
Kubeflow pipeline에서 DVC로 데이터 버전관리하기
최근 사내에서 MLOps의 수많은 컴포넌트중 한 부분인 데이터 버전관리를 Kubeflow 파이프라인에서 수행하도록 구성 할 일이 있었다. 그 과정 속에서 겪었던 문제와 해결방법을 이번 포스팅에 담아보려고 한다.
데이터 버전관리 툴은 DVC(Data Version Control)로 선택하였다. DVC를 선택한 이유는 과금이 발생하지 않는 오픈소스이기도 하고 git과 밀접한 관계를 가지기 때문에 코드 버전 관리와 더불어 데이터 버전관리를 간편하게 할 수 있어 결정하였다.
DVC 기본 활용방법은 공식문서에 자세히 나와있고 지난 포스팅에서도 한번 다뤘기 때문에 DVC 기본 문법에 대해서는 생략한다.
1. Intro
현재 상황에 대해 간략히 설명하면 다음과 같다.
- 머신러닝 프로젝트가 여러개 존재하며 정형데이터가 사용된다.
- Raw data가 MySQL DB에 실시간으로 저장되며 일정 기간을 쿼리로 가져와 학습데이터로 구축하거나 Inference를 수행한다.
단순하게 일정시간 간격으로 Raw 데이터를 가져와서 DVC로 버전관리를 할 수도 있지만 쿼리로 가져온 데이터를 어차피 csv로 만들어야 하기도 하고 하이퍼파라미터 튜닝과 학습 컴포넌트에서 csv를 읽어서 전처리를 반복적으로 수행하는 것을 피하기 위해 Raw 데이터를 전처리해서 csv로 저장하고 이것을 DVC로 관리할수 있는 preprocess 컴포넌트를 생성하였다. 전처리 완료된 데이터는 서버에 저장된다.
Kubeflow pipeline에서 DVC를 활용한다는 의미는 컨테이너 안에서 DVC를 활용한다는 말이기 때문에 컨테이너 입장에서 원격저장소인 서버에 데이터를 Push, Pull 하기 위해서는 컨테이너에서 서버의 url, user, port, password 정보를 알고 있어야 한다. DVC에서는 이런 ssh 관련 정보를 .dvc/config 경로에서 관리한다.
DVC repository를 구성하는 방법에는 4가지 선택지가 있었다.
1. 프로젝트별로 repository를 구분하고 같은 이름의 tag로 공통관리한다.
- 장점: 프로젝트가 분리되어있으며 태그명을 버전명으로 깔끔하게 관리 할 수 있음
- 단점: github repository 수가 프로젝트 개수만큼 증가하여 repository 관리가 어렵고 서버 정보가 변경된다면 각 repository에 있는 config 파일을 수정해야 함프로젝트별로 repository를 구분하고 tag로 버전관리한다.
2. 하나의 repository에서 tag에 프로젝트명을 붙여 관리한다.
- 장점: 서버 정보가 변경되어도 하나의 config 파일만 수정하면 되므로 변경이 수월함
- 단점: tag명에 버전과 프로젝트명이 포함되기 때문에 가독성이 나쁘고 tag 개수가 많아져 관리하기 불편함
3. 하나의 repository에 같은 이름의 tag로 공통 관리한다.
- 장점: 서버 정보가 변경되어도 하나의 config 파일만 수정하면 되므로 변경이 수월하며 태그명을 버전명으로만 깔끔하게 관리할 수 있음
- 단점: 데이터에 대한 메타정보가 담기는 dvc 파일이 프로젝트간의 구분없이 하나의 repository에 담기기 때문에 가독성이 나쁨
4. 하나의 repository에 하위폴더로 프로젝트를 구분하고 같은 이름의 tag로 공통관리한다.
- 장점: 하나의 Github repository 안에 프로젝트가 분리되어 있으며 태그명을 버전명으로 깔끔하게 관리할 수 있음
- 단점: 서버 정보가 변경된다면 각 프로젝트 폴더에 있는 config 파일을 수정해야 함
각 방법 모두 장단점이 있는데 4번을 택했다. 서버 정보가 변경되면 프로젝트별로 config 파일을 수정해야 한다는 단점이 있지만 프로젝트안에서도 다양한 종류의 데이터가 발생할 수도 있기 때문에 나중을 고려했다.
2. prerequisite
먼저 해야할 작업은 master branch에서 각 프로젝트 폴더에 dvc를 초기화해주고 서버 정보를 입력하는 것이다. 즉 master branch는 기본적으로 DVC가 작동할 수있는 정보를 가지고 있게 된다. 이제 repository를 생성하고 DVC 를 활용하기 위해 필요한 정보를 등록해보자.
dvc라는 repository를 만들고 두개의 프로젝트 폴더를 생성하였다.
tree dvc
# dvc
# ├── project1
# └── project2
dvc를 초기화 하기 위해서는 먼저 git이 초기화 되어야 한다.
git init
각 프로젝트로 이동하여 dvc를 초기화해준다. 이때 root 경로가 아닌 각 프로젝트별로 dvc를 초기화 하므로 –subdir 옵션을 활용한다.
# project1 기준
cd project1
dvc init --subdir
tree -a
# .
# ├── .dvc
# │ ├── .gitignore
# │ ├── config
# │ └── tmp
# │ ├── hashes
# │ │ └── local
# │ │ └── cache.db
# │ └── links
# │ └── cache.db
# └── .dvcignore
dvc를 초기화하면 .dvc 폴더가 생성되고 그안에 빈 config 파일이 생성되는데 여기에 서버의 정보를 등록해주어야 한다. 서버의 정보는 remote 명령어를 활용해 등록한다.
dvc remote add -d <remote name> ssh://<서버 IP>/<경로>
dvc remote modify <remote name> user <user name>
dvc remote modify <remote name> port <port number>
dvc remote modify <remote name> password <password>
cat .dvc/config
# [core]
# remote = <remote name>
# ['remote "<remote name>"']
# url = ssh://<서버 IP>/<경로>
# user = <user name>
# port = <port number>
# password = <password>
각 프로젝트별로 해당 작업을 진행했다면 github에 master branch를 push한다. 단 서버의 정보를 가지고 있기 때문에 private repository로 관리한다. private repository에 접근하는 방법중 하나로 ssh key를 활용하는 방법이 있는데 이 방법에 대해서는 잠시 후에 다루고 로컬에서 private repository에 접근 가능하다고 가정하고 계속 진행한다.
# 루트폴더(dvc)로 이동
git remote add origin <ssh github url>
git add .
git commit -m "<commit 메시지>"
git push origin master
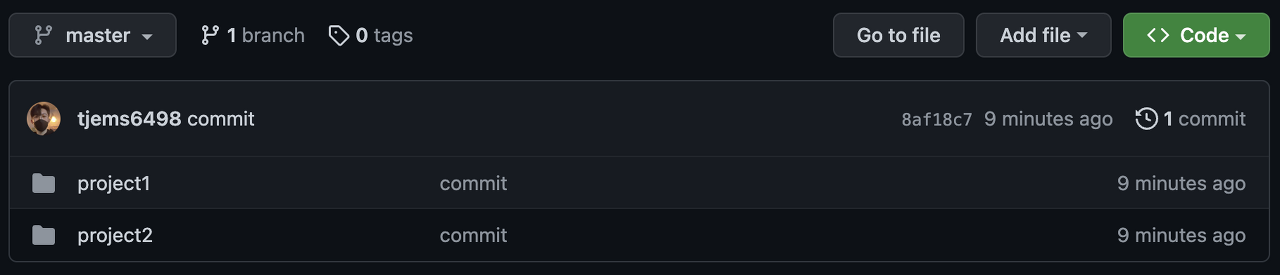
지금까지 미리 준비해야 하는 작업을 마쳤다. 다음으로 특정 프로젝트의 preprocess 컴포넌트의 코드를 살펴보자.
3. Code
preprocess 컴포넌트에서 dvc를 조작하기 위해서는 쉘 스크립트를 작성해야 한다. 그리고 이 쉘 스크립트를 파이썬 스크립트에서 실행하기 위해서 아래 라이브러리를 사용했다.
import subprocess
import shlex
subprocess.run(["chmod", "+x", "save_data.sh"])
subprocess.call(shlex.split(f"./save_data.sh {opt.tag} "), stderr=0)
- 해당 코드는 쿼리를 통해 DB에서 Raw데이터를 추출해 전처리를 수행하고 가장 마지막에 실행하도록 구성하였다.
- 쉘스크립트 파일에 실행 권한을 주고 쉘 스크립트를 실행한다.
- stderr=0 은 에러로그를 출력하지 않는다는 의미인데 해당 파라미터의 인자값을 0으로 설정한 이유는 쉘 스크립트에서 에러를 활용한 예외처리를 수행하기 때문에 에러를 출력할 필요는 없기 때문이다.
save_data.sh
#!/bin/bash
TAG=$1
PROJECT_DIR="preprocess"
git clone <ssh github url>
cd <github repository>/<project name>
git checkout $TAG
if [ $? -eq 0 ];then
echo overwrite tag
git tag -d $TAG
git push origin :$TAG
else
echo create new tag
fi
# 조건문 종료
- 쉘 스크립트에서는 prerequisite에서 생성한 github repo를 clone하여 dvc 정보를 이용해 데이터를 버전 관리하게된다. 쉘 스크립트에서 $?은 가장 최근에 실행한 명령어의 결과가 정상이면 0을 에러가 났다면 1의 값을 가지고 있다. 즉 git checkout 을 통해 먼저 해당 태그가 있다면 local과 원격 tag를 지우도록 한다. 그런데 해당 로직이 왜 필요할까?
- 어떤 프로젝트에서 v1.0 tag가 이미 등록되어 있다고 가정해보자. 이때 새로운 프로젝트가 추가되었고 v1.0 데이터셋을 등록해야 한다. 그런데 v1.0 tag는 이미 존재하기 때문에 tag를 먼저 삭제해야 한다. 왜냐하면 중복된 tag를 생성하는것을 git에서 허용하지 않기 때문이다. tag는 특정 commit의 기록이기 때문에 수정도 불가능하다.
- 그래서 기존의 tag의 정보를 checkout으로 먼저 불러들이고 tag를 삭제하도록 조치하였다. 동일 tag의 다른 프로젝트 dvc 파일까지 가져온다는 단점이 있지만 파일 크기가 워낙 작기 때문에 보안문제가 해결된다면 괜찮을 것이라고 판단했다
mv /$PROJECT_DIR/<data> ./<data>
dvc add <data>
# git push를 위해 유저정보입력
git config --global user.email <github email>
git config --global user.name <github name>
git add .
git commit -m "Dataset $TAG Updated in remote storage"
git tag $TAG
dvc push
git push origin $TAG
- mv 명령어로 .dvc 폴더가 있는 곳으로 전처리 완료된 데이터를 가져오고 dvc add 명령어를 실행하면 .dvc 파일이 생성된다. .dvc 파일은 데이터의 해시값, 크기, 경로를 담은 metadata이다.
- 이후 git add, commit을 진행하고 tag를 생성한 뒤에 dvc push로 데이터를 서버로 전송하고 git push 로 .dvc파일을 github(원격저장소)에 업데이트 한다.
4. Image Build
github repository에는 서버 정보가 담겨있어서 보안때문에 private으로 생성하였는데 어떻게 컨테이너에서 clone과 push를 사용할 수 있을까?
바로 컨테이너에 ssh key(개인키)를 포함시키고 해당 키의 public키를 github 계정에 등록했기 때문에 가능하다. ssh 공개키는 ssh-keygen 명령어로 생성할 수 있고 github에 등록하는 방법은 관련 블로그가 많기 때문에 여기서는 생략한다. 아래 파일은 preprocess 컨테이너의 Dockerfile이다.
Dockerfile
FROM python:3.8.10-slim
RUN apt-get update && apt-get install -y git
RUN mkdir /root/.ssh/
COPY <ssh-key path> /root/.ssh/id_rsa
RUN chmod 600 /root/.ssh/id_rsa
RUN touch /root/.ssh/known_hosts
RUN ssh-keyscan github.com >> /root/.ssh/known_hosts
ENV PROJECT_DIR preprocess
WORKDIR /${PROJECT_DIR}
COPY ./preprocess/requirements.txt /${PROJECT_DIR}/
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install 'dvc[ssh]'
COPY ./preprocess/save_data.sh /${PROJECT_DIR}/
COPY ./preprocess/preprocess.py /${PROJECT_DIR}/
- ssh-key와 관련된 부분만 설명하자면 먼저 로컬에 준비한 ssh-key를 컨테이너에 COPY시킨뒤에 chmod 600 으로 read write 가능하도록 만들어 주고 knwon_hosts 파일을 준비한다. 컨테이너가 github에 연결하기 위해서는 컨테이너 빌드 환경에서 known_hosts 파일에 공개 SSH 키를 추가해야 한다.
- dvc의 ssh 기능을 활용하기 위해 pip install ‘dvc[ssh]‘를 추가로 설치한다.
이제 해당 이미지를 기반으로 컨테이너를 실행하여 실제로 원격저장소와 서버에 코드와 데이터가 업데이트 되는지 확인해보자.
5. Result
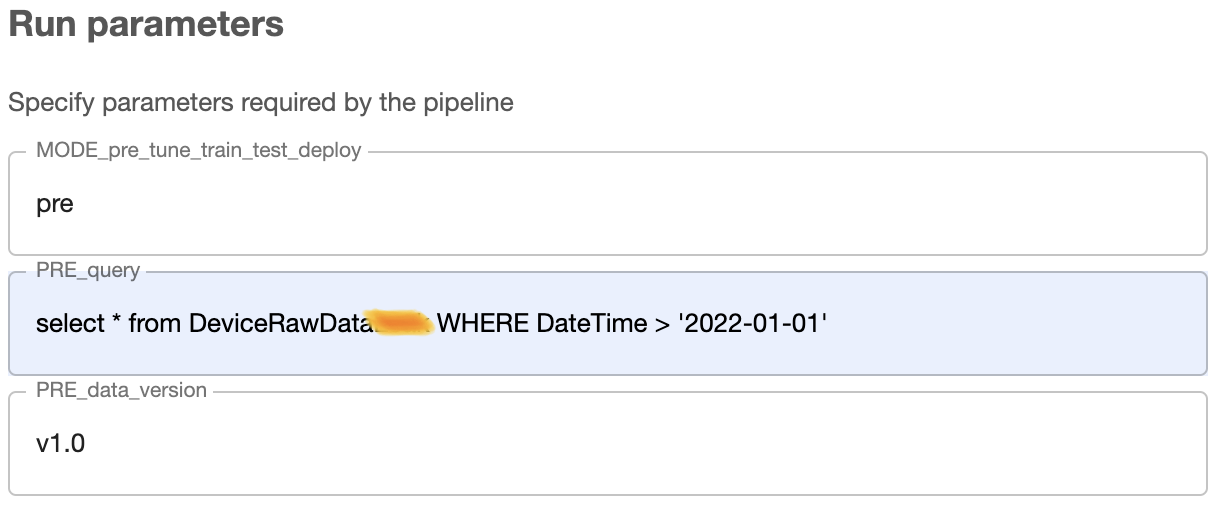
preprocess 컴포넌트를 실행할때 데이터의 범위는 2022-01-01 이후의 데이터를 가져왔고 v1.0 tag로 관리하겠다고 설정하였다. 파이프라인 실행이 종료 된 이후 github repository를 가보면 dvc파일이 생성된 모습을 볼 수 있다.
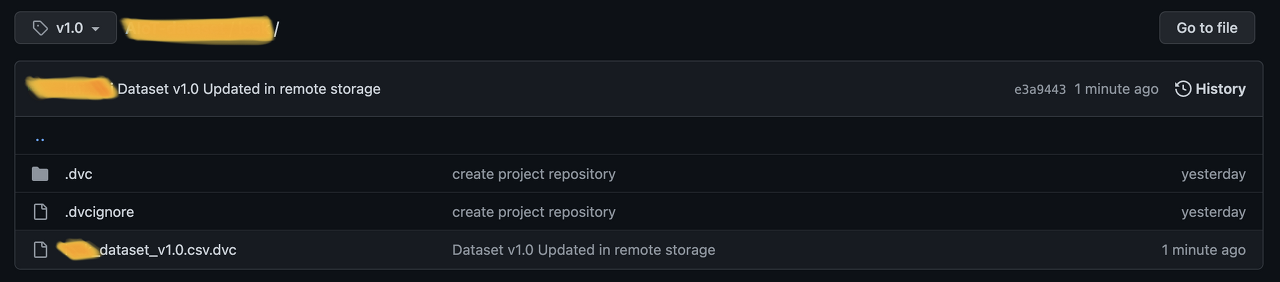

파일을 확인해보면 54로 시작하는 hash name과 size, 실제 파일이름이 담겨있다. 이제 서버로 이동하여 prerequisite에서 설정한 서버 경로에 데이터가 저장되었는지 확인해보자.
# 서버경로 이동
tree
.
└── 54
└── b9b29a9000374332c6b9e2f4b4c459
54라는 폴더가 하나 생겼고 그안에 b9~라는 파일이 생성되었다. dvc 파일의 md5에서 앞의 두자리가 폴더명, 나머지가 파일명이 된다. 이제 서버에 저장된 데이터를 dvc 파일을 통해 하이퍼파라미터 튜닝과 train에서 dvc pull로 가져올 수 있게 되었다. dvc pull로 가져온 데이터는 dvc 파일과 같은 경로에 생성되고 파일명은 dvc파일의 path에 적인 이름으로 적용된다.
train 컴포넌트에서도 마찬가지로 dvc 명령어로 원하는 버전의 데이터를 불러와야 하기 때문에 dvc명령어를 담은 쉘 스크립트파일을 실행해야 한다. 데이터를 불러올때는 아래와 같이 활용할 수 있다.
load_data.sh
#!/bin/bash
TAG=$1
PROJECT_DIR="train"
git clone <ssh github url>
cd <github repository>/<project name>
git checkout $TAG -- .
dvc pull
mv ./<data> /$PROJECT_DIR/<data>
- github repository를 clone하고 프로젝트 폴더로 이동한다. 이후 원하는 버전으로 checkout을 하는데 git checkout에는 – 옵션으로 해당 tag의 파일을 현재 branch 즉 master branch로 가져오도록 할 수 있다. 움직이는게 아니라 가져오는 것이기 때문에 원하는 프로젝트를 지정해서 가져올 수 있다. 현재 이미 프로젝트 폴더로 이동했기 때문에 현재경로를 의미하는 . 을 작성하였다.
- 이후 dvc pull을 통해 데이터셋을 현재경로로 가져오고 train.py 코드에서 사용할 수 있도록 컨테이너의 workdir로 데이터를 이동시킨다.
End
이번 포스팅에서는 DVC를 Kubeflow pipeline의 한 컴포넌트로 적용하여 데이터 버전 관리 하는 방법을 공유해 보았다. 항상 ‘이런식으로 구축하면 되겠지?’ 라는 생각으로 작업을 시작하면 중간에 빈틈이 하나 둘 보이기 시작한다. 떠오른 아이디어를 바로 행동으로 옮기기 전에 설계에 문제가 없는지 리뷰하는 시간이 필요하다고 느낀다.
그래도 다양한 시도를 해보고 자동화시키는 방법에 대해 고민하다 보면 이전보다 나아진 결과물들이 보이는 것 같다.
Keep going
Leave a comment