
LangChain을 활용한 Image Editor (feat. Streamlit)
Intro
안녕하세요. 이번 포스팅에서는 LangChain과 이미지 생성기술을 활용해서 진행한 토이 프로젝트에 대해 글을 적어보려고 합니다.
LangChain은 LLM에 여러 기능을 붙여 애플리케이션으로 개발할 수 있도록 도와주는 프레임워크입니다. 예를 들어 사용자가 가지고 있는 데이터를 참조하는 문서 챗봇을 만들거나 데이터 프레임으로 Pandas Agent를 생성하여 대화형으로 데이터를 분석할 수도 있습니다.
이외에도 다양한 사례가 있지만 저는 LangChain에서 이미지 생성분야 모델을 활용할 수 있는 방법에 대한 고민을 했고 그것을 Custom Tools를 통해 풀어본 경험을 나누어 보겠습니다.
(LangChain에 대한 자세한 내용은 공식 문서 를 참고해 주세요.)
Project Abstract
Demo
아래 Demo 영상은 Streamlit을 활용하여 간단하게 만든 웹 어플리케이션입니다. 사용자는 이미지를 업로드할 수 있으며 3개의 Drawing Tool(point, rect, freedraw)와 채팅을 활용해서 이미지를 편집할 수 있습니다.
Idea
딥러닝 모델은 정해진 입력을 받도록 설계가 되어있습니다. 당연하게도 이미지를 분류하고 싶으면 이미지를 입력으로 주어야 하고 문장의 빈칸을 예측 하려면 빈칸이 있는 문장을 주어야 합니다.
즉 어떤 모델을 사용하려면 그 모델이 어떤 역할을 하는지 알아야 하고 적절한 입력값이 필요합니다.
여기서 "사용자가 원하는 작업에 적합만 모델을 AI가 선택하고 추론해 준다면 어떨까?" 라는 생각을 하게 되었습니다.
Chat-GPT에서는 Few-Shot prompt를 통해 system에 특정한 역할을 부여할 수 있습니다. (e.g. “넌 이제 한영 번역기야”)
그렇다면 이와 비슷한 맥락으로 특정 모델의 역할과 입력값을 LLM에게 가이드 해주면 해결할 수 있을 것이라고 판단했습니다.
Needs
최근 이미지 생성 기술이 발전되면서 단순히 텍스트에서 이미지를 만들어 내는것 뿐만 아니라 이미지 전체 스타일을 변환하거나, 특정 객체를 지우거나 Inpaint 하는 등 다양한 모델이 연구되고 있습니다.
저는 이런 성격이 비슷한 모델들을 한데모아 Image Editor로 구현해 보았습니다. 기존의 다른 Editor 어플리케이션 대비 장점은 확장성과 더 나은 사용자 경험에 있습니다.
자체 서비스에 AI모델을 갖춘 Editor 어플리케이션이 정말 많아졌습니다. 하지만 기존 서비스에 AI 모델이 추가될수록 각각의 모델을 실행하는 추가적인 도구(버튼)를 제공해야 하므로 어플리케이션이 점점 복잡해 질 것입니다.
또한 사용자 입장에서는 해당 기능을 사용하기 위해서 가이드를 읽고 사용법을 익혀야 한다는 단점이 있습니다.(특정 모델을 사용하기 위해 그 모델이 어떤 역할을 하는지 알아야 하는 것과 동일한 맥락)
하지만 LangChain을 활용한다면 Editor에서 원하는 작업을 채팅으로 입력하면 자동으로 적합한 모델을 실행할 수 있습니다. 즉 각 모델의 역할만 부여해 준다면 어플리케이션을 확장하기 쉬우며 사용자가 따로 추가되는 기능에 대한 학습을 할 필요가 없으므로 사용자 경험 관점에서 이점이 있습니다.
Details
Custom Tools
LangChain에서 자신만의 Agent를 생성하기 위해서는 Tools를 리스트로 담아야 합니다. 이 Tools는 특정 기능을 하는 함수 혹은 클래스가 됩니다.
LangChain의 Tool 모듈에서 웹 검색, 연산 등 몇가지 기본적인 툴을 지원하지만 자신만의 툴을 사용하기 위해서는 Custom Tools를 정의해야 합니다.
Custom Tools는 아래 파라미터를 포함하는 데코레이터+함수 조합 혹은 클래스로 정의할 수 있습니다.
name(str): 실제 기능을 담은 함수의 이름을 문자열로 작성합니다.description(str): tool의 역할을 작성합니다. agent가 어떤 툴을 선택할지 판단할 때 사용되는 매우 중요한 파라미터입니다.return_direct(bool): True로 사용할 시 tool의 return값을 agent output으로 직접 전달합니다. default 값인 False로 두면 agent의 output은 입력에 대한 문자열 답변이 됩니다. (일반적으로 챗봇에서 False로 두고 사용)args_schema(Pydantic BaseModel): pydantic을 사용하여 입력 파라미터 타입에 대한 유효성 검증을 수행합니다.
아래는 실제 사용예시 입니다.
from pydantic import BaseModel, Field
from typing import Optional, Type
from langchain.tools import BaseTool
def image_transform(pil_image, prompt):
if st.session_state["coord"] == False: # 마스크가 없다면 이미지 전체 변환(pix2pix)
transform_pillow = instruct_pix2pix(pil_image, prompt)[0]
else: # 마스크가 있다면 특정 영역 inpaint
mask = Image.fromarray(st.session_state["mask"])
transform_pillow = sd_inpaint(pil_image, mask, prompt)
class ImageTransformCheckInput(BaseModel):
prompt: str = Field(..., description="prompt for transform the image")
class ImageTransformTool(BaseTool):
name = "image_transform"
description = """
Please use this tool when you want to change the image style or replace, add specific objects with something else.
"""
return_direct=True
def _run(self, prompt: str):
pil_image = st.session_state["inference_image"][st.session_state["image_state"]]
transform_pillow = image_transform(pil_image, prompt)
return transform_pillow
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
args_schema: Optional[Type[BaseModel]] = ImageTransformCheckInput
위와 같이 모델 추론을 위한 함수, 유효성 검증을 위한 pydantic 클래스, Custom Tools 총 3가지가 필요합니다.
Custom Tools인 ImageTransformTool 클래스에 대한 설명은 다음과 같습니다.
name: 실제 모델을 추론하는 함수 이름과 동일하게image_transform으로 작성합니다.description: 이미지 스타일 바꾸거나 특정한 객체를 다른 객체로 변환할때 사용되는 툴이라고 명시를 해주었습니다. 이렇게 되면 사용자의 입력 프롬프트가 이미지 변환과 관련된 문장이라면 agent가 이 툴을 선택하게 됩니다.return_direct: 변환된 이미지를 return 해야 하기 때문에 True로 설정하였습니다._run: 실제 Tool이 실행하고자 하는 작업을 작성합니다. 여기서image_transform함수를 사용해 모델을 추론할 수 있습니다. (_arun메서드는 비동기 처리와 관련된 메서드입니다.)args_schema:ImageTransformTool은 입력 파라미터로 prompt를 받기 때문에 문자열 Pydantic을 사용합니다.
Agent
LangChain의 Agent는 특정 목적을 달성하기 위해 계속해서 다음 동작을 생각하고 추론해 나가는 도구입니다. (LangChain에서 기본적으로 제공하는 Agent는 여기를 참고해 주세요.)
직접 Custom Agent를 생성하고자 할때는 initialize_agent 를 사용할 수 있습니다.
아래는 실제 사용 예시입니다.
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
initialize_agent(
agent=AgentType.OPENAI_FUNCTIONS,
tools=[ImageTransformTool()],
llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo",
request_timeout=120),
max_iterations=1,
verbose=True
)
initialize_agent 함수의 필수 파라미터는 tools와 llm 입니다. tools는 위에서 정의한 Custom tools의 클래스를 초기화하여 리스트안에 담아보냅니다. 물론 여러개의 Tool을 담아서 agent가 추론과정에서 상황에 적합한 툴을 선택하게 할 수 있습니다.
주의할 점은 Tool 개수가 증가할수록 의도된 Tool을 사용하지 않고 엉뚱한 Tool을 선택할 확률이 증가하기 때문에 Custom Tools의 description에 역할을 명확히 구분지어 명시해야 합니다.
llm은 agent가 추론 과정에서의 생각 및 응답을 하는데에 사용됩니다. Image Editor에서 llm 자체의 의존성은 낮기 때문에 어떤 llm을 선택해도 차이는 없습니다.
PromptTemplate
PromptTemplate를 활용하여 Agent에 프롬프트를 입력할때 시스템에 role을 부여할 수 있으며 Custom Tools의 입력 파라미터를 전달하는 용도로도 사용할 수 있습니다. 예시는 아래와 같습니다.
from langchain import PromptTemplate
def image_editor_template(prompt):
prompt_template = PromptTemplate.from_template(
"""
prompt: {prompt}
Make sure prompt must be in English when using the tool.
"""
)
prompt = prompt_template.format(prompt=prompt)
return prompt
먼저 template 내용을 살펴보면 prompt 변수를 중괄호 안에 넣었습니다. 이 프롬프트는 Custom Tools의 매개변수로 활용됩니다.
특정 문자열을 중괄호로 묶게 되면 format 함수에서 매개변수로 활용할 수 있습니다. 만약 문자열 자체에 중괄호가 포함되어야 한다면 {{문자열}} 과 같이 이중 중괄호를 사용하면 됩니다.
그리고 사용자의 입력 프롬프트를 영어로 바꿔서 Custom Tools에게 전달하도록 role을 부여하였습니다. prompt가 필요한 모델의 경우 영문장으로 학습되었기 때문에 한국어 보다는 영어에서 훨씬 더 잘 동작하기 때문입니다.
이렇게 하지 않고 번역 역할을 하는 Custom Tools를 추가로 생성하여 번역 후 모델을 실행하는 방법을 고려할 수 있지만 LLM에게 번역을 맡기는 것이 경험적으로 훨씬 자연스러웠습니다.
Streamlit
Streamlit은 머신러닝을 위한 웹 어플리케이션을 쉽고 빠르게 만들수 있도록 도와주는 python 라이브러리입니다. (Streamlit에 대해 조금 더 자세히 알고 싶은 분들은 공식문서를 참고해 주세요.)
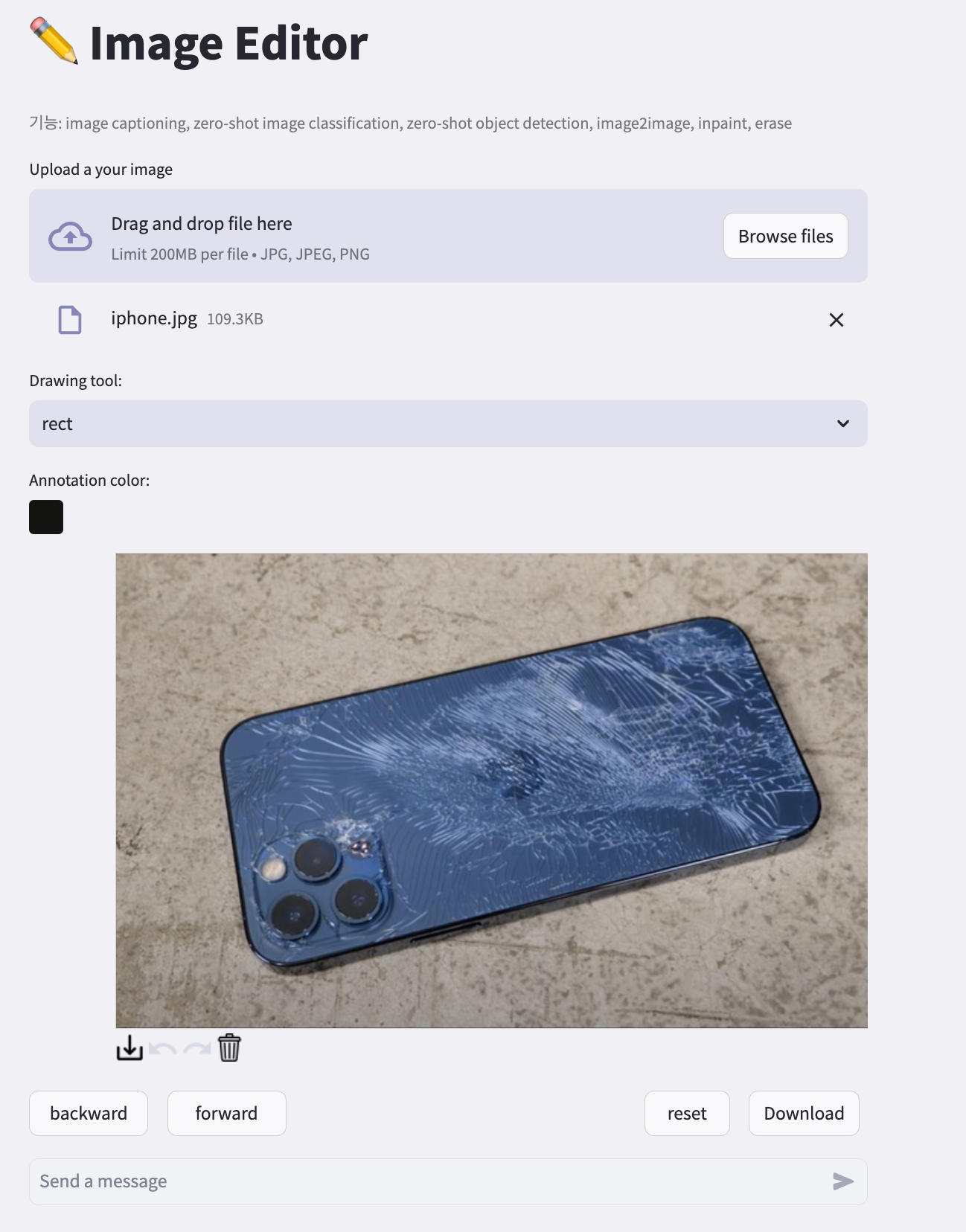
이 프로젝트에서는 Streamlit으로 아래 기능을 활용했습니다.
- 이미지 업로더: 사용자가 편집하고자 하는 로컬 이미지를 drag & drop 으로 서버에 업로드
- Drawing Tool: Fabric.js로 제작된 외부 컴포넌트활용
- Chat: Agent의 입력 프롬프트로 전달되는 채팅창
- state 관련 버튼: backward, forward 버튼으로 원하지 않은 결과가 나왔을 때 되돌릴 수 있으며 Download 버튼으로 완성된 이미지를 로컬에 다운받고 Reset 버튼으로 원본으로 복구
Streamlit으로 UI를 구성하면서 가장 중요했던 기능은 streamlit.session_state 입니다. Streamlit은 어떤 행동(버튼 클릭 등)을 하게 되면 세션이 reload 되어 코드가 처음부터 다시 실행되기 때문에 streamlit.session_state를 활용하여 재실행이 필요 없거나 상태를 유지해야 하는 변수를 캐싱할 수 있습니다.(이 내용은 공식문서의 예제를 통해 확인하는 것을 추천드립니다.)
Issue
프로젝트를 진행하며 이런 생각이 문득 들었습니다.
마스킹 결과를 유저가 확인하도록 해야 할까?
사용자가 Drawing Tool을 사용해서 point 혹은 box를 그린 후 inpaint 관련 요청을 한다면 내부적으로 SAM을 먼저 실행하여 객체의 마스크를 얻고 그 뒤에 inpainting을 수행하게 됩니다.
이때 point의 경우 마스킹 기준이 애매(사람 상체를 클릭 했을 때 옷을 의미하는지 사람을 의미하는지 와 같은 상황)하기 때문에 여러 부위를 클릭해야하는데 현재 masking 상태를 알 수 없다는 문제가 있습니다.
여러곳을 클릭해서 객체를 확실히 해야한다는 정보 자체가 사전지식을 필요로 하는 것이므로 사용자 경험 관점에서 좋지 못한 방법이라고 판단 했습니다.
그래서 Drawing Tool을 채팅과 별도로 분리하여 point와 box를 칠 때마다 SAM을 실행하고 그 결과를 이미지에 masking 하도록 변경하였습니다.
e.g.

1 point

2 point
이렇게 되면 사용자가 자신이 의도한 객체를 확실히 할 수 있기 때문에 좀 더 좋은 결과를 제공할 수 있습니다. 그리고 SAM이 자주 실행되는 만큼 추론시간을 단축하기 위해 경량화 모델인 Mobile-SAM을 선택하였습니다.
변경 전 후 파이프라인은 아래와 같습니다.
before:
Drawing tool -> 채팅으로 이미지 편집 -> SAM -> Image Generation -> 변환된 이미지 확인
after:
Drawing tool -> SAM -> 마스킹 확인 -> 채팅으로 이미지 편집 -> 변환된 이미지 확인
What to do next
Image Editor는 Demo 영상 기준으로 4개의 모델을 사용하고 있습니다.(Instruct Pix2Pix, Stable Diffusion Inpainting, lama-cleaner, Mobile-SAM)
대부분 Transformer 기반의 딥러닝 모델을 사용하고 있으며 CNN과 비교하면 결코 가벼운 모델이 아니기 때문에 CPU 보다는 GPU를 사용해야 사용 가능한 수준입니다.
현재는 Streamlit의 @st.cache_resource 데코레이터를 활용하여 모델을 로드해두고 scratch로 추론을 수행하고 있습니다.
하지만 scratch 추론 방법은 처리 가능한 요청 수에 제한이 있어 확장성(scalability)에 문제가 있으며 자체적으로 버전 관리를 해야하기 때문에 모델 관리가 어려워집니다.
그래서 Nvidia Triton Server를 활용해 Image Editor에 API 형태로 제공하는 방향을 선택하였습니다. Nvidia Triton Server는 위 한계점들을 보완하면서 multi model을 최적의 GPU 리소스로 추론할 수 있습니다.
각 모델을 TensorRT로 변환하고 Nvidia Triton Server를 배포하는 과정은 추후에 2편으로 찾아오겠습니다. 감사합니다.
Reference
Code: https://github.com/visionhong/langchain-cv
Leave a comment