
[Part.2] Image Classification on MLOps
Content
1. Define Persistent Volume Claim
2. Kubeflow Pipeline
3. Preprocessing
4. Hyperparameter Tuning (weights and biases)
5. Model Training & Test (kfp)
6. Model Versioning (mlflow)
7. Model Serving (bentoml)
8. Monitoring (prometheus & grafana)
지난 포스팅에서 Kubeflow pipeline을 작성하여 Kubeflow dashboard에 pipeline을 등록하였다. 이제 pipeline을 실행하면서 각 컴포넌트의 결과값을 살펴보자
3. Preprocessing
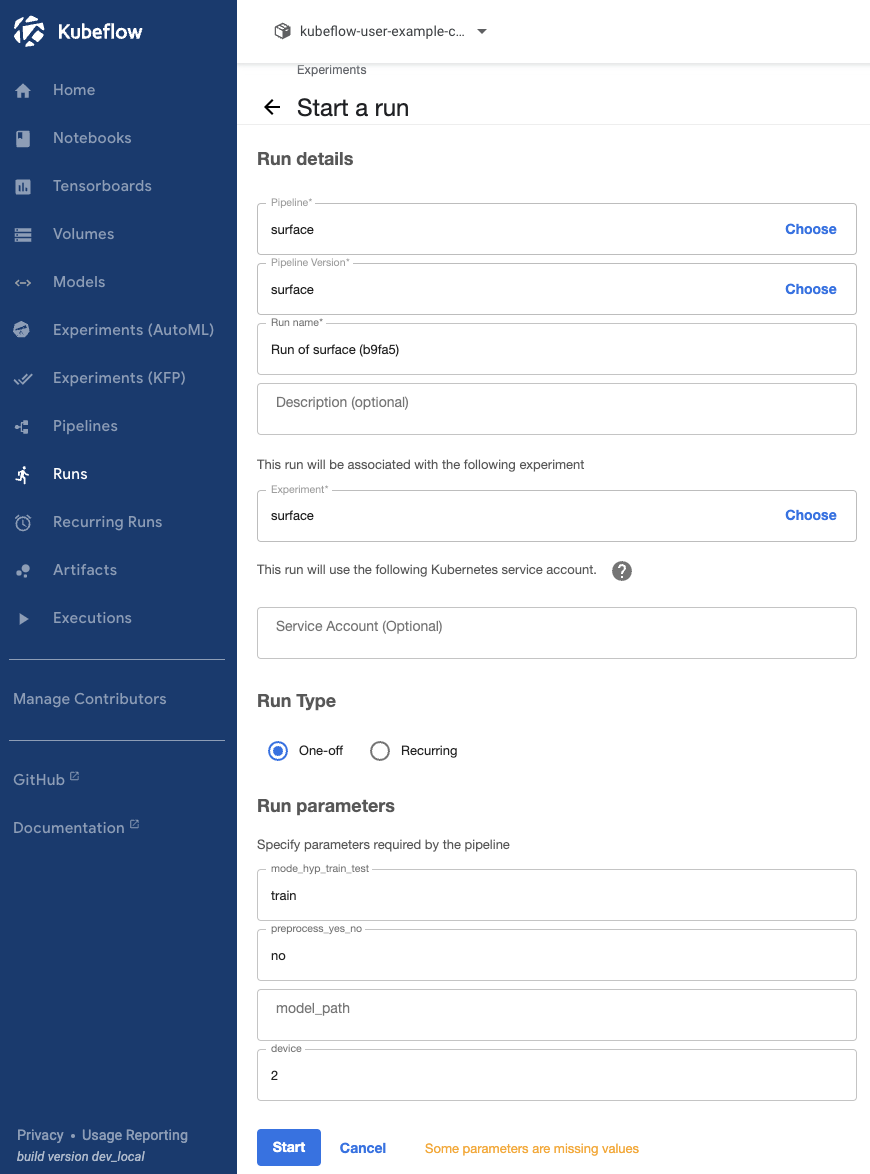
surface pipeline에서 create run을 클릭하면 아래와 같은 화면이 나오게된다.
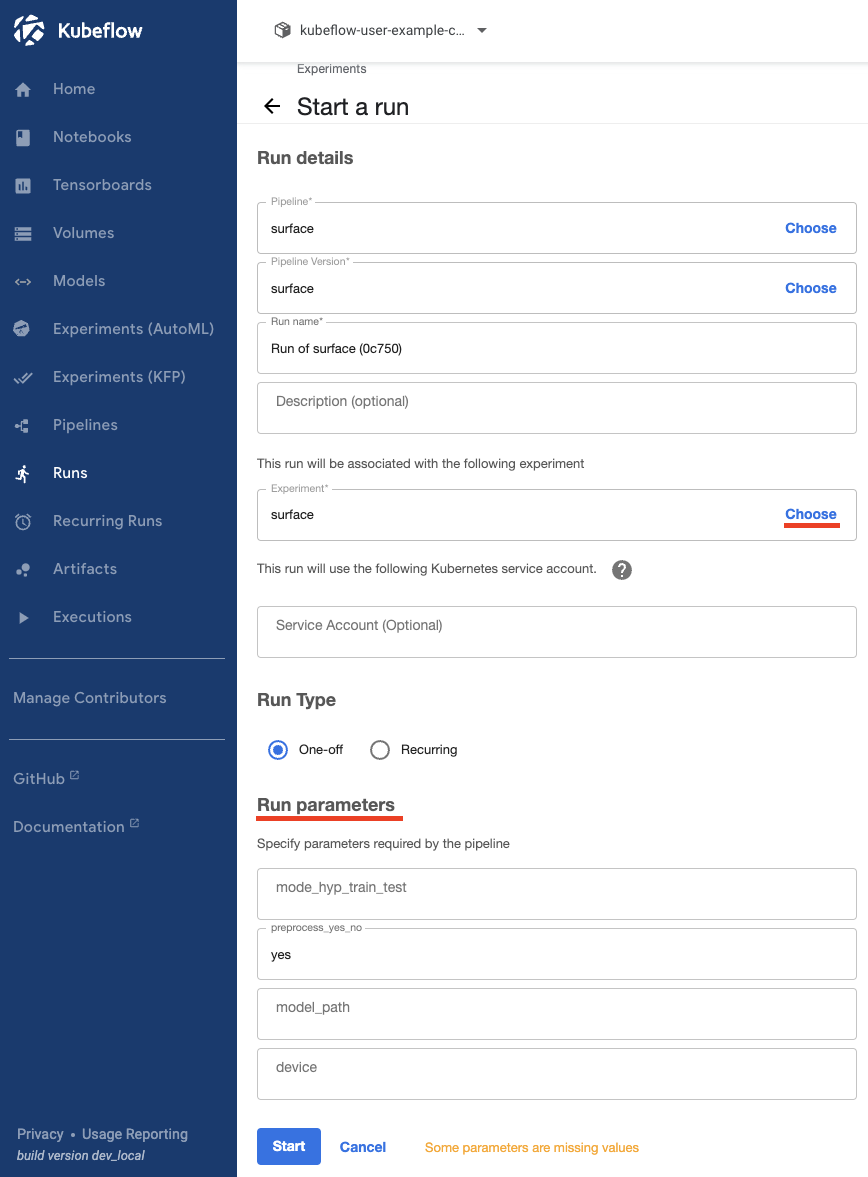
- 중간에 Experiment choose를 클릭한 뒤 이전에 생성한 surface Experiment를 선택한다.
- 하단 Run parameters에서 실행에 필요한 파라미터를 작성해주면 된다.
- mode_hyp_train_test : hyp, train, test중 한가지를 적으면 해당 일을하는 컴포넌트가 실행된다.
- preprocess_yes_no : yes를 적으면 전처리를 진행하고 no를 적으면 전처리를 하지 않는다.
- model_path : test시에 필요한 모델의 s3 주소를 적어야 한다.
- device : 해당 run에서 사용될 gpu 번호를 적는다. (0, 1, 2, 3 or cpu)
- 지금은 전처리만 진행할 것이기 때문에 preprocess_yes_no에 yes로 적고 나머지는 공백으로 두었다.
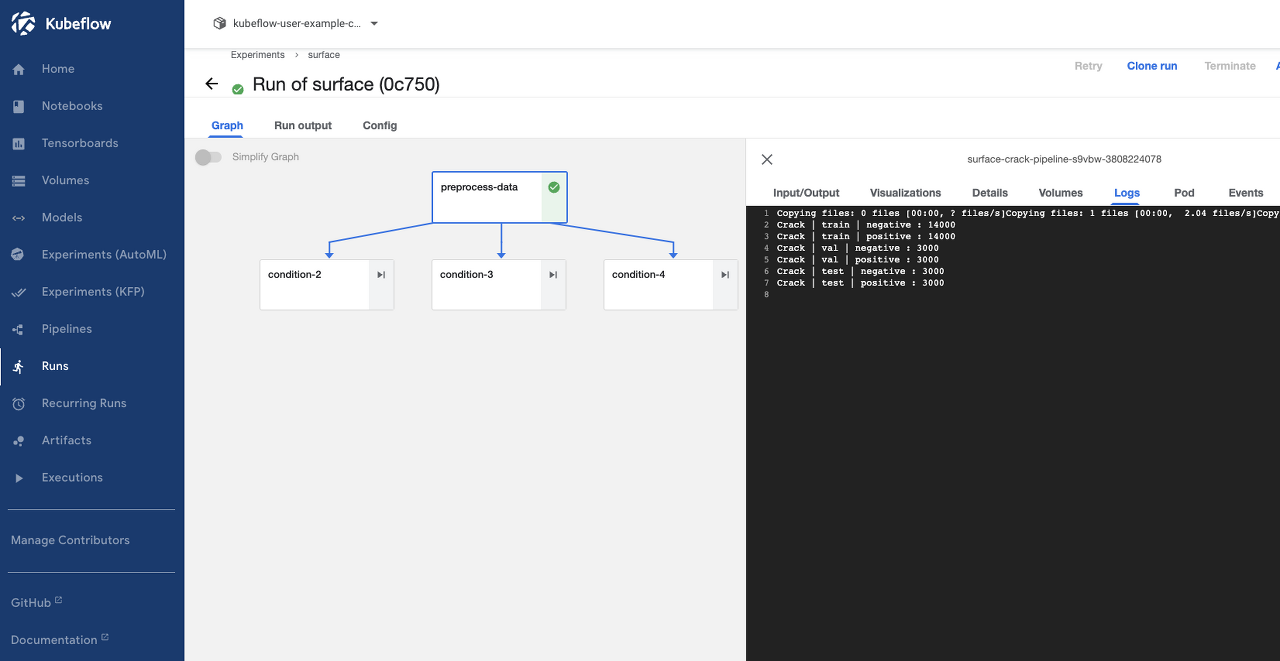
Start를 클릭하면 run이 실행되면서 사용자가 선택한 파라미터에 따라 다른 DAG가 생성된다. 위 그림은 run이 완료된 후의 모습이며 preprocess-data 컴포넌트의 Logs에서 파이썬파일의 print문이 log로 남아있다.
kubeflow 설치 가이드에 따라했다면 user의 Kubeflow Profile이 kubeflow-user-example-com 네임스페이스로 지정되어 있다. 해당 네임스페이스의 pod를 살펴보면 실행한 run(pod)가 Completed 된 것을 볼 수 있다.
kubectl get pod -n kubeflow-user-example-com | grep surface

전처리에서는 평균과 표준편차를 계산하여 txt파일을 저장하고, dataset을 나누는 일을 한다. 아래 PV의 상태를 보면 정상적으로 작동한 것을 볼 수 있다.

4. Hyperparameter Tuning
하이퍼 파라미터 튜닝은 wandb의 sweep 기능을 활용하도록 하였다. UI는 wandb 홈페이지에서 확인할 수 있다.
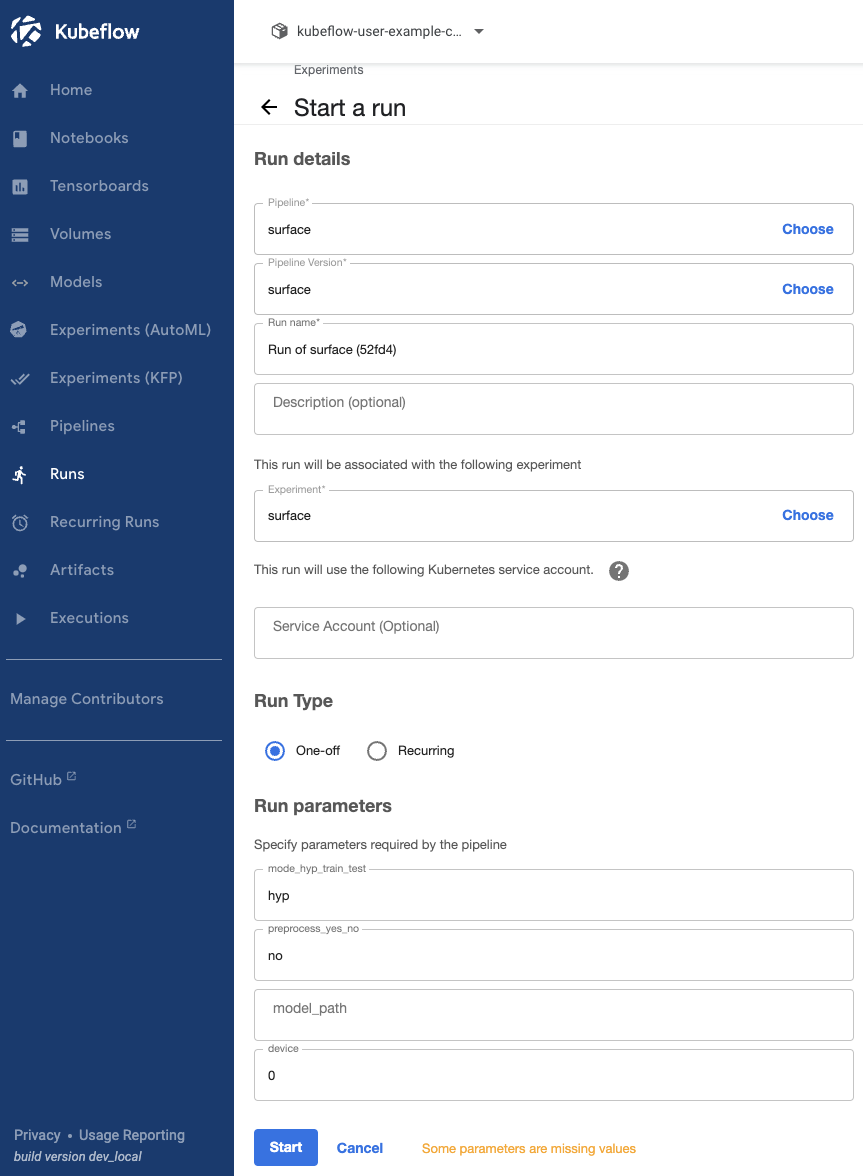
- 하이퍼 파라미터 튜닝을위해 hyp, 전처리는 이미 진행했으므로 no, GPU는 0번을 작성하였다.
DAG
Weights & Biases UI
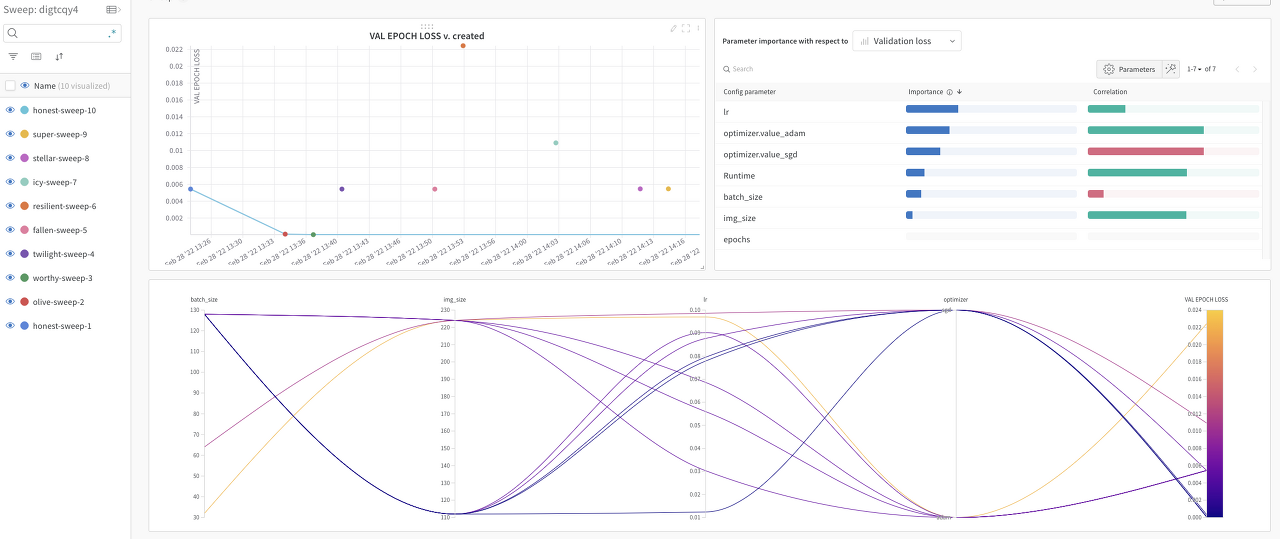
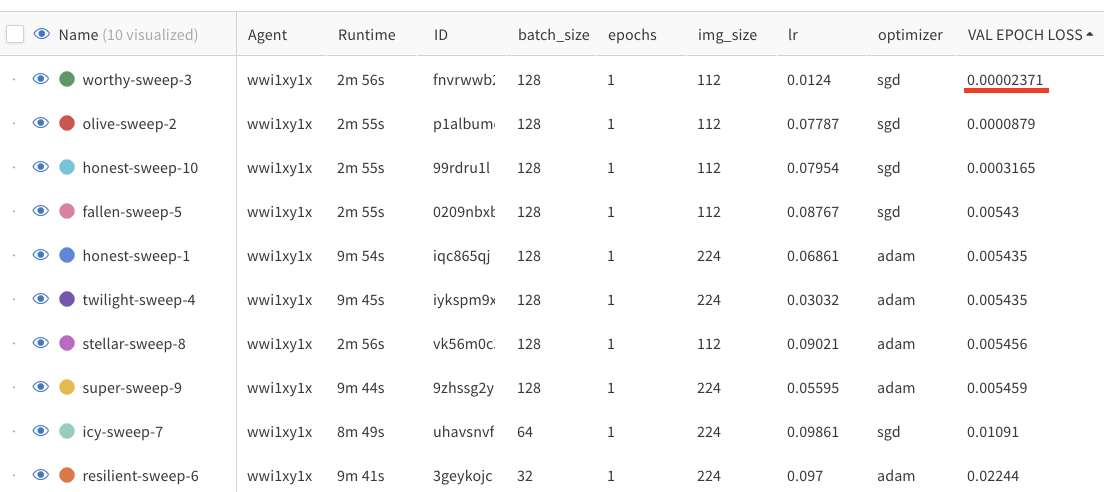
- 위 그림과 같이 wandb는 유연하고 깔끔한 UI를 제공한다는 장점이 있다. 위 테이블을 통해 실행한 sweep에서 가장 성능이 좋은 파라미터를 얻을 수 있다.
- sweep 결과를 보면 optimizer로 adam을 사용할 때, lr가 클 때 성능이 좋지 않다는 것을 알 수 있다.
- 모델이 워낙 간단하기 때문에 Train에서 sweep에서 얻은 최적 파라미터를 사용하지는 않았고 임의로 설정하였다. (sweep에서 얻은 파라미터를 코드에 적용하려면 kubeflow pipeline을 실행할때 image size, learning rate, optimizer를 직접 입력할 수 있게 추가해야 한다.)
5. Model Training & Test
Train
- train mode, 전처리x, 2번 GPU
DAG
Result(컴포넌트 log 일부)
| Epoch: 1. Validation. Loss: 0.006 | accuracy: 99.917: 100% | ██████████ | 94/94 [00:26<00:00, 3.51it/s] |
- 데이터셋이 너무 쉬워서 1 epoch만에 99.917% validation accuracy가 나왔다. 모델은 minio에 artifact로 저장이 되었고 이를 mlflow experiments 메뉴에서 확인할 수 있다. 아래 mlflow UI에 접속을 하면 surface Experiments에 run이 생성된 것을 볼 수 있다.
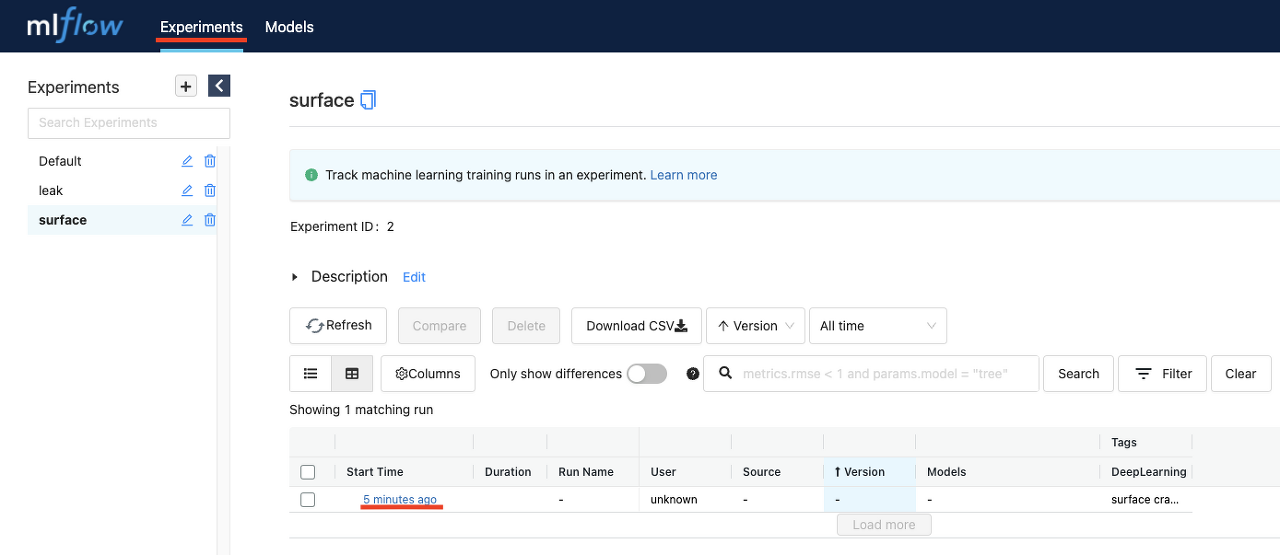
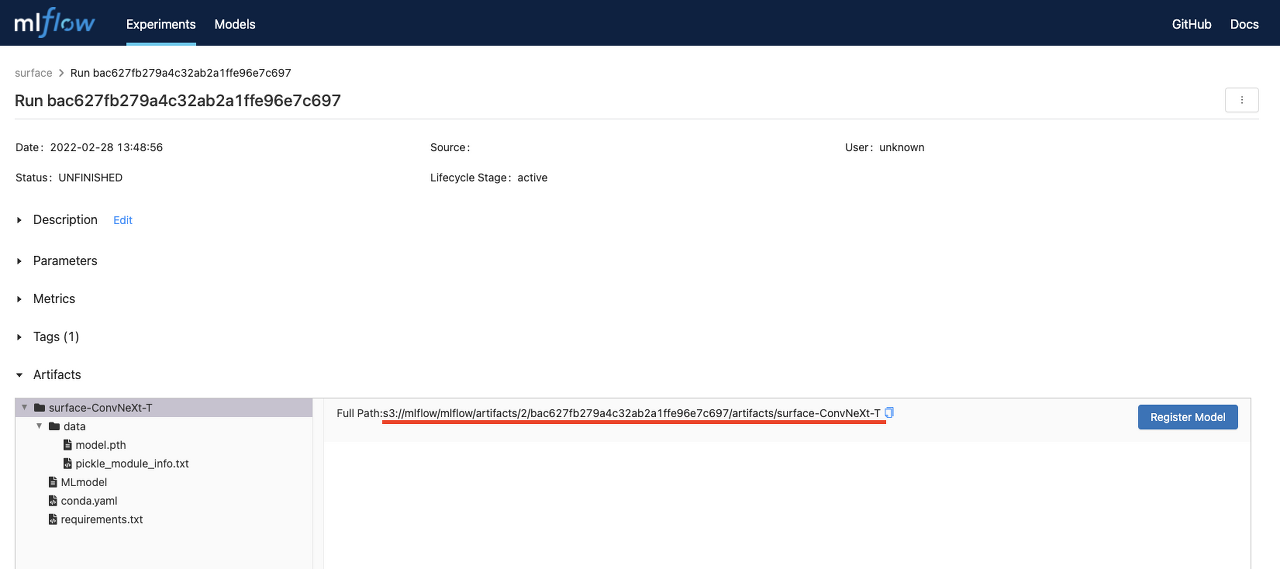
해당 run을 클릭하면 아래와 같은 화면이 나오게 되는데 빨간 밑줄이 쳐진 부분이 해당 run의 model S3주소이다. 이 주소는 모델이 minio에 artifact로서 저장이 되어있다는 것을 의미한다.
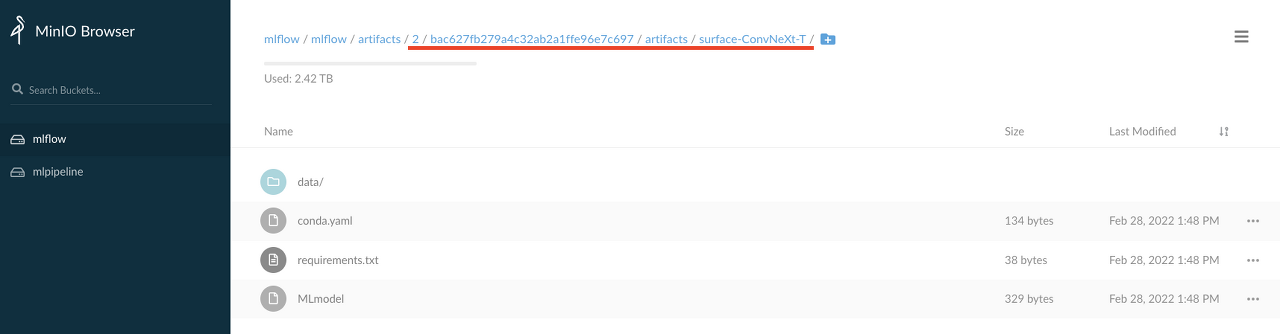
MiniO Browser에 접속해보면 실제로 방금 실행한 run id 경로로 정보가 저장되어 있는것을 알 수있다. minio는 S3주소를 공유하지만 현재 쿠버네티스 환경은 Cloud가 아닌 On-premise 환경이기 때문에 실질적으로는 클러스터(리눅스 서버)의 저장공간을 사용한다.
Test
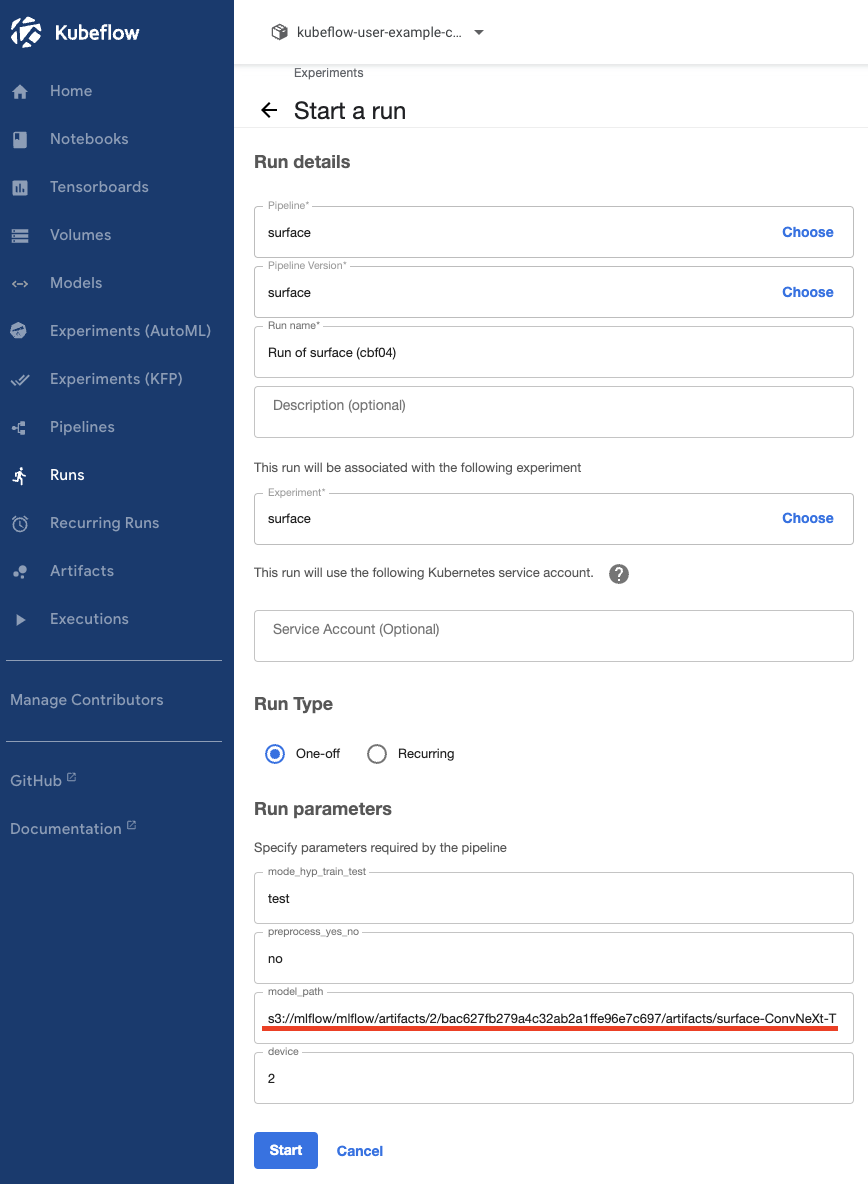
- mlflow에서 S3주소를 복사해 parameter에 입력한다.
- test mode, 전처리 x, 2번 GPU 사용
DAG
Result(컴포넌트 log 일부)
| Test. Loss: 0.007 | accuracy: 99.851: 100% | ██████████ | 94/94 [00:33<00:00, 2.83it/s] |
- Validation과 유사하게 Test에서도 99.851이라는 높은 정확도가 나왔다.
다음 포스팅에 이어서 Model Versioning, Serving, Monitoring에 대해 다뤄보자
Leave a comment