
Understanding the Feature Store with Feast
이번 포스팅에서는 MLOps의 구성요소(infrastructure) 중 아직은 많이 알려지지 않은 Feature Store에 대해 알아보고 Feature Store Open Source인 Feast의 사용법을 알아보고 Kubeflow에 적용 해보려고 한다. 우선 Feature Store가 무엇인지 알아보자.
Feature Store
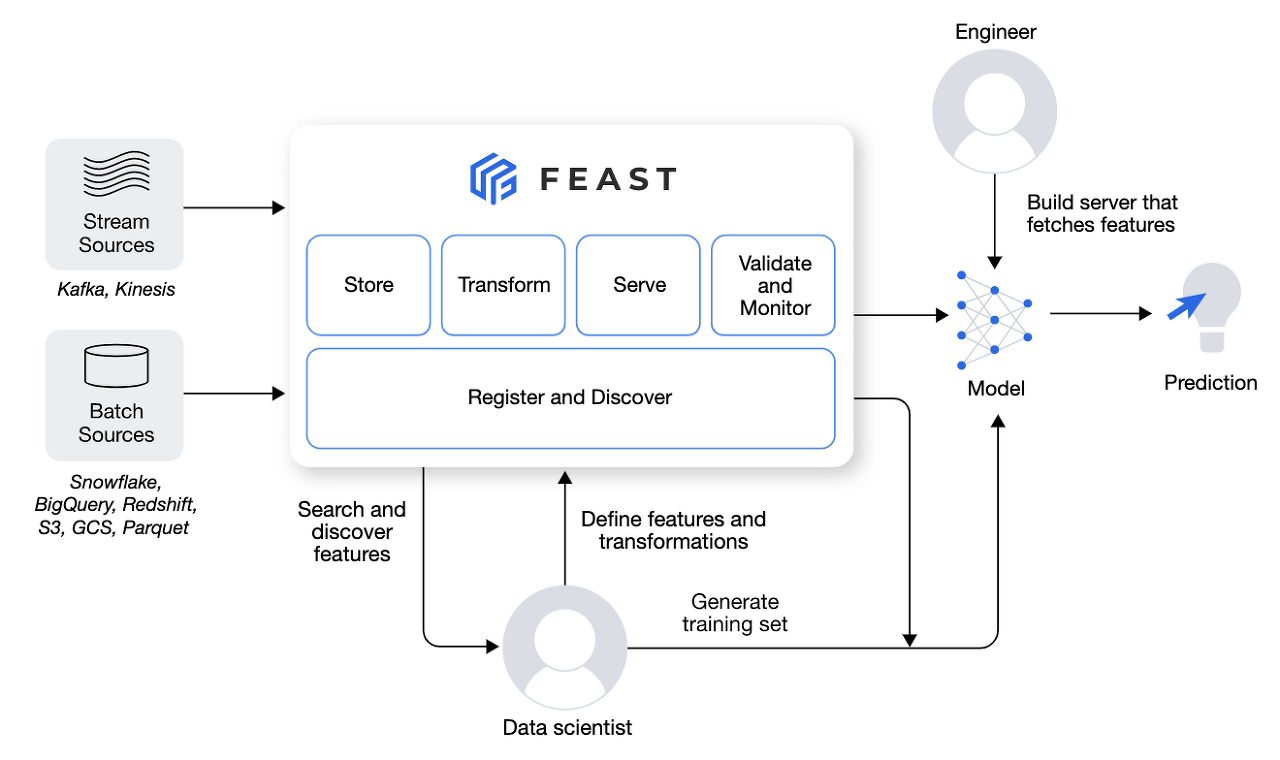
Feature Store란 이름 그대로 머신러닝 프로젝트에서 다루는 Feature(Column)와 value를 저장하는 저장소를 의미한다. 그런데 굳이 Feature Store를 사용하는 이유는 무엇일까?
큰 조직에 여러 데이터 사이언티스트 팀과 머신러닝 엔지니어 팀이 있다고 가정해보자. 각각의 데이터 사이언티스트 팀은 Feature Engineering을 거쳐 데이터를 잘 표현하는 데이터프레임을 생성할 것이다. 이후 ML 엔지니어 팀은 이 데이터로 학습과 inference가 가능하도록 코드를 작성하게 된다. 또한 더 좋은 성능을 내는 Feature를 발견하여 데이터 사이언티스트 팀에게 Feature Engineering을 다시 요구하는 경우도 있다.
이때 중요한 점은 팀이 여러개 존재한다는 것이다. 각각의 데이터 사이언티스트 팀이 원천 데이터로부터 발견하는 insight는 서로 다를수밖에 없고 Feature Engineering 결과는 서로 같을 수가 없다. 그리고 ML 엔지니어 팀에서 데이터 사이언티스트 팀에게 Feature 수정을 요구했을때 이것이 즉각적으로 반영되는 것이 수월하지 않다보니 ML 엔지니어팀에서는 Local에 데이터를 올려 직접 학습에 어울리는 Feature를 탐색하는 작업을 진행하기도 한다.
Feature Store는 이러한 문제를 해결하기 위해 등장하였다. 각각의 데이터 사이언티스트 팀은 Feature Engineering을 거친 데이터를 Feature Store에 올리면 ML 엔지니어 팀에서는 다양한 Feature들 중 최적의 Feature만을 선택해 학습 및 inference 데이터를 가져올 수 있게된다.
정리해서 Feature Store를 사용하는 이유는 아래와 같다.
- compute once, used by many
- 데이터 사이언티스트 팀에서 한번만 Feature Engineering을 통해 Feature를 정의 해 놓으면 여러 ML 엔지니어 팀이 편하게 Feature를 불러와서 여러 모델을 개발하는 일이 좀 더 수월해진다.
- shared expertise
- 추천시스템을 개발하는 조직이 있다고 가정했을때 product, review, user account 등 각 파트를 담당하는 전문 팀들이 각자의 데이터를 분석하여 그 결과를 Feature Store에 올리기 때문에 각 분야의 경험 및 전문지식이 서로 공유가 될 수 있다.
- easier data quality guarantees
- 위와 연장선상에서 각 데이터의 전문가들이 Feature Engineering을 수행하기 때문에 데이터의 품질이 어느정도 보장이 되며 ML 엔지니어 팀에서는 각 데이터 사이언티스트 팀에서 나온 여러 Feature를 잘 활용하기만 하면 된다.
- focus on respective roles
- 데이터 사이언티스트는 데이터 분석 및 Feature Engineering에만 집중하면 되고 ML 엔지니어는 데이터의 도메인 지식이 부족하더라도 모델 학습 및 배포에 집중할 수 있다.
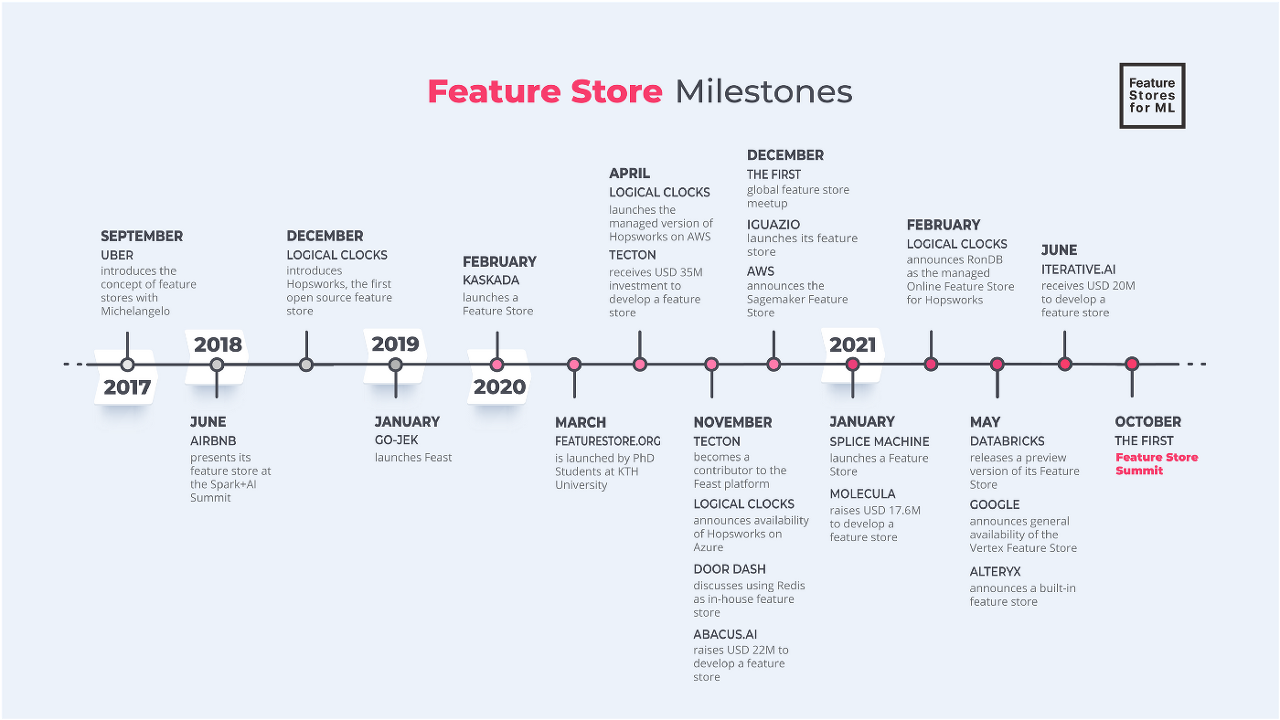
Feature Store를 활용하고 있는 기업들은 계속해서 늘어나고 있는 추세이다. Uber에서 2017년도에 가장 먼저 Feature Store를 도입하였고 이후로도 유명한 기업들에서 Feature Store를 자신들의 서비스의 한 component로 사용하고 있다. Feature Store 특성상 큰 조직일수록 더 큰 필요성을 느끼기 때문에 데이터를 많이 보유하고 있는 큰 기업들이 앞서서 적용을 해나가는 느낌이다.
이제 Feature Store의 종류중 하나인 Feast에 대해 알아보고 직접 다뤄보자
Feast
Feast는 오픈소스이며 사용하기 쉽고 외부 시스템과 통합하기 좋다는 장점이 있다. Feast는 다른 MLOps component들과 마찬가지로 파이썬 라이브러리를 지원하며 현재 포스팅 날짜 기준으로 0.21.3버전까지 나왔다.
Feast를 사용하기 전에 짚고 넘어가야 할 부분은 바로 버전과 관련된 정보이다. Feast는 0.9 버전 이후로 크게 달라졌기 때문에 Feast를 각자의 MLOps 환경에 구축하기 위해서 어떤 버전을 사용해야 할지 고려해볼 필요가 있다.
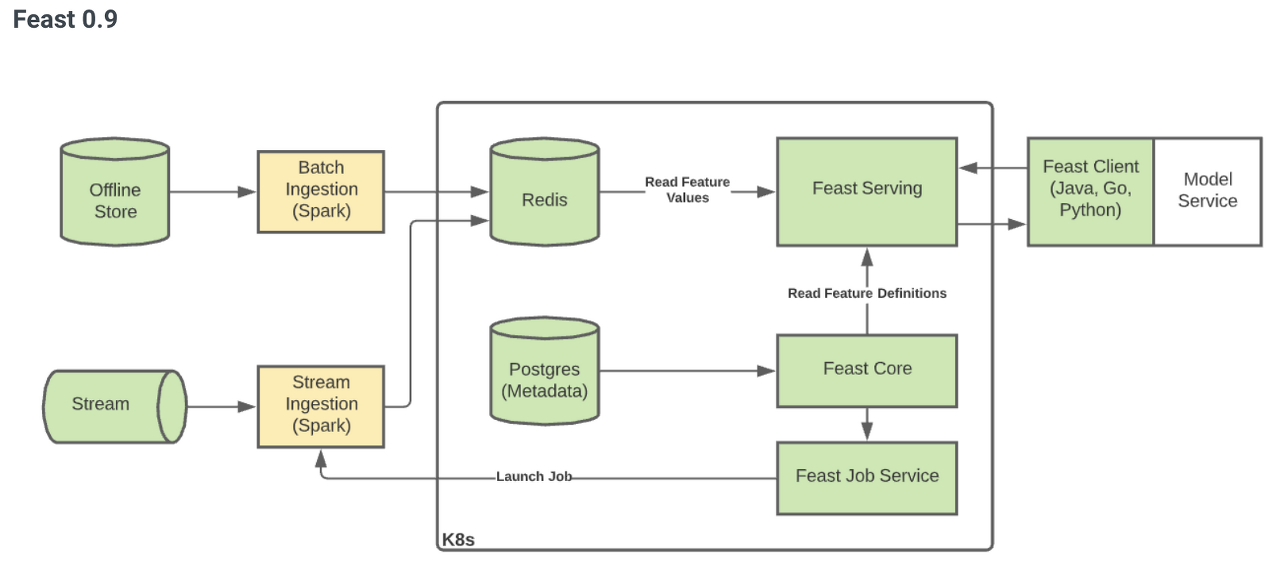
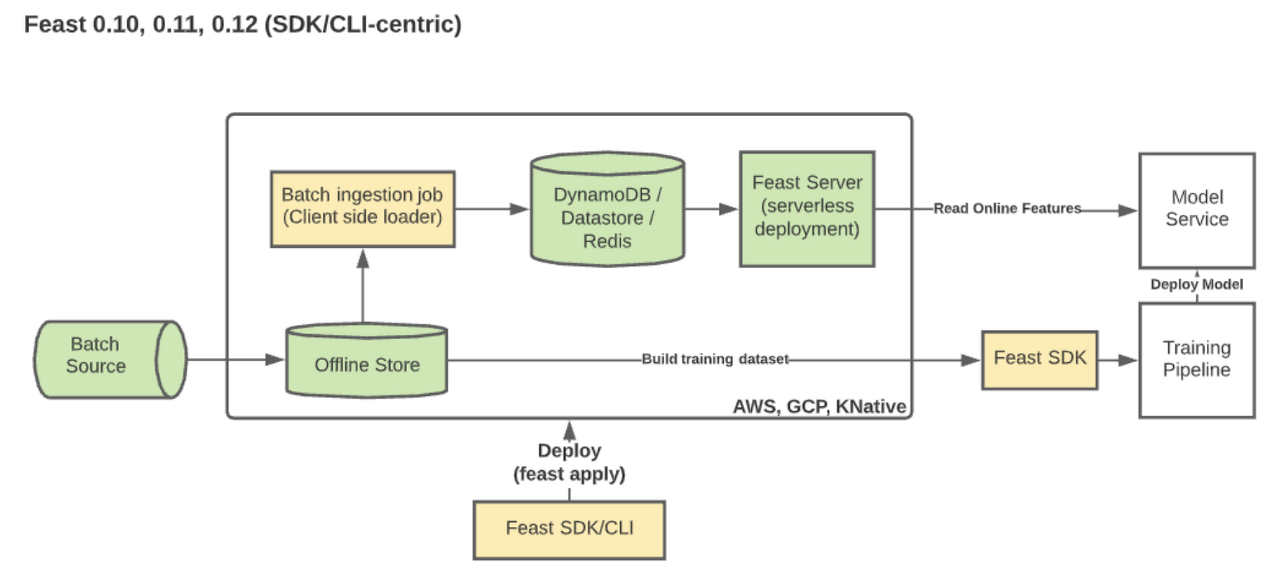
위 그림과 같이 Feast 0.9 버전까지는 쿠버네티스 환경에서 Spark, Redis, Postgres와 같은 component가 같이 구성되어야 작동이 가능했다. 초기에는 일반적으로 많이 사용되는 MLOps 파이프라인에서 별도의 추가작업 없이 Feast를 손쉽계 연계시킨다는 목표로 진행되었지만 쿠버네티스 환경이 반드시 갖춰져야만 활용 가능하고 점점 인기나 활용도가 떨어지는 오픈소스에 대한 의존성이 Feast의 접근성을 막게되어 0.10 버전부터는 대대적인 개편이 이루어진 것으로 예상된다.
| Component | Feast 0.9 | Feast 0.10~ |
|---|---|---|
| 아키텍쳐 | - 서비스 중심 - 쿠버네티스 환경에 배포된 컨테이너와 서비스 | - SDK/CLI 중심 소프트웨어 - Feature Store 사용 가능하도록 인프라 설정 및 배포 가능 |
| 설치 방법 | - Terraform 또는 Helm 이용 | - SDK/CLI 환경에서 pip install - apply 명령을 사용한 GCP, AWS, Local에 배포 |
| 필요한 인프라 | - Kubernetes, Postgress, Spark, Docker, Object Store | - 없음 |
| Batch 계산 | - 가능 (Spark 기반) | - Python을 이용해 데이터 컨트롤 - Data Warehouse 활용 |
| Streaming 지원 | - 가능 (Spark 기반) | - 계획되어 있음 |
| 오프라인 저장소 | - 없음 (Spark를 사용한 활용 제한) | - BigQuery, Redshift, Snowflake, Custom stores |
| 온라인 저장소 | - Redis | - DynamoDB, Firestore, Redis 이외 다수 계획 중 |
| Job Manager | - 있음 | - 없음 |
| Registry | - Postgress 백엔드 기반 gRPC | - SDK 활용 가능한 파일 기반 |
| Local Mode | - 없음 | - 있음 |
위 표와 같이 0.10 버전 이후 pip install 만으로 Feast 설치가 가능하며 쿠버네티스나 Spark가 설치되어야 하는 제한적인 환경이 아닌 Local에서 즉시 활용 가능하다. 물론 0.10 버전 이후에도 쿠버네티스 환경에서 활용 가능하기 때문에 실습에서 가장 최신 버전인 0.21.3을 on-premise 쿠버네티스 환경에서 진행하려고 한다.
Use case
현재 Kubernetes가 on-premise 환경이기 때문에 원천 데이터를 minio에 등록한 뒤에 feature store를 kubeflow jupyter lab에 구축하였다. kubeflow jupyter lab을 생성할 때 dynamic provisioning을 통해 pv와 pvc를 자동생성 시킬 수 있기 때문에 kubeflow pipeline에서 pvc를 volume mount하여 구축된 feature store를 활용할 수 있게 하였다.
Feast 활용 예제는 아래와 같이 진행된다.
- minio bucket 생성 및 데이터 등록
- kubeflow jupyter lab, pvc 생성
- Feature Engineering & Feature store 등록
- offline store를 활용한 모델 학습
- online store를 활용한 모델 테스트
1. minio bucket 생성 및 데이터 등록
kubeflow manifest에 포함되어 있는 minio를 그대로 활용한다. 먼저 minio 서비스를 port-forward 혹은 NodePort를 통해 웹 UI에 접속한다.
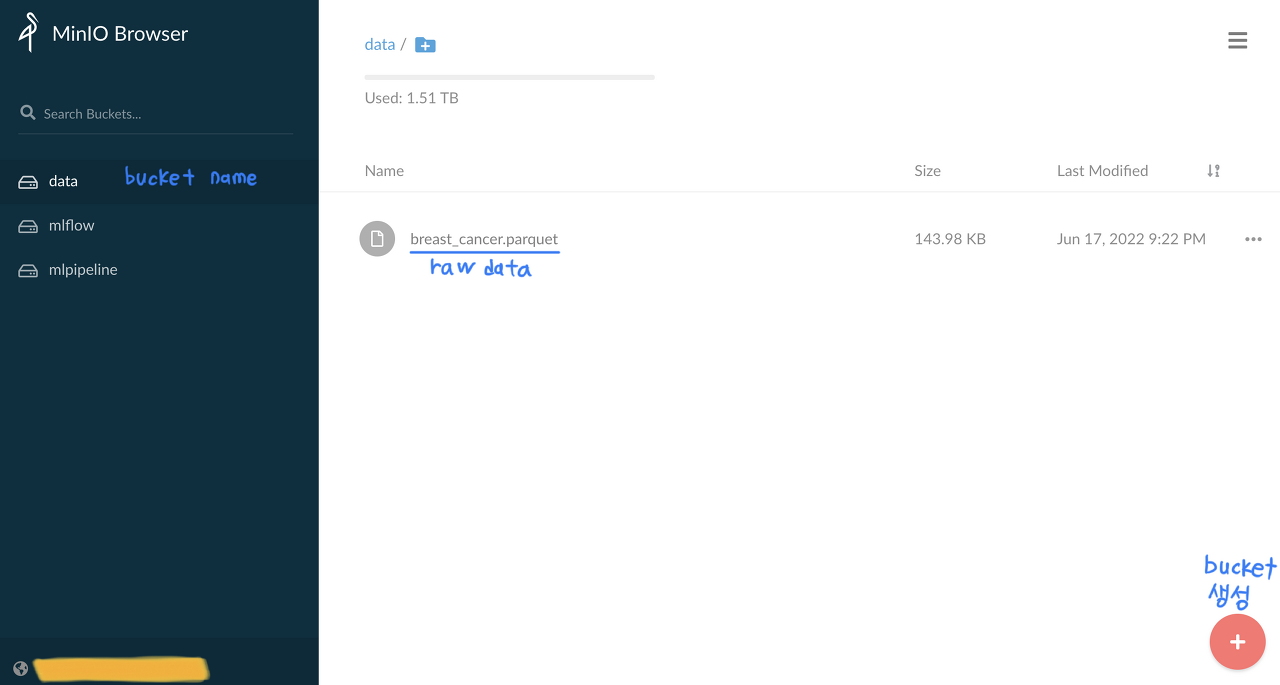
minio browser에 접속하여 우측 하단의 버튼으로 data라는 이름의 bucket을 생성하고 breast_cancer.parquet 데이터를 등록하였다. 해당 데이터셋은 sklearn.datasets.load_breast_cancer()를 통해 쉽게 얻을 수 있는 toy dataset이며 data와 target을 하나의 데이터프레임으로 붙여 parquet 형식의 데이터로 저장하여 업로드 한 것이다.
2. kubeflow jupyter lab, pvc 생성
kubeflow dashboard를 port-forward 혹은 NodePort를 통해 접속한 뒤 Notebook 탭에서 새 노트북을 만들었다.
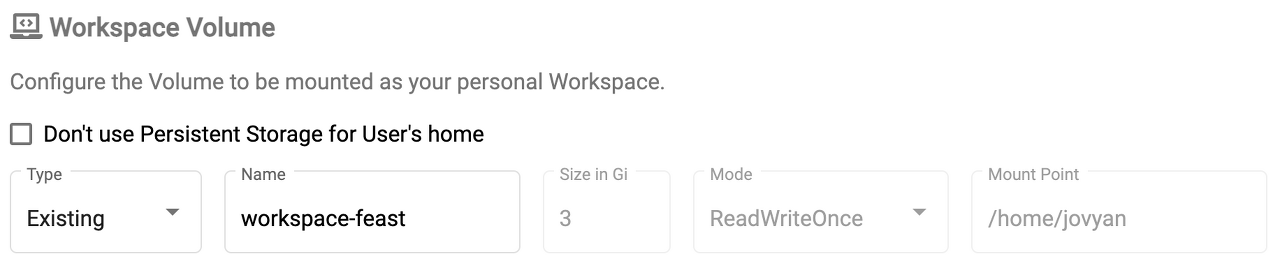
noteebook 생성 과정에서 위에 보이는 사진 부분을 통해 dynamic provisioning을 실행한다. Name은 pvc name이며 workspace-feast-demo라는 pvc를 위와같은 설정으로 생성한다는 의미이다. (미리 feast라는 이름으로 노트북을 생성하여 Type이 Existing으로 보이지만 새로 작성시에는 New라고 되어있음.)

노트북을 create하면 위와같이 feast라는 이름의 jupyter lab이라는 pod가 생기게 되고 pod는 statefulset으로 관리된다. 오른쪽에 CONNECT를 눌러 jupyter lab에 접속하자.
3. Feature Engineering & Feature store 등록
Feast 초기화
ipynb 파일을 하나 생성하고 pip install을 통해 feast를 설치한다. (Feast 버전이 빠르게 바뀌면서 내부 함수나 파라미터 이름이 자주 변경되기 때문에 동일한 결과를 얻기 위해서 같은 버전을 설치하는것을 추천)
%%sh
pip install feast -U -q # -U: 지정된 모든 패키지를 최신으로 업그레이드, -q: 출력 최소화
pip install --upgrade ipykernel
feast version
# Feast SDK Version: "feast 0.21.3"
최초에 feast init 명령어를 통해 feature store directory를 생성하게 되는데 이때 샘플 데이터셋과 feature store 정의되어 있는 파이썬 파일과 yaml 파일도 자동생성해준다. 하지만 다른데이터셋을 사용할 것이기 때문에 -m 옵션으로 yaml 파일만 존재하는 directory를 생성한다.
!feast init -m breast_cancer
%cd breast_cancer
# Creating a new Feast repository in /home/jovyan/breast_cancer.
breast_cancer 폴더에 생성된 feature_store.yaml 파일을 왼쪽 그림에서 오른쪽 그림처럼 수정해주고 data라는 이름의 폴더를 breast_cancer의 하위폴더로 생성한다.

- project: Feature Store project repository
- registry: 모든 Feature들의 정의와 메타데이터 정보를 가진 파일
- provider: Offline Store, Online Store, Infra, Computing등을 활용할 provider 종류(local, aws, gcp)
- online_store: online feature에 대한 정보를 가진 파일
registry.db와 online_store.db는 뒤에서 feast apply 명령어를 통해 Feature Store를 업데이트 시키면 자동으로 yaml 파일 경로에 생성되게 된다.
원천데이터 불러오기
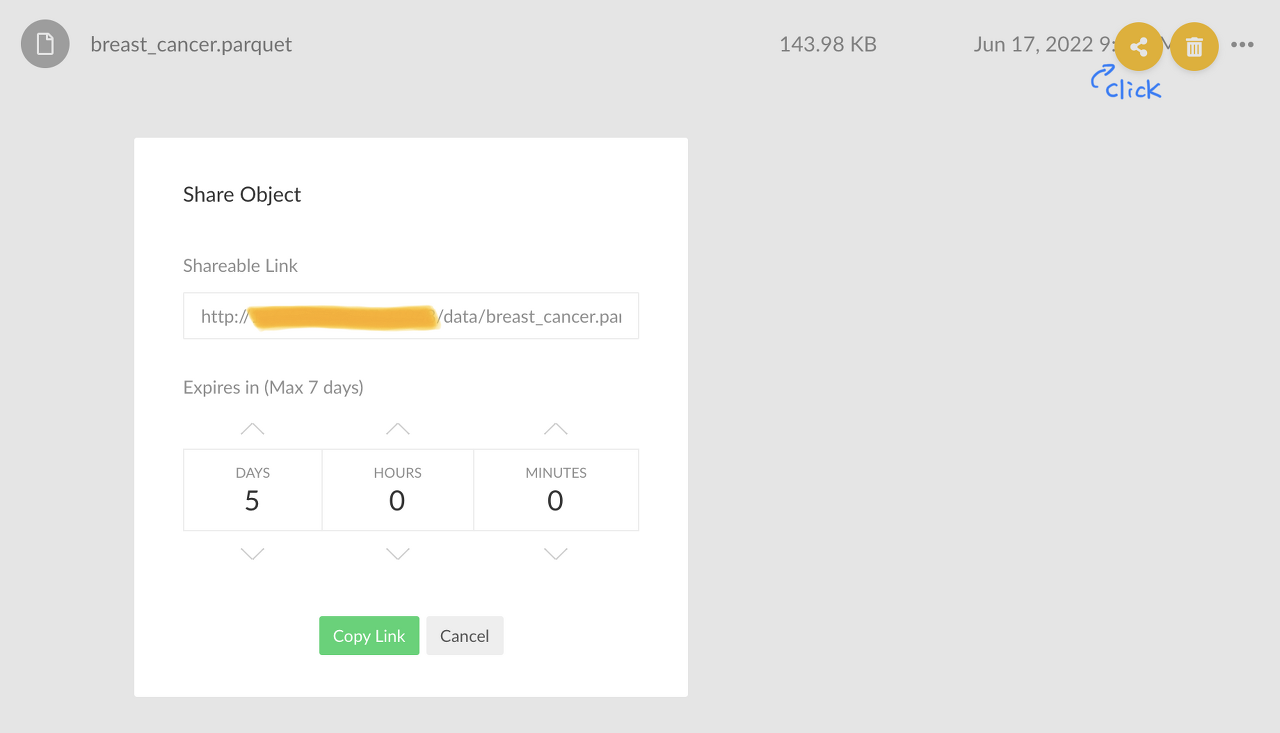
앞서 원천데이터를 minio에 등록하였다. minio에 접속해서 breast_cancer.parquet 데이터의 오른쪽 버튼을 클릭해 shareable link를 가져와 아래 코드의 {MINIO URL}에 적어준다.
from sklearn import datasets
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
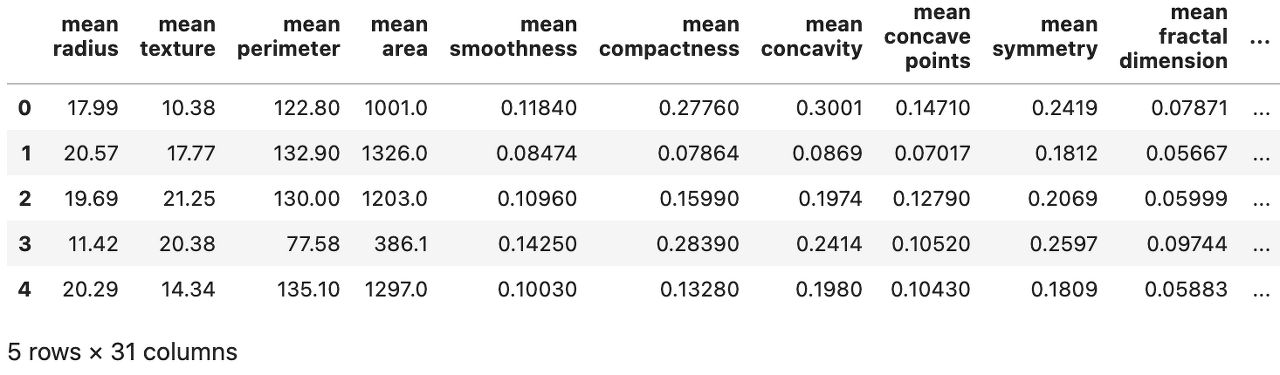
data_df = pd.read_parquet('{MINIO URL}')
data_df.head()
Feature Engineering
이제 Feature Engineering 작업을 진행해야 하지만 Feast의 기능 활용에 좀더 초점을 맞추기 위해 target 컬럼을 제외한 30개의 feature를 그대로 활용하려고 한다. 다만 각 분야의 데이터 사이언티스트 팀이 Feature Engineering을 거쳐 Feature Store에 다양한 feature를 등록한다는 컨셉을 따라가기 위해 breast_cancer 원본 데이터 프레임을 4개의 데이터프레임으로 나누어 진행할 것이다.
data_df1 = data_df[data_df.columns[:5]]
data_df2 = data_df[data_df.columns[5:10]]
data_df3 = data_df[data_df.columns[10:17]]
data_df4 = data_df[data_df.columns[17:30]]
target_df = pd.DataFrame(data=data_df.target, columns=['target'])
데이터를 4개의 데이터프레임으로 만들고 target정보만 담은 데이터프레임도 만들었다. 여기서 끝이 아니고 Feast는 Feature Store에 등록하기 전에 추가해야하는 컬럼이 있다.
Timestamp
Feast는 timestamp를 사용하여 다양한 데이터로부터 feature가 올바른 시간순으로 결합되도록 한다. 기본적으로는 학습 및 예측에 오래된 데이터의 사용을 방지하기 위함이며 뒤에서 이 timestamp로 online store에서 최근에 추가된 데이터 혹은 구간데이터를 추출해 내게 된다. breast cancer 데이터셋에 timestamp가 없기 때문에 하루 간격을 가지는 event_timestamp 컬럼을 추가하였다.
# 가장 마지막 데이터가 현재시간
timestamps = pd.date_range(
end=pd.Timestamp.now(),
periods=len(data_df),
freq='D').to_frame(name="event_timestamp", index=False)
data_df1 = pd.concat([data_df1, timestamps], axis=1)
data_df2 = pd.concat([data_df2, timestamps], axis=1)
data_df3 = pd.concat([data_df3, timestamps], axis=1)
data_df4 = pd.concat([data_df4, timestamps], axis=1)
target_df = pd.concat([target_df, timestamps], axis=1)
data_df1.tail()
Entity
각 데이터들의 Key를 의미하며 예를 들어 계정 정보를 가진 테이블에서는 user id, 상품 정보를 가진 테이블에서는 product name이 entity가 된다. DB에서 쿼리를 통해 여러 테이블을 그룹화할때 사용하는 key와 비슷한 개념이다. breast cancer 데이터셋에는 key로 사용할 컬럼이 없기 때문에 각 행을 한명의 환자로 간주하여 patient_id 라는 컬럼을 생성해 각 행에 key값을 추가하였다.
data_df1['patient_id'] = range(0, data_df1.shape[0])
data_df2['patient_id'] = range(0, data_df2.shape[0])
data_df3['patient_id'] = range(0, data_df3.shape[0])
data_df4['patient_id'] = range(0, data_df4.shape[0])
target_df['patient_id'] = range(0, target_df.shape[0])
data_df1.head()
분할한 데이터프레임을 data폴더에 저장한다.(지금 저장하는 target을 제외한 4개의 데이터가 각팀에서 feature engineering 작업을 완료한 데이터라고 보면 된다.)
data_df1.to_parquet(path="data/data_df1.parquet", use_deprecated_int96_timestamps=True)
data_df2.to_parquet(path="data/data_df2.parquet", use_deprecated_int96_timestamps=True)
data_df3.to_parquet(path="data/data_df3.parquet", use_deprecated_int96_timestamps=True)
data_df4.to_parquet(path="data/data_df4.parquet", use_deprecated_int96_timestamps=True)
target_df.to_parquet(path="data/target_df.parquet", use_deprecated_int96_timestamps=True)
Feature Store Definition
Feast는 데이터별로 최소 하나 이상의 Feature View를 보유하고 있다. 이 Feature View 안에는 Feature(schema), Entity, Data Source가 포함되어야 한다. Feature View를 통해서 오프라인(학습)데이터와 온라인(추론) 환경 모두에서 일관된 방식으로 Feature 데이터를 모델링 할 수 있게 해준다.
Feature Store를 정의하기 위해 breast_cancer 폴더 아래에 definitions.py 파일을 생성한 뒤에 아래와 같이 작성한다.
from feast import Entity, Field, FeatureView, FileSource, ValueType
from datetime import timedelta
from feast.types import Int32, Int64, Float32
patient = Entity(
name="patient_id",
value_type=Int64,
description="The ID of the patient")
f_source1 = FileSource(
path="/home/jovyan/breast_cancer/data/data_df1.parquet",
timestamp_field="event_timestamp"
)
df1_fv = FeatureView(
name="df1_feature_view",
ttl=timedelta(days=3),
entities=["patient_id"],
schema=[
Field(name="mean radius", dtype=Float32),
Field(name="mean texture", dtype=Float32),
Field(name="mean perimeter", dtype=Float32),
Field(name="mean area", dtype=Float32),
Field(name="mean smoothness", dtype=Float32)
],
source=f_source1
)
f_source2 = FileSource(
path="/home/jovyan/breast_cancer/data/data_df2.parquet",
timestamp_field="event_timestamp"
)
df2_fv = FeatureView(
name="df2_feature_view",
ttl=timedelta(days=3),
entities=["patient_id"],
schema=[
Field(name="mean compactness", dtype=Float32),
Field(name="mean concavity", dtype=Float32),
Field(name="mean concave points", dtype=Float32),
Field(name="mean symmetry", dtype=Float32),
Field(name="mean fractal dimension", dtype=Float32)
],
source=f_source2
)
f_source3 = FileSource(
path="/home/jovyan/breast_cancer/data/data_df3.parquet",
timestamp_field="event_timestamp"
)
df3_fv = FeatureView(
name="df3_feature_view",
ttl=timedelta(days=3),
entities=["patient_id"],
schema=[
Field(name="radius error", dtype=Float32),
Field(name="texture error", dtype=Float32),
Field(name="perimeter error", dtype=Float32),
Field(name="area error", dtype=Float32),
Field(name="smoothness error", dtype=Float32),
Field(name="compactness error", dtype=Float32),
Field(name="concavity error", dtype=Float32)
],
source=f_source3
)
f_source4 = FileSource(
path="/home/jovyan/breast_cancer/data/data_df4.parquet",
timestamp_field="event_timestamp"
)
df4_fv = FeatureView(
name="df4_feature_view",
ttl=timedelta(days=3),
entities=["patient_id"],
schema=[
Field(name="concave points error", dtype=Float32),
Field(name="symmetry error", dtype=Float32),
Field(name="fractal dimension error", dtype=Float32),
Field(name="worst radius", dtype=Float32),
Field(name="worst texture", dtype=Float32),
Field(name="worst perimeter", dtype=Float32),
Field(name="worst area", dtype=Float32),
Field(name="worst smoothness", dtype=Float32),
Field(name="worst compactness", dtype=Float32),
Field(name="worst concavity", dtype=Float32),
Field(name="worst concave points", dtype=Float32),
Field(name="worst symmetry", dtype=Float32),
Field(name="worst fractal dimension", dtype=Float32),
],
source=f_source4
)
target_source = FileSource(
path="/home/jovyan/breast_cancer/data/target_df.parquet",
timestamp_field="event_timestamp"
)
target_fv = FeatureView(
name="target_feature_view",
entities=["patient_id"],
ttl=timedelta(days=3),
schema=[
Field(name="target", dtype=Int32)
],
source=target_source
)
- name: Feature View name으로 feast.FeatureStore.get_feature_view 등과 같은 함수에서 활용한다.
- entities: Feature View에서 사용될 key값인 entity, 만약 FeatureView가 특별한 entity와 관계가 없는 feature 들만 포함한다면 entities가 없이 (entities=[]) 구성될 수 있다.
- ttl: 학습데이터를 불러올 때 timestamp컬럼으로부터 ttl에 입력한 기간 전까지의 데이터를 허용한다.
- schema: 등록하고자 하는 모든 Feature(Field)를 등록한다. (feature name 정확히 기재)
- source: feature 데이터의 FileSource를 정의하여 입력한다. FileSource 함수에는 반드시 path와 timestamp_field 파라미터가 입력되어야 한다. Feature Store에 담을 데이터는 project안에 data폴더에 있기 때문에 local path를 적어주고 timestamp_field는 timestamp 컬럼인 event_timestamp를 적어주었다.
Feast Apply
이제 Feature Store를 등록할 준비가 완료되었다. Feast apply 명령어를 통해 앞서 정의한대로 Feature Store를 등록할 수 있다. apply 명령을 사용할때는 현재경로가 project(breast_cancer)안에 있어야 한다.
# 주피터에서 작업을 했기 때문에 자동생성된 .ipynb_checkpoints폴더를 지워주어야 apply 실행 가능.
!rm -rf .ipynb_checkpoints/
!feast apply
!ls -R # 폴더구조 확인
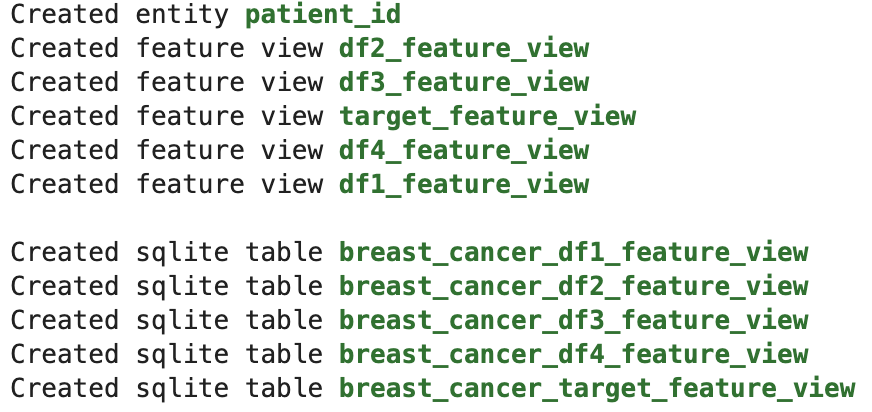

5개의 feature view와 entity가 생성되었고 폴더 구조를 보면 data 폴더안에 registry.db 파일과 online_store.db 파일이 생긴것을 볼 수 있다.
Entity, Feature View 등록 확인
!feast entities list
!feast feature-views list
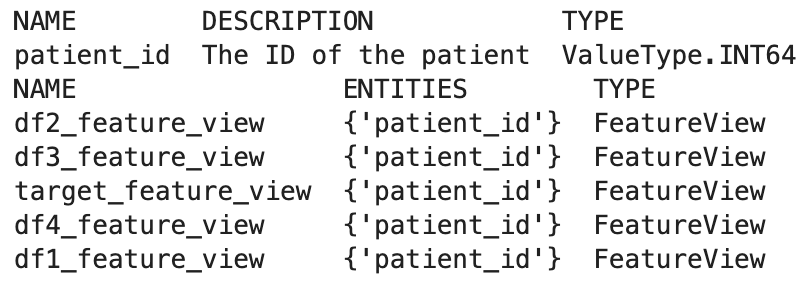
4. offline store를 활용한 모델 학습
이제 Kubeflow pipeline에서 Feature Store에서 학습에 필요한 feature를 가져와서 모델을 학습시켜보자. kubeflow 코드는 파이썬 SDK를 활용하여 작성하였다. Kubeflow에는 kfp라는 파이썬 패키지가 있는데 머신러닝 파이프라인을 쉽고 빠르게 구축할 수 있도록 도와준다. (Kubeflow kfp에 대한 자세한 내용및 코드설명은 추후에 다룰 예정)
feast-pipeline.py(1)
from functools import partial
from kfp.components import InputPath, OutputPath, create_component_from_func
from kfp.dsl import pipeline
import kfp
from kfp import dsl, onprem
@partial(
create_component_from_func,
packages_to_install=["pandas", "sklearn", "dill", "feast"],
)
def train(volume_mount_path: str,
store_name: str,
model_path: OutputPath('dill')):
import os
import pandas as pd
from feast import FeatureStore
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import dill
store = FeatureStore(repo_path=os.path.join(volume_mount_path, store_name))
entity_df = pd.read_parquet(path=os.path.join(volume_mount_path, store_name, 'data/target_df.parquet'))
training_df = store.get_historical_features(
entity_df=entity_df,
features=[
"df1_feature_view:mean radius",
"df1_feature_view:mean texture",
"df1_feature_view:mean perimeter",
"df1_feature_view:mean area",
"df1_feature_view:mean smoothness",
"df2_feature_view:mean compactness",
"df2_feature_view:mean concavity",
"df2_feature_view:mean concave points",
"df2_feature_view:mean symmetry",
"df2_feature_view:mean fractal dimension",
"df3_feature_view:radius error",
"df3_feature_view:texture error",
"df3_feature_view:perimeter error",
"df3_feature_view:area error",
"df3_feature_view:smoothness error",
"df3_feature_view:compactness error",
"df3_feature_view:concavity error",
"df4_feature_view:concave points error",
"df4_feature_view:symmetry error",
"df4_feature_view:fractal dimension error",
"df4_feature_view:worst radius",
"df4_feature_view:worst texture",
"df4_feature_view:worst perimeter",
"df4_feature_view:worst area",
"df4_feature_view:worst smoothness",
"df4_feature_view:worst compactness",
"df4_feature_view:worst concavity",
"df4_feature_view:worst concave points",
"df4_feature_view:worst symmetry",
"df4_feature_view:worst fractal dimension"
]
).to_df()
print(training_df.head())
labels = training_df['target']
features = training_df.drop(
labels=['target', 'event_timestamp', 'patient_id'],
axis=1)
X_train, _, y_train, _ = train_test_split(features, labels, stratify=labels)
reg = LogisticRegression()
reg.fit(X=X_train[sorted(X_train)], y=y_train) # when loading features from feature views, Feast may not preserve the order from the source data.
with open(model_path, mode='wb') as f:
dill.dump(reg, f)
Feast 패키지안에 FeatureStore라는 모듈이 있으며 파라미터로 project 경로(/home/jovyan/breast_cancer)를 적어주면 앞서 feast apply를 통해 등록된 정보들을 담은 Feature Store를 변수로 불러올 수 있다.
학습데이터를 불러오기 위해서 FeatureStore 모듈에 포함된 get_historical_features 함수를 사용하는데 다음 두개의 파라미터가 필요하다.
- entity_df: 학습데이터로 사용할 entity와 timestamp 컬럼이 포함된 데이터 프레임. 데이터가 entity이면서 timestamp가 FileSource의 timestamp_field로 등록한 시간 - ttl 범위 안에 들어오는 데이터만 추출하게 된다. 예를들어 timestamp_filed가 2022-06-10이고 ttl이 3일이라면 timestamp값이 2022-06-07~2022-06-10안에 들어와야 학습데이터로 추출된다. 하지만 코드에 보이는것 처럼 entity_df로 target_df를 사용하고 target_df의 entity와 timestamp는 FeatureStore에 등록할때 정보와 동일하게 했기때문에 모든 데이터를 학습데이터로 추출하였다.
- features: 현재 Feature Store에 등록된 모든 feature중 학습에 사용할 feature를 선택한다. 입력 형식은 [“Feature View Name:Feature Name”] 으로 작성한다.
- 팁 한가지는 FileSource의 timestamp_field에 7시와 8시가 있을때 7시 50분의 timstamp entity_df 데이터는 8시가 아닌 7시의 데이터를 가져온다. 즉 시간은 정시 기준으로 내림 계산한다.
training_df를 주피터에서 head() 출력해보면 아래와 같이 entity_df인 target_df의 기존컬럼 3개와 학습에 사용할 feature로 지정한 30개의 feature가 합쳐지면서 학습 데이터프레임이 생성되는것을 볼 수 있다.
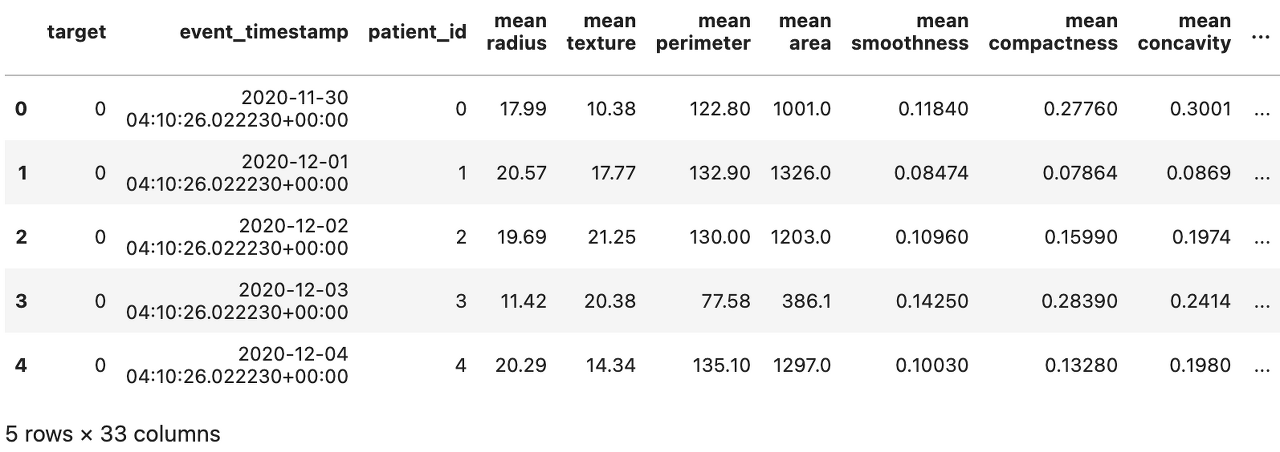
5. online store를 활용한 모델 테스트
여기서 모델 테스트는 테스트 데이터셋을 활용하는 것이 아니라 배포과정에서의 inference 데이터를 활용한다. Feast에서는 Online Store로 데이터를 적재하기 위해 materialize 혹은 materialize-incremental 명령어를 사용한다.
materialize
- 과거의 특정 범위내에 최신 feature값들을 online store로 적재
- python script: feast.FeatureStore.materialize(start_date: datetime(2022,6,1,5,0,0), end_date: datetime.now())
- CLI: feast materialize {datetime(2022,6,1,5,0,0).isoformat()} {datetime.now().isoformat()}
materialize-incremental
- 가장 최근 실행된 materialize-incremental 이후의 모든 새로운 feature 값들을 serialization 시켜주는 역할
- 만약 materialize-incremental를 처음 실행한다면 지정한 날짜로부터 ttl 기간 전까지의 데이터를 적재
- materialize-incremental 이후 생긴 데이터가 없다면 그대로 이전 데이터를 활용
유의할 점
- materialize-incremental 선언 이후 과거 데이터 구간을 보고싶어서 materialize를 실행한뒤 새로운 데이터가 들어오지 않은 상태에서 materialize-incremental을 하게되더라도 online store가 여전히 materialize 데이터구간을 보고있게된다.
- CLI에서 materialize, materialize-incremental명령어 뒤에 날짜를 적을때 iso 형식으로 주어야 한다.
- materialize, materialize-incremental 는 반드시 entity당 최근 한개의 데이터만 가지고 온다.
Online Store로 데이터 적재
from datetime import datetime, timedelta
from feast import FeatureStore
store = FeatureStore(repo_path="/home/jovyan/breast_cancer")
store.materialize_incremental(end_date=datetime.now())
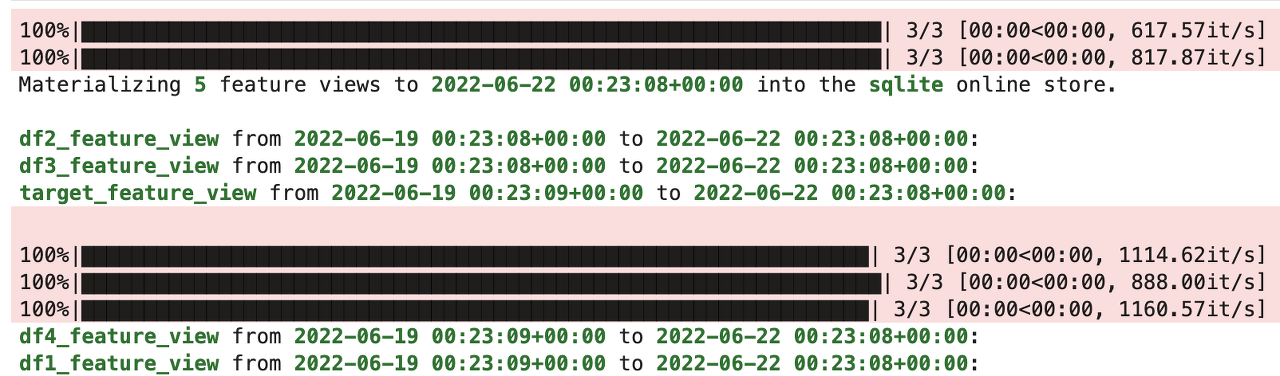
materialize_incremental을 사용하였다. materialize_incremental 파라미터로 feature_view를 지정하여 원하는 Feature View만 적재할 수도 있다. 현재 최초로 materialize_incremental을 실행했기 때문에 최근 3일동안의 데이터만 online store로 데이터를 적재하는것을 볼 수 있다.
materialize_incremental을 실행함으로써 online_store.db에 latest feature value가 저장되었다. 이제 test코드를 작성하여 online store에 적재된 데이터로 추론 결과를 얻어보자.
feast-pipeline.py(2)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "feast"],
)
def test(volume_mount_path: str,
store_name: str,
model_path: InputPath('dill')):
import os
import pandas as pd
from feast import FeatureStore
import dill
store = FeatureStore(repo_path=os.path.join(volume_mount_path, store_name))
feast_features = [
"df1_feature_view:mean radius",
"df1_feature_view:mean texture",
"df1_feature_view:mean perimeter",
"df1_feature_view:mean area",
"df1_feature_view:mean smoothness",
"df2_feature_view:mean compactness",
"df2_feature_view:mean concavity",
"df2_feature_view:mean concave points",
"df2_feature_view:mean symmetry",
"df2_feature_view:mean fractal dimension",
"df3_feature_view:radius error",
"df3_feature_view:texture error",
"df3_feature_view:perimeter error",
"df3_feature_view:area error",
"df3_feature_view:smoothness error",
"df3_feature_view:compactness error",
"df3_feature_view:concavity error",
"df4_feature_view:concave points error",
"df4_feature_view:symmetry error",
"df4_feature_view:fractal dimension error",
"df4_feature_view:worst radius",
"df4_feature_view:worst texture",
"df4_feature_view:worst perimeter",
"df4_feature_view:worst area",
"df4_feature_view:worst smoothness",
"df4_feature_view:worst compactness",
"df4_feature_view:worst concavity",
"df4_feature_view:worst concave points",
"df4_feature_view:worst symmetry",
"df4_feature_view:worst fractal dimension"
]
# Getting the latest features
features = store.get_online_features(
features=feast_features,
entity_rows=[{"patient_id": 568}, {"patient_id": 567}, {"patient_id": 566}]
).to_dict()
test_df = pd.DataFrame.from_dict(data=features)
print(test_df)
with open(model_path, mode="rb") as file_reader:
reg = dill.load(file_reader)
predictions = reg.predict(
test_df[sorted(test_df.drop('patient_id', axis=1))] # sort test features like train features
)
print("result: ", predictions)
online store에 적재된 데이터를 불러오기 위해서 feast.FeatureStore.get_online_features()를 사용한다. get_online_features 함수는 다음 2개의 파라미터를 입력해주어야 한다.
- features: online store에 적재된 데이터의 어떤 feature를 가져올 것인지 지정한다. get_historycal_features와 마찬가지로 [“Feature View Name: Feature Name”] 형식으로 작성한다. 당연하지만 학습에 사용된 Feature와 동일한 Feature를 적어야 한다.
- entity_rows: online store에 적재된 데이터중 추출하고자 하는 feature의 entity 정보를 입력한다. [{“Entity Column Name”: Value}] 와같은 형식으로 입력한다.
test_df를 주피터에서 확인해보면 아래와 같이 3개의 데이터가 추출되는 것을 볼 수 있다. 데이터가 하루에 1개 등록되도록 위에서 미리 설정하였고 가장 아래의 데이터가 현재시간이기 때문에 가장 아래 3개의 entity값 566, 567, 568을 적었으니 3개의 데이터 모두 나오는 것이 정상이다. online store에 존재하지 않는 데이터의 entity값을 입력하면 null값으로 데이터프레임에 추가된다.
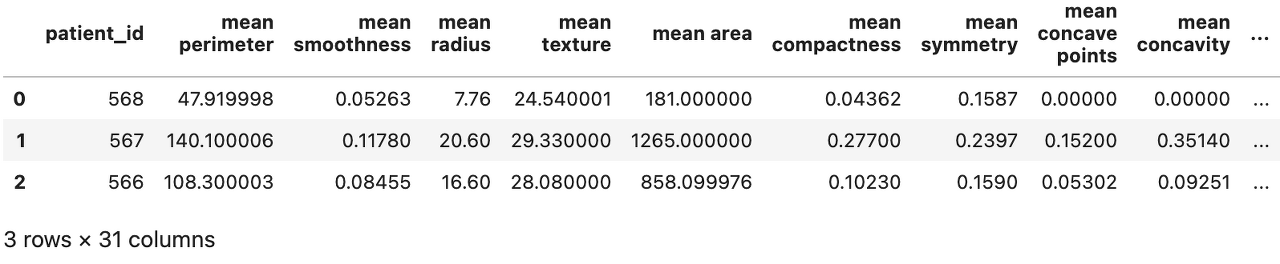
예측결과를 확인하기 위해 kfp 코드를 마저 작성하고 kubeflow dashboard에서 확인해보자.
feast-pipeline.py(3)
@pipeline(name='feast example')
def feast_pipeline(store_name: str):
pvc_name = "workspace-feast"
volume_name = 'pipeline'
volume_mount_path = '/home/jovyan'
_train_op = train(volume_mount_path, store_name).apply(onprem.mount_pvc(pvc_name, volume_name=volume_name, volume_mount_path=volume_mount_path))
test(volume_mount_path, store_name, _train_op.outputs['model']).after(_train_op).apply(onprem.mount_pvc(pvc_name, volume_name=volume_name, volume_mount_path=volume_mount_path))
if __name__ == '__main__':
kfp.compiler.Compiler().compile(feast_pipeline, './feast-pipeline.yaml')
pipeline 코드작성 완료 후 파일을 실행하면 yaml 파일이 생성되고 이 yaml 파일을 kubeflow dashbaord pipelines에 등록하여 run을 수행한다.
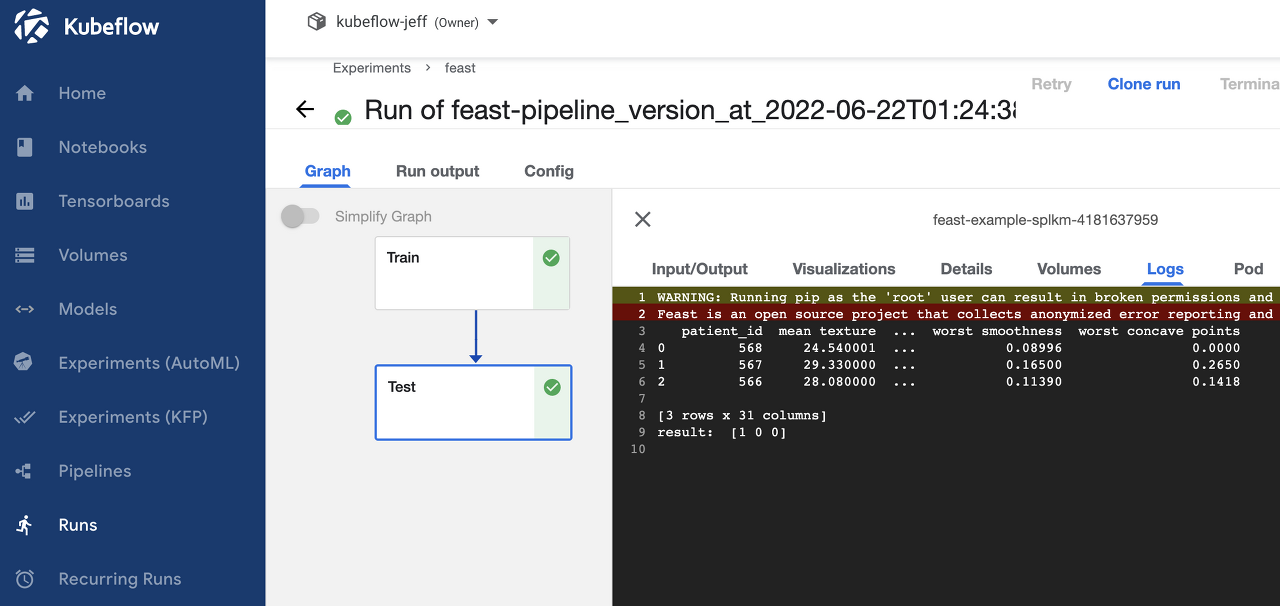
DAG의 Test log를 살펴보면 3개의 데이터가 online store로 부터 추출되어 정상적으로 예측한 것을 볼 수 있다. 현재 데이터를 local에서 불러오기 때문에 offline과 online infernce 속도차이가 크게나지 않지만 source data의 저장소가 GCP bucket이나 AWS cloud storage라면 꽤 유의미한 속도 차이가 있다.
End
지금까지 Feature Store의 개념과 Open Source인 Feast에 대해 알아보았다. Feature Store는 다양한 데이터에 대한 Feature를 한곳에서 관리하고 학습 및 배포시의 low load latency 등 여러 장점이 있기 때문에 꼭 큰 조직이 아니더라도 테이블이 분리되어 있으며 time series를 다룬다거나 inference speed 향상을 원한다면 충분히 MLOps의 component로 고려해볼 가치가 있다고 생각한다.
keep going
Leave a comment