
Drift Detection with Evidently
Drift는 머신러닝에서 실제 운영 환경에서의 머신러닝 모델의 성능이 시간이 지남에 따라 천천히 나빠지는 것을 설명하는 용어입니다. Drift는 입력 데이터의 분포가 시간이 지남에 따라 변경되거나 입력(x)와 목표(y) 사이의 관계가 변경되는 등 여러 이유로 발생할 수 있습니다.
MLOps 환경에서 빼놓을 수 없는것이 데이터 유효성 검증입니다. 실제 운영환경 데이터에 대하여 Null값이 있는지, 최소 최대값이 threshold 값을 넘어가는지에 더하여 모니터링을 통해 Drift를 감지할 수 있다면 모델 재학습에 대한 기준으로 삼을 수 있습니다.
이번 포스팅에서는 모델이 Drift하는 이유, Drift의 다양한 유형, 그리고 이를 감지하는 알고리즘 및 Drift 감지 오픈소스 라이브러리를 통해 Drift가 감지되는 과정을 보도록 하겠습니다.
Drift?
“Drift” 는 머신러닝 모델을 학습하는데 사용된 데이터의 통계적 특성이 시간이 지남에 따라 변경되는 것을 말합니다. 이로 인해 모델이 원래 설계된대로 동작하지 않거나 정확도가 떨어지게 됩니다. 다시말해 “Drift”는 모델이 사용되는 환경의 변화로 인해 예측 성능이 감소하는 현상이라고 할 수 있습니다.
머신러닝 모델이 Drift되는 이유는 여러가지가 있습니다. 가장 일반적인 이유 중 하나는 학습에 사용된 데이터가 오래되거나 현재 조건을 더 이상 대표하지 않는 것 입니다.
예를 들어, 과거 데이터를 기반으로 부동산 가격을 예측하는 모델을 생각해봅시다. 안정적인 시장의 데이터로 모델을 훈련시키면 초반에는 잘 작동할 수 있지만 시간이 지나면서 부동산 시장이 불안정해지면 데이터의 통계적 특성이 변경되어 모델이 부동산 가격을 정확하게 예측하지 못할 수 있습니다.
Drift의 유형
1. Concept Drift(Target Drift)
Concept Drift는 모델이 학습한 데이터와 예측 데이터와의 특징이 달라지는것을 의미합니다. 단어 그대로 데이터가 가지고있는 컨셉이 달라지는 것. 즉 예측하고자 하는 대상이 바뀌는 현상이라 할 수 있습니다.
예를 들어 OTT 서비스를 이용하는 사용자의 클릭 데이터를 수집하고 분석했다고 합시다. 그런데 시간이 지나면서 사용자의 성격을 따르던 클릭패턴이 다른 요인으로 변화할 수 있기 때문에, 이전과는 다른 새로운 패턴이 나타날 수 있습니다.
또 다른 예시로는 금융 분야에서 신용카드 사기 탐지 모델을 학습시켰다고 해봅시다. 이 모델은 고객의 결제 내역을 기반으로 사기 여부를 판단합니다. 그런데 만약 사기꾼들이 새로운 방식으로 사기를 시도한다면 모델이 잘 예측할 수 있을까요?
이런 상황을 Concept Drift가 발생했다고 합니다.
2. Data Drift
Data Drift는 입력데이터의 분포가 시간이 지남에 따라 변경될 때 발생하는 현상으로, covariate shift 라고도 합니다.
예를 들어, 고객의 연령과 소득을 기반으로 제품 구매 가능성을 예측하는 모델을 학습했다고 합시다. 그런데 고객들의 연령과 소득 분포가 시간이 지남에 따라 변화하기 때문에 오래된 모델은 더 이상 구매 가능성을 정확하게 예측하지 못할 수 있습니다.
또, 여름에 수집한 데이터셋으로 학습된 모델을 겨울에 활용한다면 이때도 Data Drift로 인해 구매 가능성 예측 성능이 떨어질 것입니다. 계절마다 소비자의 소비패턴, 즉 분포가 다르기 때문입니다.
Drift는 모델의 성능에 직결되는 문제이기 때문에 실제 운영단계에서 머신러닝 모델을 활용하려면 Concept Drift와 Data Drift를 방지하거나 완화할 수 있도록 조치를 취하는 것이 중요합니다.
Drift를 감지하는 방법
Drift를 감지하는 방법은 크게 두가지가 있습니다.
- 통계적인 검정
- 머신러닝 모델
통계적인 검정중에 일반적으로 잘 알려진 방법은 PSI, KL Divergence, JS Distance, Wasserstein distance, K-S test 등이 있습니다. 이 방법들이 어떻게 Drift 감지에 사용되는지 알아보겠습니다.
PSI(Population Stability Index)
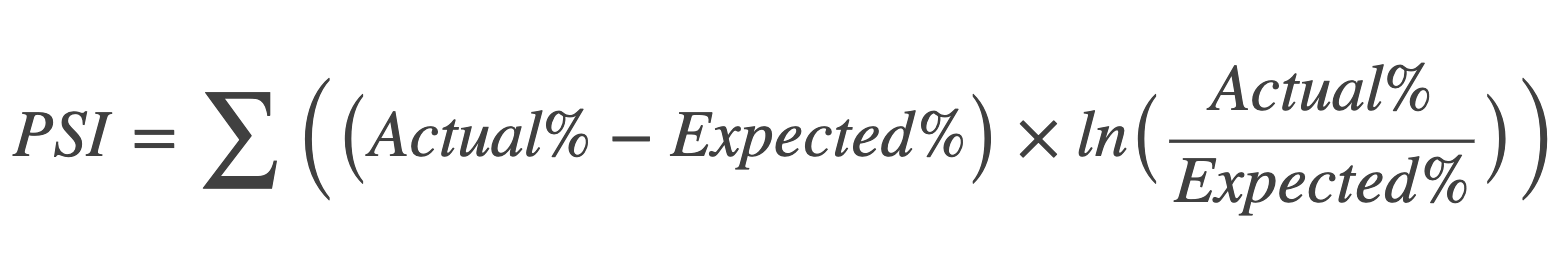
Population Stability Index(PSI)는 학습 데이터와 검증 데이터가 서로 동일한 분포에서 추출되었는지를 평가하는 데 사용되는 지표입니다.
PSI는 각 데이터 집합의 분포의 차이를 계산하여 나타냅니다. PSI 값이 낮을수록 두 데이터 집합의 분포가 유사하고 안정적이며, PSI 값이 높을수록 두 데이터 집합의 분포가 다르고 불안정해집니다.
일반적으로, PSI 값이 0.1 미만이면 안정적이며, 0.25 이상이면 불안정하다고 판단합니다.
KL(Kullback Leibler) Divergence
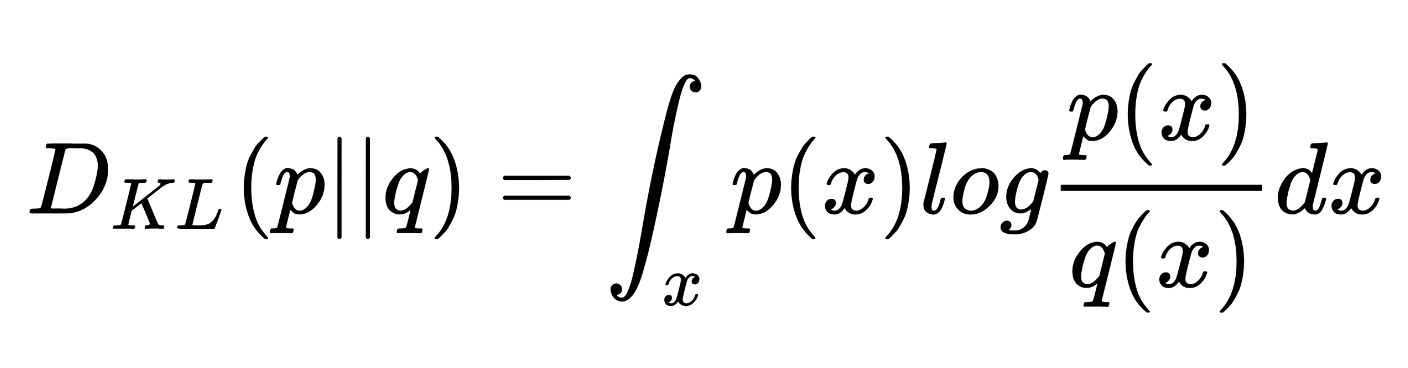
KL Divergence는 정답값의 분포(p)에서 예측값의 분포(q)가 상대적으로 얼마나 다른지를 수치적으로 계산한 값입니다. KL Divergence는 relative entropy(상대 엔트로피)라고도 불립니다.
위 식을 전개하면 KL-Divergence를 Cross Entropy - Entropy로 나타낼 수 있습니다. 이말은 즉 불확실성을 가지는 비트수 - 최소한의 비트수 이므로 KL-Divergence는 항상 0과 같거나 큰 값이 나오게 됩니다.
여기서 Entropy는 상수값이기 때문에 일반적으로 머신러닝 학습에서는 KL-Divergence를 minimize하기 보다는 연산이 적은 Cross Entropy를 minimize하게 됩니다.
이 개념을 Drift 감지에 적용하면 학습데이터를 기준으로 검증 데이터의 분포가 얼마나 다른지를 계산하여 일정 값 이상으로 KL Divergence가 증가하면 Drift가 발생했다고 판단할 수 있습니다.
PSI가 두 데이터 집합의 분포 차이를 단순히 계산하는 반면, KL divergence는 두 분포의 차이를 보다 정량적으로 측정하여 데이터 드리프트를 감지합니다. 또한 PSI는 데이터 집합의 크기에 민감하게 반응하지만, KL divergence는 데이터 분포 자체의 차이를 측정하므로 데이터 분포의 크기에 영향을 받지 않습니다.
JS(Jenson-Shannon) Distance
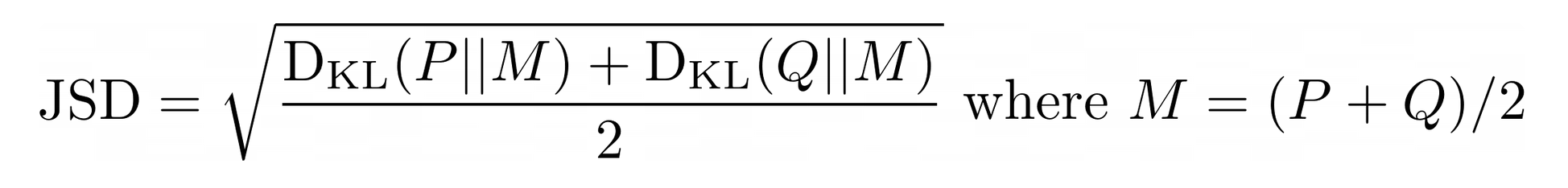
JS Distance는 KL Divergence의 변형된 형태로, 두 확률분포의 거리를 구하는데 사용됩니다. JS Distance는 두 확률분포의 중간지점(M)에 대한 두개의 KL Divergence의 평균으로 정의됩니다. 그러므로 비대칭이 없고, 항상 0과 1 사이의 값을 가지며 두 분포가 같을경우는 당연히 0이됩니다.
이때도 적절한 Threshold 를 설정하여 Data Drift감지에 활용할 수 있습니다.
Wasserstein Distance
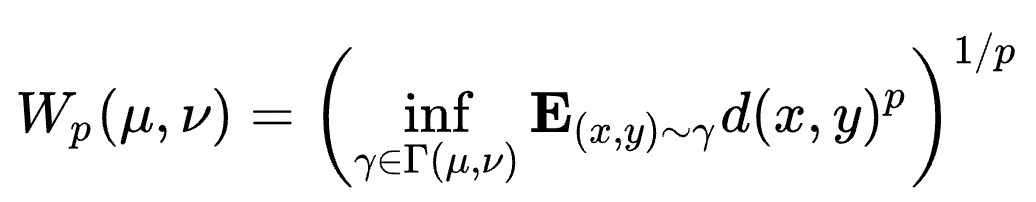
Wasserstein Distance(또는 Earth Mover’s Distance, EMD)는 두 확률분포 간의 거리를 측정하는 방법 중 하나로, Optimal Transport 이론에서 비롯되었습니다. 이 거리는 한 분포에서 다른 분포로 변환(이동)하기 위해 필요한 최소한의 "작업량"을 측정합니다. 이 때 “작업량”이란, 확률 질량을 옮기는 데 드는 비용을 의미합니다.
값은 0에서 무한대까지의 범위를 가질 수 있으며, 두 분포가 동일할 때는 역시 0이 됩니다.
KS(Kolmogorov Smirnov) test
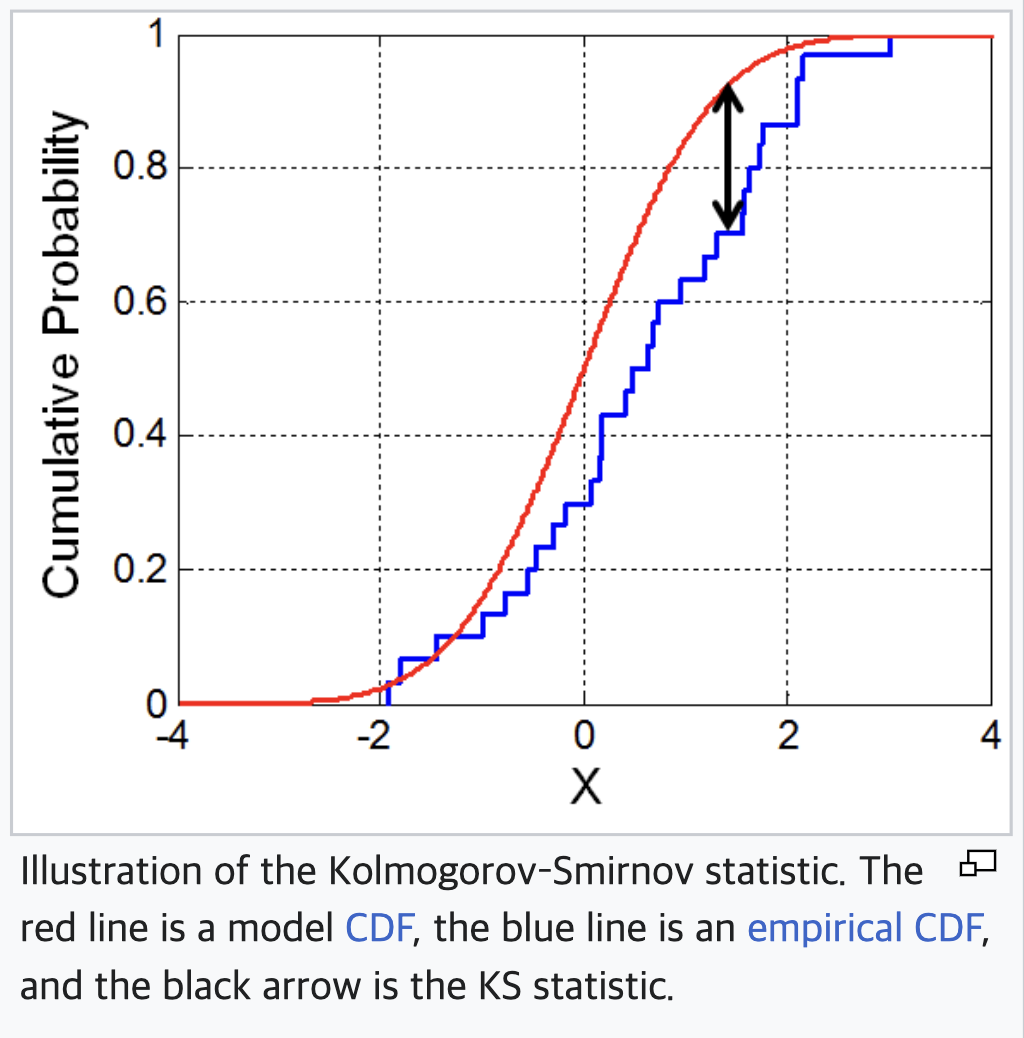
KS(Kolmogorov Smirnov) test는 두 개의 데이터 집합이 동일한 분포에서 추출되었는지를 확인하는 데 사용됩니다. 따라서 데이터 Drift 감지를 위해 KS test를 사용하는 경우, 모델이 예측을 수행하는 시점에서 훈련 데이터와 새로운 데이터의 분포를 비교하고, 이를 통해 데이터 드리프트를 감지할 수 있습니다.
KS test는 두 개의 분포 간의 최대 차이를 측정하며, 이 차이가 미리 정한 임계값보다 크면 Data Drift가 발생했다고 판단합니다. 일반적으로는 훈련 데이터와 새로운 데이터를 동일한 구간으로 나누고, 각 구간에서 누적 분포 함수의 차이를 계산하여 최대 차이를 측정합니다.
KS test는 Data Drift를 빠르게 감지할 수 있는 장점이 있지만, 두 분포 간의 차이를 정확하게 측정하지는 못합니다. 그렇기 때문에 대규모 데이터셋에서 사용하기에는 제한이 있을 수 있습니다.
Data Drift Detection
위에서 소개한 여러가지 통계적인 기법들을 활용하여 머신러닝 Task에 대해 Drift를 탐지할 수 있는 evidently 라는 오픈소스가 있습니다. evidently 라이브러리를 설치하여 샘플 데이터에 대해 Drift를 감지할 수 있는지 테스트해보겠습니다.
evidently는 Drift 이외에도 데이터 요약, 퀄리티 파악, 모델의 예측결과 요약 등 여러 기능을 지원하지만 글의 주제인 Drift를 위주로 사용해보겠습니다.
Evidently는 pip install evidently로 설치 가능합니다. 데이터셋은 evidently에서 제공하는 california_housing toy dataset을 활용하겠습니다.
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset
from evidently.metrics import ColumnDriftMetric
from evidently.test_suite import TestSuite
from evidently.tests import TestNumberOfDriftedColumns
evidently는 분석 방법에 따라 Report와 TestSuite로 나뉩니다. Report는 분석 결과를 요약하고 시각화하는데 사용되며 TestSuite는 정의된 조건에서 합격/불합격에 대한 결과를 반환합니다. 만약 evidently를 유효성 검증 파이프라인에 추가하려면 이 TestSuite를 활용하여 모니터링 할 수 있습니다.
data = fetch_california_housing(as_frame=True)
housing_data = data.frame
housing_data.rename(columns={'MedHouseVal': 'target'}, inplace=True)
# target 값에 가우시안 분포를 더하여 prediction 컬럼 생성
housing_data['prediction'] = housing_data['target'].values + np.random.normal(0, 5, housing_data.shape[0])
reference = housing_data.sample(n=5000, replace=False) # 학습데이터
current = housing_data.sample(n=5000, replace=False) # 검증데이터
데이터셋을 불러오고 전처리 한 뒤에 데이터를 두개로 쪼갭니다. Drift를 감지하려면 기존 학습데이터와 검증데이터가 필요하므로 두가지의 데이터프레임이 필요합니다.
Report
report = Report(metrics=[
DataDriftPreset(),
TargetDriftPreset()
])
report.run(reference_data=reference, current_data=current)
report.show(mode='inline')
Preset() 함수에는 대표적으로 columns, stattest, drift_share 파라미터가 있습니다. columns에 원하는 컬럼을 지정할 수 있고 stattest에 원하는 drift 알고리즘을 선택할 수 있습니다. (Drift 알고리즘 종류는 여기에서 확인하실 수 있습니다. 추가로 Custom drift method를 정의할 수도 있습니다.)
drift_share 파라미터는 Drift 감지에 사용될 데이터의 비율입니다. 이 파라미터가 존재하는 이유는 전체 데이터셋에 대해 Drift를 계산하게 되면 많은 비용이 들기 때문입니다. 일정 비율의 데이터만 사용하면 빠르고 효율적으로 Drift를 검출할 수 있습니다.
그외에도 Thresold 값을 조정하는 stattest_threshold 파라미터도 있습니다. stattest_threshold를 통해 데이터 특성에 맞게 임계값을 Thresold 조정한다면 좀 더 정확한 Drift 감지를 할 수 있습니다.
만약 Preset() 함수에 어떤 파라미터도 입력하지 않으면 모든 컬럼에 대해 Drift를 계산하게 됩니다. 이때 사용되는 알고리즘은 데이터의 특성에따라 자동으로 설정됩니다.
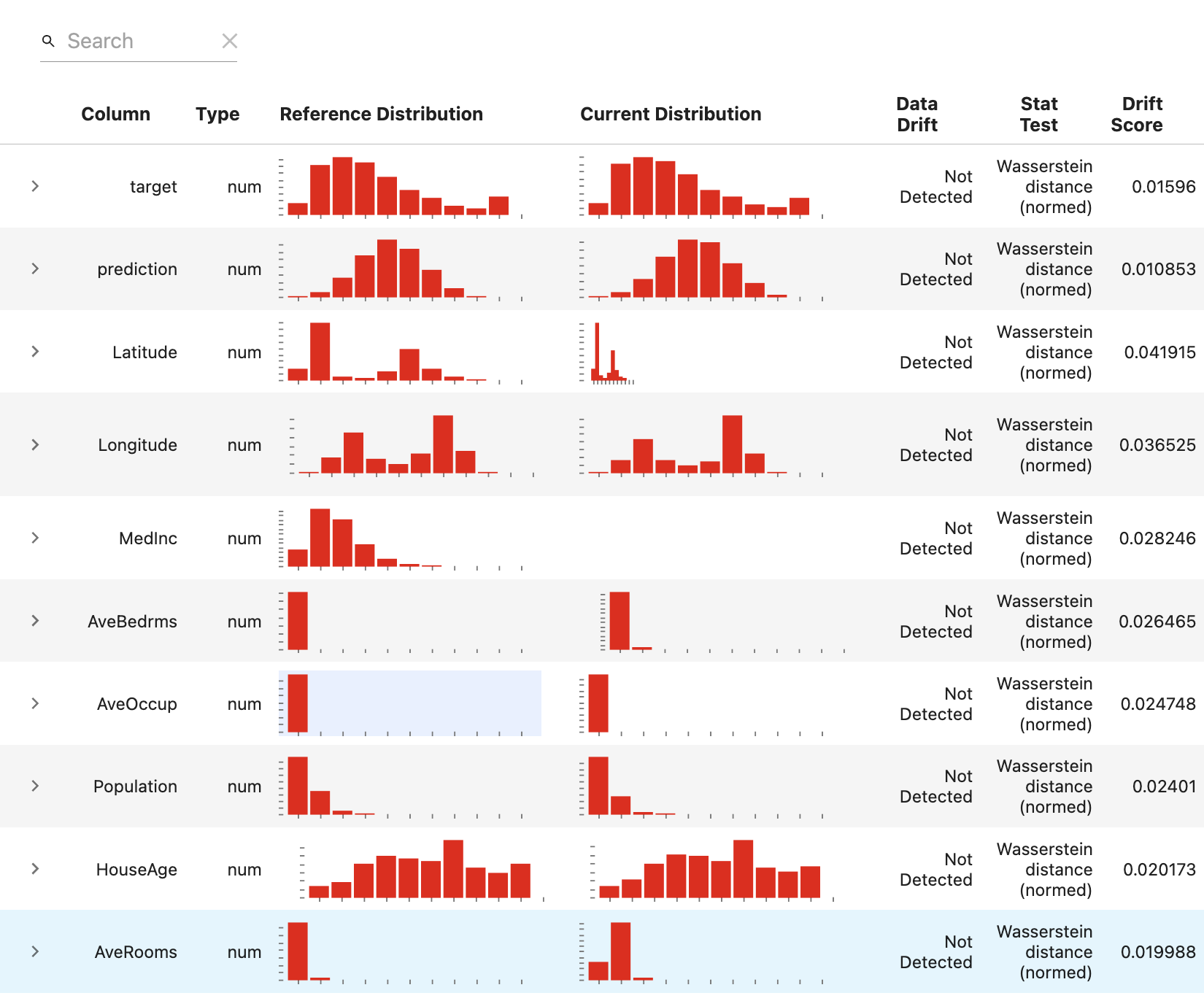
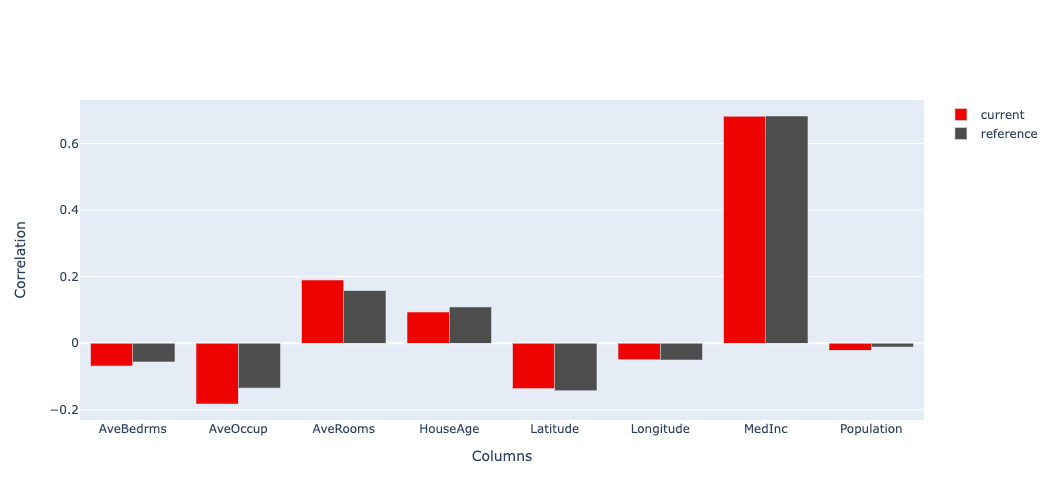
위 결과를 보면 Wesserstein distance가 사용되었고 Drift가 감지되지 않았음을 시각적으로 보여줍니다. 또한 target column과 다른 컬럼과의 상관관계도 확인할 수 있습니다.
output:
Test Suites
tests = TestSuite(tests=[
TestShareOfDriftedColumns(), # 전체 컬럼중 Drift가 발생한 column의 비율
TestNumberOfDriftedColumns(), # Drift가 발생한 column 개수
])
tests.run(reference_data=reference, current_data=current)
tests.save_html("test_drift.html")
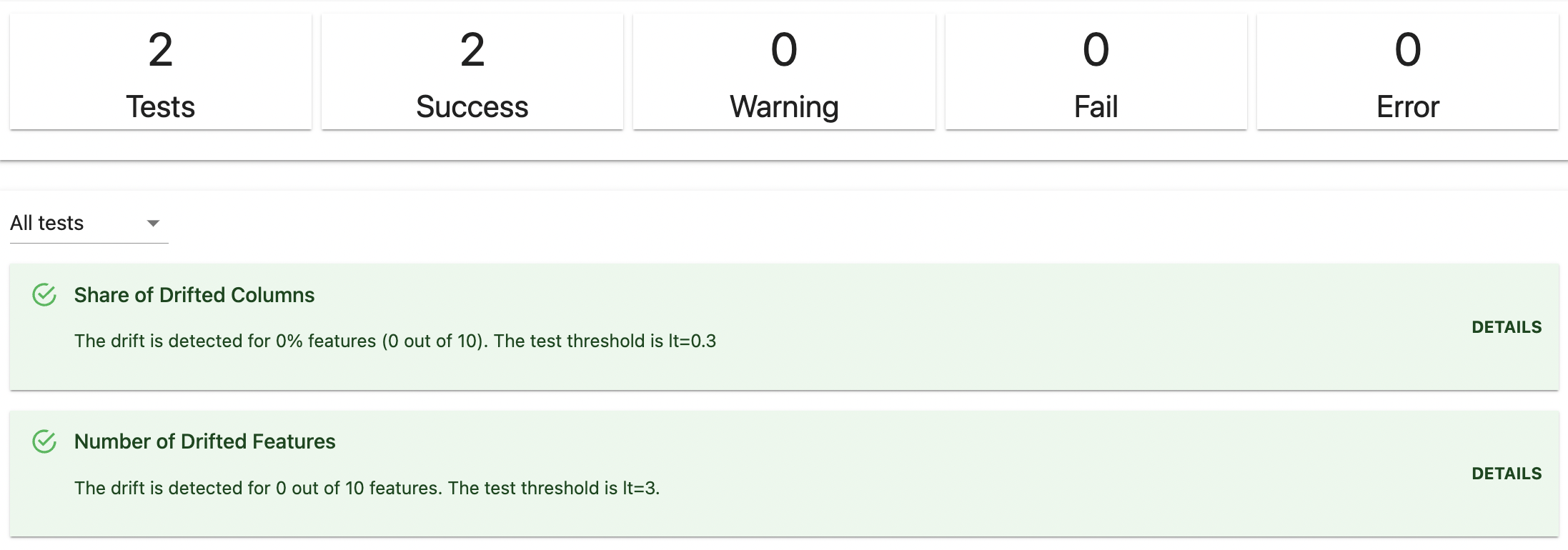
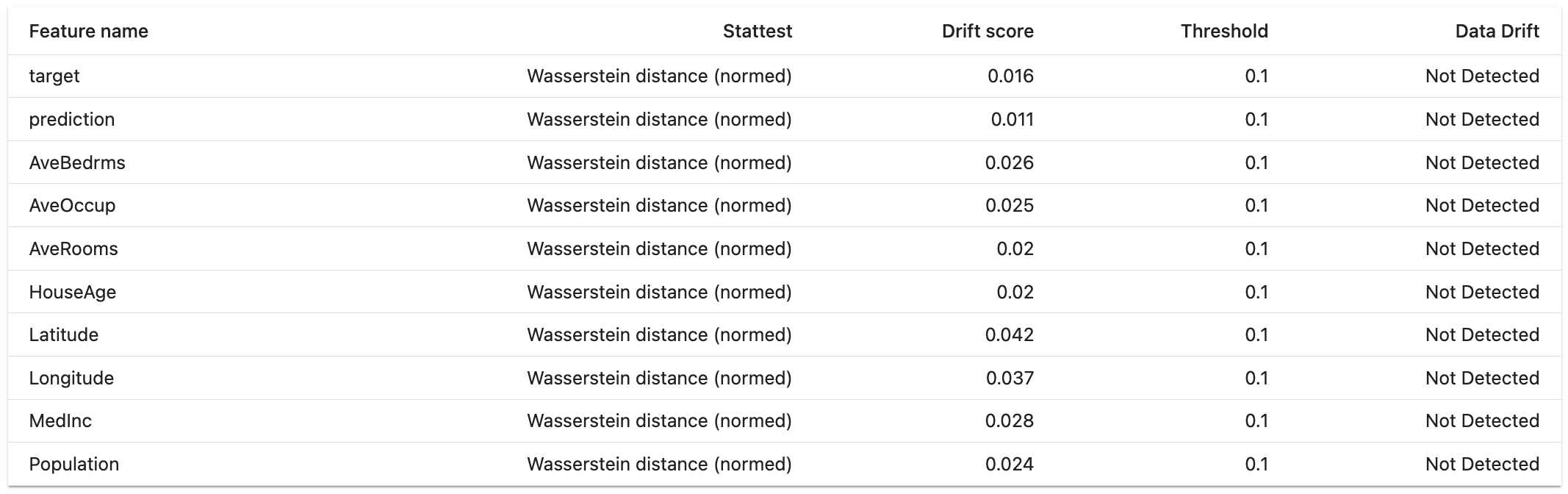
DriftedColumns()에서는 전체 컬럼에 대해 Drift 테스트를 진행합니다. 물론 파라미터를 통해 specific한 column을 선택할 수 있습니다. 여기서는 결과를 html로 저장하였고 html을 확인해보면 그림처럼 Test결과를 한눈에 볼 수 있습니다.
테스트 항목의 DETAILS 버튼을 클릭하면 아래처럼 사용된 알고리즘, Drift score, Threshold 등을 확인할 수 있습니다.
output:
자 이제 Drift가 감지되도록 Dummy Data를 생성하여 current data로 사용해서 다시 실험해보겠습니다.
current['HouseAge'] = current['HouseAge'] + np.random.randint(0, 20, current.shape[0])
tests = TestSuite(tests=[
TestNumberOfDriftedColumns(lt=1),
])
tests.run(reference_data=reference, current_data=current)
tests.save_html("test_drift.html")
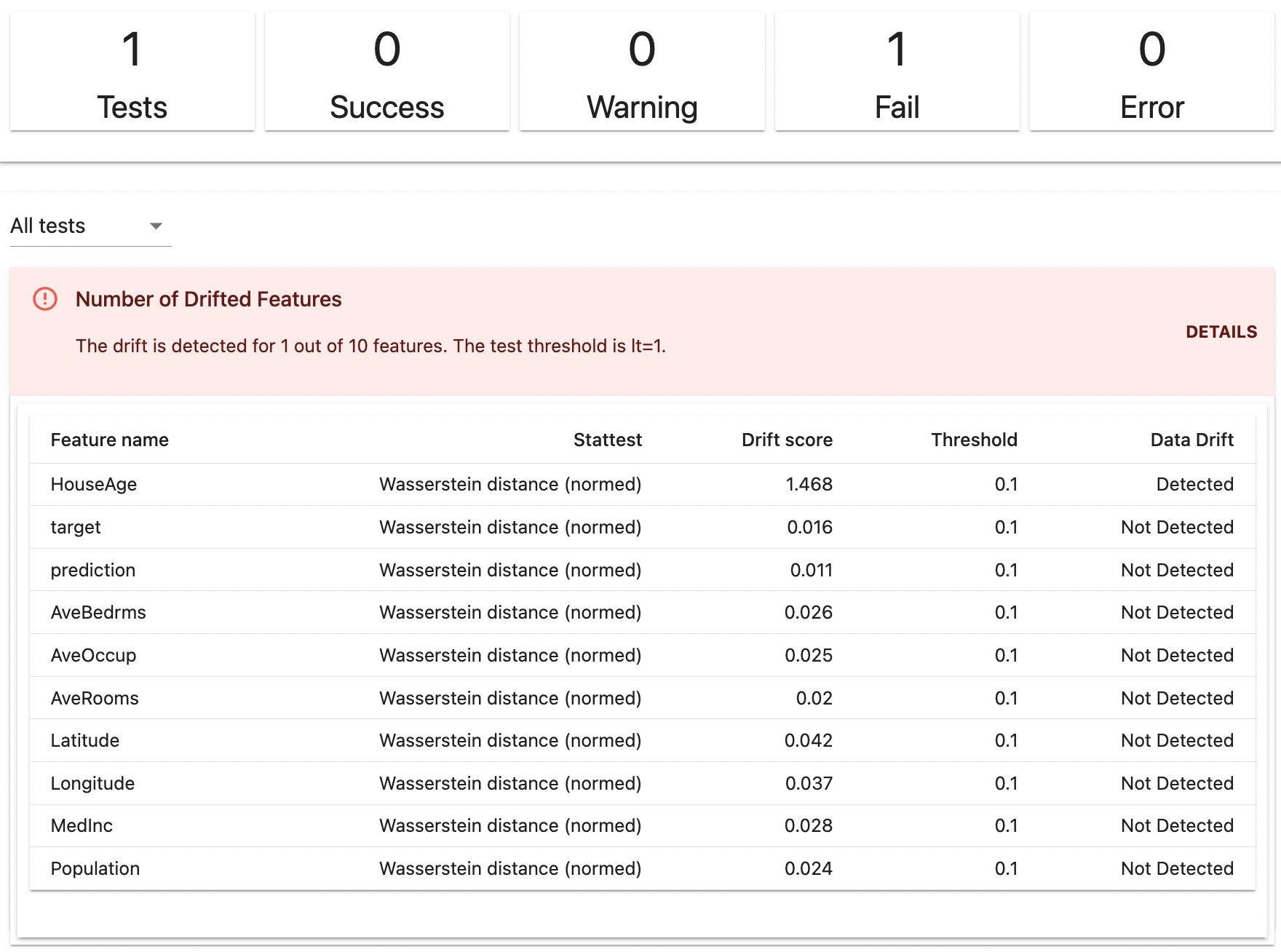
current data의 HouseAge 컬럼에 0에서 20까지의 숫자를 랜덤하게 더한 뒤에 TestSuite를 진행하겠습니다.
여기서 DriftedColumns() 함수에 lt 파라미터는 less than(미만)이라는 의미로 Drift된 컬럼이 해당 값보다 적을경우 테스트에 합격하고 같거나 많을경우 불합격하게 됩니다. 1이라고 적었기 때문에 하나의 컬럼이라도 Drift가 감지되면 불합격하게 됩니다.
아래 결과를 확인해보면 HouseAge컬럼의 Drift score가 1.468이되어 Threshold 기준(0.1)보다 크기때문에 Drift가 감지된것을 볼 수 있습니다.
output:
END
지금까지 머신러닝에서 중요한 문제인 Drift가 무엇인지 알아보고 통계적인 검정으로 Drift를 감지할 수 있는 Evidently 라이브러리를 간단하게 알아보았습니다.
머신러닝 모델은 시간이 지나면서 성능이 떨어질 수 밖에 없습니다. 만약 실시간, 혹은 주기적으로 데이터 유효성 검증을 진행하고 이를 모니터링할 수 있도록 시스템에 구성한다면 모델을 좀 더 효율적으로 운영할 수 있게 됩니다.
Evidently는 이를 고려하여 다른 몇몇 서드파티와도 Integration 할 수 있도록 지원합니다. 대표적으로 MLflow에서 metric을 log할 수 있으며 Grafana에서 metric을 모니터링을 할 수 있습니다. Evidently를 다른 서드파티와 연동하는 방법에 대해서는 추후에 튜토리얼로 작성해 보겠습니다. 감사합니다.
Keep going
Reference
Leave a comment