
Auto Acceleration
Intro
AI모델을 운영단계에서 활용할때는 최적화를 통해서 최대한 모델을 가속화하고 경량화시킵니다. 이는 비용문제와 직결되기 때문에 아주 중요한 작업입니다. 일반적으로 머신러닝 모델은 추론속도가 빠르기 때문에 최적화가 필수적으로 요구되는 작업이 아닐 수 있지만 딥러닝에서는 상황에 따라 최적화 효과를 크게 볼 수 있습니다.
최근 LLM(Large Language Model)이 빠르게 발전되어 가면서 이것들을 서비스화 시키기 위해 모델 최적화 및 경량화에 대한 중요성이 점점 더 대두 될 것으로 보입니다.
저는 지금까지 여러 도메인에서 모델을 개발할 때 대부분 모델 최적화를 적용했습니다. 상당히 불편하게 말이죠.
새로운 모델을 개발하게되면 Inference 환경에 사용 가능한 최적화 라이브러리를 선택하고 모델에 맞는 명령어를 작성하여 그때마다 수동으로 변환하였습니다. 그러다 문득 "어떤 딥러닝 모델이던지 환경에 맞는 최적화 모델들을 자동으로 생성하고 성능을 비교해주는 애플리케이션을 개발해보면 어떨까?" 라는 생각을 하게되었습니다.
그래서 Auto Acceleration이라는 애플리케이션을 개발하였고 이 애플리케이션을 통해 많은분들이 모델 최적화를 편하게 하실 수 있도록 오픈소스로 공개하였습니다.
이번 포스팅에서는 모델 최적화의 불편함을 해결한 Auto Acceleration 프로젝트에 대해 공유하는 시간을 가지려고 합니다.
Why need?
문제 1. 최적화 툴마다 명령어가 다르고 모델의 입출력 shape, 데이터타입, 레이어의 특성에 따라 사용해야 하는 옵션이 많다.
- 모델이 어떻게 생겼든지 자동으로 최적화가 가능하도록 할 수 없을까?
문제 2. 최적화 툴을 사용하기 위해서 요구하는 조건을 만족하는지 파악해야 한다.
- 기본적으로 OpenVINO는 Intel processor가 필요하며 TensorRT는 Nvidia gpu가 필요하다. 이 외에도 다양한 조건들이 있는데, 최적화 툴에 내가 맞추는게 아니라 “내 환경을 알려줄테니 알아서 변환해줘” 를 가능하게 한다면 모델 최적화를 빠르고 편리하게 진행할 수 있지 않을까?
문제 3. 여러 데이터 타입에 따른 성능비교를 해야할 경우 반복적인 변환작업을 해야한다.
- 마치 모델의 하이퍼파라미터를 튜닝하듯이 모델의 weight 와 입출력 텐서를 다양한 데이터 타입(FP32, FP16, INT8)에 대해 자동으로 실험하면서 최적의 성능을 내는 export를 찾아낼 수 있다면?
문제 4. 모델 최적화를 MLOps의 한 컴포넌트로 활용하기 어렵다.
- Auto Acceleration을 활용한다면 배포 가능한 최적의 경량화 모델을 얻는 컴포넌트를 설계하여 ML 파이프라인에 추가 할 수 있지 않을까?
Dev issue
1. 초기 모델파일 형식
사용자가 PyTorch의 모델파일인 .pt(.pth)를 입력으로 주면 onnx변환을 내부적으로 처리하려고 했지만 사용자의 모델 아키텍쳐(모듈) 코드를 보유하고 있지 않기 때문에 PyTorch 모델을 로드할 수 없다.
timm, ultralyrics, transformers 와 같은 대중적인 라이브러리를 컨테이너에 미리 설치해두면 PyTorch 모델을 로드 할 수 있지만 여러 라이브러리를 하나의 환경에 설치하면 패키지 버전이나 호환성 문제가 일어날 확률이 높고 모델 아키텍쳐가 라이브러리가 아닌 커스텀 모듈 클래스라면 여전히 로드 할 수 없는 문제가 있다.
Solution
-> 아키텍쳐와 가중치를 직렬화 한 ONNX 파일을 사용자로부터 받도록 하고 ONNX 파일을 활용하여 정보를 추적
2. 정확도 비교 vs output tensor 비교
샘플데이터와 라벨을 입력으로 받고 변환한 모델의 정확도를 계산하여 각 task에 맞는 성능지표를 출력하면 가장 best이지만 몇가지 문제가 있다.
-
개발범위 증가
모델의 정확도를 계산하기 위해서는 모델 output에 대한 후처리가 필요하다. 하지만 모델마다 후처리가 각기 다르기 때문에 다양한 task의 후처리를 담아내기까지 많은 시간이 소요되며 일반적이지 않은 후처리가 필요한 경우 구현에 한계가 있다. -
자동화같지 않은 자동화
모델의 정확도를 계산한다는 것은 데이터셋이 필요하다는 말이다. 즉 사용자가 auto-accerlation을 사용하기 위해 룰에 맞는 데이터셋을 따로 준비해야 한다는 치명적인 단점이 발생한다.
Solution
-> 데이터와 라벨을 요구하지 않고 모델 shape에 맞는 dummy input을 생성하여 추론을 진행하고 MAE로 원본 ONNX의 output에 비하여 변환된 파일의 output tensor가 얼마나 다른지 확인
3. 모델마다 다른 input output
최적화 툴 명령어를 사용시에 입출력 데이터에 대한 정확한 정보를 입력해주어야 한다. 그런데 문제는 모델에 따라 Input과 Output이 천차만별이라는 것이다.
Image Classification, Object Detection과 같은 일반적인 CV task에서는 input과 output이 1개인 경우가 대부분이지만 Text Model 같은 경우 모델 종류에 따라 Tokenizer를 통해 얻어진 token, attention_mask 이외에 token_type_ids, position_ids 등 여러개의 input이 들어올 수 있으며 output 또한 한 개만 나온다고 장담할 수 없다.
입출력 텐서의 정보는 onnxruntime.InferenceSession의 get_inputs(), get_outputs() 함수를 통해 input과 output의 name, shape, data type 정보를 얻어낼 수 있다. 하지만 shape을 그대로 가져와서 사용하게 된다면 에러가 발생할 수 있다.
만약 사용자가 ONNX모델을 변환할때 dynamic shape으로 변환했다고 가정해보자
dynamic_axes={
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
"timestep": {0: "batch"},
"encoder_hidden_states": {0: "batch", 1: "sequence"},
},
위 dynamic shape으로 변환하려는 모델은 stable diffusion의 unet 모델인데 stable diffusion은 여러개의 모델로 구성되어있기때문에 중간에 위치한 unet의 Input이 여러개가 들어오는 상황이다.
이렇게 ONNX 변환된 모델의 onnxruntime.InferenceSession의 get_inputs()으로 shape을 확인해보면 아래와 같다.
print(session.get_inputs()[0].shape)
print(session.get_inputs()[1].shape)
print(session.get_inputs()[2].shape)
# ['batch', 'channels', 'height', 'width']
# ['batch']
# ['batch', 'sequence', 1024]
dynamic으로 지정된 차원은 이름으로만 남아있기 때문에 이를 적당한 숫자로 처리하여 dummy input을 생성해야 한다.
“dynamic shape이면 전부다 어떤 값을 사용해도 처리가 가능해야 한것 아닌가?” 라고 생각할 수 있지만 만약 dynamic값을 1로 설정한다면 당연히 연산량이 줄어들기 때문에 throughput이 비정상적으로 커지게 되면서 사용자에게 혼동을 줄 수 있다.
심지어 특정 상황에서는 임의로 값을 설정하면 에러가 발생한다.
stable diffusion의 unet은 중간에 있는 모델이기 때문에 앞쪽의 다른모델의 레이어가 달라지면 unet으로 들어오는 Input shape이 달라질 수 있다. 그렇기 때문에 사용자는 위처럼 dynamic axis를 설정한 것이지만 Auto Acceleration 입장에서는 unet 단일모델만 다루기 때문에 input shape을 현재 unet에서 처리 가능한 값을 사용해야 한다.
Solution
-> dummy input으로 활용할 model shape을 config.yml에 사용자가 직접 지정
-> 실제 inference에서 사용될 shape을 지정하여 일반적인 throughput 을 얻을 수 있음.
-> batch 또한 자유롭게 설정할 수 있기 때문에 원하는 batch를 사용해서 OOM을 피하거나 특정 batch로 테스트 가능
Function
Environment
- Image: nvcr.io/nvidia/pytorch:22.08-py3
- TensorRT: 8.4.2
- OpenVINO: 2022.3.0
- ONNX: 1.12.0
- onnxruntime-gpu: 1.14.1
- pycuda: 2022.2.2
INPUT
- onnx 모델파일
- config.yml(device, I/O tensor shape)
OUTPUT
- throughput, filesize, mae 등의 정보가 담긴 엑셀파일
- 변환된 모델파일
Tutorial
Auto Acceleration을 사용하려면 우선 Nvidia Docker가 설치되어있어야 합니다. 만약 Nvidia Docker가 설치되어 있지 않으신 분들은 여기를 참조해주세요.
Stable Diffusion의 변형된 버전으로 입력 프롬프트인 텍스트에 더해서 원본 이미지, 마스크를 활용하여 이미지의 마스킹된 부분을 생성(복원)하는 Stable Diffusion Inpainting 이라는 기술이 있습니다. Stable Diffusion과 Stable Diffusion Inpaint 모델 모두 unet에서 병목현상이 일어납니다. 이러한 병목현상을 해결하기위해 unet 모델을 최적화시켜보겠습니다.
Convert to ONNX
Auto Acceleration은 사용자로부터 onnx 파일을 요구합니다. 먼저 huggingface diffusers 라이브러리로 원본 모델을 불러와 onnx로 변환하겠습니다.
import torch
from diffusers import StableDiffusionInpaintPipeline
device= 'cuda'
dtype=torch.float32
pipeline = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float32).to(device)
unet_in_channels = pipeline.unet.config.in_channels # 9
unet_sample_size = pipeline.unet.config.sample_size # 64
num_tokens = pipeline.text_encoder.config.max_position_embeddings # 77
text_hidden_size = pipeline.text_encoder.config.hidden_size # 1024
torch.onnx.export(
pipeline.unet, # pipeline에서 unet 모듈만 선택
(
torch.randn(2, unet_in_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
torch.randn(2).to(device=device, dtype=dtype),
torch.randn(2, num_tokens, text_hidden_size).to(device=device, dtype=dtype),
False,
),
f="unet/stable_diffusion_inpaint_unet.onnx",
input_names=["sample", "timestep", "encoder_hidden_states", "return_dict"],
output_names=["out_sample"],
dynamic_axes={
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
"timestep": {0: "batch"},
"encoder_hidden_states": {0: "batch", 1: "sequence"},
},
do_constant_folding=True,
opset_version=16, keep_initializers_as_inputs=True)
unet 폴더에 stable_diffusion_inpaint_unet.onnx가 잘 저장되어있는지 확인해 보겠습니다.

폴더를 확인해보면 위 그림처럼 onnx파일 외에 모든 레이어에 대한 weight가 따로 저장되어 있는것을 보실 수 있습니다. 왜 이런 현상이 나타날까요?
onnx 모델은 protobuf 형식으로 저장됩니다. protobuf는 구조화된 데이터를 직렬화하고 전송하는 역할을 하는데 protobuf의 단점이 max size가 2GB라는 점 입니다. 직렬화된 모델의 protobuf size가 2GB 미만이라면 하나의 onnx 파일에 모델의 모든 weight가 저장되고 2GB보다 큰 상황이라면 위 그림처럼 weight가 레이어별로 따로 저장됩니다.
만약 지금처럼 레이어별로 weight가 따로 직렬화되어 저장된다면 모든 파일들을 onnx와 같은폴더에 두시면 문제없이 사용 가능합니다.
한가지 더 주의할 점은 opset_version입니다. nvcr.io/nvidia/pytorch:22.08-py3 컨테이너 환경에서는 opset_version=16 까지만 지원하기 때문에 16 이하의 버전을 사용하시면 됩니다.
Configuration
먼저 GitHub에서 코드를 가져오겠습니다.
git clone https://github.com/visionhong/Auto-Acceleration.git
Auto-Acceleration 폴더로 이동하면 input 폴더와 output 폴더가 있습니다. input 폴더는 사용자의 config와 onnx 파일을 가지고 있어야 하며 변환된 파일 및 결과는 output 폴더에 담기게 됩니다.
위에서 변환한 onnx 파일 및 weight 파일을 모두 input/model 폴더 안으로 이동시키겠습니다.
mv <unet onnx 폴더경로>/* <Auto-Acceleration 경로>/input/model
input/config 폴더에는 config.yml 이라는 샘플파일이 있습니다. 이 config는 아래와 같은 형식으로 사용자가 직접 작성해야합니다.
# config.yml
device: 0 # cpu or 0, 1, 2, 3 ...
input:
sample:
min_shape: [1, 9, 32, 32]
max_shape: [4, 9, 64, 64]
use_shape: [1, 9, 64, 64]
timestep:
min_shape: [1]
max_shape: [1]
use_shape: [1]
encoder_hidden_states:
min_shape: [1, 77, 1024]
max_shape: [4, 77, 1024]
use_shape: [1, 77, 1024]
output:
out_sample:
use_shape: [1, 4, 64, 64]
device는 추론 대상이되는 프로세서를 의미합니다. cpu를 적으면 onnxruntime + openvino 변환 및 추론을 수행하고 gpu 번호를 적으면 해당 gpu를 활용하여 onnxruntime + tensorrt 변환 및 추론을 수행합니다.
min_shape과 max_shape은 dynamic shape 범위를 지정하는 역할이며 use_shape은 변환된 최적화 모델의 성능비교에 활용될 inference shape입니다.
Run Auto Acceleration
Nvidia Docker가 준비되셨다면 docker compose 명령어를 통해 바로 테스트를 진행할 수 있습니다.
docker compose up
명령어를 실행하면 모델 변환이 먼저 이루어지고 마지막에 변환된 파일을 추론하여 성능을 테스트하게 됩니다. 모델파일과 성능결과 파일은 호스트 output 폴더에 저장되도록 미리 마운트 해두었습니다. output 폴더의 summary.xlsx 파일에서 변환된 모델에 대한 추론 결과를 확인할 수 있습니다.
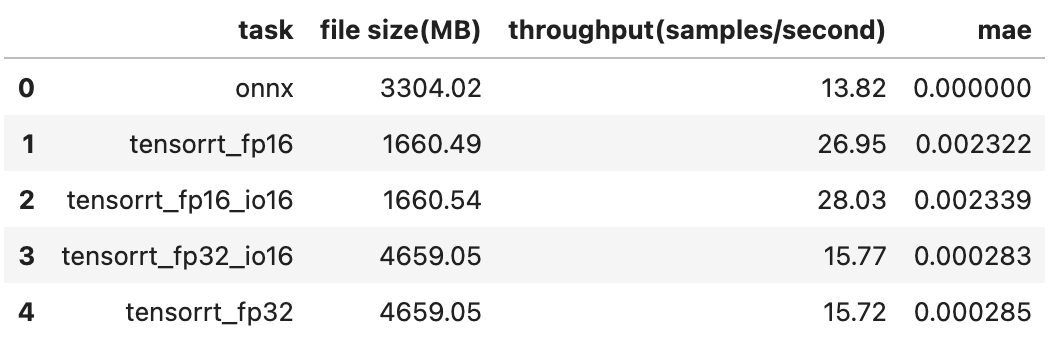
아래는 device를 cpu로 바꾸어서 테스트 한 결과입니다.
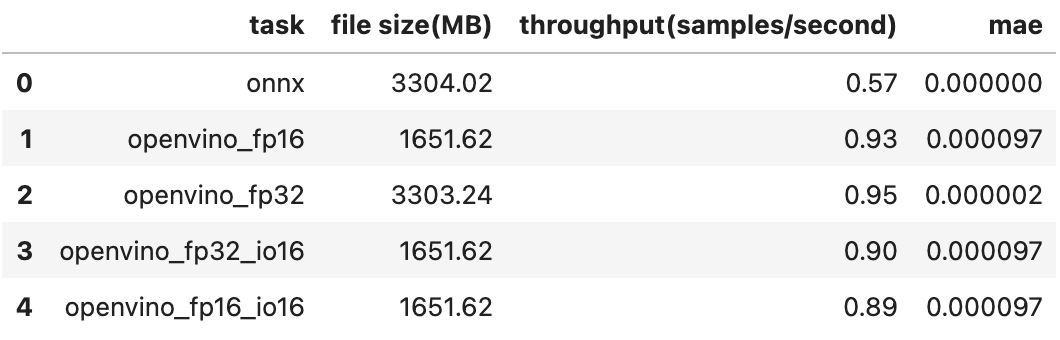
확인결과 Stable Diffusion Inpaint의 unet 모델은 cpu와 gpu 모두 onnx 보다 openvino, tensorrt로 변환했을때의 성능이 더 좋아보이고 원본과 비교하여 output이 크게 달라지지 않았습니다.
END
처음 프로젝트를 구상했을때는 여러 모델을 최적화 한 경험이 있어서 개발이 수월하게 진행될 줄 알았는데 로직을 몇번이나 수정했는지 모르겠네요.. 가장 고민을 많이 한 부분이 “어떻게하면 최대한 많은 Task와 모델에서 사용할 수 있도록 일반화, 자동화 시킬 수 있을까?” 였습니다.
처음에 욕심은 많았지만 가장 중요하게 생각한 일반화와 자동화라는 목표를 달성하려면 어쩔 수 없이 놓아 주어야 하는 부분도 생겼습니다.
사용자로부터 얻는 정보가 많아지면 많은 모델을 사용 가능하도록 일반화시킬 수 있지만 자동화의 입장에서 바라볼때는 사용자에게 정보를 요구하게 되는 것이므로 이 둘은 이 프로젝트에서 Trade-off 관계에 있었습니다. 나름대로 타협점을 잡으려고 노력한 것이 onnx파일과 config.yml 작성 까지만 사용자에게 요구하는 것이었습니다.
이제 어느정도 틀은 잡혔지만 아직 추가해야 할 부분(UINT8 변환 및 추론, 버전 업데이트)이 남아있기 때문에 천천히 계속해서 기능을 추가할 예정입니다.
Keep Going
Auto Acceleration은 아래 github repo에서 사용 가능합니다.
Github repo: https://github.com/visionhong/Auto-Acceleration
Leave a comment