
YOLOv8 with TensorRT & Nvidia Triton Server
Intro
YOLOv5를 개발했던 ultralytics에서 최근 YOLOv8 오픈소스를 개발하였습니다. 기존 YOLOv5는 파이썬 스크립트를 실행하는 방식으로 모델을 학습시킬 수 있었는데 이번에는 파이썬 패키지(ultralytics)를 제공하여 좀 더 쉽게 모델을 학습할 수 있게 되었습니다. 또한 export 모듈을 통해 파일 변환도 빠르게 수행할 수 있습니다.
이번 포스팅에서는 YOLOv8 pretrained 모델을 TensorRT로 변환하고 Nvidia Triton Server를 Launch하여 gpu를 활용한 추론을 해보려고 합니다. YOLOv8에 대해서는 자세히 다루진 않기 때문에 라이브러리가 궁금하신 분들은 공식문서를 참고해주세요.
Environment
- Docker:version 23.0.1
- GPU: NVIDIA RTX A6000
공식문서에서는 Python >=3.7, PyTorch>=1.7 환경이 필요하다고 합니다. 저희의 목표는 TensorRT 변환과 Triron server로 모델을 배포하는 것이기 때문에 Nvidia NGC에서 제공하는 PyTorch 이미지를 컨테이너로 띄워서 진행하겠습니다.
Python 코드를 작성해야 하므로 주피터 랩 환경으로 컨테이너에 접속합니다.
docker run -d -it --ipc=host --gpus all \
-p <호스트 포트>:8888 --name ultralytics \
-v <로컬 경로>:/workspace/ultralytics nvcr.io/nvidia/pytorch:23.01-py3 \
jupyter lab &
# log에 남아있는 jupyter token 확인 후 접속
docker logs ultralytics
YOLOv8 Vanila to TensorRT
먼저 ultralytics 패키지를 설치하고 공식 github에서 모델을 다운로드 받습니다. ultralytics는 특정 모듈(train, predict, export 등)을 사용할때 사용자가 작성한 파라미터 값에 따라 요구되는 추가 라이브러리를 자동으로 설치해 주기 때문에 저희는 ultralytics만 있으면 됩니다.
# 패키지 설치
!pip install ultralytics
# pretrained 모델 다운로드
!wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt
pretrained 모델(PyTorch)을 export 모듈을 통해 TensorRT로 변환할 수 있습니다. 변환된 모델은 yolov8l.engine 파일로 저장됩니다. (이 글에서 TensorRT에 대한 설명은 넘어가겠습니다. TensorRT에 대해 자세히 알고싶으신 분들은 공식문서를 참고해 주세요.)
from ultralytics import YOLO
# 모델 로드
model = YOLO("yolov8l.pt")
# PyTorch to TensorRT
model.export(format='engine', device=0, half=True)
- format
- 변환할 포맷을 지정합니다. 지원하는 포맷은 TorchScript, ONNX, OpenVINO, TensorRT, CoreML, PaddlePaddle 등이 있습니다. TensorRT를 사용하고자 하는 경우 engine이라고 적으시면 됩니다.
- device
- 추론시에 cuda를 활용한다면 사용할 gpu의 device 번호를 적어줍니다. default값은 cpu입니다.
- half
- fp16 precision을 활용하고자 하는 경우 True를 적어줍니다. default값은 False(fp32)입니다.
PyTorch모델과 TensorRT모델의 Benchmark를 보도록 하겠습니다. 아래 코드를 실행시키면 sample 데이터셋을 다운받고 PyTorch 모델과 TensorRT 모델 및 precision(FP32, FP16)에 대한 Benchmark를 데이터 프레임으로 반환합니다.
import platform
import time
from pathlib import Path
import pandas as pd
from ultralytics import YOLO
from ultralytics.yolo.engine.exporter import export_formats
from ultralytics.yolo.utils import LINUX, LOGGER, ROOT, SETTINGS
from ultralytics.yolo.utils.checks import check_yolo
from ultralytics.yolo.utils.downloads import download
from ultralytics.yolo.utils.files import file_size
from ultralytics.yolo.utils.torch_utils import select_device
def benchmark(export_formats=None, imgsz=640, device='cpu', hard_fail=False):
device = select_device(device, verbose=False)
y = []
t0 = time.time()
for name, model_name, half in export_formats:
emoji, model = '❌', None # export defaults
try:
model = YOLO(model_name, task="detect")
emoji = '❎' # indicates export succeeded
# Predict
if not (ROOT / 'assets/bus.jpg').exists():
download(url='https://ultralytics.com/images/bus.jpg', dir=ROOT / 'assets')
model.predict(ROOT / 'assets/bus.jpg', imgsz=imgsz, device=device, half=half) # predict check
results = model.val(data="coco128.yaml", batch=1, imgsz=imgsz, plots=False, device=device, half=half, verbose=False)
metric, speed = results.results_dict['metrics/mAP50-95(B)'], results.speed['inference']
y.append([name, '✅', round(file_size(model_name), 1), round(metric, 4), round(speed, 2)])
except Exception as e:
if hard_fail:
assert type(e) is AssertionError, f'Benchmark hard_fail for {name}: {e}'
LOGGER.warning(f'ERROR ❌️ Benchmark failure for {name}: {e}')
y.append([name, emoji, round(file_size(model_name), 1), None, None]) # mAP, t_inference
# Print results
check_yolo(device=device) # print system info
df = pd.DataFrame(y, columns=['Format', 'Status❔', 'Size (MB)', 'metrics/mAP50-95(B)', 'Inference time (ms/im)'])
s = f'\nBenchmarks complete for {model_name} on coco128.yaml at imgsz={imgsz} ({time.time() - t0:.2f}s)\n{df}\n'
LOGGER.info(s)
with open('benchmarks.log', 'a', errors='ignore', encoding='utf-8') as f:
f.write(s)
if hard_fail and isinstance(hard_fail, float):
metrics = df[key].array # values to compare to floor
floor = hard_fail # minimum metric floor to pass, i.e. = 0.29 mAP for YOLOv5n
assert all(x > floor for x in metrics if pd.notna(x)), f'HARD FAIL: one or more metric(s) < floor {floor}'
return df
# name, path, half
export_formats = [
["PyTorch_fp32", "model/yolov8l.pt", False],
["PyTorch_fp16", "model/yolov8l.pt", True],
["TensorRT_fp32", "model/yolov8l_fp32.engine", False],
["TensorRT_fp16", "model/yolov8l_fp16.engine", True]]
benchmark(export_formats=export_formats, device='cuda:0'){: width="100" height="100"}{: .align-center}
output:
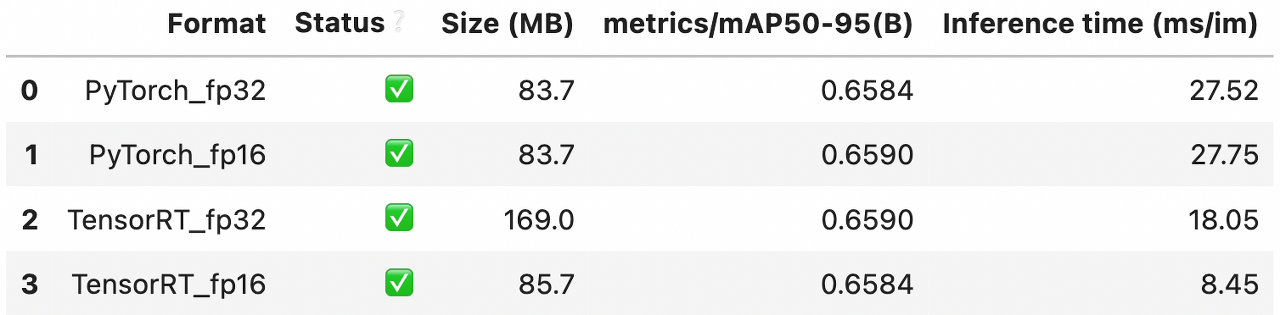
추론결과 FP32에서 TensorRT의 추론이 0.5배 빠르고 FP16에서는 Vanila 대비 3배이상 빠른 것을 확인할 수 있습니다. 간혹 FP16을 사용하면 성능이 떨어지는 경우가 있지만 지금의 결과에서는 mAP가 거의 유지되고 있기 때문에 가장 좋은 TensorRT_fp16 모델을 추론모델로 정하겠습니다.
Warning
위에서 export모듈을 통해 TensorRT로 변환한 .engine 파일은 아직 Nvidia Triton Server와 호환되지 않습니다. (ultralytics Issues 에 따르면 Triton을 지원하도록 작업할 예정이라고 합니다.) 이 문제를 해결하기 위해서는 직접 CLI명령어(trtexec)를 통해 TensorRT 모델로 변환해야 합니다.
그렇기 때문에 저희는 ultralytics의 export 모듈을 통해 ONNX 변환까지만 수행할 수 있습니다. 저희는 Dynamic Axes를 활용해서 batch size와 image scale을 바꾸면서 Nvidia Triton server에 추론을 요청 할 예정입니다. ultralytics의 export 모듈은 dynamic이라는 파라미터를 통해 dynamic axes를 받을 수 있도록 설정할 수 있습니다. 그런데 아래 명령어를 실행하게 되면 에러가 발생합니다.
model.export(format='onnx', device=0, half=True, dynamic=True)
# ONNX: export failure ❌ 0.4s: "slow_conv2d_cpu" not implemented for 'Half'
YOLOv8의 exporter.py 스크립트 파일을 확인해보면 dynamic=True일때 model과 dummy input tensor를 cpu로 변경시켜 버립니다. (torch.onnx.export 함수에서 확인가능) 무슨 이유때문에 해당 로직을 사용하는지는 모르겠지만 이렇게 되면 문제점이 ONNX는 cpu에서 FP16을 지원하지 않는다는 점 입니다. 그렇기 때문에 위와 같은 에러가 발생하게 됩니다.
여기서 tricky한 방법을 사용할 수 있습니다. 바로 half=False로 설정하는 것 입니다. 그리고 방금 말씀드린 것처럼 dynamic=True이면 device가 cpu로 변경되기 때문에 아래 코드의 결과는 동일합니다.
model.export(format='onnx', device=0, half=False, dynamic=True)
model.export(format='onnx', device='cpu', half=False, dynamic=True)
# same result: CPU + FP32 + dynamic
위 코드에 대한 의문점이 있을 수 있습니다.
1. gpu를 활용해 inference를 활용할 예정인데 cpu상태에서 ONNX 변환이 된 부분
2. 모델의 파라미터를 FP16으로 변경해야 하는데 FP32 그대로 ONNX 변환이 된 부분
먼저 1번 같은 경우는 문제가 되지 않습니다. ONNX 모델을 device=’cpu’ 상태에서 변환 했더라도 TensorRT에서 GPU로 추론이 가능합니다. PyTorch에서 모델을 CPU나 GPU에 올리더라도 모델 구조 자체는 변하지 않는 것처럼 모델 구조에 대한 정보를 담고 있는 ONNX 포맷으로 변환할 때에도 device와는 관계 없이 동일한 모델 구조 정보가 추출됩니다.
2번같은 경우는 저희가 ONNX를 TensorRT로 한번 더 변환해야 하기 때문에 괜찮습니다. TensorRT 변환 CLI 명령어인 trtexec에서 FP16 설정을 위한 옵션이 있기 때문에 ONNX를 추론에 사용할 것이 아니라면 신경쓰지 않아도 됩니다.
위 코드 실행 후 yolov8l.onnx 파일이 생성되었는지 확인해주세요.
추가 TIP
- TensoRT 자체 추론에서는 Nvidia gpu를 활용한 추론만 가능합니다. 타사의 GPU나 CPU 추론은 불가능합니다.
- Nvidia Triton server에서 TensorRT 모델을 활용할때는 CPU 추론이 가능합니다.
Convert ONNX to TensorRT
Nvidia NGC 컨테이너에는 기본적으로 TensorRT가 설치되어 있습니다. trtexec 명령어로 모델을 변환해 보겠습니다.
trtexec --onnx=yolov8l.onnx --saveEngine=model.plan \
--inputIOFormats=fp16:chw --outputIOFormats=fp16:chw --fp16 \
--minShapes=images:1x3x640x640 --maxShapes=images:10x3x640x640 --optShapes=images:3x3x640x640
- --onnx
- TensorRT로 변환할 onnx 모델의 경로입니다.
- –saveEngine
- 변환할 TensorRT 모델의 이름입니다. Triton에서 TensorRT 모델을 사용하기 위해서는 .plan 확장자를 사용합니다.
- --inputIOFormats, –outputIOFormats
- 입력과 출력 텐서의 데이터 형식을 의미합니다. 입력값에 붙어있는 :chw는 channel, height, width를 의미하지만 크게 신경쓰지 않아도 됩니다. (참고로 YOLOv8의 Output의 각 차원의 의미는 [batch, classes(xywh+class), boxes] 입니다.)
- --fp16
- 모델의 precision을 FP16으로 설정한다는 의미입니다. 벤치마크에서 FP16의 성능이 좋았기 때문에 사용하겠습니다.
- --minShapes, –maxShapes, –optShapes
- 차례대로 입력 텐서의 최소, 최대, 최적 shape을 의미합니다. 저는 위와같이 batch size의 범위만 다르게 설정하였습니다.
실행이 완료되기까지 약간의 시간이 소요됩니다. 커피 한잔 하면서 기다려주세요!

model.plan 파일이 생성되었다면 정상적으로 변환이 완료된 것입니다. 이제 Nvidia Triton Server에 대해 알아보겠습니다.
Nvidia Triton Server
Triton을 사용하기 위해서는 먼저 Model Repository를 구성해 놓아야 합니다. triton 서버를 띄울 때 tritonserver라는 명령어를 사용하게 되는데 필수옵션으로 –model-repository 를 작성하게 되어 있습니다. Model Repository를 구성하는 디렉토리와 파일은 triton 규칙을 따르는 layout으로 작성되어야 합니다.
# 예시
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
먼저 Model Repository의 하위 디렉토리 이름은 모델 이름이 되고 해당 모델 디렉토리 안에는 모델의 버전을 나타내는 숫자 하위 디렉토리를 하나 이상 가지고 있어야 합니다. 그리고 그 버전 디렉토리 안에는 TensorRT, PyTorch, ONNX, OpenVINO 및 TensorFlow와 같은 프레임워크의 실제 모델파일이 담겨있어야 합니다.
또한 모델의 configuration을 설명하는 config.pbtxt를 작성해야 합니다. Auto-Generated Model Configuration 이라는 기능으로 추론서버 실행 시 자동으로 configuration을 작성할 수 있지만 여기에서는 직접 pbtxt를 작성해 보겠습니다.
Model Configuration(config.pbtxt)
name: "yolov8l"
platform: "tensorrt_plan"
max_batch_size : 0
input [
{
name: "images"
data_type: TYPE_FP16
dims: [ -1, 3, 640, 640 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP16
dims: [ -1, 84, 8400 ]
}
]
- name
- optional field로 필수는 아니지만 pbtxt 파일의 구별을 위해 작성합니다. 작성시 주의할 점은 모델 디렉토리의 이름과 동일하게 작성해야 한다는 것입니다.
- platform
- _ 를 기준으로 앞쪽에는 backend를 뒤쪽에는 파일의 확장자를 작성합니다. 저희는 tensorrt 모델을 plan 확장자로 저장해 두었으므로 tensorrt_plan 이라고 적겠습니다.
- max_batch_size
- inference시 최대 배치사이즈를 지정할 수 있습니다. 그런데 TensorRT 모델을 생성할 때 Batch size에 대한 옵션을 설정해주기 때문에 TensorRT engine을 사용할때는 0으로 세팅해야 합니다. 0이 아닌 값을 설정하면 에러가 발생합니다.
- input, output
- 모델 입출력 tensor의 대한 정보를 입력합니다.
- name
- ONNX 변환할 때 input_names, output_names 파라미터에 설정한 값 그대로 작성합니다. ultralytics의 export 모듈로 변환한 경우 “images”, “output0” 로 설정됩니다.
- data_type
- 입출력 tensor의 유형을 설정합니다. TensorRT에서 변환할때 –inputIOFormats, –outputIOFormats 옵션에서 FP16으로 지정했기 때문에 여기서도 TYPE_FP16 으로 설정합니다.
- dims
- Tensor의 입출력 차원입니다. 저희는 dynamic axes를 batch에 사용 할 예정이기 때문에 가장 앞쪽에 있는 batch size 차원에 -1로 설정하여 batch size를 자유롭게 받을 수 있게합니다. 나머지 차원은 default 값으로 고정시키겠습니다.
작성이 완료되었으면 아래와 같은 폴더 구조를 만들어주세요. (현재 작업중인 환경이 컨테이너이신 분들은 설정한 볼륨 위치에 저장해주시기 바랍니다.)
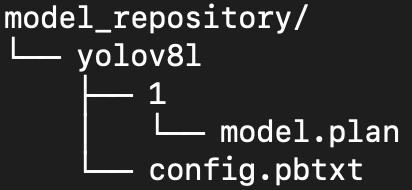
사전준비가 끝났습니다. 이제 tritonserver를 배포시켜 추론 테스트를 해보겠습니다.
Launch Triton Server
Triton 서버를 직접 로컬에 설치할 수 있지만 Triton에서는 도커 컨테이너를 활용할 것을 권장하고 있습니다. 자세한 내용은 여기를 참조하시길 바랍니다.
저는 TensorRT 변환을 nvcr.io/nvidia/pytorch:23.01-py3 컨테이너에서 작업했기 때문에 Triton 서버를 nvcr.io/nvidia/tritonserver:23.01-py3 컨테이너로 띄우겠습니다. (동일한 버전의 이미지를 사용하지 않으면 의존성 에러가 발생할 확률이 높습니다.)
docker run --gpus all -it --rm \
-p <http 호스트 포트>:8000 -p <grpc 호스트 포트>:8001 -p <metrics 호스트 포트>:8002 \
--name tritonserver \
-v <model_repository 경로>:/models \
nvcr.io/nvidia/tritonserver:23.01-py3 \
/bin/bash
Triton server는 HTTP/REST protocol과 GRPC protocol 통신을 지원합니다. 또한 GPU 사용량이나 추론 요청에 대한 통계 Metric을 제공하기 때문에 각 컴포넌트별로 엔트포인트가 존재합니다.(http=8000, grpc=8001, metrics=8002) 외부접속을 위해 자신이 접속할 포트번호로 port forwarding 해주세요. 그리고 -v 를 통해 위에서 준비해 놓은 model_repository를 triton server의 /models에 mount 시키겠습니다.
컨테이너에 접속하셨다면 이제 tritonserver 명령어를 통해 추론기를 배포할 수 있습니다.
그전에 model_repository를 주피터에서 작성하신 분들은 /models로 이동하여 .ipynb_checkpoint 폴더를 삭제해 주세요. model_repository 안에 레이아웃(규칙)을 벗어난 파일이나 폴더가 존재하면 배포시에 에러가 발생합니다.
cd /models
find . -name ".ipynb_checkpoints" -exec rm -rf {} \;
이제 추론기를 배포하겠습니다.
tritonserver --model-repository=/models
--model-repository=/models 옵션을 통해 yolov8.plan을 추론기로 배포할 수 있습니다. tritonserver 명령어에는 많은 옵션들이 존재합니다. 서버에 대해 보다 자세한 내용이 궁금하신 분들은 여기를 참고해주세요.
명령어를 실행했을때 아래와 같은 log가 남아있다면 정상적으로 배포된 것입니다.
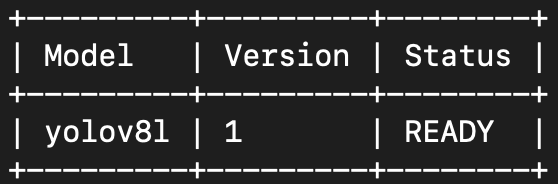

Performance Check
서버의 성능을 측정할 때는 크게 Latency와 Throughput을 통해 판단하게 됩니다. Latency란 클라이언트 입장에서 완료까지 얼마나 걸리는가를 의미하고 Throughput은 서버의 입장에서 시간당 얼마나 처리하는가를 의미합니다. 즉 Latency는 낮을수록 좋고 Throughput은 빠를수록 좋습니다.
예를 들어 고속도로 상황에서 Latency가 낮다라는건 제한속도가 높아서 차들이 빠르게 지나다닐 수 있다고 할 수 있고 Throughput이 높다는 것은 도로가 넓어서 한번에 통과할 수 있는 차량의 수가 많은 것이라고 할 수 있습니다. 이때 고속도로에 많은 차량이 지나다니게 하고 싶을때 제한속도를 높일것인지, 도로를 넓힐것인지를 적당히 따져 가면서 최적점을 찾아야 합니다.
이제 클라이언트를 준비해서 Triron Server의 성능을 확인해 보겠습니다. NGC sdk 컨테이너는 Triton Server의 throughput과 latency를 분석해주는 툴인 perf_analyzer를 지원합니다. 아래 명령어를 통해 클라이언트를 실행하겠습니다.
docker pull nvcr.io/nvidia/tritonserver:23.01-py3-sdk
docker run --rm -it --ipc=host nvcr.io/nvidia/tritonserver:23.01-py3-sdk
이제 perf_analyzer를 통해서 추론 성능을 확인해 보겠습니다. (perf_analyzer에는 매우 많은 옵션이 있습니다. 상황에 맞게 옵션을 잘 활용하시면 보다 정확한 결과를 얻으실 수 있습니다.)
perf_analyzer -m yolov8l -u <호스트IP>:<grpc 호스트Port> \
--shape=images:1,3,640,640 --concurrency-range=1:8 -i grpc -f result.csv
# Inferences/Second vs. Client Average Batch Latency
# Concurrency: 1, throughput: 19.2675 infer/sec, latency 51786 usec
# Concurrency: 2, throughput: 27.0915 infer/sec, latency 73725 usec
# Concurrency: 3, throughput: 29.3156 infer/sec, latency 102268 usec
# Concurrency: 4, throughput: 29.3335 infer/sec, latency 136086 usec
# Concurrency: 5, throughput: 29.4154 infer/sec, latency 169712 usec
# Concurrency: 6, throughput: 29.2504 infer/sec, latency 204928 usec
# Concurrency: 7, throughput: 29.203 infer/sec, latency 239180 usec
# Concurrency: 8, throughput: 29.1438 infer/sec, latency 273415 usec
- -m
- 추론에 사용할 모델의 (폴더)이름입니다.
- -u
- 서버의 IP와 Port 정보를 입력합니다.
- --shape
- 입력 데이터의 shape 입니다. input_name:shape 형식으로 작성할 수 있습니다. 저희의 경우 만약 이 옵션을 사용하지 않으면 dynamic shape을 포함하고 있으므로 shape을 명시하라는 에러가 발생합니다.
- --concurrency-range
- 추론 요청을 보내는 클라이언트수(동시에 처리가능한 추론 요청의 개수)를 start:end:step 에 따라 증가시켜 테스트를 진행합니다. 1부터 8까지 증가시켜 보겠습니다.
- -i
- 사용할 protocol을 설정합니다. grpc 통신을 하겠습니다.
- -f
- 성능평가에 대한 결과를 저장할 수 있습니다.
결과를 해석해보면 Concurrency 5일때 서버는 초당 29.4154개의 inference를 수행(throughtput)할 수 있고 5개의 추론 요청을 한번에 처리하여 결과를 반환하는데 평균적으로 169.712ms가 소요된다고 할 수 있습니다.
GPU 성능도 좋고 메모리도 여유가 있더라도 Concurrency가 증가함에 따라 throughput이 선형적으로 빨라지지 않는 이유는 병목현상이나 네트워크 대역폭 한계 때문일 수 있습니다. 이에반해 Concurrency가 증가하면 한번에 추론해야 하는 요청이 많이 때문에 연산량이 많아지므로 latency는 선형적으로 높아지게됩니다.
시스템의 전반적인 구성 및 리소스 사용, 네트워크 대역폭 등을 고려하여 최적의 Concurrency를 찾는 것이 중요합니다.
Inference with Client
Nvidia Triton Server에서는 client가 요청을 주고받을 수 있도록 C++, Python, JAVA API를 제공합니다. 저희는 Python API를 활용해서 서버로 요청을 보내고 추론 결과를 확인해 보겠습니다.
추론을 위해서는 tritonclient 라이브러리를 설치해야 합니다. 클라이언트 환경을 준비해주시고 아래와 같이 tritonclient를 설치합니다.(추가적으로 전 후처리를 위해 opencv, numpy, pillow 등이 필요합니다. 환경에 없는 라이브러리가 있다면 추가 설치해주시면 됩니다. )
pip install tritonclient[all]
import tritonclient.http as httpclient
import numpy as np
client = httpclient.InferenceServerClient(url="<IP>:<HTTP PORT>")
inputs = httpclient.InferInput("images", img.shape, datatype="FP16")
outputs = httpclient.InferRequestedOutput("output0", binary_data=True)
inf_time = 0
for _ in range(10):
img = np.random.randn(8, 3, 640, 640).astype(np.float16)
inputs.set_data_from_numpy(img, binary_data=True) # FP16 이라면 binary_data=True 필수
# Inference
start_time = time.time()
res = client.infer(model_name="yolov8l", inputs=[inputs], outputs=[outputs]).as_numpy('output0')
end_time = time.time()
inf_time += (end_time - start_time)
print(f"inference time: {inf_time/10 * 1000:.3f} ms")
print(f"input shape: {img.shape}")
print(f"output shape: {res.shape}")
tritonclient 사용법은 onnxruntime이나 openvino inference와 비슷합니다. input과 output의 정보와 데이터를 입력해주고 client.infer() 함수를 통해 결과를 얻을 수 있습니다. 이번에는 http protocol을 통해 batch size 8 인 dummy data를 10번 추론해보겠습니다.
result:
inference time: 395.394 ms
input shape: (8, 3, 640, 640)
output shape: (8, 84, 8400)
추론 속도는 평균적으로 395.394 ms가 나오며 input, output의 shape은 예상대로 나오는 것을 확인할 수 있습니다. 만약 저희가 TensorRT 변환에서 설정한 max batch size인 10을 넘어가면 에러가 발생하게 됩니다.
이제 결과를 활용해서 ultralytics의 pytorch모델과 실제 추론결과를 시각화하여 비교해보겠습니다.
Ultralytics
from ultralytics import YOLO
model = YOLO("model/yolov8l.pt")
result = model("<your image path>")[0].plot()
pil_image=Image.fromarray(result[:, :, ::-1])
pil_image.show()
Nvidia Triton Server
from ultralytics.yolo.utils import ROOT, yaml_load
from ultralytics.yolo.utils.checks import check_yaml
import time
import cv2
import numpy as np
from PIL import Image
import tritonclient.http as httpclient
client = httpclient.InferenceServerClient(url="<IP>:<HTTP PORT>")
CLASSES = yaml_load(check_yaml('coco128.yaml'))['names']
colors = np.random.uniform(0, 255, size=(len(CLASSES), 3))
def draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):
label = f'{CLASSES[class_id]} ({confidence:.2f})'
color = colors[class_id]
cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)
cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_DUPLEX, 0.7, color, 1)
def main():
# Pre Processing
original_image = cv2.imread("<your image path>")
or_copy = original_image.copy() # 시각화가 적용될 원본 이미지
[height, width, _] = original_image.shape
length = max((height, width))
scale = length / 640 # bbox scaling(후처리)를 위한 값
image = np.zeros((length, length, 3), np.uint8)
image[0:height, 0:width] = original_image # 정사각형을 만들면서 비율을 유지하기 위해 나머지는 black 처리
resize = cv2.resize(image, (640, 640))
img = resize[np.newaxis, :, :, :] / 255.0
img = img.transpose((0, 3, 1, 2)).astype(np.float16)
inputs = httpclient.InferInput("images", img.shape, datatype="FP16")
inputs.set_data_from_numpy(img, binary_data=True) # FP16일때는 binary 필수
outputs = httpclient.InferRequestedOutput("output0", binary_data=True)
# Inference
start_time = time.time()
res = client.infer(model_name="yolov8l", inputs=[inputs], outputs=[outputs]).as_numpy('output0')
end_time = time.time()
inf_time = (end_time - start_time)
print(f"inference time: {inf_time*1000:.3f} ms")
# Post Processing
outputs = np.array([cv2.transpose(res[0].astype(np.float32))])
rows = outputs.shape[1]
boxes = []
scores = []
class_ids = []
for i in range(rows):
classes_scores = outputs[0][i][4:]
(minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)
if maxScore >= 0.25:
box = [
outputs[0][i][0] - (0.5 * outputs[0][i][2]), outputs[0][i][1] - (0.5 * outputs[0][i][3]),
outputs[0][i][2], outputs[0][i][3]]
boxes.append(box)
scores.append(maxScore)
class_ids.append(maxClassIndex)
result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)
detections = []
for i in range(len(result_boxes)):
index = result_boxes[i]
box = boxes[index]
detection = {
'class_id': class_ids[index],
'class_name': CLASSES[class_ids[index]],
'confidence': scores[index],
'box': box,
'scale': scale}
detections.append(detection)
draw_bounding_box(or_copy, class_ids[index], scores[index], round(box[0] * scale), round(box[1] * scale),
round((box[0] + box[2]) * scale), round((box[1] + box[3]) * scale))
return or_copy


ultralytics inference vs triton inference
현재 이미지 기준에서는 triton 쪽에서 confidence가 조금 낮아졌지만 cup을 예측한 bounding box 좌표는 오히려 triton 쪽이 조금 더 정확하게 잡은 것 같습니다. ultralytics의 추론속도는 30.2ms, triton server의 추론속도는 53.1 ms 가 나왔습니다.
왜 triton server의 속도가 더 느릴까요?
Triton Server는 클라이언트와 통신이 필요합니다. Triton Server는 클라이언트의 요청에 대한 응답으로 추론 결과를 반환해야 합니다. 이 때, 클라이언트와 Triton Server 간의 통신에 따른 지연 시간(latency)이 발생할 수 있습니다.
즉 ultralytics inference는 개발 환경에 모델을 로드한 상태에서 추론을 하는 것이기 때문에 당연히 비교적으로 빠를수밖에 없습니다. 제대로 triton server와의 추론속도를 비교하기 위해서는 FastAPI와 같은 웹 프레임워크에 모델을 배포하고 마찬가지로 client 환경에서 FastAPI endpoint에 추론을 요청해야합니다. 그렇게되면 FastAPI vs Triton Server로 제대로 된 비교를 할 수 있습니다.
END
지금까지 YOLOv8 large 모델을 활용하여 TensorRT 변환, 그리고 NVIDIA Triton Server에 대해 알아보았습니다. 정리하면 TensorRT는 최적화된 CUDA 커널과 네트워크 최적화 기술을 사용하여 GPU에서 딥러닝 모델의 추론 성능을 크게 향상 시킬 수 있는 툴킷입니다. 그리고 NVIDIA Triton Server는 모델을 배포하고 관리하는 데 사용되는 오픈소스 프레임워크이며 클라이언트와의 통신, 모델 로딩, 스케일링, 메트릭 수집 등의 기능을 제공하고 Kubernetes, Docker 등의 컨테이너 환경에서 쉽게 사용이 가능한 장점이 있습니다.
추론 과정에서 gpu를 활용하는 경우에 TensorRT와 Triton Server를 함께 사용하면 성능이 좋다고 알려져 있습니다. 정확한 이유는 모르겠지만 아무래도 둘 다 NVIDIA에서 개발한 오픈소스이기 때문에 최적화 잘 이루어지도록 설계된 것으로 보입니다.
여유가 된다면 NVIDIA Triton Server를 kuberences 환경에서 활용하는 방법과 metric을 수집해 알람 시스템을 구축하는 포스팅을 작성해보겠습니다.
Keep Going
Reference
ultralytics: https://github.com/ultralytics/ultralytics
NVIDIA Triton Server: https://github.com/triton-inference-server
Leave a comment