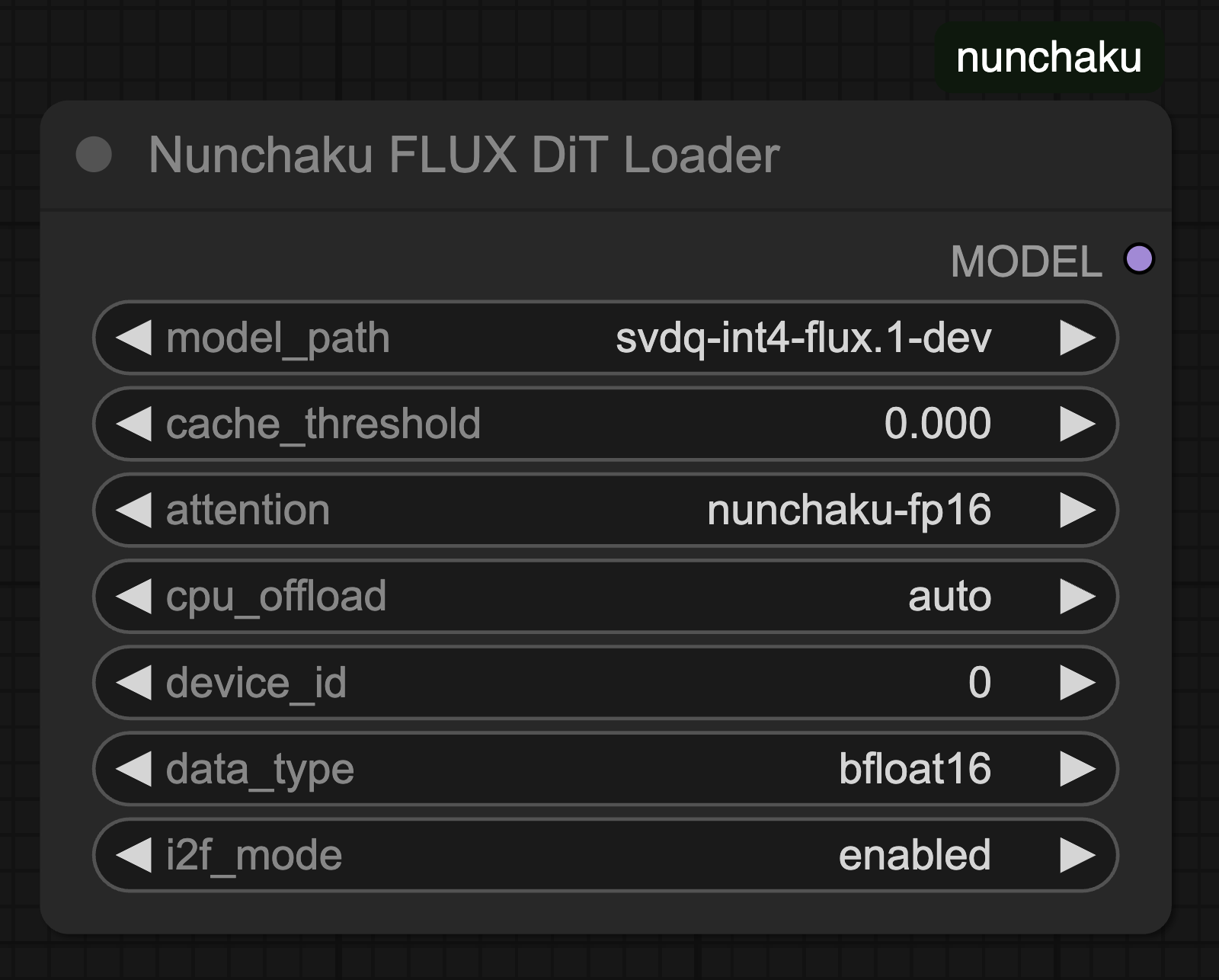
Nunchaku FLUX DiT Loader
- cache_threshold:
- First-Block Cache 허용 오차를 조정하는 값입니다. 이는 WaveSpeed의 residual_diff_threshold와 비슷한 역할을 합니다.
- 값을 높이면 속도가 빨라지지만, 품질이 약간 저하될 수 있습니다. 일반적으로 0.12 정도를 사용하며, 0으로 설정하면 이 기능이 비활성화됩니다.
- attention:
- 어텐션(attention) 연산 방식을 지정합니다.
- flash-attention2 또는 nunchaku-fp16 중 선택할 수 있습니다.
- nunchaku-fp16은 flash-attention2보다 약 1.2배 빠르면서 정밀도는 유지합니다.
- 특히 Turing 아키텍처(GTX 20시리즈) GPU는 flash-attention2를 지원하지 않으므로 반드시 nunchaku-fp16을 사용해야 합니다.
- cpu_offload:
- 트랜스포머 모델 일부를 CPU로 오프로드할지 여부를 설정합니다.
- 이를 활성화하면 GPU 메모리 사용량을 줄일 수 있지만, 추론 속도는 다소 느려질 수 있습니다.
- auto로 설정하면, 사용 가능한 GPU 메모리를 자동으로 감지해서 14GiB 이상이면 오프로드를 비활성화하고, 14GiB 이하이면 활성화합니다.
- (추후 노드(node)에서도 메모리 최적화가 추가로 이루어질 예정입니다.)
- device_id:
- 모델을 실행할 GPU의 ID를 지정합니다.
- (예: 0번 GPU, 1번 GPU 선택)
- data_type:
- 디퀀타이즈(dequantize)된 텐서의 데이터 타입을 지정합니다.
- Turing(20시리즈) GPU는 bfloat16을 지원하지 않으므로, 반드시 float16을 사용해야 합니다.
- i2f_mode:
- Turing(20시리즈) GPU에서 GEMM(일반 행렬 곱셈) 구현 방식을 설정하는 옵션입니다.
- enabled와 always 모드는 약간의 차이가 있지만 대부분 비슷한 성능을 보입니다.
- (다른 아키텍처의 GPU에서는 이 옵션은 무시됩니다.)
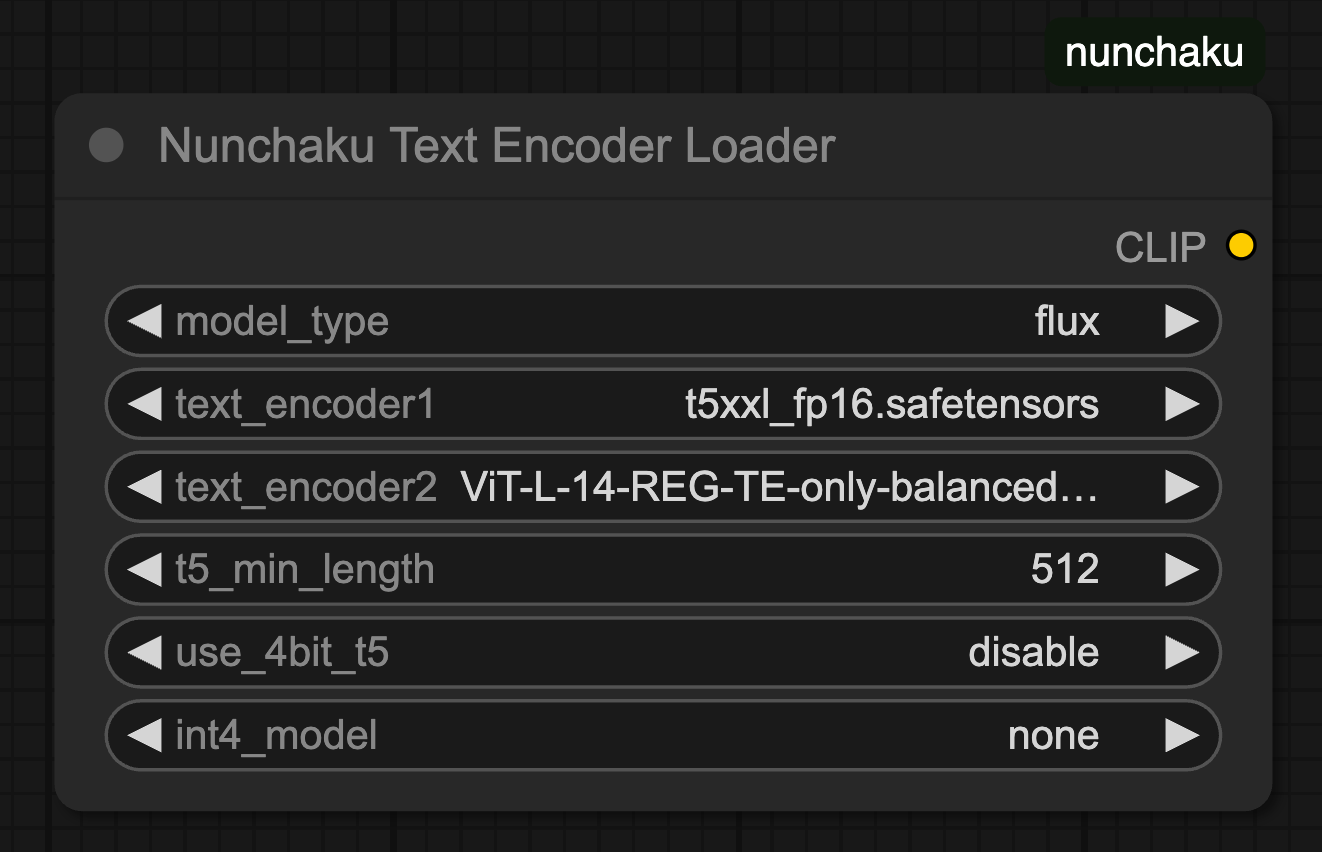
Nunchaku Text Encoder Loader
- text_encoder1
- 자연어 문장을 벡터로 변환하는 데 사용되는 T5 텍스트 인코더 모델 파일입니다.(ex. t5xxl_fp16.safetensors)
- VRAM이 16GB 이상인 경우 FP16 모델을 사용할 수 있으며, VRAM이 8GB 이하인 경우 GGUF 또는 FP8 버전을 고려해야 합니다.
- text_encoder2
- 태그 기반 프롬프트를 처리하는 데 사용되는 CLIP 텍스트 인코더 모델 파일입니다.(ex. clip_l.safetensors)
- t5_min_length
- T5 텍스트 임베딩의 최소 시퀀스 길이를 설정합니다. 기본값은 256이지만, 더 나은 이미지 품질을 위해 512로 설정하는 것이 권장됩니다.
- use_4bit_t5
- 4비트로 양자화된 T5 모델을 사용할지 여부를 지정합니다. VRAM 사용량을 줄이기 위해 활성화할 수 있습니다.
- 현재 4비트 T5 모델은 메모리 사용량이 많을 수 있으며, 향후 최적화가 예정되어 있습니다.
- int4_model
- use_4bit_t5가 활성화된 경우, 사용할 4비트 T5 모델의 위치를 지정합니다.
- 설정 방법:
- Hugging Face에서 INT4 T5 모델을 다운로드합니다.
- 다운로드한 모델 폴더를 models/text_encoders 디렉토리에 저장합니다.
- 현재 4비트 T5 모델을 로드하면 메모리가 과도하게 소모됩니다. (추후 최적화 할 예정이라고 합니다.)
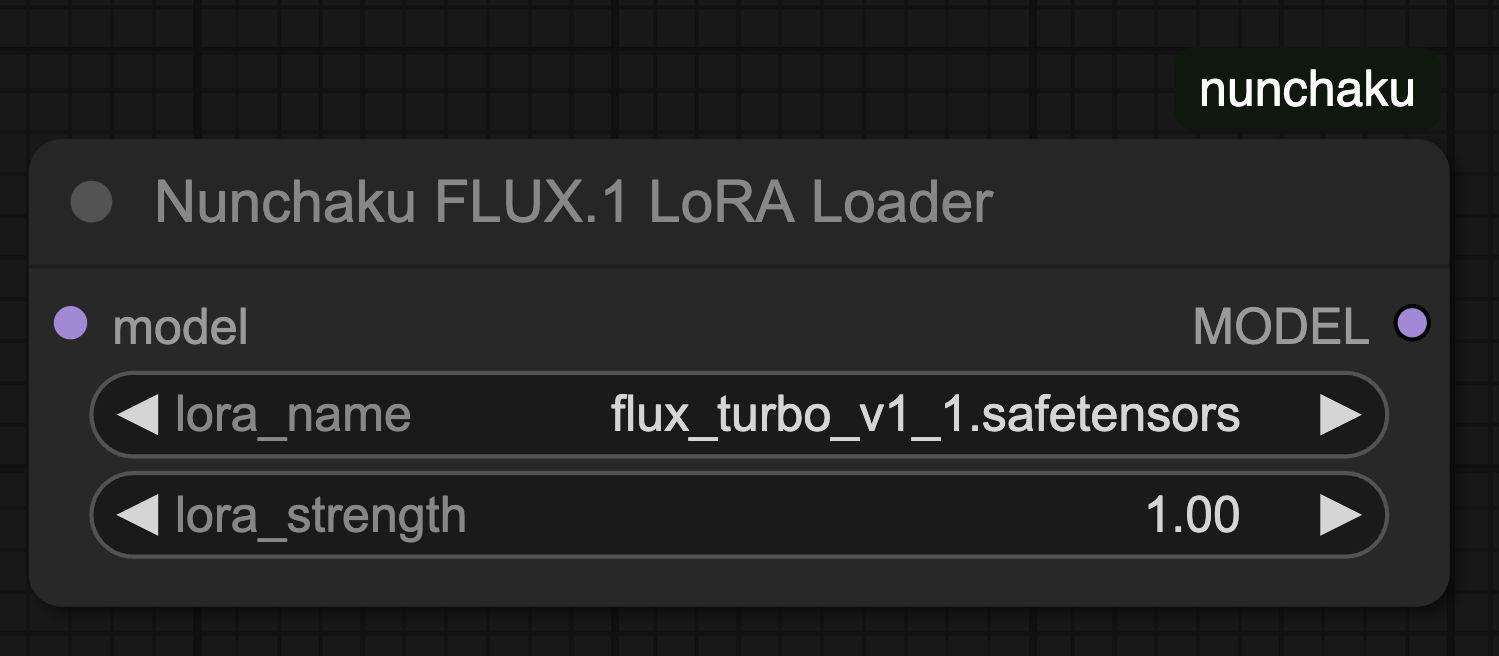
Nunchaku FLUX.1 LoRA Loader
nunchaku v0.1.4 까지는 LoRA를 nunchaku로 실행하기 위해 별도의 변환이 필요했습니다. 하지만 최근 v0.2.0 에서는 기존 LoRA 모델을 바로 사용할 수 있도록 업데이트 되었습니다. 기존과 동일하게 lora 파일을 선택하고 strength를 조절할 수 있습니다.
Comparison

FLUX FP8 / 1.68it/s

Nunchaku / 4.75it/s
일반적으로 많이 사용하는 FP8 버전의 FLUX 모델과 Nunchaku 모델을 비교해보았습니다. 역시 FLUX FP8 결과가 조금 더 디테일이 있지만 Nunchaku의 결과물도 충분히 FP8과 유사하게 나오고 있습니다.
그에반해 생성 속도는 비약적으로 단축되었습니다.
FLUX FP8 모델이 약 1.68 iteration/s 속도를 기록한 데 반해, Nunchaku 모델은 4.75 iteration/s를 기록하며 약 2.8배 빠른 속도 향상을 보여주었습니다.
이러한 속도 향상은 비디오 생성 분야에서도 큰 변화를 일으킬 가능성이 있습니다. 비디오 생성은 한 프레임 한 프레임을 순차적으로 생성해야 하기 때문에, 메모리 사용량과 생성 속도가 가장 큰 병목 요소로 작용해왔습니다. 만약 Nunchaku 기술이 비디오 생성에도 적용된다면, 일반 사용자들도 고품질 비디오를 손쉽게 제작할 수 있는 시대가 한층 앞당겨질 것입니다.
Conclusion
지금까지 SVDQuant 알고리즘과 이를 실제 시스템에 적용한 Nunchaku에 대해 알아보고 ComfyUI로의 적용방법에 대해 알아보았습니다.
실제 ControlNet, Redux 등의 모델과 결합하여 사용해봤을때 Nunchaku가 텍스트에 대한 디테일이 아직 아쉬워서 개인적으로 실제 production에 적용하기에는 어려울 것 같지만 4비트로 양자화하는 아이디어뿐만 아니라, 이를 실제 속도 향상으로 연결시키기 위해 커스텀 엔진(Nunchaku)까지 개발한 점은 인상적입니다.
헌재는 mit-han-lab에서 Wan2.1 모델을 위한 Nunchaku 최적화 작업을 진행 중이며, 공식 Roadmap에 등록되어 있습니다. 앞으로 Nunchaku가 다양한 생성 모델에 적용되어 어떤 변화를 이끌어낼지 기대가 됩니다.
keep going
Paper: https://arxiv.org/abs/2411.05007
nunchaku GitHub: https://github.com/mit-han-lab/nunchaku
ComfyUI-nunchaku GitHub: https://github.com/mit-han-lab/ComfyUI-nunchaku
Intro
The diffusion model, which generates images from text, has sparked a boom in the field of image generation with its remarkable results.
Initially, Stable Diffusion 1.4 operated with about 800 million parameters, but now the latest models have expanded to billions of parameters, allowing for the creation of more sophisticated and detailed images.
However, while these large-scale models have improved quality, they also demand immense memory and compute resources, resulting in slower speeds and making real-time applications more challenging.
computation vs parameters
Meanwhile, as hardware advancements have slowed (the so-called end of Moore’s Law), there has been increasing effort to enhance efficiency through low-precision computation.
In fact, the latest GPU architectures (e.g., NVIDIA Blackwell) have started to support 4-bit floating point (FP4) operations.
Quantization is a technique that reduces the range of data representation to fewer bits, lightening computation.
In large language models (LLMs), this has mainly been applied to weights, compressing them to 8 bits to reduce model size and memory usage.
However, in diffusion models, simply reducing the weight precision is not enough to significantly improve speed.
Because these models involve large computational loads, activation values (intermediate computation results) must also be reduced to low bits along with the weights to achieve true acceleration.
Otherwise, if only one side is quantized, computations revert to high-precision internally, nullifying any practical gains.
In short, for a model to truly be a “4-bit model”, both weights and activations must be 4-bit.
Why is 4-bit quantization difficult?
Using 4 bits means representing data with about 16 levels (2^4).
When the representable range is this small, the presence of outliers (extreme values) can cause serious problems.
For example, if most values lie between 1 and 10 but a few are near 100, adjusting for these large values can distort the representation of the majority or cause the large values to be clipped.
It’s like having to size school uniforms to fit a few very tall students, making the uniforms way too loose for the rest.
Looking at the distribution of actual weights W or activations X in diffusion models, there are rare but very large values that make 4-bit quantization difficult.
Such extreme values can cause quantization errors that severely degrade the quality of generated images.
One proposed method to alleviate this issue is a “smoothing” technique like SmoothQuant.
In simple terms, this method transfers outliers from activations to weights, flattening the distribution.
This makes it easier to fit activations into 4-bit, but the burden of outliers shifts onto the weights instead.
Thus, under the extreme condition of 4 bits, it is still not enough.
It’s like moving the tall students to another class, only to create new problems there.
To resolve this dilemma, SVDQuant was introduced.
SVDQuant
SVDQuant proposes a completely new approach for 4-bit quantization: adding a low-rank branch specifically to handle outliers.
Conceptually, it’s like attaching a small, sophisticated auxiliary circuit to the original model.
This auxiliary branch processes a handful of extreme values with 16-bit precision, while the main model handles the majority with 4-bit precision.
When the two parts collaborate, the final output maintains overall accuracy while leveraging the advantages of 4-bit precision.
First, SVDQuant performs the smoothing step to shift outliers from activations to weights.
The resulting adjusted weights W_hat are heavily influenced by outliers, and then SVD (Singular Value Decomposition) is used to split W_hat into two parts:
- One part is the low-rank component — essentially the top few directions containing the most energy (variability).
- The other part is the residual — the remainder.
Interestingly, in large models, most of the variance is known to concentrate on just a few singular values.
SVDQuant exploits this fact by extracting the low-rank part (dominant components) and handling it with 16-bit precision.
After removing these dominant components, the remaining part of W_hat becomes much easier to quantize to 4 bits because the range and outliers are significantly reduced.
Thus, the low-rank branch absorbs the quantization difficulty from both weights and activations, enabling the 4-bit model to maintain near-original image quality.
Nunchaku
While SVDQuant solves the algorithmic challenges, Nunchaku is the secret to optimizing for actual system performance.
Although the two branches (main 4-bit and low-rank) work together, if implemented naively, the system could actually become slower.
This is because if the low-rank and 4-bit branches operate separately, it would require duplicated computation and duplicated memory accesses for the same input data.
According to the authors’ analysis, running the auxiliary branch separately can cause about 50% additional latency compared to running only the 4-bit branch.
Even though the low-rank calculations themselves are small, data movement of activations becomes a bottleneck.
Nunchaku is a custom inference engine designed together with SVDQuant, smartly fusing the two branches into a single efficient operation.
Specifically:
- The down-projection (projecting inputs into the low-rank space) shares the same input as the main 4-bit computation, and both are fused into a single kernel.
- The up-projection (merging low-rank outputs back into the final result) is combined with the main 4-bit output stage, processing them simultaneously.
By sharing input and output in real-time, Nunchaku eliminates unnecessary memory trips and halves the number of kernel calls.
As a result, the overhead from the auxiliary branch becomes as little as 5–10%, making the performance impact almost negligible.
In other words, it’s like integrating two separate assembly lines into one, completing tasks in a single run.
Fittingly, “Nunchaku” (nunchucks) refers to two sticks connected together, symbolizing how the two computational branches are unified here.
Additionally, thanks to Nunchaku, compatibility with LoRA has improved.
LoRA is a method for adding new styles or functions to pretrained models via low-rank updates.
Under previous quantization methods, applying LoRA often required re-quantization of the model.
But with the SVDQuant + Nunchaku combination, such low-rank additional branches can be naturally accepted, allowing pretrained LoRA modules to be attached without modification.
This means users can easily apply diverse LoRA styles to 4-bit models.
Experiments
The effectiveness of SVDQuant and Nunchaku has been demonstrated through various experiments on large-scale diffusion models.
In terms of model size and memory usage, they showed revolutionary improvements.
The authors compared the original 16-bit (BF16) FLUX.1 model (about 12 billion parameters) against the 4-bit SVDQuant model.
As a result, the 4-bit SVDQuant model reduced memory usage by about 3.6x, enabling much larger models to fit into the same GPU memory.
Moreover, with Nunchaku optimization applied, memory usage was reduced by a total of 3.5x compared to the original 16-bit model, and inference speed was 3.0x faster than a baseline model that quantized only the weights (W4A16).
In simple terms, it means you can generate images 3 times faster on the same hardware.
Interestingly, these optimizations now allow huge models to run on consumer GPUs.
For instance, the original 16-bit FLUX.1 model would overflow GPU memory on a 16GB RTX 4090 laptop GPU, requiring CPU offloading.
Due to slow data transfers between CPU and GPU, performance would drastically drop.
But after compression with 4-bit quantization, the entire model fits into GPU memory, resulting in over 8x speedup, and when CPU offloading is fully avoided, performance can improve up to 10x.
This shows that even massive diffusion models can now be used almost in real-time on a single, modest GPU, without the need for expensive server-class hardware.
Image quality was also a critical evaluation point.
The 4-bit SVDQuant model maintained almost the same quality and text-image alignment as the original 16-bit model.
Additionally, when applied to various models such as PixArt-∑ and SDXL, SVDQuant’s 4-bit results showed better visual quality compared to previous 4-bit or 8-bit quantized models.
ComfyUI-nunchaku
Installation
To use nunchaku, you need to install it into your Python virtual environment and install the ComfyUI-nunchaku custom nodes by following the README.md guide.
⚠️
Note -
Since nunchaku compiles CUDA custom operations directly, compiler setup and environment configuration are essential. Please pay attention to your CUDA, Python, and Torch versions.
The installation process is detailed in the README.md, so it will be omitted here.
Workflow
Applying nunchaku to an existing ComfyUI workflow is very straightforward.
In the example workflow above, the main differences when using the Flux model with Nunchaku are related to the Base Model, Text Encoder, and Lora nodes.
Nunchaku FLUX DiT Loader
- cache_threshold:
- Adjusts the tolerance for First-Block Cache. It plays a role similar to WaveSpeed’s
residual_diff_threshold.
- Increasing this value speeds up processing but may slightly reduce quality. A value around 0.12 is generally recommended. Setting it to 0 disables this feature.
- attention:
- Specifies the attention computation method.
- You can choose between
flash-attention2 and nunchaku-fp16.
nunchaku-fp16 is about 1.2x faster than flash-attention2 while maintaining precision.- GPUs based on the Turing architecture (e.g., GTX 20 series) must use
nunchaku-fp16 because they do not support flash-attention2.
- cpu_offload:
- Determines whether part of the transformer model should be offloaded to the CPU.
- Enabling this can reduce GPU memory usage but might slow down inference slightly.
- Setting it to
auto will automatically detect available GPU memory: it disables offloading if memory is 14GiB or more, and enables it if less than 14GiB.
- (Further memory optimization will be added to nodes in the future.)
- device_id:
- Specifies which GPU ID to use for running the model. (e.g., GPU 0, GPU 1)
- data_type:
- Specifies the data type of the dequantized tensor.
- Turing GPUs (RTX 20 series) do not support bfloat16, so you must use float16.
- i2f_mode:
- An option to configure GEMM (General Matrix Multiplication) implementation for Turing GPUs.
- Although there are slight differences between
enabled and always modes, the performance is generally similar.
- (Ignored on other GPU architectures.)
Nunchaku Text Encoder Loader
- text_encoder1:
- The T5 text encoder model file used to convert natural language sentences into vectors (e.g.,
t5xxl_fp16.safetensors).
- FP16 models can be used if VRAM is 16GB or more; if VRAM is 8GB or less, consider using GGUF or FP8 versions.
- text_encoder2:
- The CLIP text encoder model file used for tag-based prompts (e.g.,
clip_l.safetensors).
- t5_min_length:
- Sets the minimum sequence length for T5 text embeddings.
- The default is 256, but setting it to 512 is recommended for better image quality.
- use_4bit_t5:
- Option to use a 4-bit quantized T5 model to reduce VRAM usage.
- Currently, 4-bit T5 models may consume a lot of memory, but further optimization is planned.
- int4_model:
- Specifies the location of the 4-bit T5 model if
use_4bit_t5 is enabled.
- Setup:
- Download the INT4 T5 model from Hugging Face.
- Save the downloaded model into the
models/text_encoders directory.
- Note: 4-bit T5 models currently consume a lot of memory (optimization is underway).
Nunchaku FLUX.1 LoRA Loader
Up until nunchaku v0.1.4, using LoRA with nunchaku required a separate conversion step.
However, from v0.2.0, existing LoRA models can be used directly without conversion.
You can select the lora file and adjust its strength just as before.
Comparison
FLUX FP8 / 1.68 it/s
Nunchaku / 4.75 it/s
We compared the commonly used FLUX FP8 version and the Nunchaku model.
As expected, FLUX FP8 results show slightly more detail, but Nunchaku’s outputs are quite close.
On the other hand, generation speed improved dramatically.
Whereas the FLUX FP8 model achieved about 1.68 iterations per second, the Nunchaku model achieved 4.75 iterations per second — about 2.8 times faster.
This speed boost could also bring major changes to the field of video generation.
Since video generation requires creating frame-by-frame sequentially, memory usage and generation speed have been critical bottlenecks.
If Nunchaku technology is applied to video generation, it could significantly advance the era where ordinary users can easily create high-quality videos.
Conclusion
We have now explored the SVDQuant algorithm, how it solves algorithmic challenges, and how Nunchaku optimizes it for real system deployment, along with how to apply it in ComfyUI.
Although Nunchaku still struggles slightly with fine text details in production scenarios (such as with ControlNet or Redux models), the innovation of quantizing to 4-bits and then developing a custom engine to realize real-world speed improvements is very impressive.
Currently, the mit-han-lab is working on optimizing Nunchaku for the Wan2.1 model, as recorded on their official Roadmap.
We look forward to seeing how Nunchaku will continue to transform various generative models in the future.
keep going
Paper: https://arxiv.org/abs/2411.05007
nunchaku GitHub: https://github.com/mit-han-lab/nunchaku
ComfyUI-nunchaku GitHub: https://github.com/mit-han-lab/ComfyUI-nunchaku





Leave a comment