
비전 프로젝트 : CVFM(Computer Vision For Market)
Project : CVFM(Computer Vision For Market)
DATE : 2021-04-01 ~ 2021-05-06
Member : 홍은표, 최정훈, 윤성현
WHAT : 고객이 과일을 고른 후에 카운터에 과일을 올려 놓으면 카운터에 설치된 카메라를 통해 과일을 검출하여 현재 과일 가격에 맞는 총 액수를 계산을 하고 모니터를 통해 고객이 바로 결제를 할 수 있도록 하는 무인 결제 시스템
WHY : 아이디어가 과일가게에 국한되지 않고 일반적인 마트, 편의점 등에 적용을 할 수가 있으며 이를 통해 인건비, 야간의 범죄 노출, 잦은 알바생 교체로 인한 고용주의 스트레스 등 사람이 일을 했을때의 많은 문제점을 해소할 수 있으며 더 나아가 기존 무인 시스템(바코드, RFID 등)에 비해 유지보수 측면에서 장점이 있다.
HOW : 카메라를 통해 전송되는 매 프레임 이미지(1 batch)를 학습된 Object detection모델에 넣어주어 그 결과와 엑셀에서 가져온 과일 정보를 매칭하여 웹 페이지에 전송해주면 detection된 과일들이 장바구니에 표시되고 총 가격을 알려주며 사용자는 웹 화면을 통해 결제를 진행한다.
PURPOSE : 실제 상업화 할 수 있도록 가장 성능이 좋은 모델을 가져다 쓰고 상업적인 완성도를 높인다기 보다는 직접 object detection모델을 구현 한 후에 own dataset에서 그동안 공부해온 Hyper parameter tuning, augmentation, pre-post processing등을 계속해서 조절하여 성능변화를 직접 경험해보는것.
STEP 1 - 데이터 수집
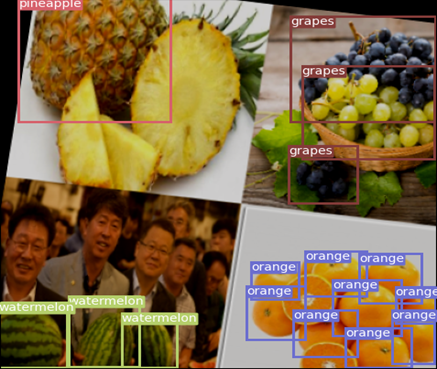
- 11 classes: apple, orange, pear, watermelon, durian, lemon, grapes, pineapple, dragon fruit, oriental melon, melon
- 기존에 있는 과일 dataset은 외국 과일을 기준으로 삼고있고 Classification에 사용되는 데이터가 대부분이기 때문에 직접 데이터셋을 만들어야 했다.
- 웹 크롤링을 통해 이미지를 모았고 해당 사이트의 모든 이미지를 저장하기 위해 페이지 이동이 가능한 동작 자동화 라이브러리 selenium을 사용했다. (아래 동영상과 같이 웹 크롤링 동작)



- 크롤링을 통해 얻은 이미지들에 대해 아래와 같은 기준을 정하여 육안으로 필요 없는 이미지를 제거 했다.
- 첫번째 사진 : 사과의 크기가 너무 작다 -> 사과의 특징을 제대로 나타내지 못한다
- 두번째 사진 : 사과가 조각이 났다 -> 과일가게에서는 완전한 과일을 판매하기 때문에 조각난 사과사진의 활용가지가 떨어진다.
- 세번째 사진 : 사과는 빨간색 이어야 한다 -> 대부분의 과일이 대륙마다 특징이 다르고 다양한 종류가 있기 때문에 현실적으로 활용 가능한 데이터의 한계점을 고려했다. (즉 11개의 과일은 한국에서만 볼 수 있는 종으로 선택)
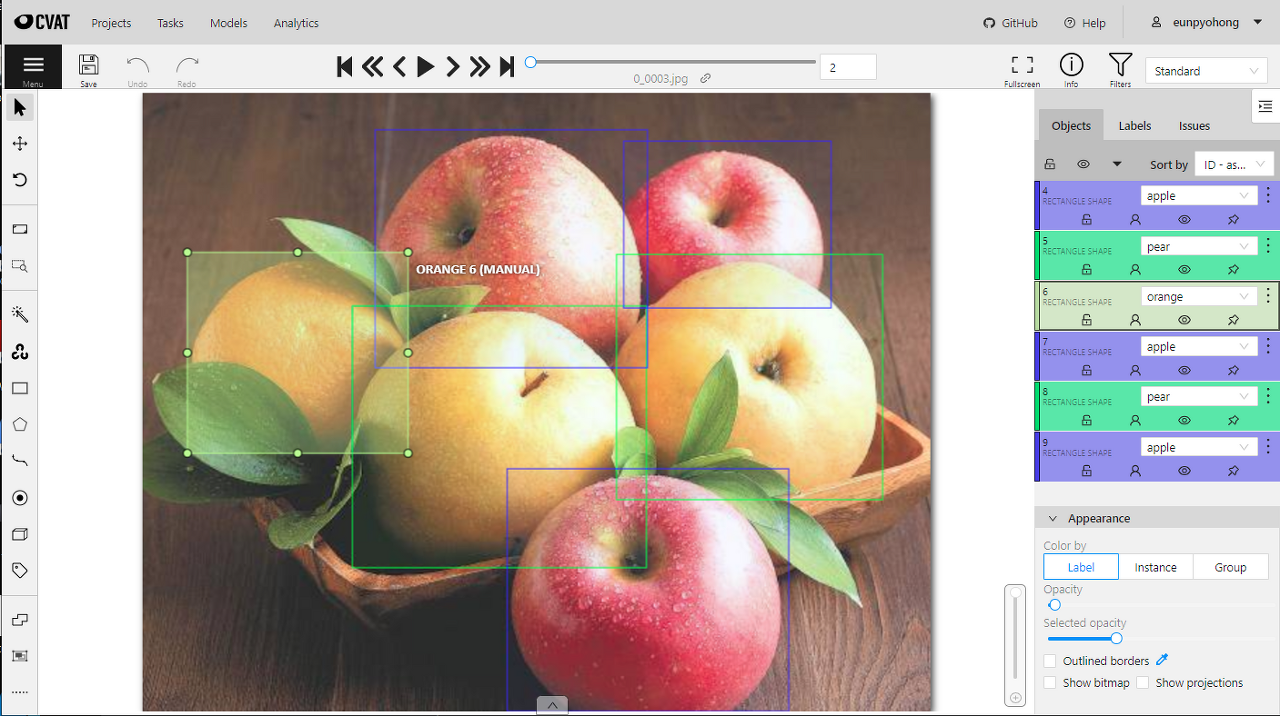
- Object Detection에서는 Bounding Box Annotation이 필요하기 때문에 CVAT.org(Computer Vision Annotation Tools) 사이트를 활용하여 데이터를 직접 Annotation 하였다.
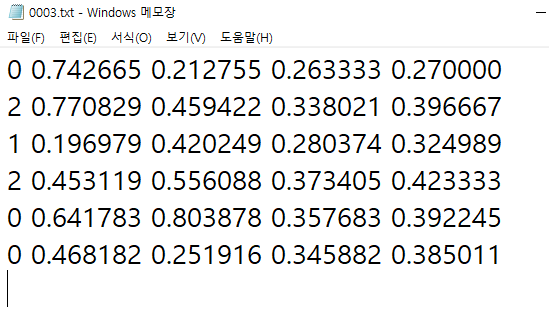
- Annotation 파일은 txt로 저장하였고 각 파일 안에는 [label x y w h] 와 같은 형태로 정보가 저장되어 있다.
- [label, x, y, w, h] = [class, center x, center y, width, height]
- 이후에 roboflow.ai 통해서 Annotation 작업이 잘 되었는지 점검했다.
최종 데이터셋
이미지
- Total 4,400개 (Train: 3,800개 / Validation: 600 개)
Annotation
- 사과 : 2575 / 오렌지 : 2954 / 배 : 3280 / 수박 : 1628 / 레몬 : 1206 / 용과 : 1686 / 포도 : 1220 / 멜론 : 811
- 두리안 : 2908 / 참외 : 2690 / 파인애플 : 1647
- Total 22,705 box
Computer Visio Annotataion Tools : cvat.org/
Annotation Inspection : https://roboflow.com/
Fruit Dataset Download: www.kaggle.com/eunpyohong/fruit-object-detection
STEP 2 - 모델 선정
- mAP와 FPS의 trade off 관계를 고려해 보았을때 프로젝트에서는 당연히 속도보다는 얼마나 과일을 잘 탐지하는지 즉 정확도가 더 중요하다.
- 프로젝트의 목적에서 말했듯이 own dateset에 대한 모델의 성능을 높이는 작업을 하고 싶었기 때문에 SOTA 모델들의 baseline이면서 어느정도 속도가 보장되는 YOLO v3모델을 base로 잡고 이후에 모델의 정확도를 높이는 방향으로 진행하였다.
- 가장 빠른 FPS를 보여주는 YOLO v5를 사용하지 않은 이유는 YOLO v4부터 COCO dataset에 대한 성능을 높이기 위한 여러가지 기법들과 약간의 변화가 있었을 뿐 뿌리는 전부 YOLO v3에서 시작하기 때문에 own dataset에서의 성능을 높이기 위해서는 YOLO v3에서부터 변화를 주는 것이 개인적으로 학습적인 측면에서 더 도움이 될 것이라고 판단했다. (워낙 YOLO v4, v5 open source가 이미 잘 되어있기도 하고 그 코드를 전부 이해하고 거기서 성능을 올리기에는 부족함이 있었던 것도 사실이다.)
- FLASK를 빨리 마무리 지어야 조급하지 않고 여러 실험들을 해볼 수 있을 것 같아서 미리 YOLO v5 s 모델 open source를 통해 작업한 과일 데이터를 가지고 간단하게 학습한 후에 웹 작업을 먼저 진행했다.
STEP 3 - FLASK를 통한 웹 구현
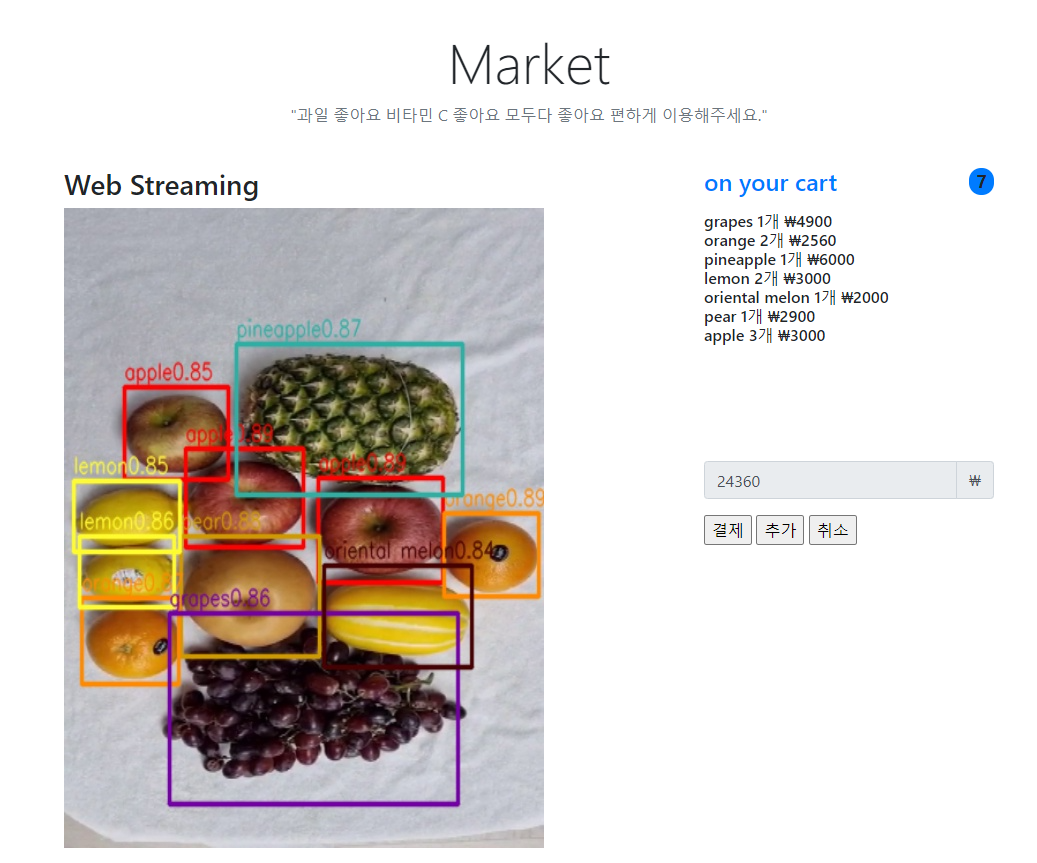
먼저 웹의 메인화면 UI에서는 위 그림과 같이 왼쪽에서 과일 detection inference를 보여주고 우측에서는 detect된 과일의 이름과 개수, 가격을 표시하고 아래에서 현재 화면에 보이는 과일의 총 가격을 알려준다.
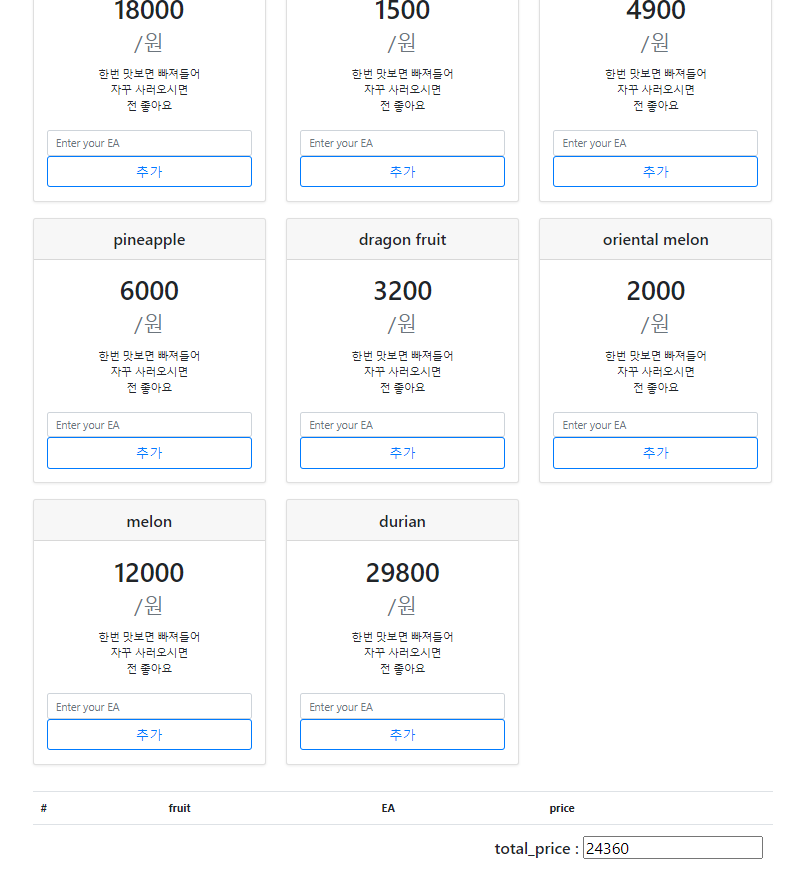
위 그림은 사용자가 직접 과일을 추가 할 수 있는 기능을 하는 UI이다. 모델의 정확도가 완벽하지 않기 때문에 혹시 박스를 치지 못한 과일이 있을때 사용할 수 있도록 하였다. (사실 추가를 만들 거였으면 삭제 수정 등 전부 갖추고 있어야 말이 되는데 모델에 집중하다보니 웹에서의 완성도가 아직 많이 미흡하다. 추후에 서비스적으로 기능추가를 해보면 좋을 것 같다.)
STEP 4 - YOLO v3 구현
기본 베이스는 아래 동영상의 implementation을 참고 하였다.
YOLO v3 paper : https://arxiv.org/abs/1804.02767
1) Custom Dataset
def readId(root):
root = os.path.join(root, 'images')
img_ids = os.listdir(root)
ids = [i.split('.')[0] for i in img_ids]
return ids
class YOLODataset(Dataset):
def __init__(self, root, anchors, image_size=416, S=[13, 26, 52], C=4, transform=None, mosaic=False):
self.ids = readId(root)
self.root = root
self.image_size = image_size
self.transform = transform
self.S = S
self.anchors = torch.tensor(anchors[0] + anchors[1] + anchors[2]) # == torch.tensor(anchors).view(9,2)
self.num_anchors = self.anchors.shape[0] # 9
self.num_anchors_per_scale = self.num_anchors // 3
self.C = C
self.ignore_iou_thresh = 0.5
self.mosaic = mosaic
def __len__(self):
return len(self.ids)
def __getitem__(self, idx):
if self.mosaic:
idxs = [self.ids[idx]] # 현재 뽑힌 인덱스
[idxs.append(self.ids[random.randint(0, len(self.ids)-1)]) for _ in range(3)] # 랜덤 인덱스 3개 더 추가
image, bboxes = mosaic(self.root, idxs, (416, 416), (0.3, 0.7), filter_scale=1 / 50)
else:
id = self.ids[idx]
try:
image = cv2.imread(os.path.join(self.root, "images", id + ".jpg"))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
except:
image = np.array(Image.open(os.path.join(self.root, "images", id+".jpg")).convert('RGB'))
# 공백 기준으로 나눔 + 최소 2차원 array로 반환
# np.roll : 첫번째 원소를 4칸 밀고 나머지를 앞으로 끌어옴 (0 ,1 ,2 ,3 ,4) -> (1, 2, 3, 4, 0)
# 즉 label값을 0번째에서 4번째로 이동
bboxes = np.roll(np.loadtxt(fname=os.path.join(self.root, "labels", id+".txt"), delimiter=" ", ndmin=2), 4, axis=1)
bboxes[:,:4] = bboxes[:,:4] - 1e-5
# 1e-5를 빼준 이유는 albumentation에서 box transform을 할 때 bbox 값에 1이 들어가면 반환될때 1이 넘어가는 오류가 있어서 이렇게 변경함.
bboxes = bboxes.tolist() # 2차원 리스트
if self.transform:
augmentations = self.transform(image=image, bboxes=bboxes)
image = augmentations['image']
bboxes = augmentations['bboxes']
# Below assumes 3 scale predictions (as paper) and same num of anchors per scale
# dim [(3,13,13,6),(3,26,26,6)(3,52,52,6)] 6 : (object_prob, x, y, w, h, class)
targets = [torch.zeros((self.num_anchors//3, S, S, 6)) for S in self.S]
for box in bboxes: # 각 스케일 셀 별 하나의 anchor box scale에 target값을 설정해주는 로직
iou_anchors = iou(torch.tensor(box[2:4]), self.anchors) # 한개의 박스와 9개의 anchor간의 w,h iou tensor(9,)
anchor_indices = iou_anchors.argsort(descending=True, dim=0) # 내림차순 정렬의 인덱스 값
x, y, width, height, class_label = box
has_anchor = [False] * 3 # [False, False, False]
for anchor_idx in anchor_indices: # true bbox와 iou가 큰 앵커 부터
scale_idx = anchor_idx // self.num_anchors_per_scale # anchor_idx가 8이면 scale_idx가 2가되고 52x52를 의미 (0, 1, 2)
anchor_on_scale = anchor_idx % self.num_anchors_per_scale # 각 그리드스케일 에서 사용할 3개의 anchor 스케일 (0, 1, 2)
S = self.S[scale_idx] # anchor_idx가 8이면 52
# 만약 x,y가 0.5라면 물체가 이미지 중앙에 있다는 의미,
# S가 13x13이면 int(6.5) -> 6이 되고 13x13에서 이 6x6번째 셀에 물체의 중심이 있다는 의미
# 애초부터 txt파일에서 bbox가 0~1로 Normalize 되어있기 때문에 가능
i, j = int(S * y), int(S * x) # which cell
anchor_taken = targets[scale_idx][anchor_on_scale, i, j, 0] # [anchor_idx, 행(y), 열(x), object probability]
if not anchor_taken and not has_anchor[scale_idx]: # 둘다 False(혹은 0)이어야 추가. 즉 한박스당 3개의 스케일에 한번씩만 아래 작업수행
targets[scale_idx][anchor_on_scale, i, j, 0] = 1 # object probability= 1
# pdb.set_trace()
x_cell, y_cell = S * x - j, S * y - i # 중심점이 있는 셀에서의 위치 0~1 (위에서 i,j구할때 int를 씌우면서 사라진 소수점 값이라고 생각하면 됨)
width_cell, height_cell = (width * S, height * S) # 해당 스케일(13x13 or 26x26 or 52x52)에서의 비율로 나타냄 (당연히 1보다 클 수있음)
box_coordinates = torch.tensor([x_cell, y_cell, width_cell, height_cell])
targets[scale_idx][anchor_on_scale, i, j, 1:5] = box_coordinates
targets[scale_idx][anchor_on_scale, i, j, 5] = int(class_label) # class_label이 float으로 되어있음
has_anchor[scale_idx] = True
elif not anchor_taken and iou_anchors[anchor_idx] > self.ignore_iou_thresh:
targets[scale_idx][anchor_on_scale, i, j, 0] = -1
'''
현재 하고있는게 한 이미지에 있는 여러 정답박스중(물론 물체가 하나라서 정답박스가 하나일 수 있음)
한개의 박스에 대한 정답을 세개의 스케일(13x13 26x26 52x52)에서 해당 위치에 o_p = 1, bbox값,라벨을 설정하고 있다.
위 과정을 9개의 anchor box와 정답박스의 크기를 비교해서 정답박스의 크기와 가장 일치하는 순서대로 진행을 하게되는데
예를들어 현재 정답과 가장 비슷한 박스가 26x26 grid scale의 0번째 스케일 박스라면 그 위치의 o_p가 1이 되는것이다.
-> target[1(grid scale)][0(box scale), 행, 열, 0(o_p)] = 1
(위 방법처럼 bbox값 + 라벨값도 넣어줌)
elif 구문은 해당 스케일에 대표 앵커가 정해졌지만 박스의 크기와 현재 인덱스의 anchor box의 크기가 ignore_iou_thresh 값보다
클 경우에 이것은 학습에 사용되지 않도록 -1로 만들어준다.
-> 즉 박스는 3개의 grid scale(13x13 26x26 52x52)중 한곳에서 target과 가장 비슷한 앵커박스를 정답으로 가지고 있도록(o_p=1) 한다.
'''
return image, tuple(targets)
- 먼저 초기화 과정에서 readId 함수를 통해 모든 데이터의 id(확장자를 제외한 파일 이름)를 가져와서 getitem의 인덱싱에 사용할 수 있도록 하였다.
- 각 이미지의 정답 즉 2차원의 target box 리스트는 다음과 같이 yolo v3에 맞게 변환을 해주었다.
- [(3, 13, 13, 6), (3, 26, 26, 6), (3, 52, 52, 6)]
- yolo v3는 3개의 feature_map에서 정답을 예측하기 때문에 위와 같은 형태를 띄게 되고 각 차원의 의미는 아래와 같다.
- 3 : grid scale당 3개의 anchor box들의 차원
- 13, 26, 52 : 현재 grid cell의 크기(가로 세로)
- 6 : 각 셀에대한 정보 (object probability, x, y, w, h, class_label)
- 이렇게 Custom Dataset Class의 output은 현재 index의 이미지와 물체의 정보를 담은 tuple이 된다.
2) Data Augmentation
Data Augmentation은 pytorch의 torchvision.transforms를 사용하지 않고 alumentations 라이브러리를 사용하였다. albumentations가 torchvision transforms보다 속도도 빠르고 무엇보다 이미지가 변환됨에 따라 박스의 위치도 그 변환에 맞춰서 자동으로 조절해주는 엄청난 기능이 있다.
예를들어 Horizontal Flip(좌우 반전)을 사용할경우 아래와 같이 이미지가 변환된다.


이미지가 위처럼 변환이 되었다면 정답박스의 위치도 조절되어야 하는데 torchvision의 transforms를 사용하게 되면 박스의 위치를 조절하는 기능이 없기 때문에 따로 함수를 추가해서 변환을 해야한다.
하지만 albumentations은 bounding box의 정보를 이미지와 같이 입력해주면 아래와 같이 box의 위치도 자동으로 조절해주는 엄청난 기능을 포함하고 있다.


scale = 1.1
train_transforms = A.Compose(
[
A.LongestMaxSize(max_size=int(IMAGE_SIZE * scale)), # 초기 이미지의 비율을 유지하면서 한쪽(w,h)이 max_size와 같도록 이미지 크기 조정 (가로 세로중 한쪽이 416*1.1 이 되도록 resize)
A.PadIfNeeded( # 입력 이미지 size가 min_height, min_width값이 될때 까지 0으로 채움
min_height=int(IMAGE_SIZE * scale),
min_width=int(IMAGE_SIZE * scale),
border_mode=cv2.BORDER_CONSTANT,
),
A.RandomCrop(width=IMAGE_SIZE, height=IMAGE_SIZE),
A.OneOf(
[
A.ShiftScaleRotate(
rotate_limit=10, p=0.4, border_mode=cv2.BORDER_CONSTANT
),
A.IAAAffine(shear=10, p=0.4, mode="constant"), # rotate와 비슷한 느낌
],
p=1.0,
),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.2),
A.Blur(p=0.1),
A.Normalize(mean=[0.6340, 0.5614, 0.4288], std=[0.2803, 0.2786, 0.3126], max_pixel_value=255,),
ToTensorV2(),
],
bbox_params=A.BboxParams(format="yolo", min_visibility=0.4, label_fields=[],), # 후의 박스 면적이 전의 면적의 0.4 이하이면 사용x
)
- albumentation을 통한 augmentation은 위 코드에서 위에서부터 차례대로 수행이 되는데 각 기법마다 p라는 확률값을 통해 매번 다르게 데이터가 변환 되도록 할 수 있다.
- 특히 맨 마지막 줄의 코드를 사용하면 target box를 같이 변환해주는데 format형식을 잘 적어야 한다. format 형식의 종류는 아래와 같다.
- pascal_voc = x_min, y_min, x_max, y_max
albumentations = x_min, y_min, x_max, y_max + Normalize
coco = x_min, y_min, width, height
yolo = x_center, y_center, width, height - (이처럼 다양한 box 좌표 표기법에 대해 알아서 처리를 해주니 참 편리한 라이브러리 인것 같다.)
Albumentations : https://albumentations.ai/
3) Model
모델은 yolo v3 구조를 하나의 파일에서 모두 구현하지 않고 backbone과 head를 구분해서 정리를 하였다. backbone network를 바꿔보면서 성능을 비교하고 싶었기 때문이다. 우선 yolo v3의 backbone인 Darknet53은 아래 구조와 같다.
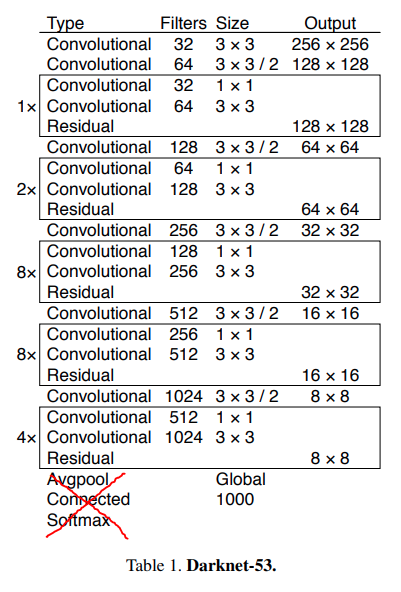
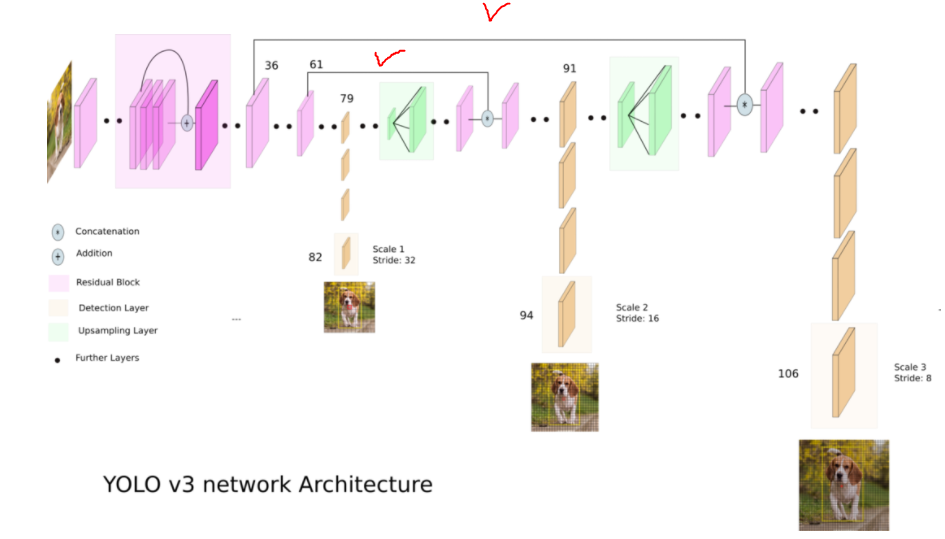
위와 똑같은 형태로 구현을 하였고 다만 이후에 head 레이어들이 와야 하기 때문에 아래 Avgpool 부터 classifier부분을 제거했다. 또한 backbone network을 따로 분리하였기 때문에 후에 있을 head와의 concatenate(위의 오른쪽 그림에서 체크한 부분)을 위한 정보를 최종 output과 함께 보내준다. (즉 backbone의 최종 출력 = output, concat1, concat2)
concat1과 concat2 의 차원은 (n, 256, 52, 52), (n, 512, 26, 26)이 되고 output의 차원은 (n, 1024, 13, 13)이다.
yolo v3는 feature pyramid network 형태를 띄고 있기 때문에 head에서는 feature_map size를 두번의 Upscaling을 통해 2배씩 키워주는 nn.Usample(scale_factor=2)를 사용하고 나머지는 일반적인 convolution과 3개의 feature_map(13, 26, 52) 에서 scale prediction이 이루어진다.
class ScalePrediction(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.pred = nn.Sequential(
CNNBlock(in_channels, in_channels*2, kernel_size=3, padding=1),
CNNBlock(2 * in_channels, (num_classes + 5) * 3, bn_act=False, kernel_size=1), # predict feature_map 에서는 batch_norm 사용 하지 않음
)
self.num_classes = num_classes
def forward(self, x):
# x = (n, 512, 13, 13) or (n, 512, 26, 26) or (n, 512, 52, 52)
return(
self.pred(x) # (n, 48, 13, 13), (n, 48, 26, 26), (n, 48, 52, 52)
.reshape(x.shape[0], 3, self.num_classes+5, x.shape[2], x.shape[3]) # (n, 3, 16, 13, 13), (n, 3, 16, 26, 26), (n, 3, 16, 52, 52)
.permute(0, 1, 3, 4, 2) # (n, 3, 13, 13, 16), (n, 3, 26, 26, 16), (n, 3, 52, 52, 16)
)
위 scale prediction 코드가 세번 호출이 되면서 3개의 scale에 대한 output이 리스트에 담기게 되고 그 리스트가 모델의 output이 된다. 여기서 눈여겨 봐야 할것은 Custom dataset target의 최종 차원들이 전부 6이었는데 모델의 prediction은 16이다. 앞 부분의 5(o_p, x, y, w, h)는 target과 같지만 prediction에서는 6~16까지 총 11개의 각 과일들에 대한 예측값이 나오게 만든다. 여기서 class에 대한 loss는 Cross Entropy를 사용할 것임을 알 수 있다.
def forward(self, x):
outputs = [] # for each scale
route_connections = []
x, concat1, concat2 = self.backbone_model(x)
route_connections.append(concat1)
route_connections.append(concat2)
# x = self.backbone_model(x)
for layer in self.layers:
if isinstance(layer, ScalePrediction):
outputs.append(layer(x))
continue
x = layer(x)
if isinstance(layer, nn.Upsample):
# upsample 한 후의 결과와 route_connections 맨 뒤에 저장된 값과 concat
x = torch.cat([x, route_connections[-1]], dim=1) # concatenate with channels (n, 768, 26, 26), (n, 384, 52, 52)
route_connections.pop()
return outputs # [(n, 3, 13, 13, 16), (n, 3, 26, 26, 16), (n, 3, 52, 52, 16)]
위 코드를 통해 모델의 최종 output이 나오게 되는데 배치사이즈 만큼의 이미지 x(n, 3, 416, 416)가 모델에 들어오게 되면 backbone으로 가서 연산을 한 후에 위에서 말했듯이 x, concat1, concat2를 반환하게 되고 이 concat값들은 Upscale 이후의 값과 concatenate 된다.
def _initialize_weights(self):
for m in self.layers.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
backbone 모델인 Darknet53은 pretrained weight을 사용했지만 head는 그렇지 않기 때문에 위 코드로 weight를 초기화 하였다.
4) Loss
| 논문 Loss | 프로젝트 Loss | |
|---|---|---|
| Class Loss | Binary Cross Entropy | Cross Entropy |
| Object Loss | Binary Cross Entropy | MSE Loss |
| No object Loss | Binary Cross Entropy | Binary Cross Entropy |
| Box coordinates Loss | MSE Loss | MSE Loss |
- Yolo v3논문에서는 데이터셋에 woman, person과 같은 계층적 구조의 label이 있을때 이것을 softmax를 사용하는 multi-class classification로 보는 것 보다 sigmoid를 사용하는 multi-label classification으로 보는 것이 성능이 더 좋다고 한다.
- 하지만 프로젝트 데이터셋은 11개의 각각의 과일이 상호 베타적 관계를 가지기 때문에 Class Loss에서 binary cross entropy가 아닌 cross entropy를 사용하였다.
- 또한 Object Loss에서 bce loss 대신 mse loss로 교체했더니 mAP가 1~2% 상승에서 mse loss를 사용하였다
- 4개의 loss항에 적용한 lambda 값은 class loss: 1 object loss: 1 noobj loss: 10 box coordinates: 10을 사용했다.
5) Hyper Parameter
| Standard Hyperparameter | value |
|---|---|
| learning_rate | 1.00E-03 |
| batch_size | 45 |
| image_size | 416 |
| weight_decay | 1.00E-04 |
| epoch | 150 |
| conf_threshold | 0.6 |
| map_iou_threshold | 0.5 |
| nms_iou_threshold | 0.45 |
| anchors | (0.28, 0.22) (0.38, 0.48) (0.9, 0.78) (0.07, 0.15) (0.15, 0.11) (0.14, 0.29) (0.02, 0.03) (0.04, 0.07) (0.08, 0.06) |
| loss function | no object loss: nn.BCEWithLogitsLoss() object loss: nn.MSELoss() box coordinates loss: nn.MSELoss() class loss: nn.CrossEntropyLoss() |
| loss lambda | no object loss: 10 object loss: 1 box coordinates loss: 10 class loss: 1 |
| optimizer | Adam |
| scheduler | ReduceLROnPlateau( optimizer, factor=0.1, patience=5, verbose=True) |
| backbone | Darknet53(pretrained weights about imagenet) |
| mAP | val_loss | param(million) | FLOPs(billion) | |
|---|---|---|---|---|
| Standard Result | 87.99% | 1.16 | 61.6m | 32.8b |
- 하이퍼 파라미터는 일반적으로 많이 사용하면서 어느정도 성능이 나오는 것을 기준으로 잡았다. 나중에 하이퍼 파라미터와 그외 여러가지 augmentation을 추가해야 하기 때문에 이 하이퍼 파라미터의 mAP를 기준으로 여러 실험들의 좋고 나쁨을 판단했다.
- 위 표에서 anchors는 위에서부터 3개씩 각각 13x13 26x26 52x52 스케일에서 사용될 anchor box의 width와 height이다. 이 값들은 COCO dataset으로 K-mean clustering을 통해 구한 값들이다.
- learning rate scheduler는 pytorch에서 제공하는 ReduceLROnPlateau를 사용하였다. 이 함수는 lr를 업데이트를 할 기준이되는 loss가 5 epoch동안 낮아지지 않게되면 lr을 0.1배 만큼 낮추는 역할을 한다.
6) Train
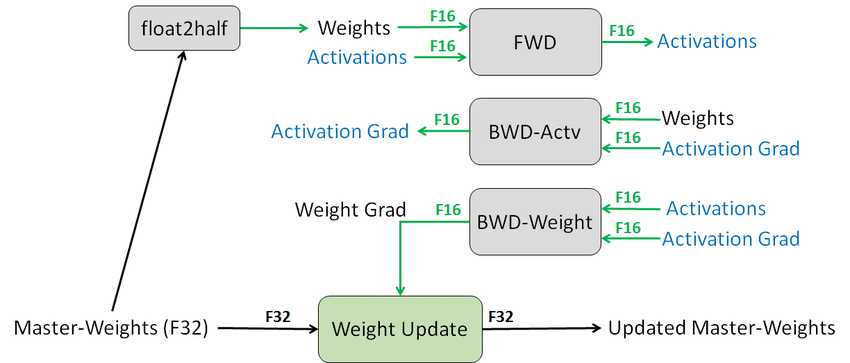
학습에서는 Mixed Precision Training을 사용하였다. Mixed Precision Training이란 학습 과정에서 계산량을 줄이기 위해 딥러닝 모델의 학습에 Single Precision(FP32) 대신 Half Precision(FP16)을 사용하는 것을 말한다. 사용하는 Bit 수가 절반으로 줄어들기 때문의 숫자를 표현하는 범위가 크게 줄어들지만 계산량과 메모리 사용량을 크게 줄일 수 있다.
하지만 Training의 모든 과정에서 FP16 연산을 하게 되면 gradient가 작아지면서 오차가 누적이 되어 loss가 증가하게 되기 때문에 Mixed precision training에서는 이것을 해결하기위해 Weight를 업데이트하는 경우에만 FP32로 증가시키고 나머지 Forward, Backward Propagation에서는 모두 FP16으로 연산을 수행한다.
Pytorch에서는 Automatic Mixed Precision을 도와주는 amp 모듈이 존재한다.
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
out = model(x) # [(2, 3, 13, 13, 16), (2, 3, 26, 26, 16), (2, 3, 52, 52, 16)]
loss = (
loss_fn(out[0], y0, scaled_anchors[0])
+ loss_fn(out[1], y1, scaled_anchors[1])
+ loss_fn(out[2], y2, scaled_anchors[2])
)
losses.append(loss.item())
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
train코드 중에서 amp scaler를 사용하는 부분만 가져왔다. 보다시피 아주 간단하게 기존의 학습코드에서 아주 조금만 바뀌었지만 이것을 사용하냐 안하냐의 차이는 꽤 컸다.
| General Training | Automatic Mixed Precision | |
|---|---|---|
| mAP | 74.4% | 87.9% |
| 최대 Batch_size | 28 | 62 |
| Training time (1 epoch) | 1분 20초 | 1분 10초 |
STEP 5 - Experiment
1) Image Transform
먼저 standard hyperparamer의 mAP를 구할때 사용한 albumentations의 이미지 변환 기법은 아래와 같다.
LongestMaxSize(max\_size\=size)
-> 가로,세로중 한쪽의 길이가 size가 될 때 까지 그 비율을 유지하면서 resize

Original / LongestMaxSize
A.PadIfNeeded(min\_height\=int(IMAGE\_SIZE \* scale),
min\_width\=int(IMAGE\_SIZE \* scale),
border\_mode\=cv2.BORDER\_CONSTANT)
-> 입력 이미지 size가 min_height, min_width값이 될때 까지 패딩 (픽셀값을 0으로 채움)
Original / PadIfNeeded
A.RandomCrop(width\=416, height\=416)
Original / RandomCrop
A.IAAAffine(shear\=10, mode\="constant")
-> 둘다 shift+rotate 변환


Original / ShiftScaleRotate or IAAAffine
A.HorizontalFlip() / A.VerticalFlip()


Original / HorizontalFlip / VerticalFlip
- 위에서 아래로 내려오면서 augmentation을 진행하게 되는데 Color를 다루는 변환기법을 사용하지 않은 것을 알 수 있다.
- 라벨로 선정한 과일중 모양이 비슷한 배 / 사과 / 오렌지 그리고 수박 / 참외는 모델이 예측을 할때 과일의 색에 대한 특징에 많이 의존해야 할 것이다.
- 그렇기 때문에 ColorJitter, Hue, Channel_shuffle과 같은 color와 관련된 변환기법을 사용하면 오히려 모델에 혼란을 줄 것이라고 생각했다.



- 위의 그림은 사과 사진을 ColorJitter, Hue, Channel_shuffle 기법들을 사용해 나온 output인데 가장 오른쪽 사진을 볼때 사과가 아니라 오히려 배와 비슷한 느낌을 주고있다.
- 실제로 이 기법들을 사용했을때 성능비교를 해보았는데 mAP가 1~2% 정도 하락했기 때문에 color와 관련된 augmentation은 적용하지 않기로 했다.



- 그리고 Brightness와 Contrast를 조절 하게되면 밝을때와 어두울때의 이미지를 추가하는 것과 같으므로 일반화에 좋을 수 있다고 가정했다. -> mAP 88.32%로 0.3% 증가
- Blur를 사용함으로써 카메라의 초점이 맞지 않았을 때의 성능 상승을 기대했지만 성능이 하락되었다.
- 이유 추론: validation set에 흐릿한 사진이 거의 없음 + blur로 인해 사진이 흐릿해 져서 과일의 특징을 약하게 만들어 버리기 때문이라고 생각한다.
- 최종적으로 Standard Transform에서 RandomBrightnessContrast만 추가하였다.
2) Mosaic Augmentation
- Mosaic Augmentation이란 데이터셋에 있는 랜덤한 4장의 이미지를 1장의 고정된 크기의 이미지로 변환하는 것을 말한다.
- Mosaic Augmentation의 장점은 batch_size가 증가하게되는 효과를 볼 수 있으며 4장의 이미지가 작아지기 때문에 small object에 대한 성능 향상을 기대할 수 있다.
- 하지만 mAP 8%하락이라는 참혹한 실험 결과가 나왔다. 성능이 하락한 이유에 대해 아래와 같이 추론해 보았다.
- 추론1: 적은 학습데이터에서 사용하다 보니 중복데이터가 많아 오히려 overfitting을 초래
- 추론2: 작은 박스들이 너무 작아져서 과일의 특징을 잃어 버린다고 생각
- 결론 : Mosaic Augmentation 제외
2) Normalize
- 보통 데이터를 모델에 입력하기 전에 학습을 쉽고 빠르게 하기 위해 정규화(Normalize)를 하게 된다.
- 0~255 사이의 픽셀값을 가지는 급변하는 이미지를 다루기 쉬운 안정적인 값으로 바꿔주는 것인데 이것이 왜 학습을 쉽고 빠르게 하는데 도움이 될까?

- 우리는 모델이 위와같은 cost function 그래프에서 빠르게 global minimum으로 가는것을 원한다.
- UnNormalized 데이터는 local minumum이 깊어서 쉽게 그곳에 빠져버려 학습이 어려워 진다.
- 하지만 Normalize를 통해 데이터를 완만하게 만든다면 상대적으로 local minumum에서 잘 빠져 나올수 있게되어 결과적으로 학습이 빠르고 쉽게 진행될 수 있는 것이다.
결국 Normalize를 사용하는것은 당연해 보인다. 그렇다면 어떤 방법을 사용해야 할까?
- 보통 이미지 데이터는 0~1사이로 만드는 Min-Max Normalize를 일반적으로 사용한다. Min-Max Normalize는 이미지 데이터에서 255를 나눠주기만 하면 된다.
- 또 다른 방법으로는 표준화(Standardization)이라는 것이 있는데 이 방법은 각 데이터들에 대해 평균값을 빼주고 그것을 표준편차로 나눠주어 평균이0 표준편차가 1인 표준정규분포를 만들어 주는 것이다.
- 여기서 먼저 데이터를 0~1사이 값으로 만든 후에 평균과 표준편차를 mean(0.5 0.5 0.5) std(0.5, 0.5, 0.5)로 하게되면 픽셀값이 -1~1 사이 값이 되고 직접 데이터셋의 mean과 std를 구해서 적용을 하면 데이터 셋의 특성에 맞게 Normalize가 된다.
- 그래서 직접 이 세가지 (0~1 / -1~1 / 데이터셋의 mean과 std를 이용한 Normalize)에 대해 성능을 비교해 보았다.
| Normalize | mAP | val_loss |
|---|---|---|
| Min-Max Normalize (0~1) | 87.85% | 1.16 |
| mean=[0.5, 0.5, 0.5] std=[0.5, 0.5, 0.5] | 86.53% | 1.22 |
| mean=[0.6340, 0.5614, 0.4288] std=[0.2803, 0.2786, 0.3126] (standard param) | 87.99% | 1.16 |
결과적으로는 데이터셋에 맞는 Normalize를 하는것과 Min-Max Normalize를 사용하는것은 크게 차이가 없다는 것을 알 수 있다. 그래도 데이터셋의 mean과 std를 구했기 때문에 3번째를 최종적으로 사용하였다.
3) Image Size
yolo v3의 이미지 사이즈는 32의 배수로 이루어져야 하고 defualt로 416을 사용했다. 이미지 사이즈에 따라 mAP와 연산량이 얼마나 증가하는지 알아보고자 여러 실험을 해 보았다.
| Image size / batch_size | mAP | val_loss | FLOPs |
|---|---|---|---|
| 320 / 45 | 85.75% | 1.27 | 19.4b |
| 352 / 45 | 87.07% | 1.15 | 23.5b |
| 384 / 45 | 87.02% | 1.19 | 27.9b |
| 416 / 45 (standard param) | 87.99% | 1.16 | 32.8b |
| 448 / 45 | 87.54% | 1.19 | 38.0b |
| 480 / 45 | 87.93% | 1.12 | 43.7b |
이미지 사이즈가 커질수록 mAP가 증가 할 것으로 예상했지만 연산량만 늘어날 뿐 좋은 현재 데이터셋에서 좋은 성능을 보여주지 못해서 default값이 416x416 이미지를 사용하기로 했다.
더 좋은 성능을 내려면 추후에 EfficientNet에서의 compound scaling(width + depth + resolution)을 적용해보면 좋을 것 같다.
4) Loss Lambda
yolo v3까지는 loss를 4가지 항으로 구분하여 각각 계산한 뒤에 합치거나 평균을내어 loss를 구한다. 그렇기 때문에 4개의 lambda값이 존재하는데 이 값들을 조절함으로 써 각 loss항들의 중요도를 모델에게 전달하게 된다. 여기서 Loss의 lambda 값을 바꿔가면서 학습을 해 보았다.
| Loss Lambda (class, noobj, obj, box) | mAP | val_loss (중요하지 않음) |
|---|---|---|
| 1, 10, 1, 10 (standard param) | 87.99% | 1.16 |
| 1, 10, 5, 10 | 89.42% | 1.61 |
| 1, 10, 10, 10 | 89.74% | 1.96 |
| 1, 1, 1, 1 | 84.38% | 0.365 |
| 1, 0.5, 1, 5 | 87.61% | 0.62 |
| 1, 0.5, 10, 10 | 88.57% | 1.2 |
- 여러가지 실험결과 class: 1 / noobj: 10 / obj: 10 / box: 10 의 lambda값을 가졌을때 성능이 가장 높았다.
- 하지만 왜 noobj loss의 lambda가 0.5일때와 10일때 큰 차이가 없는지 이해가 되지 않았다.
- noobj라는 것은 background라는 의미가 되고 background는 굉장히 많고 예측하기 쉽기 때문에 noobj loss의 중요도를 낮추기 위헤 작은 lambda를 곱하는게 더 좋을 것이라고 예상했다.
- yolo v4, v5에서는 noobj와 obj를 따로 구분하지 않고 예측하기 쉬운 것들 즉 noobj인 것들의 loss를 실제 박스와 같은 맞추기 어려운것의 loss보다 훨씬 줄이는 방식인 focal loss를 적용시켰다.
- focal loss와 noobj의 labmda를 줄이는 것은 같은 일을 한다고 보았는데 결과가 예상과 달랐다. 여기에 focal loss를 추후에 적용해 봐서 다시 확인해 봐야 할 것 같다.
- 또 배치 내에 있는 이미지들의 loss를 따로 구해 큰 loss를 가지는 Topk 만큼의 이미지의 loss만 backward하는 방법인 OHEM(Online Hard Example Mining)도 적용하면 좋을 것 같다.
5) Anchor Box
위에서 언급했듯이 Standard Hyper parameter로 anchor box를 COCO dataset으로 부터 구한 값으로 사용하였다. Yolo v5 오픈소스에서 k-mean clustering을 사용하여 Custom Dataset에 대해 anchor box를 구할 수 있는 함수가 구현되어 있어서 과일 데이터셋에 적용을 하고 그 값으로 학습을 해보았다.
| Anchor box | values | mAP | val_loss |
|---|---|---|---|
| COCO Dataset | (0.28, 0.22) (0.38, 0.48) (0.9, 0.78) (0.07, 0.15) (0.15, 0.11) (0.14, 0.29) (0.02, 0.03) (0.04, 0.07) (0.08, 0.06) | 87.99% | 1.16 |
| Fruit Dataset | (0.31, 0.31) (0.43, 0.45) (0.74, 0.69) (0.18, 0.18) (0.23, 0.22) (0.21, 0.33) (0.06, 0.05) (0.1, 0.09) (0.14, 0.13) | 85.11% | 1.16 |
- 학습결과 오히려 COCO Dataset에서의 성능이 더 좋았다. 그 이유는 다음과 같이 추론했다.
- 1. Fruit Dataset의 양이 적고 quality가 떨어져서 충분히 과일의 모양에 대해 일반화 되지 않음 (작고 정사각형의 박스 다수 존재)
- 2. 과일은 모든 방향에서 잘 예측이 가능해야 하기 때문에 오히려 COCO Dataset의 anchor box와 같이 가로 세로 비가 다양할때 성능이 좋은 것으로 추정
Auto anchor box: https://github.com/ultralytics/yolov5/blob/master/utils/autoanchor.py
6) Synthesis + Batch Size
지금까지 Standard Hyper Parameter의 성능보다 높았던 방법들을 종합하여 Batch Size를 다르게 하여 최종 결과를 내 보았다.
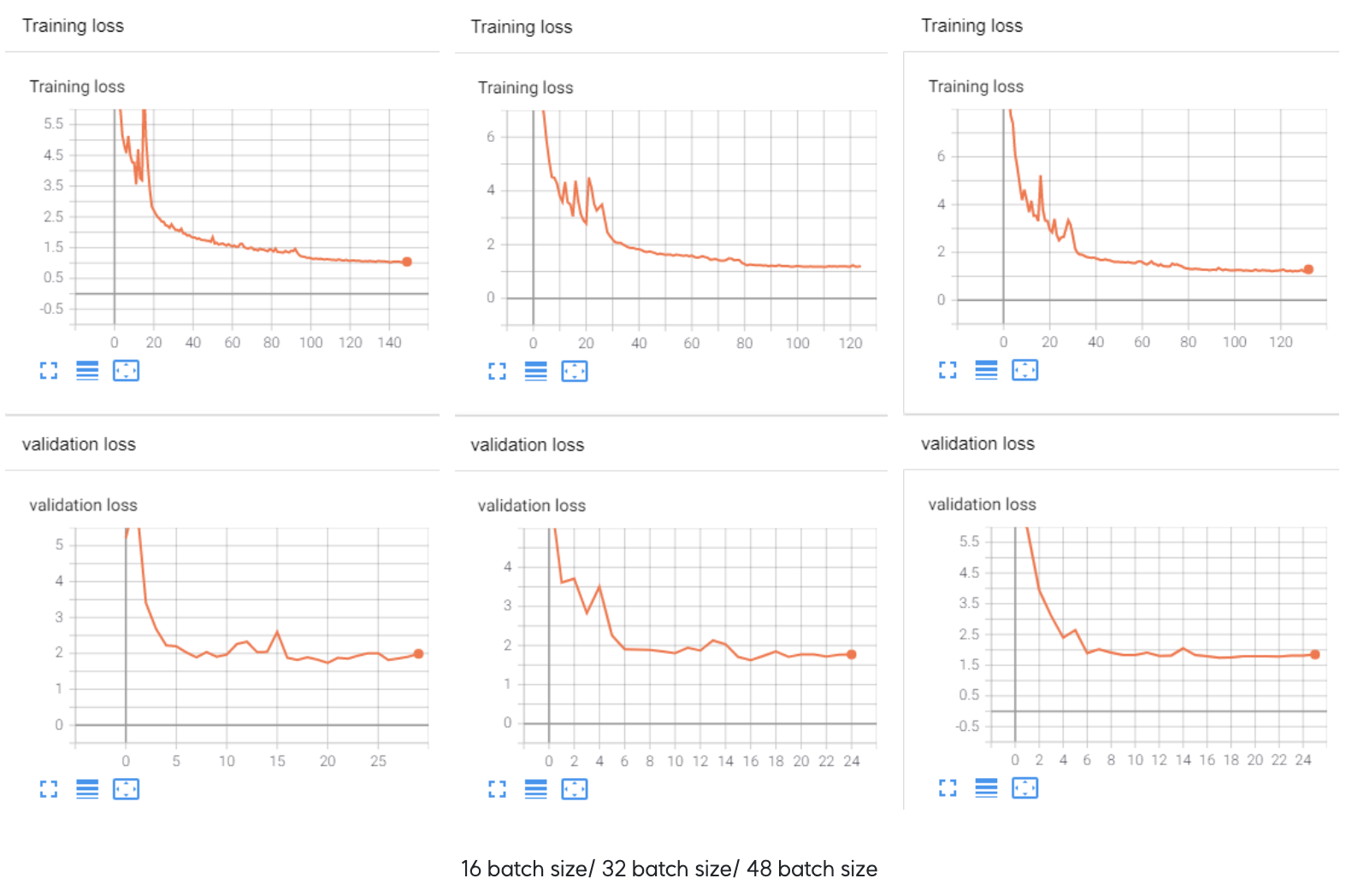
- 전체 데이터를 batch size만큼 분할하여 학습을 하게 되는데 이때 batch size의 데이터가 모집단(사실 데이터셋 자체도 표본이지만 설명상 모집단으로 표현함)의 표본이 되어 전체 데이터를 설명한다고 가정하기 때문에 batch size가 클 수록 전체 데이터셋을 잘 표현하므로 더 안정적으로 학습을 하게 된다.
- 위 그래프를 보면 batch size가 커질수록 loss graph가 완만한 것을 볼 수 있다.
- 하지만 오차를 최소화 하는 방향이 이미 정해졌을 확률이 크기 때문에 sharp local minimum에서 탈출하기가 어렵다. 즉 최적화와 일반화가 어려울 수 있게 된다.
- 반대로 batch size가 작으면 데이터내의 이상치의 영향이 커지기 때문에 학습이 잘 안될 수 있을 것이라고 생각 할 수 있지만 오히려 그 이상치가 미분값(변화율)을 크게 만들어 sharp한 local minimum에서 빠져나올 확률이 높아지기 때문에 batch size가 클때보다 성능이 높게 나올 수 있다.
| Batch Size | mAP | val_loss | Time(1 Epoch) |
|---|---|---|---|
| 16 | 92.28 | 1.82 | 1분 36초 |
| 32 | 92.66 | 1.77 | 1분 26초 |
| 48 | 92.29 | 1.85 | 1분 21초 |
- 실험결과 batch size에 따른 성능이 큰 차이가 없었지만 그나마 높은 32 batch size를 선택하였다.
최종 모델 성능
- mAP : 92.66% - FPS : 20 f/s
STEP 5 - Demo Video
STEP 6 - Learned & Improvement
What we learned?
1. Data doesn’t lie!
- 한국 과일 데이터가 많이 부족하다 보니 좋지 않은 이미지도 사용했었는데 나중에 좋지 않은 데이터를 삭제하고 퀄리티 있는 데이터를 조금 추가했더니 mAP가 5% 이상 증가했다.
2. Annotate carefully
- 짧은 기간동안 22,705개의 박스를 그리다 보니 중간에 box가 빠져 있다든지 라벨링을 잘못 지정하는 등의 annotation과정에서의 실수가 몇번 있었다. 중간중간 데이터를 수정하다보니 프로젝트 진행이 매끄럽지 못했는데 앞으로는 데이터와 라벨을 확실하게 점검한 후에 모델 작업을 해야 할 것 같다.
3. Augmentation ≠ Always Better
- 좋다고 하는 Augmentation 기법들을 적용했을 때 성능이 좋지는 못할망정 최소한 성능 하락은 없을 것 같았는데 Dataset의 quality와 도메인에 따라 그 효과가 좋을수도 나쁠수도 있다는 것을 경험했다. Augmentation을 적용하기 전에 데이터셋을 충분히 이해하고 고민해야 할 필요성을 느꼈다.
What we need?
1. Use Another backbone
- 사실 이 부분에 대해 많은 시간을 투자했지만 아직 좋은 방안을 찾지 못했다. backbone을 Darknet53에서 교체하지 못한 이유는 최근 Object Detectio은 대부분 backbone과 head와의 Concatenate이 이루어 지는 Feature Pyramid Network구조를 가지기 때문이다. Concatenate이 있다는 것은 backbone에서의 중간 레이어들의 output을 따로 저장해서 head로 연결 시켜야 하는데 그렇게 하기 위해서는 모델을 직접 구현해야 한다. 여기 까지는 문제가 없다.
하지만 과일 데이터가 많지 않기 때문에 최소한 backbone model은 pretrained weight을 사용해야 했다. 여기서 문제가 생긴다. pretrained weight을 그냥 사용하면 concatenate을 위한 중간 레이어의 output을 가져올 수 없기 때문에 pretrained model의 구현 코드를 구한 다음 concatenate를 head에 보낼 수 있도록 수정해야 한다. 그런데 내가 원했던 CSPNet(Cross Stage Partial Network)를 기반으로한 CSPDarknet53, CSPResNexXt50 등의 pretrained weight은 있지만 그에 맞는 pytorch구현코드를 구하기가 힘들었다. 시간 여유가 있다면 내가수정한 backbone들을 다른 이미지 dataset에
직접 학습시켜 pretrained weight을 얻는 것이 가능하지만 현실적으로 어려웠다.
그래서 pretrained weight을 사용하지 않고 weight initiallize만 사용해서 처음부터 과일 데이터셋에 대해 학습을 했지만 mAP가 50%까지 밖에 오르지 않았고 concatenate 없이 pretrained weight적용하는 방식도 해 보았지만 mAP 65%에서 멈췄다. 추후에 다른 모델의pretrained weight와 구현코드를 구해보거나 내가 직접 pretrained weight에 맞춰 구현해봐야 할 것 같다.
2. Complete the web
- 프로젝트의 초점이 모델 성능 향상에 집중되었기 때문에 웹에 대한 기능구현이 많이 필요한 상태이다. 추후에 여유가 된다면 무인 결제 시스템의 기본적인 기능을 추가하면 좋을 것 같다.
3. Add Data
- 실제 마트에서는 훨씬 다양한 제품(class)가 있다. 그렇기 때문에 현실에서 적용하기 위해서는 엄청나게 많은 데이터가 필요할 텐데 이 많은 데이터를 어떻게 구할 것이며 다양한 class에서의 성능을 어떻게 높일 수 있을지 고민을 많이 해봐야 할 것 같다.
End
모든 코드를 직접 구현하면서 다른 좋은 코드를 많이 보다보니 새로운 코드를 보았을때 이전에는 전체를 보지 못하고 코드 레벨만 보고 막막해서 한줄한줄 코드를 해석했었는데 이제는 내가 원하는 부분을 빠르게 찾고 코드의 핵심을 파악하는 능력이 생긴 것 같다.
정말 어려운 코드는 딥러닝과 관련된 부분이 아니라 pre processing과 post processing의 tricky한 부분이라고 생각한다. 특히 computer vision에서는 필수인 pre processing, post processing 그리고 visualization에 대한 연습을 kaggle에서 많이 하면 좋을 것 같다.
플레이 데이터에서의 6개월간의 교육과정이 끝났다.
이 과정에서 내가 얻어간 것은 교육과정에서 배운것들이 아니라 어떻게 무엇을 공부해야 하는지 인 것 같다.
6개월간 도와주신 강사님과 동기님들 감사합니다.

Keep going
발표자료 및 코드
ppt:drive.google.com/file/d/1yS8vYuBwW2hC4LYKH9Tn-eI6DSLnuclN/view?usp=sharing
Code: https://github.com/visionhong/Vision/tree/master/project/Fruit%20Detection
Leave a comment