
On-premise에서 오픈소스로 MLOps 구축하기
Purpose
- 기존 IoT 시스템에 ML 개발 및 운영 자동화를 위해 MLOps 플랫폼 구축
Goal
- On-premise 환경에서 오픈소스만을 활용
- 머신러닝 파이프라인 자동화
- 데이터 유효성 검증
- 무중단 배포
Key Point
1. CI
- Data Scientist를 위한 작업공간이 필요하다.
- 코드가 push되면 github tag와 도커 이미지를 같은 tag 버전으로 생성하는것을 자동화한다.
Kubeflow Jupyterlab에서 데이터분석을 할 수 있으며 작성한 코드를 github repo에 push하면 Github actions workflow에 의해 현재 코드를 새로운 태그로 자동 생성하고 생성된 태그 버전으로 코드변경이 일어난 컴포넌트에 대해 도커 이미지를 build & push
2. Private Registry
- 각 프로젝트의 컴포넌트별로 생성되는 도커 이미지를 private registry에서 관리해야 한다.
- docker hub, github packages registry에서 private 이미지를 제대로 관리하기 위해서는 유료계정이 필요하다.
Open Source Private registry인 Harbor에서 Web UI로 이미지를 관리하고 이미지를 kubeflow 컴포넌트에서 활용
3. 데이터 버전 관리
- 데이터는 모델의 성능에 큰 영향을 미치기 때문에 지속적인 학습을 위해 지속적으로 데이터를 수집한다.
- 특정 모델이 어떤 데이터셋으로 학습되었는지 알 수 있어야 한다.
- 데이터가 버저닝되면 inference 데이터와 비교하여 통해 데이터 검증을 진행할 수도 있다.
코드를 Github에서 관리하므로 Git과 연동되면서 Open Source인 DVC를 통해 kubeflow pipeline 안에서 자동으로 데이터 버저닝
4. 모델 성능비교 및 버전관리
- 일반적으로 손실함수(loss function)가 작을수록 좋은 모델이 되지만 비즈니스 요구사항에 따라 성능비교 기준이 달라질 수 있다.(precision, recall 우선순위 등)
- 모델을 관리할 수 있도록 버저닝이 되어야 한다.
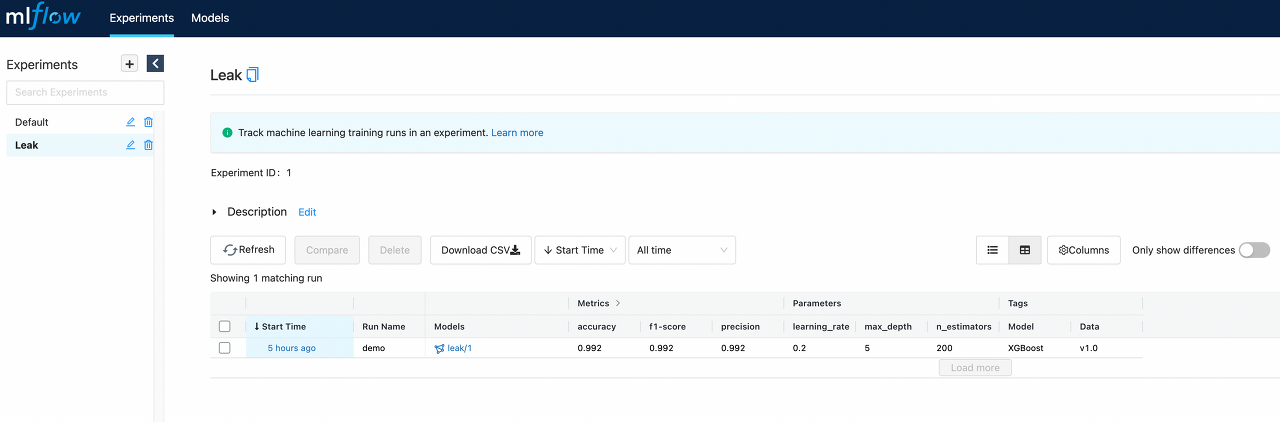
MLflow tracking server 대시보드에 매트릭을 남겨서 다양한 기준으로 모델의 성능을 쉽게 비교하고 모델 버전 까지 한번에 관리
5. 원하는 형태의 데이터인가에 대한 검증(unit test) 필요
- unit test가 필요한 이유는 상황에 따라 데이터가 조금씩 변화(새로운 클래스, 계절성 데이터, 분포 변화 등)하기 때문이다.
- 정상적인 데이터는 어떤 형태인지를 정의하고 실시간으로 들어오는 데이터에 대해 unit test를 진행해야 한다.(ex null값 유무, 최소 최대 평균 값의 범위, concept drift, data drift 등)
- 머신러닝에서는 데이터의 오류가 장애로 이어지기까지 오랜 시간이 걸리기 때문에 데이터가 들어오는 입구 부분에서 데이터를 검증하는 단계를 잘 구축해놓아야 한다.
1. BentoML inference 전처리 단계에서 data 유효성 검증 + Prometheus 모니터링 + Grafana 알람 구성 2. 최근 raw 데이터에 대하여 배치단위로 모델의 성능과 여러가지 drift를 확인하기 위한 “test” kubeflow 컴포넌트 구성(with Evidently)
6. Labeling tool(추가예정)
- 모델을 개선하려고할때 다양한 방법을 시도하지만 결국 데이터가 부족한 문제로 귀결된다.
- 데이터 부족하다면 라벨링을 통해 데이터를 만들어야 하기 때문에 라벨링 툴이 필요하다. (Supervised 기준)
7. AutoML(추가예정)
- 한정된 컴퓨팅 자원을 최대한 활용해서 가장 좋은 모델들을 만들어내는 scalable ai computing이 중요하다.
- 하이퍼파라미터 튜닝, NAS(Neural architecture search)를 통한 모델 아키텍쳐 학습, feature engineering 자동화와 같은 AutoML 기법이 필요하다.
8. Serving
- sync vs Async
- IoT 시스템은 특정 서비스에 ML이 붙어서 작동하는 방식이 아니라 실시간 센서 데이터에 대한 단순 추론 시스템이며 빠른 응답이 중요하다. 그렇기에 비동기 처리에 대한 메리트가 크지 않으며 클라이언트의 요청에 즉시 응답을 할 수 있도록 동기처리 방식으로 처리하는게 더 이점이 있다.
- Offline(Batch) Inference vs Online Inference
- 이상감지 시스템이 중심이기 때문에 실시간으로 추론이 이루어져야 한다. 이상 현상을 늦게 발견 할수록 작게는 비용 문제에서 크게는 인명 피해까지 발생할 수 있다. 그러므로 online Inference가 적합하고 batch Inference는 프로젝트의 특성 및 상황에 따라 추가적으로 가져가야 할 것 같다.
BentoML과 Yatai 조합으로 동기, 비동기 / Adaptive Batching 등의 기능을 활용한 inference 코드를 쉽게 작성할 수 있으며 UI에서 쿠버네티스에 모델 서빙 가능
9. 모니터링
- 서빙중인 모델과 쿠버네티스 클러스터의 실시간 리소스 사용량과 각종 매트릭을 모니터링 해야한다.
- 수집된 매트릭을 Dashboard에서 직관적으로 확인할 수 있어야 한다.
- 특정 조건에 대한 Alert 시스템을 구축할 수 있어야 한다.
Prometheus를 통해 metric을 수집하고 이를 Grafana에서 dashboard로 표현하고 알람조건 설정
Tools

Architecture
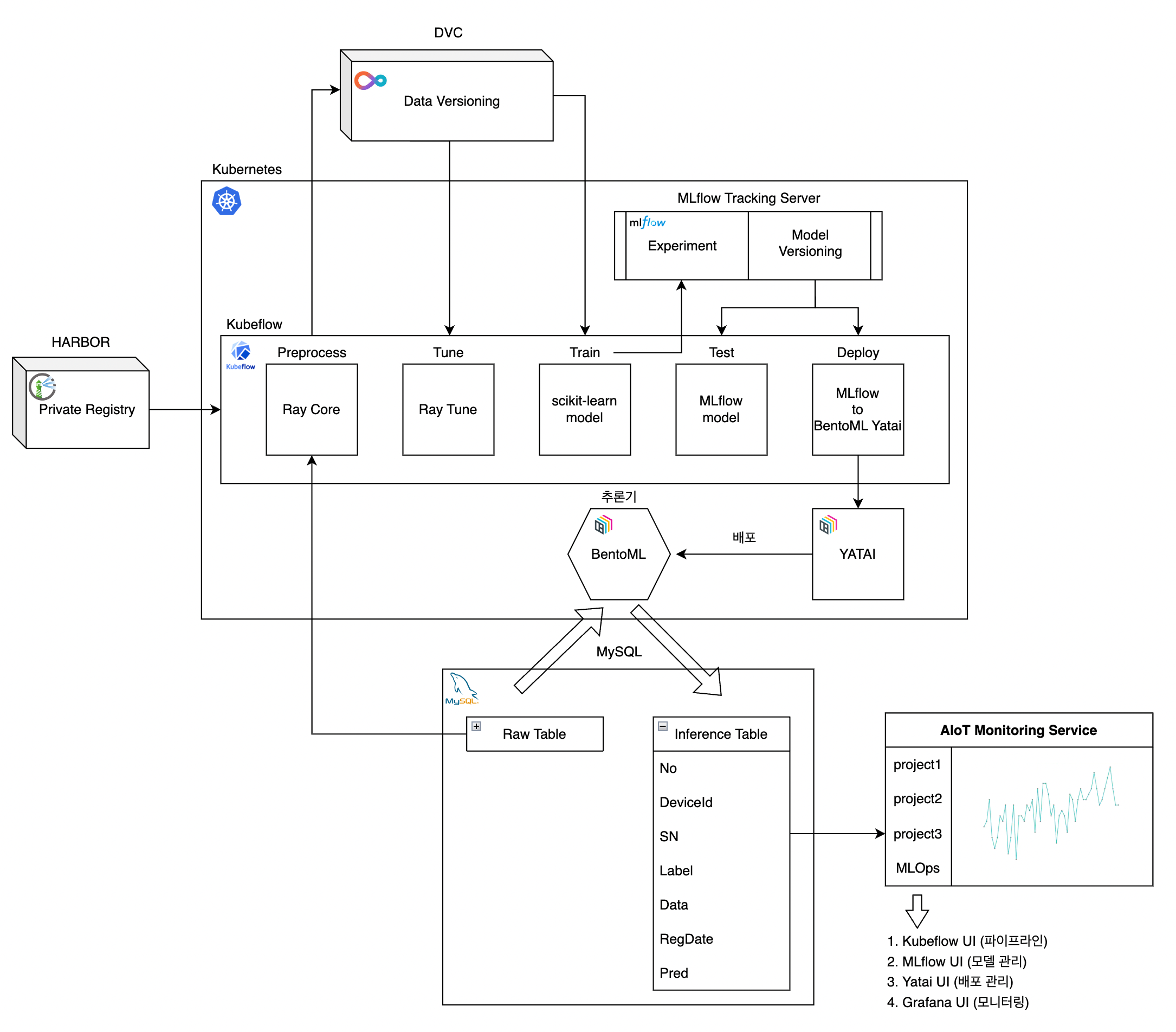
Kubeflow Pipeline
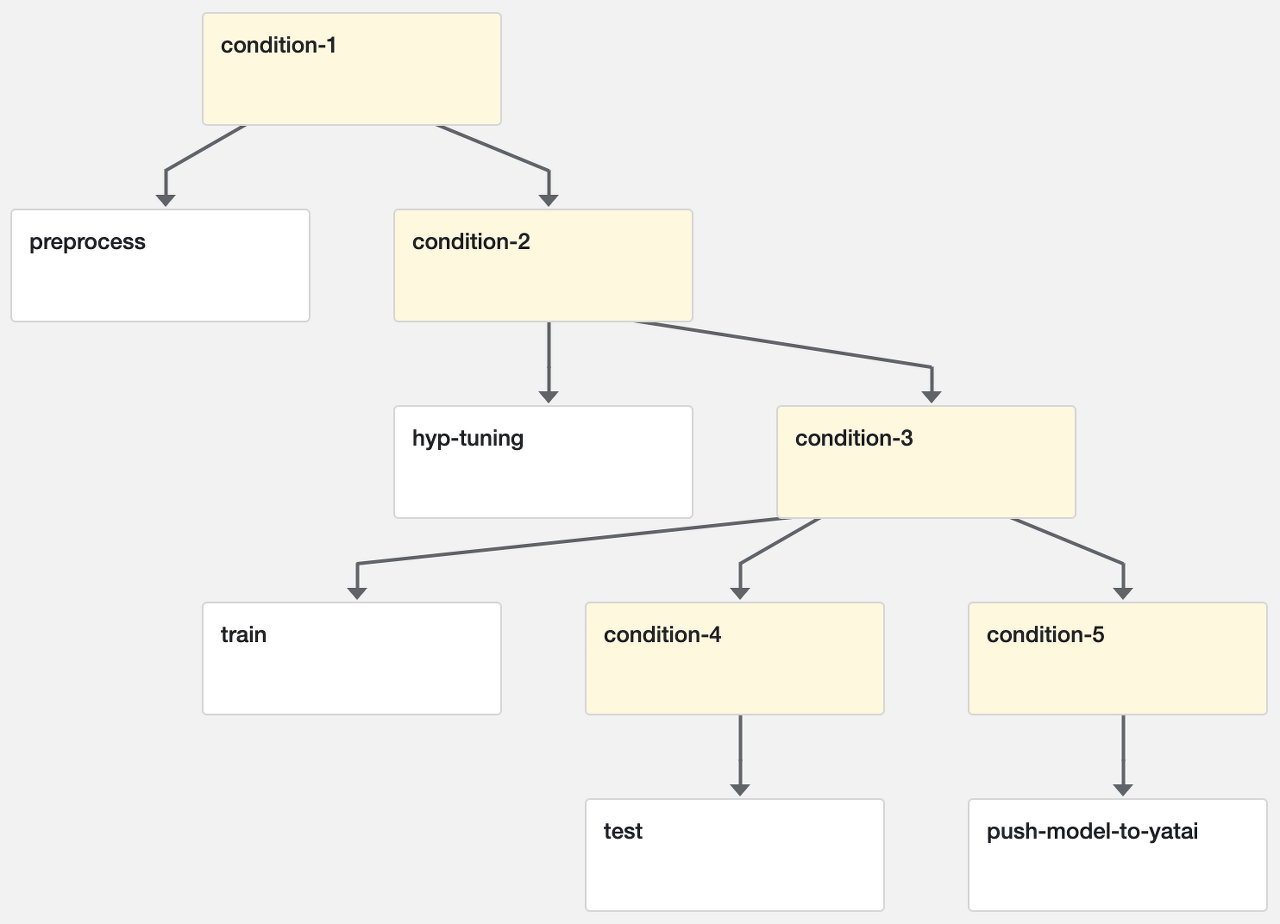
1. Description
- 전처리 컴포넌트부터 모델 배포 컴포넌트까지 한번에 실행할 수 있도록 end2end로 구성하지 않고 특정 컴포넌트만 실행하고자 하는 경우가 있어 condition에 따라 작동하도록 함
- MySQL, Minio, Yatai 접속에 필요한 계정 정보는 사전에 secret yaml 파일을 작성하여 쿠버네티스에 배포시키고 python kubeflow kfp 모듈을 통해 secret 정보를 컨테이너의 환경변수로 가져올 수 있도록 함
2. Component Details
1) preprocess
- Argument
- –query : 전처리 및 버저닝에 사용할 데이터를 가져오는 select 쿼리
- –tag : 저장할 데이터 버전
- Logic
- MySQL DB에 저장되는 Raw 데이터를 쿼리를 통해 가져옴(sql-alchemy, pymysql)
- 각 row의 특정 컬럼에 데이터가 문자열로 들어가 있기 때문에 전처리시에 반복문이 필요하므로분산처리 수행(Ray Core)
- 쉘 스크립트를 통해 전처리된 데이터를 버저닝 (DVC)
- Comment
- 하이퍼파라미터 튜닝과 학습 컴포넌트에서 전처리 과정을 반복하지 않도록 미리 전처리를 하여 데이터를 버저닝 해두는 것이 효율적이라고 판단
(2) hyp-tuning
- Argument
- –tag : 로드할 데이터 버전
- –count : 튜닝 횟수
- Logic
- 쉘 스크립트를 통해 하이퍼파라미터 튜닝에 사용할 데이터 로드
- 하이퍼파라미터 튜닝 수행(Ray Tune - sklearn)
- Best 하이퍼파라미터를 json으로 저장하여 현재 데이터 버전(tag)에 commit & remote repository(GitHub)에 push
- Comment
- 하이퍼파라미터 튜닝 컴포넌트와 학습 컴포넌트가 분리되어있기 때문에 학습 컴포넌트에서 Best 하이퍼파라미터를 사용하기 위해 Best 하이퍼파라미터 정보를 저장 할 필요가 있었고 이를 데이터와 함께 버저닝 하기로 결정
(3) train
- Argument
- –tag : 로드할 데이터 버전
- –run-name : MLflow Experiments에 저장되는 Run name(Folder name)
- Logic
- 쉘 스크립트를 통해 학습에 사용할 데이터와 하이퍼파라미터 정보를 담은 JSON 파일 로드
- 모델 학습 (XGBoost) 및 결과 mlpipeline-ui-metadata로 시각화
- 학습 실험을 MLflow Experiments에 run으로 생성하여 metric 비교
- Comment
- 학습한 모델을 새로운 버전으로 등록할지 말지는 학습 결과나 상황에 따라 정할수 있도록 Experiments run만 생성하도록 구현
- 모델 버저닝은 MLflow dashboard에서 직접 관리
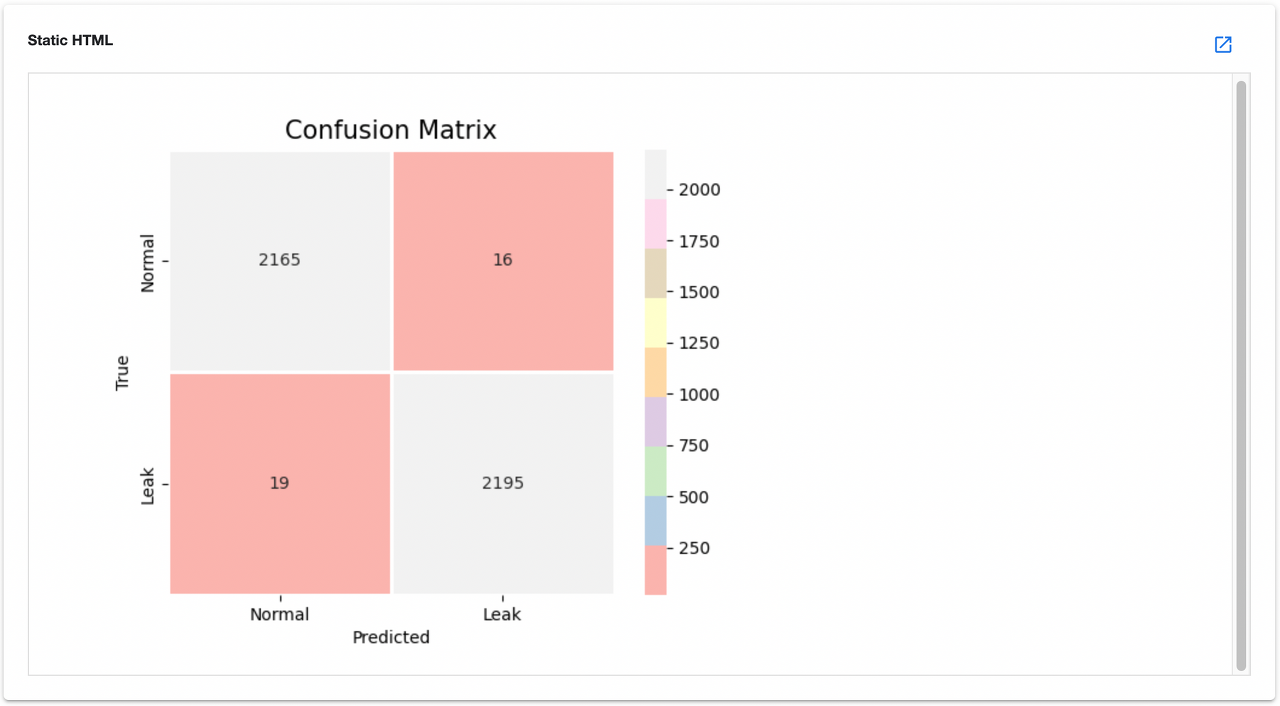
(4) test
- Argument
- –query : model test에 사용할 데이터를 가져오는 select 쿼리
- –model-name : MLflow에서 불러올 모델 이름
- –model-version : MLflow에서 불러올 모델 버전
- Logic
- MySQL DB에 저장되는 Raw 데이터를 쿼리를 통해 가져오고 전처리 수행
- 모델 이름과 버전을 통해 모델 uri를 얻고 mlflow.sklearn.load_model(uri) 함수를 통해 모델 초기화
- 모델 테스트 및 결과 mlpipeline-ui-metadata로 시각화
- Comment
- test 컴포넌트는 MLflow에 등록된 모델이 최근 데이터에 대해 예측을 잘 하는지 파악하고 데이터 유효성 검증을 위해 존재
- 그러므로 데이터는 버저닝된 데이터가 아닌 실시간 Raw 데이터를 가져와야하고 전처리가 필요
(5) push-model-to-yatai
- Argument
- –model-name : MLflow에서 불러올 모델 이름
- –model-version : MLflow에서 불러올 모델 버전
- Logic
- 모델 이름과 버전을 통해 모델 uri를 얻고 bentoml.mlflow.import_model(uri) 함수를 통해 MLflow 모델을 BentoML Models로 저장
- bentoml 명령어를 활용해 yatai로 모델을 build & push
- Comment
- Yatai 에서는 배포 버전관리의 개념, MLflow 에서는 모델 버전관리의 개념으로 활용하기 위해 별도로 관리
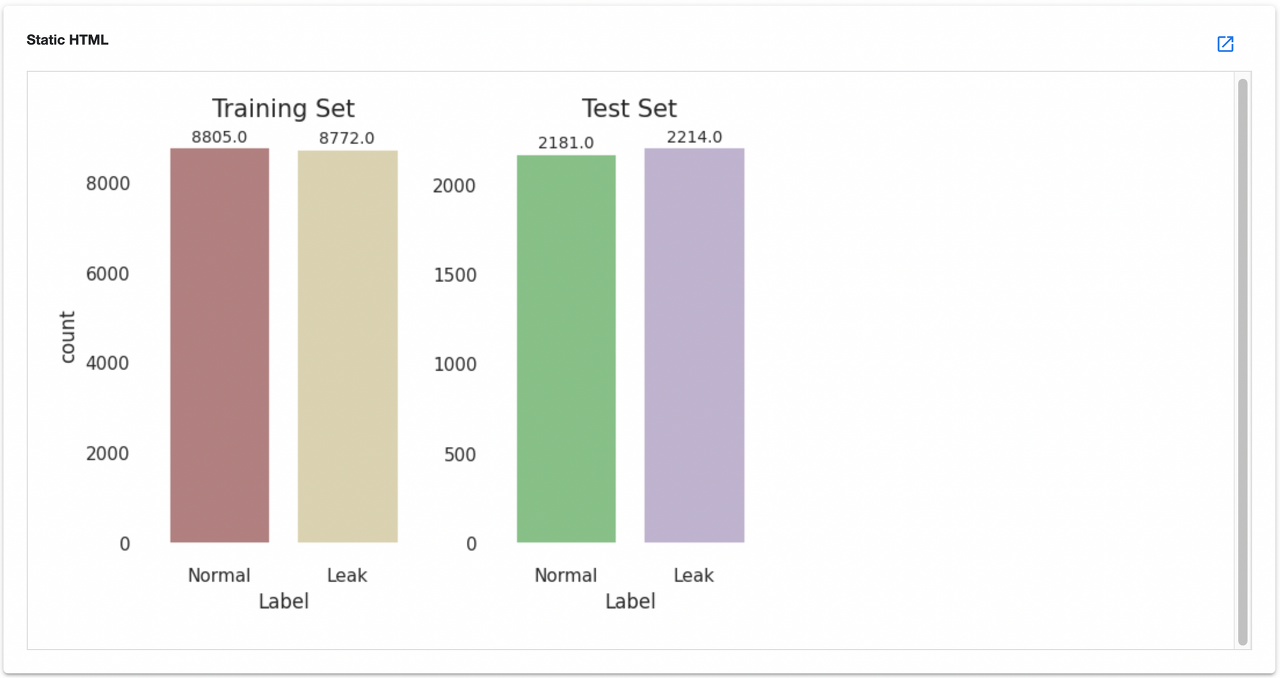
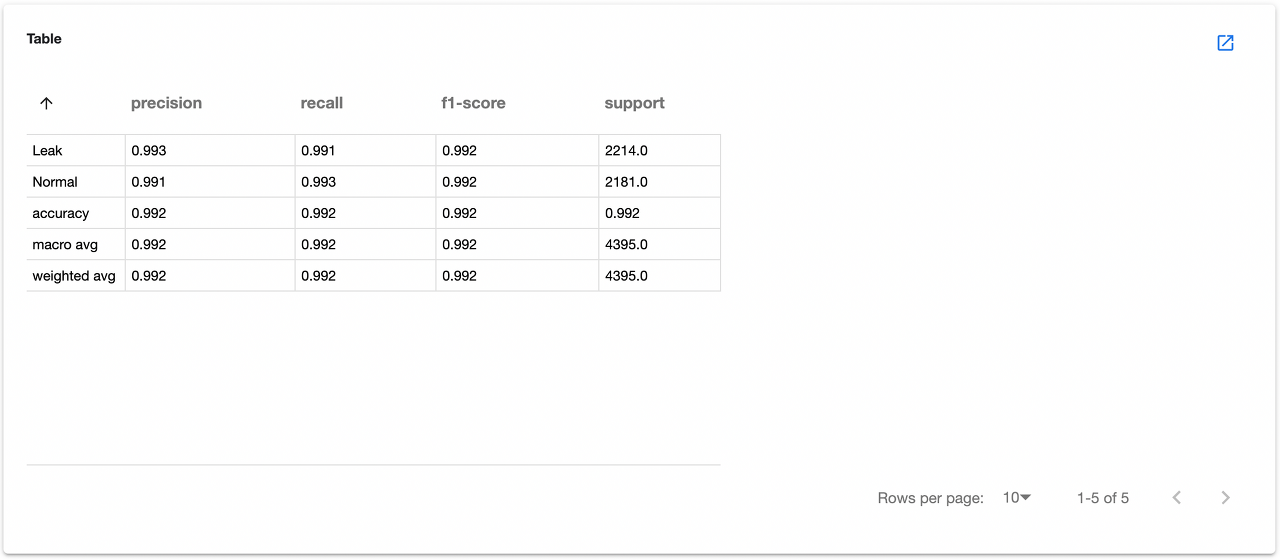
관련 이미지

Leave a comment